 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCrossAttention: Supercharging Transformer Residual Connections
Feb 10, 2025



Transformer networks have achieved remarkable success across diverse domains, leveraging a variety of architectural innovations, including residual connections. However, traditional residual connections, which simply sum the outputs of previous layers, can dilute crucial information. This work introduces DeepCrossAttention (DCA), an approach that enhances residual learning in transformers. DCA employs learnable, input-dependent weights to dynamically combine layer outputs, enabling the model to selectively focus on the most relevant information in any of the previous layers. Furthermore, DCA incorporates depth-wise cross-attention, allowing for richer interactions between layers at different depths. Our language modeling experiments show that DCA achieves improved perplexity for a given training time. Moreover, DCA obtains the same model quality up to 3x faster while adding a negligible number of parameters. Theoretical analysis confirms that DCA provides an improved trade-off between accuracy and model size when the ratio of collective layer ranks to the ambient dimension falls below a critical threshold.
Data-Efficient Learning via Clustering-Based Sensitivity Sampling: Foundation Models and Beyond
Feb 27, 2024



We study the data selection problem, whose aim is to select a small representative subset of data that can be used to efficiently train a machine learning model. We present a new data selection approach based on $k$-means clustering and sensitivity sampling. Assuming access to an embedding representation of the data with respect to which the model loss is H\"older continuous, our approach provably allows selecting a set of ``typical'' $k + 1/\varepsilon^2$ elements whose average loss corresponds to the average loss of the whole dataset, up to a multiplicative $(1\pm\varepsilon)$ factor and an additive $\varepsilon \lambda \Phi_k$, where $\Phi_k$ represents the $k$-means cost for the input embeddings and $\lambda$ is the H\"older constant. We furthermore demonstrate the performance and scalability of our approach on fine-tuning foundation models and show that it outperforms state-of-the-art methods. We also show how it can be applied on linear regression, leading to a new sampling strategy that surprisingly matches the performances of leverage score sampling, while being conceptually simpler and more scalable.
SequentialAttention++ for Block Sparsification: Differentiable Pruning Meets Combinatorial Optimization
Feb 27, 2024



Neural network pruning is a key technique towards engineering large yet scalable, interpretable, and generalizable models. Prior work on the subject has developed largely along two orthogonal directions: (1) differentiable pruning for efficiently and accurately scoring the importance of parameters, and (2) combinatorial optimization for efficiently searching over the space of sparse models. We unite the two approaches, both theoretically and empirically, to produce a coherent framework for structured neural network pruning in which differentiable pruning guides combinatorial optimization algorithms to select the most important sparse set of parameters. Theoretically, we show how many existing differentiable pruning techniques can be understood as nonconvex regularization for group sparse optimization, and prove that for a wide class of nonconvex regularizers, the global optimum is unique, group-sparse, and provably yields an approximate solution to a sparse convex optimization problem. The resulting algorithm that we propose, SequentialAttention++, advances the state of the art in large-scale neural network block-wise pruning tasks on the ImageNet and Criteo datasets.
Greedy PIG: Adaptive Integrated Gradients
Nov 10, 2023



Deep learning has become the standard approach for most machine learning tasks. While its impact is undeniable, interpreting the predictions of deep learning models from a human perspective remains a challenge. In contrast to model training, model interpretability is harder to quantify and pose as an explicit optimization problem. Inspired by the AUC softmax information curve (AUC SIC) metric for evaluating feature attribution methods, we propose a unified discrete optimization framework for feature attribution and feature selection based on subset selection. This leads to a natural adaptive generalization of the path integrated gradients (PIG) method for feature attribution, which we call Greedy PIG. We demonstrate the success of Greedy PIG on a wide variety of tasks, including image feature attribution, graph compression/explanation, and post-hoc feature selection on tabular data. Our results show that introducing adaptivity is a powerful and versatile method for making attribution methods more powerful.
