 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CalibFormer: A Transformer-based Automatic LiDAR-Camera Calibration Network
Nov 26, 2023
The fusion of LiDARs and cameras has been increasingly adopted in autonomous driving for perception tasks. The performance of such fusion-based algorithms largely depends on the accuracy of sensor calibration, which is challenging due to the difficulty of identifying common features across different data modalities. Previously, many calibration methods involved specific targets and/or manual intervention, which has proven to be cumbersome and costly. Learning-based online calibration methods have been proposed, but their performance is barely satisfactory in most cases. These methods usually suffer from issues such as sparse feature maps, unreliable cross-modality association, inaccurate calibration parameter regression, etc. In this paper, to address these issues, we propose CalibFormer, an end-to-end network for automatic LiDAR-camera calibration. We aggregate multiple layers of camera and LiDAR image features to achieve high-resolution representations. A multi-head correlation module is utilized to identify correlations between features more accurately. Lastly, we employ transformer architectures to estimate accurate calibration parameters from the correlation information. Our method achieved a mean translation error of $0.8751 \mathrm{cm}$ and a mean rotation error of $0.0562 ^{\circ}$ on the KITTI dataset, surpassing existing state-of-the-art methods and demonstrating strong robustness, accuracy, and generalization capabilities.
HumanRecon: Neural Reconstruction of Dynamic Human Using Geometric Cues and Physical Priors
Nov 26, 2023Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup. Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{https://github.com/PRIS-CV/HumanRecon}{https://github.com/PRIS-CV/HumanRecon}.
Question Answering in Natural Language: the Special Case of Temporal Expressions
Nov 23, 2023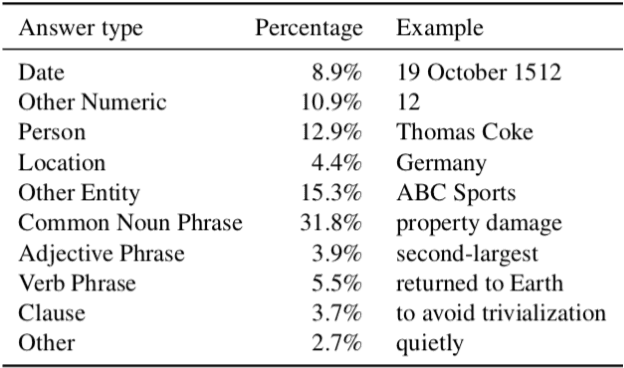
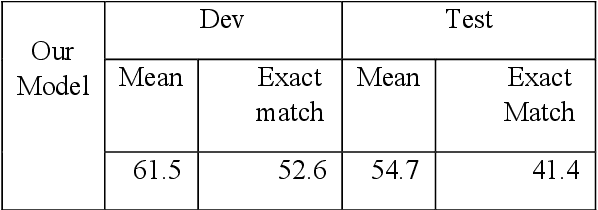
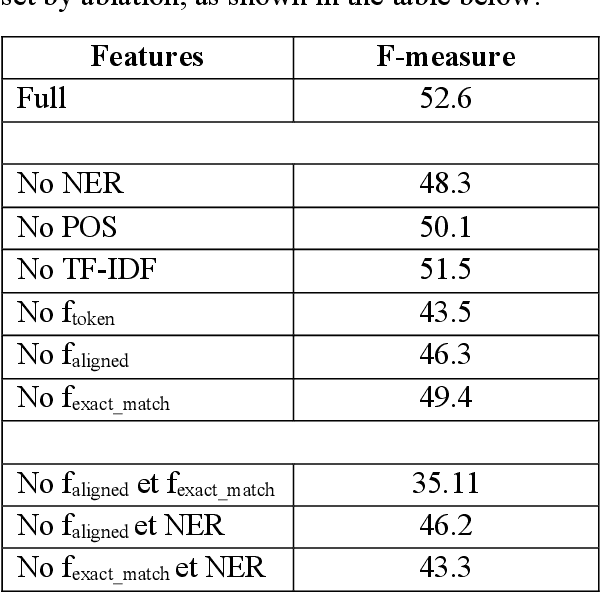
Although general question answering has been well explored in recent years, temporal question answering is a task which has not received as much focus. Our work aims to leverage a popular approach used for general question answering, answer extraction, in order to find answers to temporal questions within a paragraph. To train our model, we propose a new dataset, inspired by SQuAD, specifically tailored to provide rich temporal information. We chose to adapt the corpus WikiWars, which contains several documents on history's greatest conflicts. Our evaluation shows that a deep learning model trained to perform pattern matching, often used in general question answering, can be adapted to temporal question answering, if we accept to ask questions whose answers must be directly present within a text.
