 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GRASP: A novel benchmark for evaluating language GRounding And Situated Physics understanding in multimodal language models
Nov 15, 2023
This paper presents GRASP, a novel benchmark to evaluate the language grounding and physical understanding capabilities of video-based multimodal large language models (LLMs). This evaluation is accomplished via a two-tier approach leveraging Unity simulations. The initial level tests for language grounding by assessing a model's ability to relate simple textual descriptions with visual information. The second level evaluates the model's understanding of 'Intuitive Physics' principles, such as object permanence and continuity. In addition to releasing the benchmark, we use it to evaluate several state-of-the-art multimodal LLMs. Our evaluation reveals significant shortcomings in current models' language grounding and intuitive physics. These identified limitations underline the importance of benchmarks like GRASP to monitor the progress of future models in developing these competencies.
A Distributed Multi-Robot Framework for Exploration, Information Acquisition and Consensus
Oct 03, 2023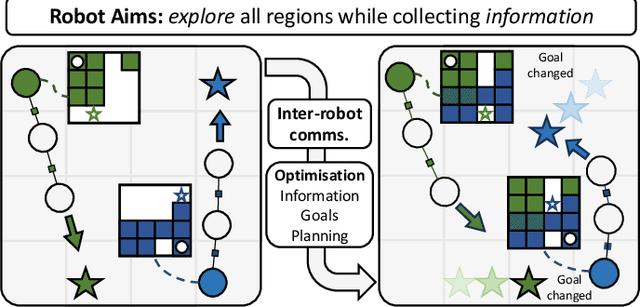
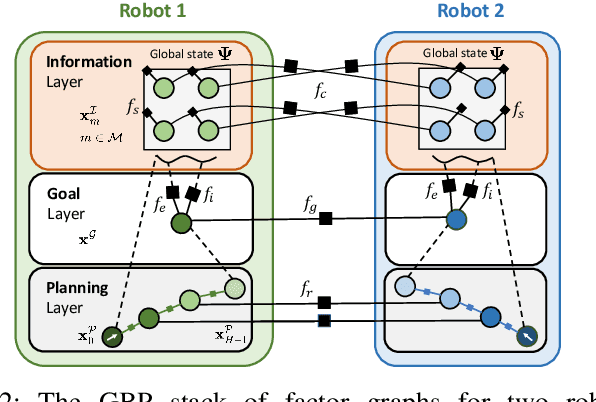
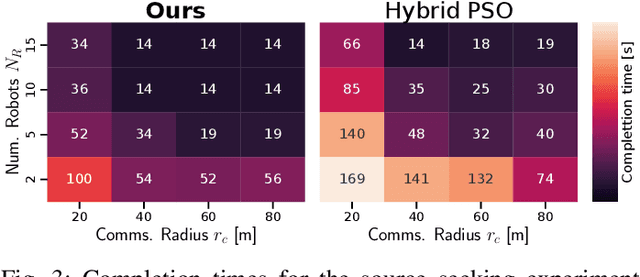

The distributed coordination of robot teams performing complex tasks is challenging to formulate. The different aspects of a complete task such as local planning for obstacle avoidance, global goal coordination and collaborative mapping are often solved separately, when clearly each of these should influence the others for the most efficient behaviour. In this paper we use the example application of distributed information acquisition as a robot team explores a large space to show that we can formulate the whole problem as a single factor graph with multiple connected layers representing each aspect. We use Gaussian Belief Propagation (GBP) as the inference mechanism, which permits parallel, on-demand or asynchronous computation for efficiency when different aspects are more or less important. This is the first time that a distributed GBP multi-robot solver has been proven to enable intelligent collaborative behaviour rather than just guiding robots to individual, selfish goals. We encourage the reader to view our demos at https://aalpatya.github.io/gbpstack
INSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis
Nov 17, 2023Synthesizing information from multiple data sources plays a crucial role in the practice of modern medicine. Current applications of artificial intelligence in medicine often focus on single-modality data due to a lack of publicly available, multimodal medical datasets. To address this limitation, we introduce INSPECT, which contains de-identified longitudinal records from a large cohort of patients at risk for pulmonary embolism (PE), along with ground truth labels for multiple outcomes. INSPECT contains data from 19,402 patients, including CT images, radiology report impression sections, and structured electronic health record (EHR) data (i.e. demographics, diagnoses, procedures, vitals, and medications). Using INSPECT, we develop and release a benchmark for evaluating several baseline modeling approaches on a variety of important PE related tasks. We evaluate image-only, EHR-only, and multimodal fusion models. Trained models and the de-identified dataset are made available for non-commercial use under a data use agreement. To the best of our knowledge, INSPECT is the largest multimodal dataset integrating 3D medical imaging and EHR for reproducible methods evaluation and research.
