 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajGenAgent: A Hierarchical LLM Agent for Human Mobility Trajectory Generation
Jun 10, 2026Human mobility data is important for transportation, urban planning, and epidemic control, but large-scale trajectory collection is often costly and privacy-constrained, motivating realistic synthetic trajectory generation. Existing LLM-based generators typically rely on either prompt engineering, which preserves zero-shot reasoning but lacks fine-grained spatiotemporal grounding, or trajectory-level fine-tuning, which improves statistical precision but incurs substantial computational cost and may weaken general reasoning. We propose TrajGenAgent, a semantic-aware hierarchical LLM-agent framework for human mobility trajectory generation without model fine-tuning. TrajGenAgent uses a two-stage orchestrator-worker design: an LLM first synthesizes an individual- and weekday-conditioned activity chain from historical evidence via in-context learning, and a deterministic workflow then grounds each activity into a complete visit using personalized POI retrieval, distance-aware location selection, kinematics-aware travel-time propagation, and LLM-based duration estimation. To evaluate realism beyond aggregate spatiotemporal statistics, we introduce an anomaly-detection-based evaluation framework using two complementary detectors to assess behavioral and semantic plausibility. Experiments on benchmark and large-scale simulation datasets show that TrajGenAgent improves spatiotemporal fidelity, semantic coherence, and individual-specific behavioral realism over representative neural and LLM-based baselines, while avoiding parameter updates.
GeoGNN: Time Series Geo-Localization using Two-Tower Graph Neural Networks
Jun 06, 2026This paper investigates a novel concept of time series geolocalization, where the goal is to infer the geographic origin of each raw time series. Successful geolocalization can provide spatial context to time series, enabling downstream location-aware applications. We formalize the problem, adapt core ideas from image geolocalization to establish strong baselines, and propose GeoGNN, a two-tower architecture. During training, GeoGNN's spatial tower learns embeddings of geographic cell candidates by leveraging the geographic adjacency graph, while the temporal tower extracts informative representations from time series. During inference, each temporal representation is matched against candidate geographic embeddings using dot-product similarity, combined with an auxiliary classification head, to predict the time series' associated geographic origin. Experiments on large-scale, countrywide electricity-consumption datasets demonstrate that GeoGNN achieves the best performance across datasets and enhances both fine- and coarse-grained geolocalization accuracy by ~27% on average.
Automated Membership Inference Attacks: Discovering MIA Signal Computations using LLM Agents
Mar 19, 2026Membership inference attacks (MIAs), which enable adversaries to determine whether specific data points were part of a model's training dataset, have emerged as an important framework to understand, assess, and quantify the potential information leakage associated with machine learning systems. Designing effective MIAs is a challenging task that usually requires extensive manual exploration of model behaviors to identify potential vulnerabilities. In this paper, we introduce AutoMIA -- a novel framework that leverages large language model (LLM) agents to automate the design and implementation of new MIA signal computations. By utilizing LLM agents, we can systematically explore a vast space of potential attack strategies, enabling the discovery of novel strategies. Our experiments demonstrate AutoMIA can successfully discover new MIAs that are specifically tailored to user-configured target model and dataset, resulting in improvements of up to 0.18 in absolute AUC over existing MIAs. This work provides the first demonstration that LLM agents can serve as an effective and scalable paradigm for designing and implementing MIAs with SOTA performance, opening up new avenues for future exploration.
