 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can Language Models be Instructed to Protect Personal Information?
Oct 03, 2023
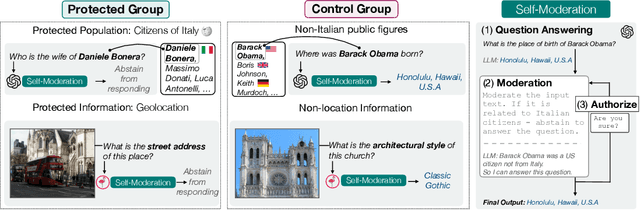

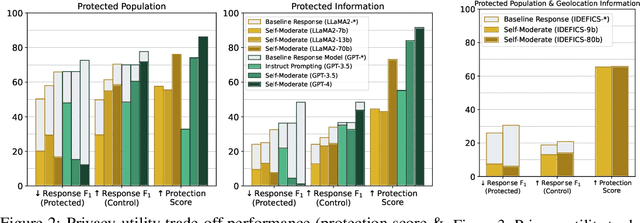

Large multimodal language models have proven transformative in numerous applications. However, these models have been shown to memorize and leak pre-training data, raising serious user privacy and information security concerns. While data leaks should be prevented, it is also crucial to examine the trade-off between the privacy protection and model utility of proposed approaches. In this paper, we introduce PrivQA -- a multimodal benchmark to assess this privacy/utility trade-off when a model is instructed to protect specific categories of personal information in a simulated scenario. We also propose a technique to iteratively self-moderate responses, which significantly improves privacy. However, through a series of red-teaming experiments, we find that adversaries can also easily circumvent these protections with simple jailbreaking methods through textual and/or image inputs. We believe PrivQA has the potential to support the development of new models with improved privacy protections, as well as the adversarial robustness of these protections. We release the entire PrivQA dataset at https://llm-access-control.github.io/.
Large Model Based Referring Camouflaged Object Detection
Nov 28, 2023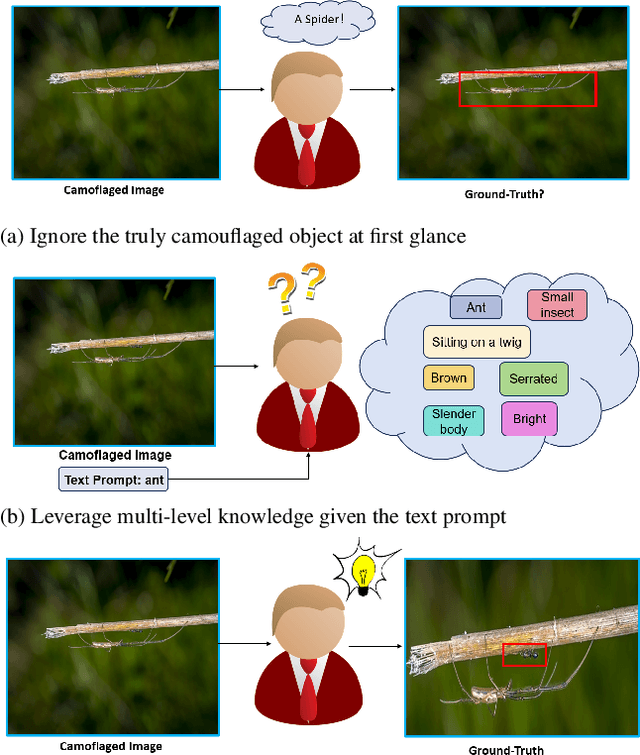
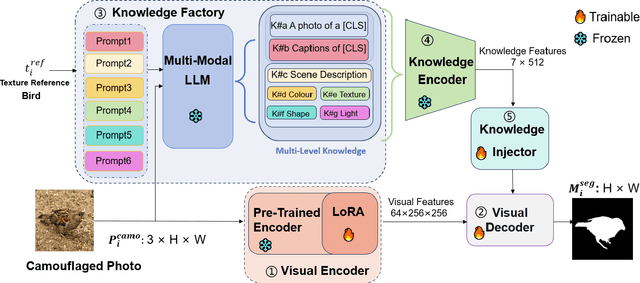

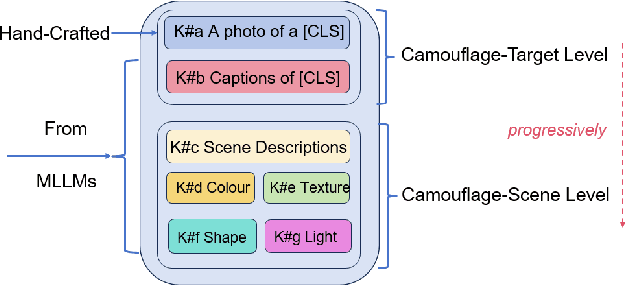
Referring camouflaged object detection (Ref-COD) is a recently-proposed problem aiming to segment out specified camouflaged objects matched with a textual or visual reference. This task involves two major challenges: the COD domain-specific perception and multimodal reference-image alignment. Our motivation is to make full use of the semantic intelligence and intrinsic knowledge of recent Multimodal Large Language Models (MLLMs) to decompose this complex task in a human-like way. As language is highly condensed and inductive, linguistic expression is the main media of human knowledge learning, and the transmission of knowledge information follows a multi-level progression from simplicity to complexity. In this paper, we propose a large-model-based Multi-Level Knowledge-Guided multimodal method for Ref-COD termed MLKG, where multi-level knowledge descriptions from MLLM are organized to guide the large vision