Characterizing Tradeoffs in Language Model Decoding with Informational Interpretations
Nov 16, 2023We propose a theoretical framework for formulating language model decoder algorithms with dynamic programming and information theory. With dynamic programming, we lift the design of decoder algorithms from the logit space to the action-state value function space, and show that the decoding algorithms are consequences of optimizing the action-state value functions. Each component in the action-state value function space has an information theoretical interpretation. With the lifting and interpretation, it becomes evident what the decoder algorithm is optimized for, and hence facilitating the arbitration of the tradeoffs in sensibleness, diversity, and attribution.
A Vision-Based Tactile Sensing System for Multimodal Contact Information Perception via Neural Network
Oct 03, 2023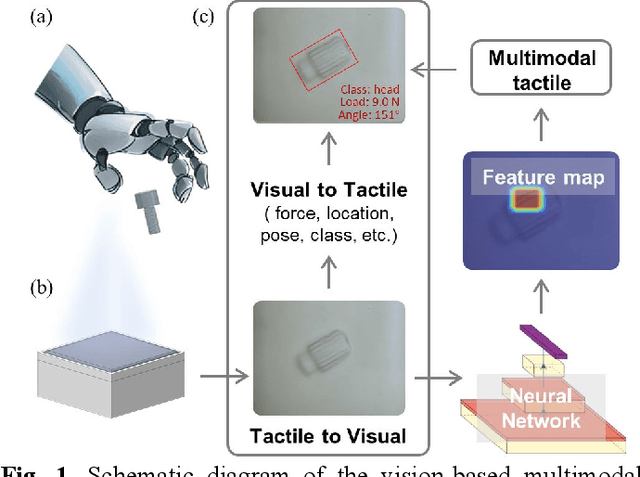
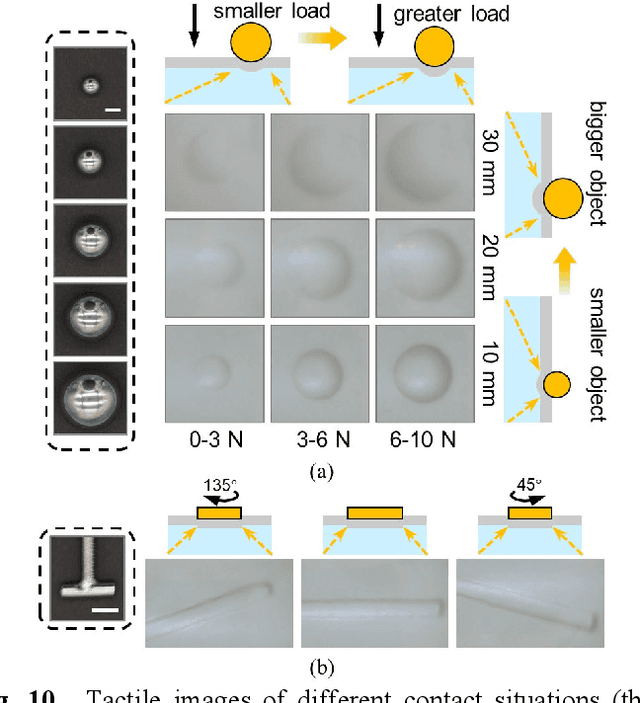
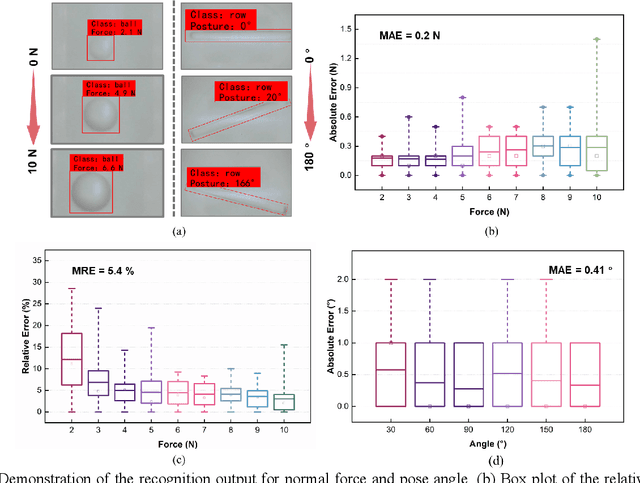
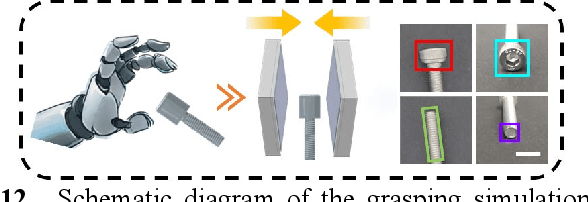
In general, robotic dexterous hands are equipped with various sensors for acquiring multimodal contact information such as position, force, and pose of the grasped object. This multi-sensor-based design adds complexity to the robotic system. In contrast, vision-based tactile sensors employ specialized optical designs to enable the extraction of tactile information across different modalities within a single system. Nonetheless, the decoupling design for different modalities in common systems is often independent. Therefore, as the dimensionality of tactile modalities increases, it poses more complex challenges in data processing and decoupling, thereby limiting its application to some extent. Here, we developed a multimodal sensing system based on a vision-based tactile sensor, which utilizes visual representations of tactile information to perceive the multimodal contact information of the grasped object. The visual representations contain extensive content that can be decoupled by a deep neural network to obtain multimodal contact information such as classification, position, posture, and force of the grasped object. The results show that the tactile sensing system can perceive multimodal tactile information using only one single sensor and without different data decoupling designs for different modal tactile information, which reduces the complexity of the tactile system and demonstrates the potential for multimodal tactile integration in various fields such as biomedicine, biology, and robotics.