Performance of $\ell_1$ Regularization for Sparse Convex Optimization
Jul 14, 2023Despite widespread adoption in practice, guarantees for the LASSO and Group LASSO are strikingly lacking in settings beyond statistical problems, and these algorithms are usually considered to be a heuristic in the context of sparse convex optimization on deterministic inputs. We give the first recovery guarantees for the Group LASSO for sparse convex optimization with vector-valued features. We show that if a sufficiently large Group LASSO regularization is applied when minimizing a strictly convex function $l$, then the minimizer is a sparse vector supported on vector-valued features with the largest $\ell_2$ norm of the gradient. Thus, repeating this procedure selects the same set of features as the Orthogonal Matching Pursuit algorithm, which admits recovery guarantees for any function $l$ with restricted strong convexity and smoothness via weak submodularity arguments. This answers open questions of Tibshirani et al. and Yasuda et al. Our result is the first to theoretically explain the empirical success of the Group LASSO for convex functions under general input instances assuming only restricted strong convexity and smoothness. Our result also generalizes provable guarantees for the Sequential Attention algorithm, which is a feature selection algorithm inspired by the attention mechanism proposed by Yasuda et al. As an application of our result, we give new results for the column subset selection problem, which is well-studied when the loss is the Frobenius norm or other entrywise matrix losses. We give the first result for general loss functions for this problem that requires only restricted strong convexity and smoothness.
Gradient Descent Converges Linearly for Logistic Regression on Separable Data
Jun 26, 2023



We show that running gradient descent with variable learning rate guarantees loss $f(x) \leq 1.1 \cdot f(x^*) + \epsilon$ for the logistic regression objective, where the error $\epsilon$ decays exponentially with the number of iterations and polynomially with the magnitude of the entries of an arbitrary fixed solution $x^*$. This is in contrast to the common intuition that the absence of strong convexity precludes linear convergence of first-order methods, and highlights the importance of variable learning rates for gradient descent. We also apply our ideas to sparse logistic regression, where they lead to an exponential improvement of the sparsity-error tradeoff.
Iterative Hard Thresholding with Adaptive Regularization: Sparser Solutions Without Sacrificing Runtime
Apr 11, 2022
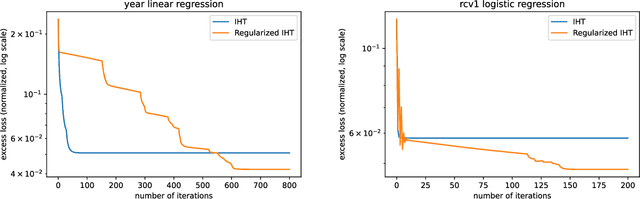
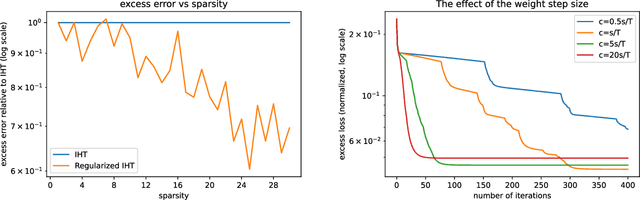
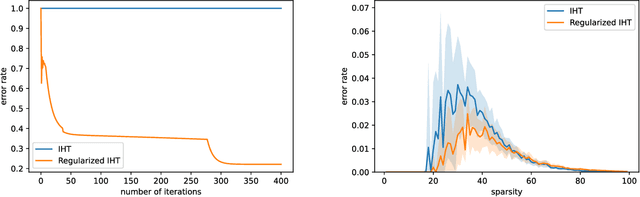
We propose a simple modification to the iterative hard thresholding (IHT) algorithm, which recovers asymptotically sparser solutions as a function of the condition number. When aiming to minimize a convex function $f(x)$ with condition number $\kappa$ subject to $x$ being an $s$-sparse vector, the standard IHT guarantee is a solution with relaxed sparsity $O(s\kappa^2)$, while our proposed algorithm, regularized IHT, returns a solution with sparsity $O(s\kappa)$. Our algorithm significantly improves over ARHT which also finds a solution of sparsity $O(s\kappa)$, as it does not require re-optimization in each iteration (and so is much faster), is deterministic, and does not require knowledge of the optimal solution value $f(x^*)$ or the optimal sparsity level $s$. Our main technical tool is an adaptive regularization framework, in which the algorithm progressively learns the weights of an $\ell_2$ regularization term that will allow convergence to sparser solutions. We also apply this framework to low rank optimization, where we achieve a similar improvement of the best known condition number dependence from $\kappa^2$ to $\kappa$.
Decomposable Submodular Function Minimization via Maximum Flow
Mar 05, 2021This paper bridges discrete and continuous optimization approaches for decomposable submodular function minimization, in both the standard and parametric settings. We provide improved running times for this problem by reducing it to a number of calls to a maximum flow oracle. When each function in the decomposition acts on $O(1)$ elements of the ground set $V$ and is polynomially bounded, our running time is up to polylogarithmic factors equal to that of solving maximum flow in a sparse graph with $O(\vert V \vert)$ vertices and polynomial integral capacities. We achieve this by providing a simple iterative method which can optimize to high precision any convex function defined on the submodular base polytope, provided we can efficiently minimize it on the base polytope corresponding to the cut function of a certain graph that we construct. We solve this minimization problem by lifting the solutions of a parametric cut problem, which we obtain via a new efficient combinatorial reduction to maximum flow. This reduction is of independent interest and implies some previously unknown bounds for the parametric minimum $s,t$-cut problem in multiple settings.