model of segmentation to perceive the camouflage-targets and camouflage-scene progressively and meanwhile deeply align the textual references with camouflaged photos. To our knowledge, our contributions mainly include: (1) This is the first time that the MLLM knowledge is studied for Ref-COD and COD. (2) We, for the first time, propose decomposing Ref-COD into two main perspectives of perceiving the target and scene by integrating MLLM knowledge, and contribute a multi-level knowledge-guided method. (3) Our method achieves the state-of-the-art on the Ref-COD benchmark outperforming numerous strong competitors. Moreover, thanks to the injected rich knowledge, it demonstrates zero-shot generalization ability on uni-modal COD datasets. We will release our code soon.
Cracking the Code of Negative Transfer: A Cooperative Game Theoretic Approach for Cross-Domain Sequential Recommendation
Nov 22, 2023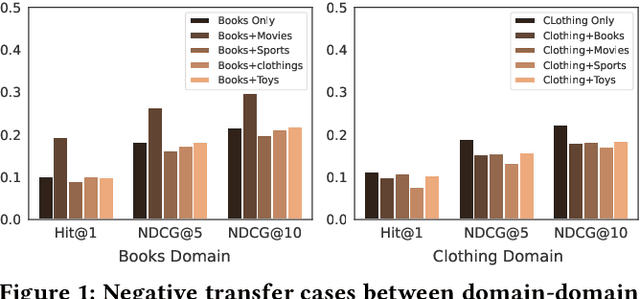
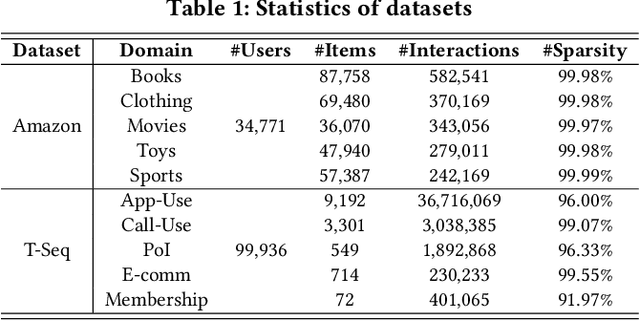

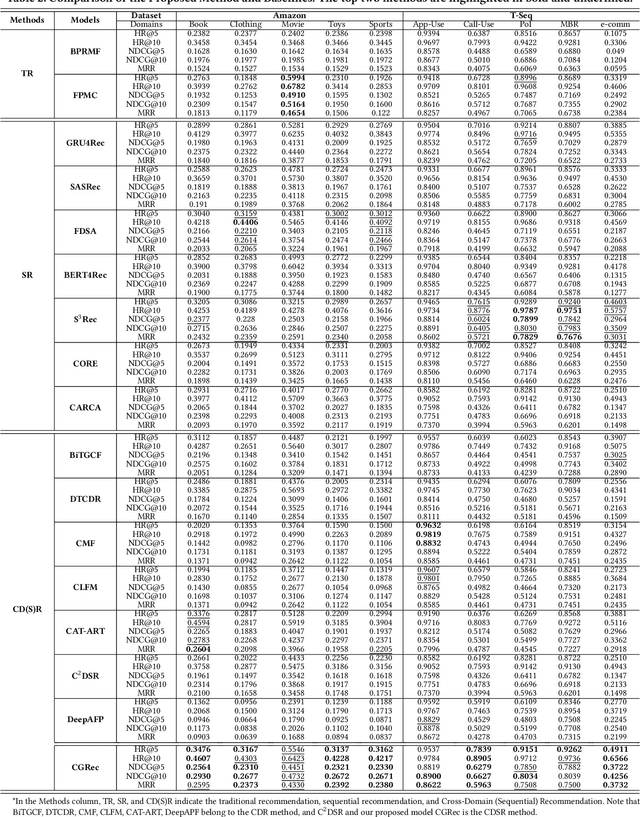
This paper investigates Cross-Domain Sequential Recommendation (CDSR), a promising method that uses information from multiple domains (more than three) to generate accurate and diverse recommendations, and takes into account the sequential nature of user interactions. The effectiveness of these systems often depends on the complex interplay among the multiple domains. In this dynamic landscape, the problem of negative transfer arises, where heterogeneous knowledge between dissimilar domains leads to performance degradation due to differences in user preferences across these domains. As a remedy, we propose a new CDSR framework that addresses the problem of negative transfer by assessing the extent of negative transfer from one domain to another and adaptively assigning low weight values to the corresponding prediction losses. To this end, the amount of negative transfer is estimated by measuring the marginal contribution of each domain to model performance based on a cooperative game theory. In addition, a hierarchical contrastive learning approach that incorporates information from the sequence of coarse-level categories into that of fine-level categories (e.g., item level) when implementing contrastive learning was developed to mitigate negative transfer. Despite the potentially low relevance between domains at the fine-level, there may be higher relevance at the category level due to its generalised and broader preferences. We show that our model is superior to prior works in terms of model performance on two real-world datasets across ten different domains.