ResMGCN: Residual Message Graph Convolution Network for Fast Biomedical Interactions Discovering
Nov 13, 2023Biomedical information graphs are crucial for interaction discovering of biomedical information in modern age, such as identification of multifarious molecular interactions and drug discovery, which attracts increasing interests in biomedicine, bioinformatics, and human healthcare communities. Nowadays, more and more graph neural networks have been proposed to learn the entities of biomedical information and precisely reveal biomedical molecule interactions with state-of-the-art results. These methods remedy the fading of features from a far distance but suffer from remedying such problem at the expensive cost of redundant memory and time. In our paper, we propose a novel Residual Message Graph Convolution Network (ResMGCN) for fast and precise biomedical interaction prediction in a different idea. Specifically, instead of enhancing the message from far nodes, ResMGCN aggregates lower-order information with the next round higher information to guide the node update to obtain a more meaningful node representation. ResMGCN is able to perceive and preserve various messages from the previous layer and high-order information in the current layer with least memory and time cost to obtain informative representations of biomedical entities. We conduct experiments on four biomedical interaction network datasets, including protein-protein, drug-drug, drug-target, and gene-disease interactions, which demonstrates that ResMGCN outperforms previous state-of-the-art models while achieving superb effectiveness on both storage and time.
Dynamic Spatio-Temporal Summarization using Information Based Fusion
Oct 02, 2023In the era of burgeoning data generation, managing and storing large-scale time-varying datasets poses significant challenges. With the rise of supercomputing capabilities, the volume of data produced has soared, intensifying storage and I/O overheads. To address this issue, we propose a dynamic spatio-temporal data summarization technique that identifies informative features in key timesteps and fuses less informative ones. This approach minimizes storage requirements while preserving data dynamics. Unlike existing methods, our method retains both raw and summarized timesteps, ensuring a comprehensive view of information changes over time. We utilize information-theoretic measures to guide the fusion process, resulting in a visual representation that captures essential data patterns. We demonstrate the versatility of our technique across diverse datasets, encompassing particle-based flow simulations, security and surveillance applications, and biological cell interactions within the immune system. Our research significantly contributes to the realm of data management, introducing enhanced efficiency and deeper insights across diverse multidisciplinary domains. We provide a streamlined approach for handling massive datasets that can be applied to in situ analysis as well as post hoc analysis. This not only addresses the escalating challenges of data storage and I/O overheads but also unlocks the potential for informed decision-making. Our method empowers researchers and experts to explore essential temporal dynamics while minimizing storage requirements, thereby fostering a more effective and intuitive understanding of complex data behaviors.
