 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PECoP: Parameter Efficient Continual Pretraining for Action Quality Assessment
Nov 11, 2023
The limited availability of labelled data in Action Quality Assessment (AQA), has forced previous works to fine-tune their models pretrained on large-scale domain-general datasets. This common approach results in weak generalisation, particularly when there is a significant domain shift. We propose a novel, parameter efficient, continual pretraining framework, PECoP, to reduce such domain shift via an additional pretraining stage. In PECoP, we introduce 3D-Adapters, inserted into the pretrained model, to learn spatiotemporal, in-domain information via self-supervised learning where only the adapter modules' parameters are updated. We demonstrate PECoP's ability to enhance the performance of recent state-of-the-art methods (MUSDL, CoRe, and TSA) applied to AQA, leading to considerable improvements on benchmark datasets, JIGSAWS ($\uparrow6.0\%$), MTL-AQA ($\uparrow0.99\%$), and FineDiving ($\uparrow2.54\%$). We also present a new Parkinson's Disease dataset, PD4T, of real patients performing four various actions, where we surpass ($\uparrow3.56\%$) the state-of-the-art in comparison. Our code, pretrained models, and the PD4T dataset are available at https://github.com/Plrbear/PECoP.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Nov 11, 2023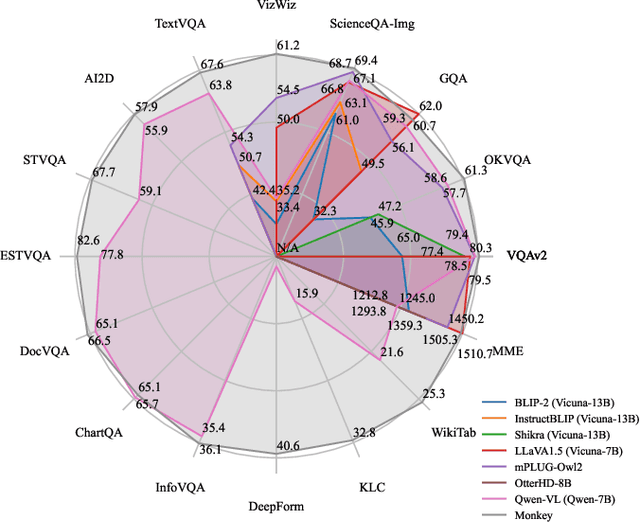
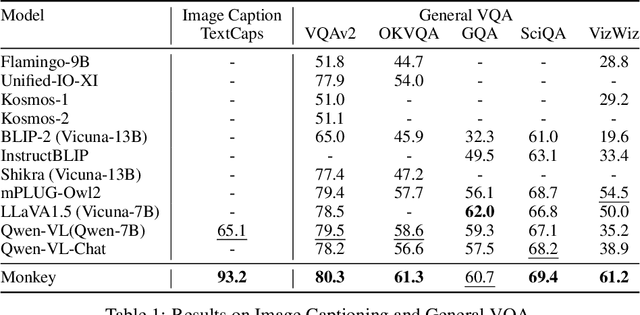
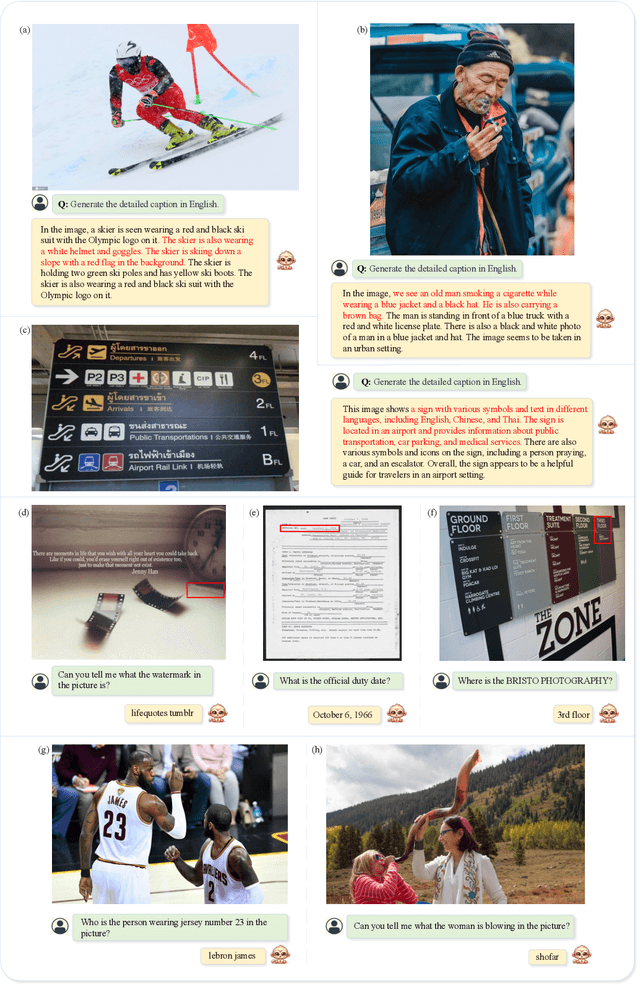
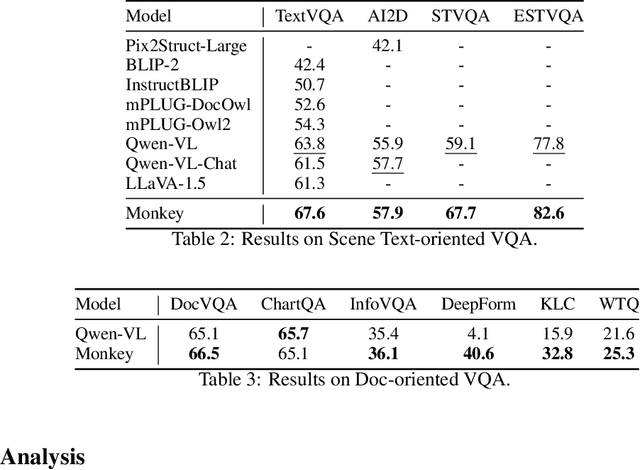
Large Multimodal Models have demonstrated impressive capabilities in understanding general vision-language tasks. However, due to the limitation of supported input resolution (e.g., 448 x 448) as well as the inexhaustive description of the training image-text pair, these models often encounter challenges when dealing with intricate scene understandings and narratives. Here we address the problem by proposing the Monkey. Our contributions are two-fold: 1) without pretraining from the start, our method can be built upon an existing vision encoder (e.g., vit-BigHuge) to effectively improve the input resolution capacity up to 896 x 1344 pixels; 2) we propose a multi-level description generation method, which automatically provides rich information that can guide model to learn contextual association between scenes and objects. Our extensive testing across more than 16 distinct datasets reveals that Monkey achieves consistently competitive performance over the existing LMMs on fundamental tasks, such as Image Captioning, General Visual Question Answering (VQA), and Document-oriented VQA. Models, interactive demo, and the source code are provided at the following https://github.com/Yuliang-Liu/Monkey.
Understanding Grokking Through A Robustness Viewpoint