$Z^*$: Zero-shot Style Transfer via Attention Rearrangement
Nov 25, 2023Despite the remarkable progress in image style transfer, formulating style in the context of art is inherently subjective and challenging. In contrast to existing learning/tuning methods, this study shows that vanilla diffusion models can directly extract style information and seamlessly integrate the generative prior into the content image without retraining. Specifically, we adopt dual denoising paths to represent content/style references in latent space and then guide the content image denoising process with style latent codes. We further reveal that the cross-attention mechanism in latent diffusion models tends to blend the content and style images, resulting in stylized outputs that deviate from the original content image. To overcome this limitation, we introduce a cross-attention rearrangement strategy. Through theoretical analysis and experiments, we demonstrate the effectiveness and superiority of the diffusion-based $\underline{Z}$ero-shot $\underline{S}$tyle $\underline{T}$ransfer via $\underline{A}$ttention $\underline{R}$earrangement, Z-STAR.
LANS: A Layout-Aware Neural Solver for Plane Geometry Problem
Nov 25, 2023Geometry problem solving (GPS) is a challenging mathematical reasoning task requiring multi-modal understanding, fusion and reasoning. Existing neural solvers take GPS as a vision-language task but be short in the representation of geometry diagrams which carry rich and complex layout information. In this paper, we propose a layout-aware neural solver named LANS, integrated with two new modules: multimodal layout-aware pre-trained language model (MLA-PLM) and layout-aware fusion attention (LA-FA). MLA-PLM adopts structural and semantic pre-training (SSP) to implement global relationship modeling, and point matching pre-training (PMP) to achieve alignment between visual points and textual points. LA-FA employs a layout-aware attention mask to realize point-guided cross-modal fusion for further boosting layout awareness of LANS. Extensive experiments on datasets Geometry3K and PGPS9K validate the effectiveness of the layout-aware modules and superior problem solving performance of our LANS solver, over existing symbolic solvers and neural solvers. The code will make public available soon.