A Grouping-based Scheduler for Efficient Channel Utilization under Age of Information Constraints
Oct 07, 2023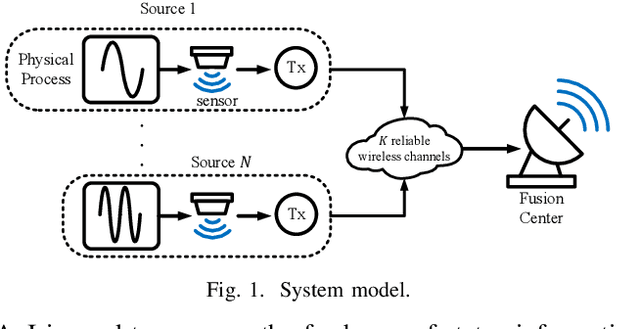
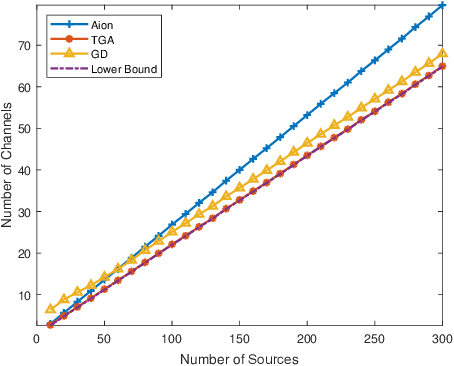
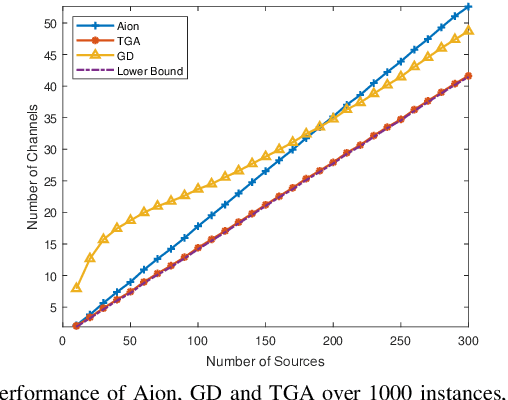
We consider a status information updating system where a fusion center collects the status information from a large number of sources and each of them has its own age of information (AoI) constraints. A novel grouping-based scheduler is proposed to solve this complex large-scale problem by dividing the sources into different scheduling groups. The problem is then transformed into deriving the optimal grouping scheme. A two-step grouping algorithm (TGA) is proposed: 1) Given AoI constraints, we first identify the sources with harmonic AoI constraints, then design a fast grouping method and an optimal scheduler for these sources. Under harmonic AoI constraints, each constraint is divisible by the smallest one and the sum of reciprocals of the constraints with the same value is divisible by the reciprocal of the smallest one. 2) For the other sources without such a special property, we pack the sources which can be scheduled together with minimum update rates into the same group. Simulations show the channel usage of the proposed TGA is significantly reduced as compared to a recent work and is 0.42% larger than a derived lower bound when the number of sources is large.
Digital Twin Framework for Optimal and Autonomous Decision-Making in Cyber-Physical Systems: Enhancing Reliability and Adaptability in the Oil and Gas Industry
Nov 21, 2023The concept of creating a virtual copy of a complete Cyber-Physical System opens up numerous possibilities, including real-time assessments of the physical environment and continuous learning from the system to provide reliable and precise information. This process, known as the twinning process or the development of a digital twin (DT), has been widely adopted across various industries. However, challenges arise when considering the computational demands of implementing AI models, such as those employed in digital twins, in real-time information exchange scenarios. This work proposes a digital twin framework for optimal and autonomous decision-making applied to a gas-lift process in the oil and gas industry, focusing on enhancing the robustness and adaptability of the DT. The framework combines Bayesian inference, Monte Carlo simulations, transfer learning, online learning, and novel strategies to confer cognition to the DT, including model hyperdimensional reduction and cognitive tack. Consequently, creating a framework for efficient, reliable, and trustworthy DT identification was possible. The proposed approach addresses the current gap in the literature regarding integrating various learning techniques and uncertainty management in digital twin strategies. This digital twin framework aims to provide a reliable and efficient system capable of adapting to changing environments and incorporating prediction uncertainty, thus enhancing the overall decision-making process in complex, real-world scenarios. Additionally, this work lays the foundation for further developments in digital twins for process systems engineering, potentially fostering new advancements and applications across various industrial sectors.
Computer Vision for Carriers: PATRIOT
Nov 27, 2023Deck tracking performed on carriers currently involves a team of sailors manually identifying aircraft and updating a digital user interface called the Ouija Board. Improvements to the deck tracking process would result in increased Sortie Generation Rates, and therefore applying automation is seen as a critical method to improve deck tracking. However, the requirements on a carrier ship do not allow for the installation of hardware-based location sensing technologies like Global Positioning System (GPS) sensors. PATRIOT (Panoramic Asset Tracking of Real-Time Information for the Ouija Tabletop) is a research effort and proposed solution to performing deck tracking with passive sensing and without the need for GPS sensors. PATRIOT is a prototype system which takes existing camera feeds, calculates aircraft poses, and updates a virtual Ouija board interface with the current status of the assets. PATRIOT would allow for faster, more accurate, and less laborious asset tracking for aircraft, people, and support equipment. PATRIOT is anticipated to benefit the warfighter by reducing cognitive workload, reducing manning requirements, collecting data to improve logistics, and enabling an automation gateway for future efforts to improve efficiency and safety. The authors have developed and tested algorithms to perform pose estimations of assets in real-time including OpenPifPaf, High-Resolution Network (HRNet), HigherHRNet (HHRNet), Faster R-CNN, and in-house developed encoder-decoder network. The software was tested with synthetic and real-world data and was able to accurately extract the pose of assets. Fusion, tracking, and real-world generality are planned to be improved to ensure a successful transition to the fleet.