Local Search Algorithms for Rank-Constrained Convex Optimization
Jan 15, 2021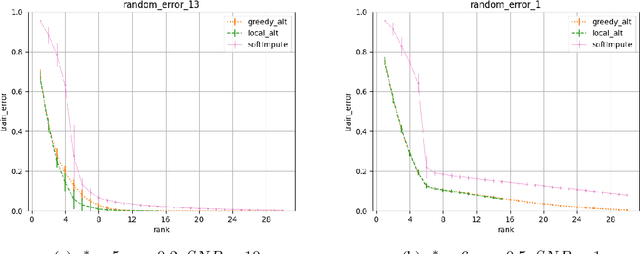


We propose greedy and local search algorithms for rank-constrained convex optimization, namely solving $\underset{\mathrm{rank}(A)\leq r^*}{\min}\, R(A)$ given a convex function $R:\mathbb{R}^{m\times n}\rightarrow \mathbb{R}$ and a parameter $r^*$. These algorithms consist of repeating two steps: (a) adding a new rank-1 matrix to $A$ and (b) enforcing the rank constraint on $A$. We refine and improve the theoretical analysis of Shalev-Shwartz et al. (2011), and show that if the rank-restricted condition number of $R$ is $\kappa$, a solution $A$ with rank $O(r^*\cdot \min\{\kappa \log \frac{R(\mathbf{0})-R(A^*)}{\epsilon}, \kappa^2\})$ and $R(A) \leq R(A^*) + \epsilon$ can be recovered, where $A^*$ is the optimal solution. This significantly generalizes associated results on sparse convex optimization, as well as rank-constrained convex optimization for smooth functions. We then introduce new practical variants of these algorithms that have superior runtime and recover better solutions in practice. We demonstrate the versatility of these methods on a wide range of applications involving matrix completion and robust principal component analysis.
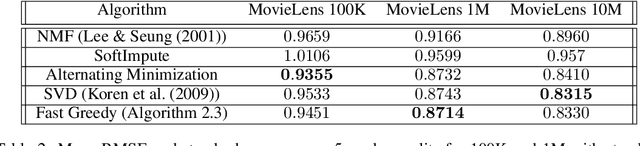
Sparse Convex Optimization via Adaptively Regularized Hard Thresholding
Jun 25, 2020
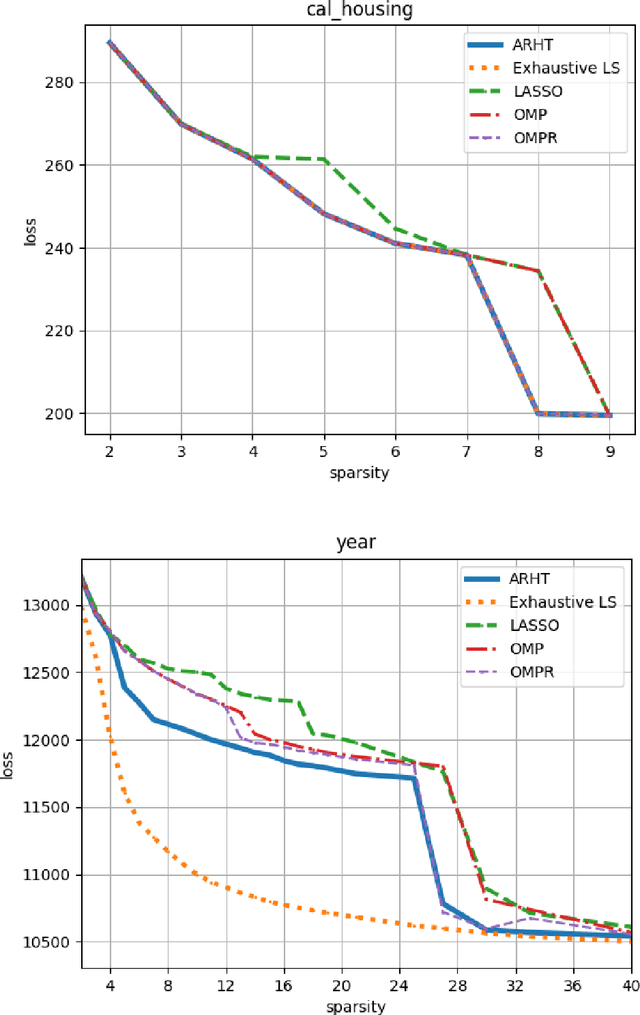
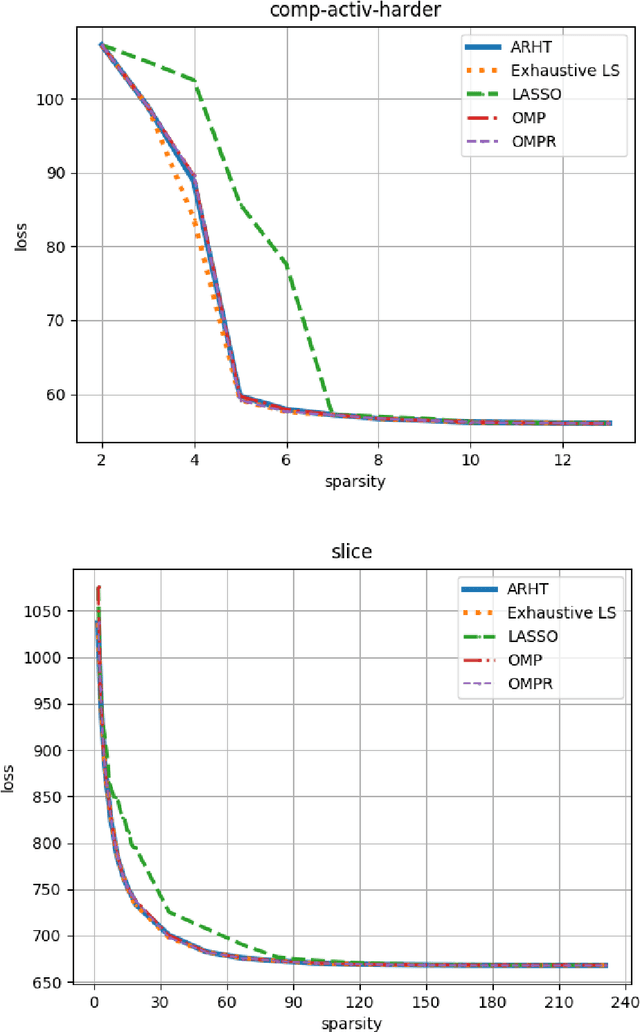
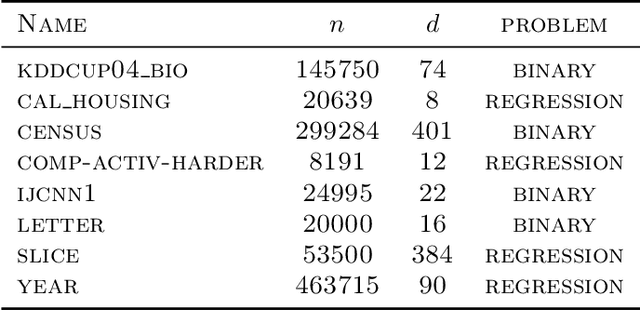