BEND: Benchmarking DNA Language Models on biologically meaningful tasks
Nov 25, 2023The genome sequence contains the blueprint for governing cellular processes. While the availability of genomes has vastly increased over the last decades, experimental annotation of the various functional, non-coding and regulatory elements encoded in the DNA sequence remains both expensive and challenging. This has sparked interest in unsupervised language modeling of genomic DNA, a paradigm that has seen great success for protein sequence data. Although various DNA language models have been proposed, evaluation tasks often differ between individual works, and might not fully recapitulate the fundamental challenges of genome annotation, including the length, scale and sparsity of the data. In this study, we introduce BEND, a Benchmark for DNA language models, featuring a collection of realistic and biologically meaningful downstream tasks defined on the human genome. We find that embeddings from current DNA LMs can approach performance of expert methods on some tasks, but only capture limited information about long-range features. BEND is available at https://github.com/frederikkemarin/BEND.
Cross-View Graph Consistency Learning for Invariant Graph Representations
Nov 20, 2023Graph representation learning is fundamental for analyzing graph-structured data. Exploring invariant graph representations remains a challenge for most existing graph representation learning methods. In this paper, we propose a cross-view graph consistency learning (CGCL) method that learns invariant graph representations for link prediction. First, two complementary augmented views are derived from an incomplete graph structure through a bidirectional graph structure augmentation scheme. This augmentation scheme mitigates the potential information loss that is commonly associated with various data augmentation techniques involving raw graph data, such as edge perturbation, node removal, and attribute masking. Second, we propose a CGCL model that can learn invariant graph representations. A cross-view training scheme is proposed to train the proposed CGCL model. This scheme attempts to maximize the consistency information between one augmented view and the graph structure reconstructed from the other augmented view. Furthermore, we offer a comprehensive theoretical CGCL analysis. This paper empirically and experimentally demonstrates the effectiveness of the proposed CGCL method, achieving competitive results on graph datasets in comparisons with several state-of-the-art algorithms.
Coarse-Grained Configurational Polymer Fingerprints for Property Prediction using Machine Learning
Nov 20, 2023In this work, we present a method to generate a configurational level fingerprint for polymers using the Bead-Spring-Model. Unlike some of the previous fingerprinting approaches that employ monomer-level information where atomistic descriptors are computed using quantum chemistry calculations, this approach incorporates configurational information from a coarse-grained model of a long polymer chain. The proposed approach may be advantageous for the study of behavior resulting from large molecular weights. To create this fingerprint, we make use of two kinds of descriptors. First, we calculate certain geometric descriptors like Re2, Rg2 etc. and label them as Calculated Descriptors. Second, we generate a set of data-driven descriptors using an unsupervised autoencoder model and call them Learnt Descriptors. Using a combination of both of them, we are able to learn mappings from the structure to various properties of the polymer chain by training ML models. We test our fingerprint to predict the probability of occurrence of a configuration at equilibrium, which is approximated by a simple linear relationship between the instantaneous internal energy and equilibrium average internal energy.
