 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
Dec 05, 2023
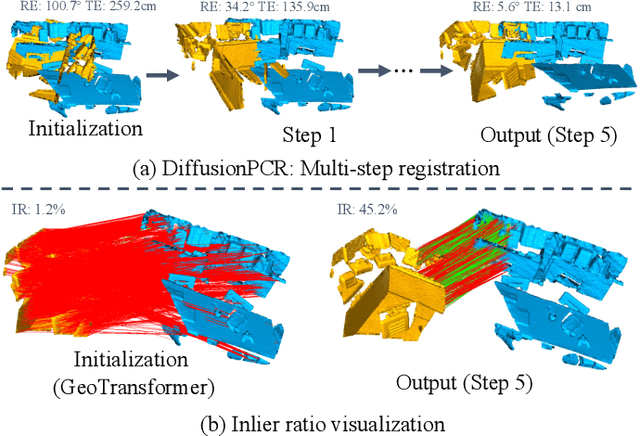
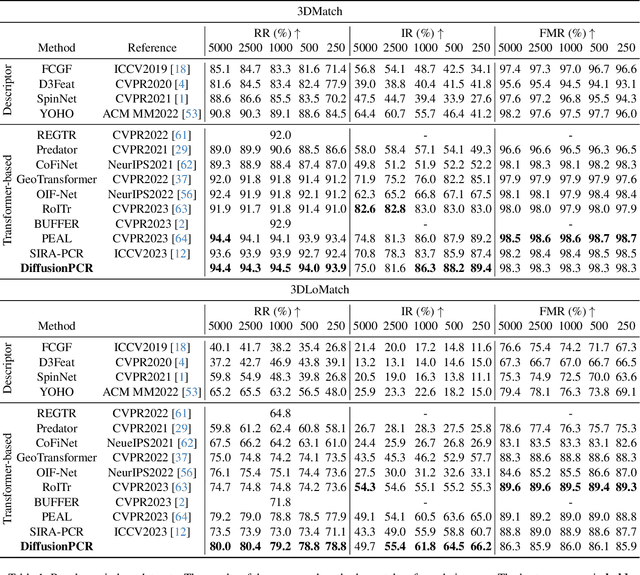
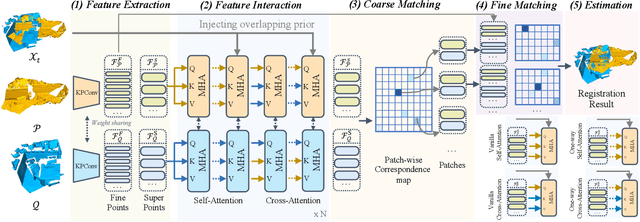
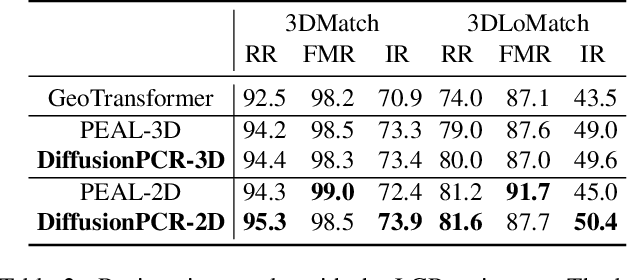
Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose formulating PCR as a denoising diffusion probabilistic process, mapping noisy transformations to the ground truth. However, using diffusion models for PCR has nontrivial challenges, such as adapting a generative model to a discriminative task and leveraging the estimated nonlinear transformation from the previous step. Instead of training a diffusion model to directly map pure noise to ground truth, we map the predictions of an off-the-shelf PCR model to ground truth. The predictions of off-the-shelf models are often imperfect, especially in challenging cases where the two points clouds have low overlap, and thus could be seen as noisy versions of the real rigid transformation. In addition, we transform the rotation matrix into a spherical linear space for interpolation between samples in the forward process, and convert rigid transformations into auxiliary information to implicitly exploit last-step estimations in the reverse process. As a result, conditioned on time step, the denoising model adapts to the increasing accuracy across steps and refines registrations. Our extensive experiments showcase the effectiveness of our DiffusionPCR, yielding state-of-the-art registration recall rates (95.3%/81.6%) on 3DMatch and 3DLoMatch. The code will be made public upon publication.
Generating Visually Realistic Adversarial Patch
Dec 05, 2023Deep neural networks (DNNs) are vulnerable to various types of adversarial examples, bringing huge threats to security-critical applications. Among these, adversarial patches have drawn increasing attention due to their good applicability to fool DNNs in the physical world. However, existing works often generate patches with meaningless noise or patterns, making it conspicuous to humans. To address this issue, we explore how to generate visually realistic adversarial patches to fool DNNs. Firstly, we analyze that a high-quality adversarial patch should be realistic, position irrelevant, and printable to be deployed in the physical world. Based on this analysis, we propose an effective attack called VRAP, to generate visually realistic adversarial patches. Specifically, VRAP constrains the patch in the neighborhood of a real image to ensure the visual reality, optimizes the patch at the poorest position for position irrelevance, and adopts Total Variance loss as well as gamma transformation to make the generated patch printable without losing information. Empirical evaluations on the ImageNet dataset demonstrate that the proposed VRAP exhibits outstanding attack performance in the digital world. Moreover, the generated adversarial patches can be disguised as the scrawl or logo in the physical world to fool the deep models without being detected, bringing significant threats to DNNs-enabled applications.
