 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effect of stemming and lemmatization on Portuguese fake news text classification
Oct 17, 2023



With the popularization of the internet, smartphones and social media, information is being spread quickly and easily way, which implies bigger traffic of information in the world, but there is a problem that is harming society with the dissemination of fake news. With a bigger flow of information, some people are trying to disseminate deceptive information and fake news. The automatic detection of fake news is a challenging task because to obtain a good result is necessary to deal with linguistics problems, especially when we are dealing with languages that not have been comprehensively studied yet, besides that, some techniques can help to reach a good result when we are dealing with text data, although, the motivation of detecting this deceptive information it is in the fact that the people need to know which information is true and trustful and which one is not. In this work, we present the effect the pre-processing methods such as lemmatization and stemming have on fake news classification, for that we designed some classifier models applying different pre-processing techniques. The results show that the pre-processing step is important to obtain betters results, the stemming and lemmatization techniques are interesting methods and need to be more studied to develop techniques focused on the Portuguese language so we can reach better results.
Spatiotemporal CNNs for Pornography Detection in Videos
Oct 24, 2018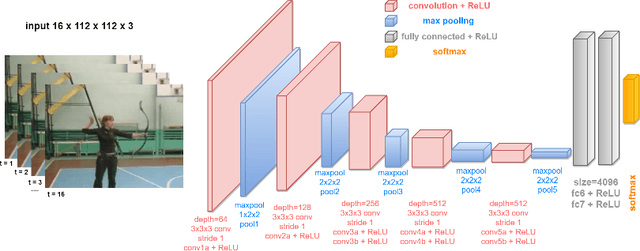
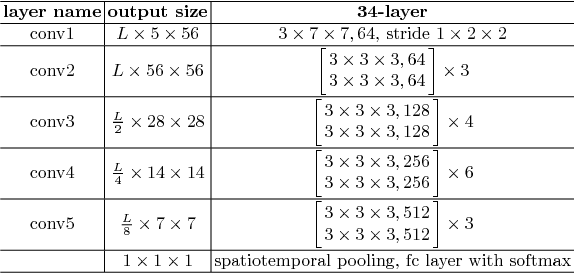

With the increasing use of social networks and mobile devices, the number of videos posted on the Internet is growing exponentially. Among the inappropriate contents published on the Internet, pornography is one of the most worrying as it can be accessed by teens and children. Two spatiotemporal CNNs, VGG-C3D CNN and ResNet R(2+1)D CNN, were assessed for pornography detection in videos in the present study. Experimental results using the Pornography-800 dataset showed that these spatiotemporal CNNs performed better than some state-of-the-art methods based on bag of visual words and are competitive with other CNN-based approaches, reaching accuracy of 95.1%.