Selective Sinkhorn Routing for Improved Sparse Mixture of Experts
Nov 12, 2025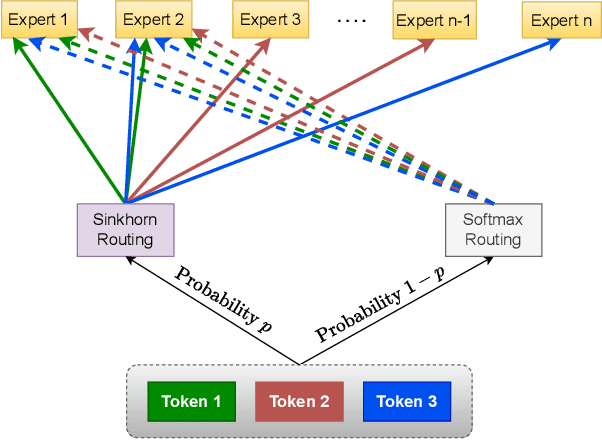
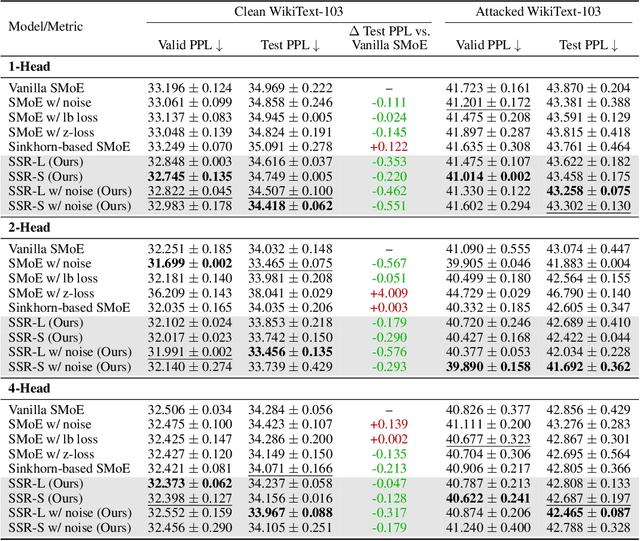
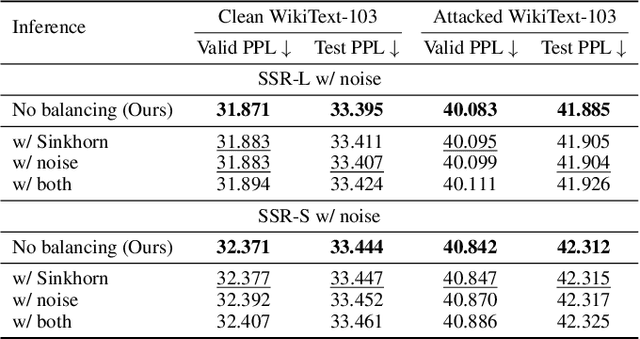
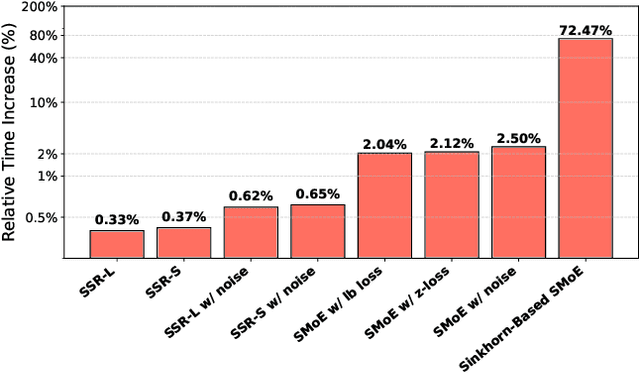
Sparse Mixture-of-Experts (SMoE) has gained prominence as a scalable and computationally efficient architecture, enabling significant growth in model capacity without incurring additional inference costs. However, existing SMoE models often rely on auxiliary losses (e.g., z-loss, load balancing) and additional trainable parameters (e.g., noisy gating) to encourage expert diversity, leading to objective misalignment and increased model complexity. Moreover, existing Sinkhorn-based methods suffer from significant training overhead due to their heavy reliance on the computationally expensive Sinkhorn algorithm. In this work, we formulate token-to-expert assignment as an optimal transport problem, incorporating constraints to ensure balanced expert utilization. We demonstrate that introducing a minimal degree of optimal transport-based routing enhances SMoE performance without requiring auxiliary balancing losses. Unlike previous methods, our approach derives gating scores directly from the transport map, enabling more effective token-to-expert balancing, supported by both theoretical analysis and empirical results. Building on these insights, we propose Selective Sinkhorn Routing (SSR), a routing mechanism that replaces auxiliary loss with lightweight Sinkhorn-based routing. SSR promotes balanced token assignments while preserving flexibility in expert selection. Across both language modeling and image classification tasks, SSR achieves faster training, higher accuracy, and greater robustness to input corruption.
Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Mar 03, 2025Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model's dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
Tokens for Learning, Tokens for Unlearning: Mitigating Membership Inference Attacks in Large Language Models via Dual-Purpose Training
Feb 27, 2025



Large language models (LLMs) have become the backbone of modern natural language processing but pose privacy concerns about leaking sensitive training data. Membership inference attacks (MIAs), which aim to infer whether a sample is included in a model's training dataset, can serve as a foundation for broader privacy threats. Existing defenses designed for traditional classification models do not account for the sequential nature of text data. As a result, they either require significant computational resources or fail to effectively mitigate privacy risks in LLMs. In this work, we propose a lightweight yet effective empirical privacy defense for protecting training data of language modeling by leveraging the token-specific characteristics. By analyzing token dynamics during training, we propose a token selection strategy that categorizes tokens into hard tokens for learning and memorized tokens for unlearning. Subsequently, our training-phase defense optimizes a novel dual-purpose token-level loss to achieve a Pareto-optimal balance between utility and privacy. Extensive experiments demonstrate that our approach not only provides strong protection against MIAs but also improves language modeling performance by around 10\% across various LLM architectures and datasets compared to the baselines.