Nov 11, 2023Recently, an unusual phenomenon called grokking has gained much attention, where sometimes a neural network generalizes long after it perfectly fits the training data. We try to understand this seemingly strange phenomenon using the robustness of the neural network. Using a robustness viewpoint, we show that the popular $l_2$ weight norm (metric) of the neural network is actually a sufficient condition for grokking. As we also empirically find that $l_2$ norm correlates with grokking on the test data not in a timely way, we propose new metrics based on robustness and information theory and find that our new metrics correlate well with the grokking phenomenon. Based on the previous observations, we propose methods to speed up the generalization process. In addition, we examine the standard training process on modulo addition dataset and find that it hardly learns other basic group operations before grokking, including the commutative law. Interestingly, the speed up of generalization when using our proposed method can be partially explained by learning the commutative law, a necessary condition when the model groks on test dataset.
Topology of Surface Electromyogram Signals: Hand Gesture Decoding on Riemannian Manifolds
Nov 14, 2023Decoding gestures from the upper limb using noninvasive surface electromyogram (sEMG) signals is of keen interest for the rehabilitation of amputees, artificial supernumerary limb augmentation, gestural control of computers, and virtual/augmented realities. We show that sEMG signals recorded across an array of sensor electrodes in multiple spatial locations around the forearm evince a rich geometric pattern of global motor unit (MU) activity that can be leveraged to distinguish different hand gestures. We demonstrate a simple technique to analyze spatial patterns of muscle MU activity within a temporal window and show that distinct gestures can be classified in both supervised and unsupervised manners. Specifically, we construct symmetric positive definite (SPD) covariance matrices to represent the spatial distribution of MU activity in a time window of interest, calculated as pairwise covariance of electrical signals measured across different electrodes. This allows us to understand and manipulate multivariate sEMG timeseries on a more natural subspace -the Riemannian manifold. Furthermore, it directly addresses signal variability across individuals and sessions, which remains a major challenge in the field. sEMG signals measured at a single electrode lack contextual information such as how various anatomical and physiological factors influence the signals and how their combined effect alters the evident interaction among neighboring muscles. As we show here, analyzing spatial patterns using covariance matrices on Riemannian manifolds allows us to robustly model complex interactions across spatially distributed MUs and provides a flexible and transparent framework to quantify differences in sEMG signals across individuals. The proposed method is novel in the study of sEMG signals and its performance exceeds the current benchmarks while maintaining exceptional computational efficiency.