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
Nov 17, 2023Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
MPSeg : Multi-Phase strategy for coronary artery Segmentation
Nov 17, 2023Accurate segmentation of coronary arteries is a pivotal process in assessing cardiovascular diseases. However, the intricate structure of the cardiovascular system presents significant challenges for automatic segmentation, especially when utilizing methodologies like the SYNTAX Score, which relies extensively on detailed structural information for precise risk stratification. To address these difficulties and cater to this need, we present MPSeg, an innovative multi-phase strategy designed for coronary artery segmentation. Our approach specifically accommodates these structural complexities and adheres to the principles of the SYNTAX Score. Initially, our method segregates vessels into two categories based on their unique morphological characteristics: Left Coronary Artery (LCA) and Right Coronary Artery (RCA). Specialized ensemble models are then deployed for each category to execute the challenging segmentation task. Due to LCA's higher complexity over RCA, a refinement model is utilized to scrutinize and correct initial class predictions on segmented areas. Notably, our approach demonstrated exceptional effectiveness when evaluated in the Automatic Region-based Coronary Artery Disease diagnostics using x-ray angiography imagEs (ARCADE) Segmentation Detection Algorithm challenge at MICCAI 2023.
Extracting periodontitis diagnosis in clinical notes with RoBERTa and regular expression
Nov 17, 2023This study aimed to utilize text processing and natural language processing (NLP) models to mine clinical notes for the diagnosis of periodontitis and to evaluate the performance of a named entity recognition (NER) model on different regular expression (RE) methods. Two complexity levels of RE methods were used to extract and generate the training data. The SpaCy package and RoBERTa transformer models were used to build the NER model and evaluate its performance with the manual-labeled gold standards. The comparison of the RE methods with the gold standard showed that as the complexity increased in the RE algorithms, the F1 score increased from 0.3-0.4 to around 0.9. The NER models demonstrated excellent predictions, with the simple RE method showing 0.84-0.92 in the evaluation metrics, and the advanced and combined RE method demonstrating 0.95-0.99 in the evaluation. This study provided an example of the benefit of combining NER methods and NLP models in extracting target information from free-text to structured data and fulfilling the need for missing diagnoses from unstructured notes.
Visual Environment Assessment for Safe Autonomous Quadrotor Landing
Nov 17, 2023Autonomous identification and evaluation of safe landing zones are of paramount importance for ensuring the safety and effectiveness of aerial robots in the event of system failures, low battery, or the successful completion of specific tasks. In this paper, we present a novel approach for detection and assessment of potential landing sites for safe quadrotor landing. Our solution efficiently integrates 2D and 3D environmental information, eliminating the need for external aids such as GPS and computationally intensive elevation maps. The proposed pipeline combines semantic data derived from a Neural Network (NN), to extract environmental features, with geometric data obtained from a disparity map, to extract critical geometric attributes such as slope, flatness, and roughness. We define several cost metrics based on these attributes to evaluate safety, stability, and suitability of regions in the environments and identify the most suitable landing area. Our approach runs in real-time on quadrotors equipped with limited computational capabilities. Experimental results conducted in diverse environments demonstrate that the proposed method can effectively assess and identify suitable landing areas, enabling the safe and autonomous landing of a quadrotor.
Quantum-Assisted Simulation: A Framework for Designing Machine Learning Models in the Quantum Computing Domain
Nov 17, 2023Machine learning (ML) models are trained using historical data to classify new, unseen data. However, traditional computing resources often struggle to handle the immense amount of data, commonly known as Big Data, within a reasonable timeframe. Quantum computing (QC) provides a novel approach to information processing. Quantum algorithms have the potential to process classical data exponentially faster than classical computing. By mapping quantum machine learning (QML) algorithms into the quantum mechanical domain, we can potentially achieve exponential improvements in data processing speed, reduced resource requirements, and enhanced accuracy and efficiency. In this article, we delve into both the QC and ML fields, exploring the interplay of ideas between them, as well as the current capabilities and limitations of hardware. We investigate the history of quantum computing, examine existing QML algorithms, and aim to present a simplified procedure for setting up simulations of QML algorithms, making it accessible and understandable for readers. Furthermore, we conducted simulations on a dataset using both machine learning and quantum machine learning approaches. We then proceeded to compare their respective performances by utilizing a quantum simulator.
Personalized Jargon Identification for Enhanced Interdisciplinary Communication
Nov 16, 2023Scientific jargon can impede researchers when they read materials from other domains. Current methods of jargon identification mainly use corpus-level familiarity indicators (e.g., Simple Wikipedia represents plain language). However, researchers' familiarity of a term can vary greatly based on their own background. We collect a dataset of over 10K term familiarity annotations from 11 computer science researchers for terms drawn from 100 paper abstracts. Analysis of this data reveals that jargon familiarity and information needs vary widely across annotators, even within the same sub-domain (e.g., NLP). We investigate features representing individual, sub-domain, and domain knowledge to predict individual jargon familiarity. We compare supervised and prompt-based approaches, finding that prompt-based methods including personal publications yields the highest accuracy, though zero-shot prompting provides a strong baseline. This research offers insight into features and methods to integrate personal data into scientific jargon identification.
Robust Contrastive Learning With Theory Guarantee
Nov 16, 2023Contrastive learning (CL) is a self-supervised training paradigm that allows us to extract meaningful features without any label information. A typical CL framework is divided into two phases, where it first tries to learn the features from unlabelled data, and then uses those features to train a linear classifier with the labeled data. While a fair amount of existing theoretical works have analyzed how the unsupervised loss in the first phase can support the supervised loss in the second phase, none has examined the connection between the unsupervised loss and the robust supervised loss, which can shed light on how to construct an effective unsupervised loss for the first phase of CL. To fill this gap, our work develops rigorous theories to dissect and identify which components in the unsupervised loss can help improve the robust supervised loss and conduct proper experiments to verify our findings.