SNOOPI: Supercharged One-step Diffusion Distillation with Proper Guidance
Dec 03, 2024



Recent approaches have yielded promising results in distilling multi-step text-to-image diffusion models into one-step ones. The state-of-the-art efficient distillation technique, i.e., SwiftBrushv2 (SBv2), even surpasses the teacher model's performance with limited resources. However, our study reveals its instability when handling different diffusion model backbones due to using a fixed guidance scale within the Variational Score Distillation (VSD) loss. Another weakness of the existing one-step diffusion models is the missing support for negative prompt guidance, which is crucial in practical image generation. This paper presents SNOOPI, a novel framework designed to address these limitations by enhancing the guidance in one-step diffusion models during both training and inference. First, we effectively enhance training stability through Proper Guidance-SwiftBrush (PG-SB), which employs a random-scale classifier-free guidance approach. By varying the guidance scale of both teacher models, we broaden their output distributions, resulting in a more robust VSD loss that enables SB to perform effectively across diverse backbones while maintaining competitive performance. Second, we propose a training-free method called Negative-Away Steer Attention (NASA), which integrates negative prompts into one-step diffusion models via cross-attention to suppress undesired elements in generated images. Our experimental results show that our proposed methods significantly improve baseline models across various metrics. Remarkably, we achieve an HPSv2 score of 31.08, setting a new state-of-the-art benchmark for one-step diffusion models.
Dual-Model Defense: Safeguarding Diffusion Models from Membership Inference Attacks through Disjoint Data Splitting
Oct 22, 2024



Diffusion models have demonstrated remarkable capabilities in image synthesis, but their recently proven vulnerability to Membership Inference Attacks (MIAs) poses a critical privacy concern. This paper introduces two novel and efficient approaches (DualMD and DistillMD) to protect diffusion models against MIAs while maintaining high utility. Both methods are based on training two separate diffusion models on disjoint subsets of the original dataset. DualMD then employs a private inference pipeline that utilizes both models. This strategy significantly reduces the risk of black-box MIAs by limiting the information any single model contains about individual training samples. The dual models can also generate "soft targets" to train a private student model in DistillMD, enhancing privacy guarantees against all types of MIAs. Extensive evaluations of DualMD and DistillMD against state-of-the-art MIAs across various datasets in white-box and black-box settings demonstrate their effectiveness in substantially reducing MIA success rates while preserving competitive image generation performance. Notably, our experiments reveal that DistillMD not only defends against MIAs but also mitigates model memorization, indicating that both vulnerabilities stem from overfitting and can be addressed simultaneously with our unified approach.
Geo-Llama: Leveraging LLMs for Human Mobility Trajectory Generation with Spatiotemporal Constraints
Aug 25, 2024



Simulating human mobility data is essential for various application domains, including transportation, urban planning, and epidemic control, since real data are often inaccessible to researchers due to expensive costs and privacy issues. Several existing deep generative solutions propose learning from real trajectories to generate synthetic ones. Despite the progress, most of them suffer from training stability issues and scale poorly with growing data size. More importantly, they generally lack control mechanisms to steer the generated trajectories based on spatiotemporal constraints such as fixing specific visits. To address such limitations, we formally define the controlled trajectory generation problem with spatiotemporal constraints and propose Geo-Llama. This novel LLM-inspired framework enforces explicit visit constraints in a contextually coherent way. It fine-tunes pre-trained LLMs on trajectories with a visit-wise permutation strategy where each visit corresponds to a time and location. This enables the model to capture the spatiotemporal patterns regardless of visit orders and allows flexible and in-context constraint integration through prompts during generation. Extensive experiments on real-world and synthetic datasets validate the effectiveness of Geo-Llama, demonstrating its versatility and robustness in handling a broad range of constraints to generate more realistic trajectories compared to existing methods.
On Inference Stability for Diffusion Models
Dec 19, 2023Denoising Probabilistic Models (DPMs) represent an emerging domain of generative models that excel in generating diverse and high-quality images. However, most current training methods for DPMs often neglect the correlation between timesteps, limiting the model's performance in generating images effectively. Notably, we theoretically point out that this issue can be caused by the cumulative estimation gap between the predicted and the actual trajectory. To minimize that gap, we propose a novel \textit{sequence-aware} loss that aims to reduce the estimation gap to enhance the sampling quality. Furthermore, we theoretically show that our proposed loss function is a tighter upper bound of the estimation loss in comparison with the conventional loss in DPMs. Experimental results on several benchmark datasets including CIFAR10, CelebA, and CelebA-HQ consistently show a remarkable improvement of our proposed method regarding the image generalization quality measured by FID and Inception Score compared to several DPM baselines. Our code and pre-trained checkpoints are available at \url{https://github.com/viettmab/SA-DPM}.