An Intraoperative Force Perception and Signal Decoupling Method on Capsulorhexis Forceps
Nov 14, 2023Force perception on medical instruments is critical for understanding the mechanism between surgical tools and tissues for feeding back quantized force information, which is essential for guidance and supervision in robotic autonomous surgery. Especially for continuous curvilinear capsulorhexis (CCC), it always lacks a force measuring method, providing a sensitive, accurate, and multi-dimensional measurement to track the intraoperative force. Furthermore, the decoupling matrix obtained from the calibration can decorrelate signals with acceptable accuracy, however, this calculating method is not a strong way for thoroughly decoupling under some sensitive measuring situations such as the CCC. In this paper, a three-dimensional force perception method on capsulorhexis forceps by installing Fiber Bragg Grating sensors (FBGs) on prongs and a signal decoupling method combined with FASTICA is first proposed to solve these problems. According to experimental results, the measuring range is up to 1 N (depending on the range of wavelength shifts of sensors) and the resolution on x, y, and z axial force is 0.5, 0.5, and 2 mN separately. To minimize the coupling effects among sensors on measuring multi-axial forces, by unitizing the particular parameter and scaling the corresponding vector in the mixing matrix and recovered signals from FastICA, the signals from sensors can be decorrelated and recovered with the errors on axial forces decreasing up to 50% least. The calibration and calculation can also be simplified with half the parameters involved in the calculation. Experiments on thin sheets and in vitro porcine eyes were performed, and it was found that the tearing forces were stable and the time sequence of tearing forceps was stationary or first-order difference stationary during roughly circular crack propagating.
Greedy PIG: Adaptive Integrated Gradients
Nov 10, 2023Deep learning has become the standard approach for most machine learning tasks. While its impact is undeniable, interpreting the predictions of deep learning models from a human perspective remains a challenge. In contrast to model training, model interpretability is harder to quantify and pose as an explicit optimization problem. Inspired by the AUC softmax information curve (AUC SIC) metric for evaluating feature attribution methods, we propose a unified discrete optimization framework for feature attribution and feature selection based on subset selection. This leads to a natural adaptive generalization of the path integrated gradients (PIG) method for feature attribution, which we call Greedy PIG. We demonstrate the success of Greedy PIG on a wide variety of tasks, including image feature attribution, graph compression/explanation, and post-hoc feature selection on tabular data. Our results show that introducing adaptivity is a powerful and versatile method for making attribution methods more powerful.
Schema Graph-Guided Prompt for Multi-Domain Dialogue State Tracking
Nov 10, 2023Tracking dialogue states is an essential topic in task-oriented dialogue systems, which involve filling in the necessary information in pre-defined slots corresponding to a schema. While general pre-trained language models have been shown effective in slot-filling, their performance is limited when applied to specific domains. We propose a graph-based framework that learns domain-specific prompts by incorporating the dialogue schema. Specifically, we embed domain-specific schema encoded by a graph neural network into the pre-trained language model, which allows for relations in the schema to guide the model for better adaptation to the specific domain. Our experiments demonstrate that the proposed graph-based method outperforms other multi-domain DST approaches while using similar or fewer trainable parameters. We also conduct a comprehensive study of schema graph architectures, parameter usage, and module ablation that demonstrate the effectiveness of our model on multi-domain dialogue state tracking.