The goal of Sparse Convex Optimization is to optimize a convex function $f$ under a sparsity constraint $s\leq s^*\gamma$, where $s^*$ is the target number of non-zero entries in a feasible solution (sparsity) and $\gamma\geq 1$ is an approximation factor. There has been a lot of work to analyze the sparsity guarantees of various algorithms (LASSO, Orthogonal Matching Pursuit (OMP), Iterative Hard Thresholding (IHT)) in terms of the Restricted Condition Number $\kappa$. The best known algorithms guarantee to find an approximate solution of value $f(x^*)+\epsilon$ with the sparsity bound of $\gamma = O\left(\kappa\min\left\{\log \frac{f(x^0)-f(x^*)}{\epsilon}, \kappa\right\}\right)$, where $x^*$ is the target solution. We present a new Adaptively Regularized Hard Thresholding (ARHT) algorithm that makes significant progress on this problem by bringing the bound down to $\gamma=O(\kappa)$, which has been shown to be tight for a general class of algorithms including LASSO, OMP, and IHT. This is achieved without significant sacrifice in the runtime efficiency compared to the fastest known algorithms. We also provide a new analysis of OMP with Replacement (OMPR) for general $f$, under the condition $s > s^* \frac{\kappa^2}{4}$, which yields Compressed Sensing bounds under the Restricted Isometry Property (RIP). When compared to other Compressed Sensing approaches, it has the advantage of providing a strong tradeoff between the RIP condition and the solution sparsity, while working for any general function $f$ that meets the RIP condition.