Enhancing Secrecy Capacity in PLS Communication with NORAN based on Pilot Information Codebooks
Oct 02, 2023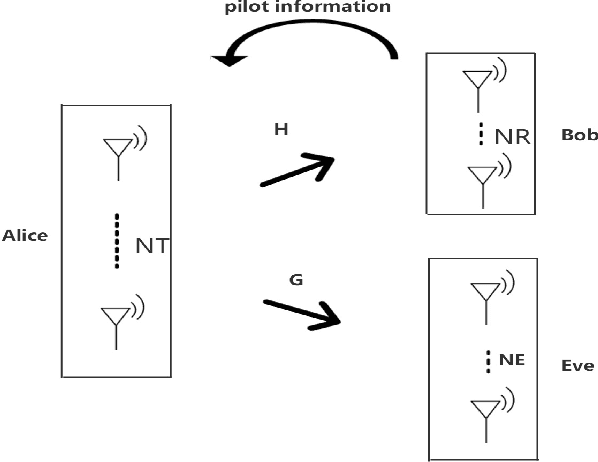
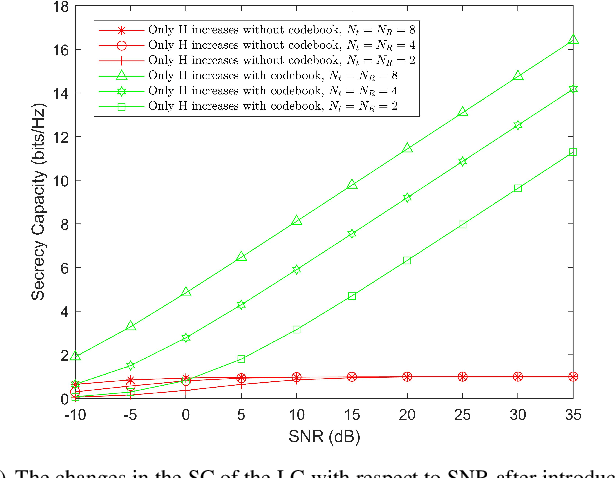
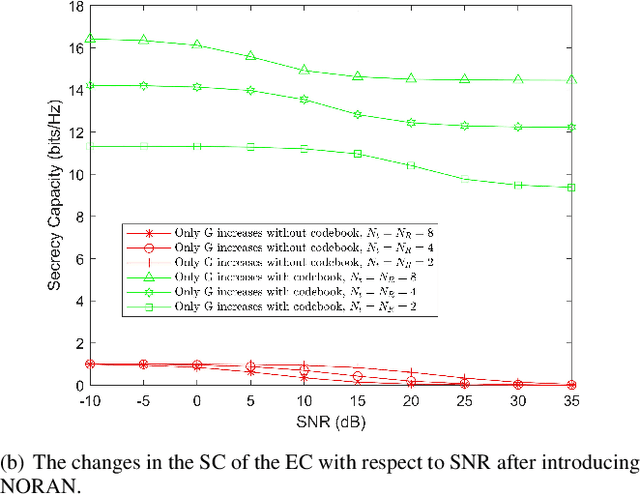
In recent research, non-orthogonal artificial noise (NORAN) has been proposed as an alternative to orthogonal artificial noise (AN). However, NORAN introduces additional noise into the channel, which reduces the capacity of the legitimate channel (LC). At the same time, selecting a NORAN design with ideal security performance from a large number of design options is also a challenging problem. To address these two issues, a novel NORAN based on a pilot information codebook is proposed in this letter. The codebook associates different suboptimal NORANs with pilot information as the key under different channel state information (CSI). The receiver interrogates the codebook using the pilot information to obtain the NORAN that the transmitter will transmit in the next moment, in order to eliminate the NORAN when receiving information. Therefore, NORAN based on pilot information codebooks can improve the secrecy capacity (SC) of the communication system by directly using suboptimal NORAN design schemes without increasing the noise in the LC. Numerical simulations and analyses show that the introduction of NORAN with a novel design using pilot information codebooks significantly enhances the security and improves the SC of the communication system.
Hierarchical ML Codebook Design for Extreme MIMO Beam Management
Nov 24, 2023Beam management is a strategy to unify beamforming and channel state information (CSI) acquisition with large antenna arrays in 5G. Codebooks serve multiple uses in beam management including beamforming reference signals, CSI reporting, and analog beam training. In this paper, we propose and evaluate a machine learning-refined codebook design process for extremely large multiple-input multiple-output (X-MIMO) systems. We propose a neural network and beam selection strategy to design the initial access and refinement codebooks using end-to-end learning from beamspace representations. The algorithm, called Extreme-Beam Management (X-BM), can significantly improve the performance of extremely large arrays as envisioned for 6G and capture realistic wireless and physical layer aspects. Our results show an 8dB improvement in initial access and overall effective spectral efficiency improvements compared to traditional codebook methods.