Overview of the CLAIMSCAN-2023: Uncovering Truth in Social Media through Claim Detection and Identification of Claim Spans
Oct 30, 2023A significant increase in content creation and information exchange has been made possible by the quick development of online social media platforms, which has been very advantageous. However, these platforms have also become a haven for those who disseminate false information, propaganda, and fake news. Claims are essential in forming our perceptions of the world, but sadly, they are frequently used to trick people by those who spread false information. To address this problem, social media giants employ content moderators to filter out fake news from the actual world. However, the sheer volume of information makes it difficult to identify fake news effectively. Therefore, it has become crucial to automatically identify social media posts that make such claims, check their veracity, and differentiate between credible and false claims. In response, we presented CLAIMSCAN in the 2023 Forum for Information Retrieval Evaluation (FIRE'2023). The primary objectives centered on two crucial tasks: Task A, determining whether a social media post constitutes a claim, and Task B, precisely identifying the words or phrases within the post that form the claim. Task A received 40 registrations, demonstrating a strong interest and engagement in this timely challenge. Meanwhile, Task B attracted participation from 28 teams, highlighting its significance in the digital era of misinformation.
Disentangled Representation Learning with Large Language Models for Text-Attributed Graphs
Nov 06, 2023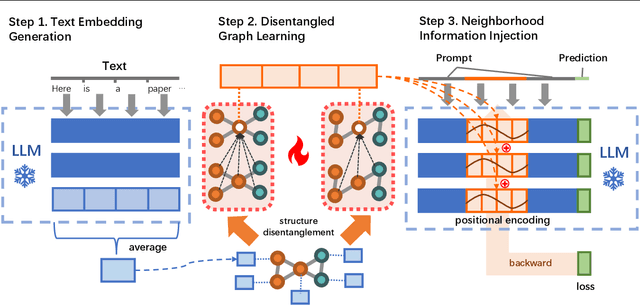

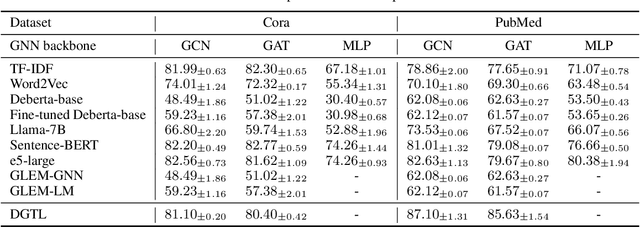
Text-attributed graphs (TAGs) are prevalent on the web and research over TAGs such as citation networks, e-commerce networks and social networks has attracted considerable attention in the web community. Recently, large language models (LLMs) have demonstrated exceptional capabilities across a wide range of tasks. However, the existing works focus on harnessing the potential of LLMs solely relying on prompts to convey graph structure information to LLMs, thus suffering from insufficient understanding of the complex structural relationships within TAGs. To address this problem, in this paper we present the Disentangled Graph-Text Learner (DGTL) model, which is able to enhance the reasoning and predicting capabilities of LLMs for TAGs. Our proposed DGTL model incorporates graph structure information through tailored disentangled graph neural network (GNN) layers, enabling LLMs to capture the intricate relationships hidden in text-attributed graphs from multiple structural factors. Furthermore, DGTL operates with frozen pre-trained LLMs, reducing computational costs and allowing much more flexibility in combining with different LLM models. Experimental evaluations demonstrate the effectiveness of the proposed DGTL model on achieving superior or comparable performance over state-of-the-art baselines. Additionally, we also demonstrate that our DGTL model can offer natural language explanations for predictions, thereby significantly enhancing model interpretability.
Deep Learning-Empowered Semantic Communication Systems with a Shared Knowledge Base
Nov 06, 2023Deep learning-empowered semantic communication is regarded as a promising candidate for future 6G networks. Although existing semantic communication systems have achieved superior performance compared to traditional methods, the end-to-end architecture adopted by most semantic communication systems is regarded as a black box, leading to the lack of explainability. To tackle this issue, in this paper, a novel semantic communication system with a shared knowledge base is proposed for text transmissions. Specifically, a textual knowledge base constructed by inherently readable sentences is introduced into our system. With the aid of the shared knowledge base, the proposed system integrates the message and corresponding knowledge from the shared knowledge base to obtain the residual information, which enables the system to transmit fewer symbols without semantic performance degradation. In order to make the proposed system more reliable, the semantic self-information and the source entropy are mathematically defined based on the knowledge base. Furthermore, the knowledge base construction algorithm is developed based on a similarity-comparison method, in which a pre-configured threshold can be leveraged to control the size of the knowledge base. Moreover, the simulation results have demonstrated that the proposed approach outperforms existing baseline methods in terms of transmitted data size and sentence similarity.