On the Initialization of Graph Neural Networks
Dec 05, 2023Graph Neural Networks (GNNs) have displayed considerable promise in graph representation learning across various applications. The core learning process requires the initialization of model weight matrices within each GNN layer, which is typically accomplished via classic initialization methods such as Xavier initialization. However, these methods were originally motivated to stabilize the variance of hidden embeddings and gradients across layers of Feedforward Neural Networks (FNNs) and Convolutional Neural Networks (CNNs) to avoid vanishing gradients and maintain steady information flow. In contrast, within the GNN context classical initializations disregard the impact of the input graph structure and message passing on variance. In this paper, we analyze the variance of forward and backward propagation across GNN layers and show that the variance instability of GNN initializations comes from the combined effect of the activation function, hidden dimension, graph structure and message passing. To better account for these influence factors, we propose a new initialization method for Variance Instability Reduction within GNN Optimization (Virgo), which naturally tends to equate forward and backward variances across successive layers. We conduct comprehensive experiments on 15 datasets to show that Virgo can lead to superior model performance and more stable variance at initialization on node classification, link prediction and graph classification tasks. Codes are in https://github.com/LspongebobJH/virgo_icml2023.
Gender inference: can chatGPT outperform common commercial tools?
Nov 24, 2023An increasing number of studies use gender information to understand phenomena such as gender bias, inequity in access and participation, or the impact of the Covid pandemic response. Unfortunately, most datasets do not include self-reported gender information, making it necessary for researchers to infer gender from other information, such as names or names and country information. An important limitation of these tools is that they fail to appropriately capture the fact that gender exists on a non-binary scale, however, it remains important to evaluate and compare how well these tools perform in a variety of contexts. In this paper, we compare the performance of a generative Artificial Intelligence (AI) tool ChatGPT with three commercially available list-based and machine learning-based gender inference tools (Namsor, Gender-API, and genderize.io) on a unique dataset. Specifically, we use a large Olympic athlete dataset and report how variations in the input (e.g., first name and first and last name, with and without country information) impact the accuracy of their predictions. We report results for the full set, as well as for the subsets: medal versus non-medal winners, athletes from the largest English-speaking countries, and athletes from East Asia. On these sets, we find that Namsor is the best traditional commercially available tool. However, ChatGPT performs at least as well as Namsor and often outperforms it, especially for the female sample when country and/or last name information is available. All tools perform better on medalists versus non-medalists and on names from English-speaking countries. Although not designed for this purpose, ChatGPT may be a cost-effective tool for gender prediction. In the future, it might even be possible for ChatGPT or other large scale language models to better identify self-reported gender rather than report gender on a binary scale.
* 14 pages, 8 tables
Federated Generalization via Information-Theoretic Distribution Diversification
Oct 11, 2023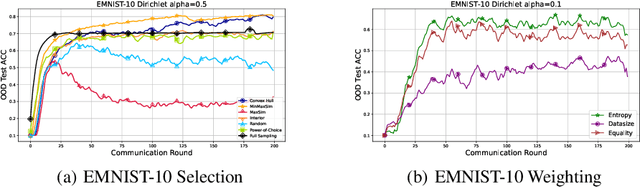
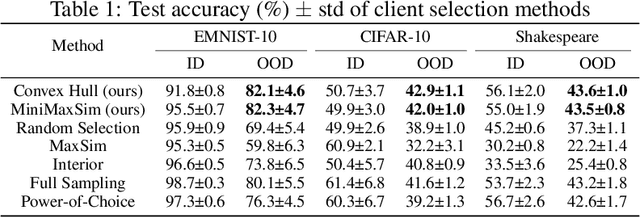

Federated Learning (FL) has surged in prominence due to its capability of collaborative model training without direct data sharing. However, the vast disparity in local data distributions among clients, often termed the non-Independent Identically Distributed (non-IID) challenge, poses a significant hurdle to FL's generalization efficacy. The scenario becomes even more complex when not all clients participate in the training process, a common occurrence due to unstable network connections or limited computational capacities. This can greatly complicate the assessment of the trained models' generalization abilities. While a plethora of recent studies has centered on the generalization gap pertaining to unseen data from participating clients with diverse distributions, the divergence between the training distributions of participating clients and the testing distributions of non-participating ones has been largely overlooked. In response, our paper unveils an information-theoretic generalization framework for FL. Specifically, it quantifies generalization errors by evaluating the information entropy of local distributions and discerning discrepancies across these distributions. Inspired by our deduced generalization bounds, we introduce a weighted aggregation approach and a duo of client selection strategies. These innovations aim to bolster FL's generalization prowess by encompassing a more varied set of client data distributions. Our extensive empirical evaluations reaffirm the potency of our proposed methods, aligning seamlessly with our theoretical construct.
Analyze the robustness of three NMF algorithms (Robust NMF with L1 norm, L2-1 norm NMF, L2 NMF)
Dec 03, 2023Non-negative matrix factorization (NMF) and its variants have been widely employed in clustering and classification tasks (Long, & Jian , 2021). However, noises can seriously affect the results of our experiments. Our research is dedicated to investigating the noise robustness of non-negative matrix factorization (NMF) in the face of different types of noise. Specifically, we adopt three different NMF algorithms, namely L1 NMF, L2 NMF, and L21 NMF, and use the ORL and YaleB data sets to simulate a series of experiments with salt-and-pepper noise and Block-occlusion noise separately. In the experiment, we use a variety of evaluation indicators, including root mean square error (RMSE), accuracy (ACC), and normalized mutual information (NMI), to evaluate the performance of different NMF algorithms in noisy environments. Through these indicators, we quantify the resistance of NMF algorithms to noise and gain insights into their feasibility in practical applications.
Improving Normative Modeling for Multi-modal Neuroimaging Data using mixture-of-product-of-experts variational autoencoders
Dec 02, 2023Normative models in neuroimaging learn the brain patterns of healthy population distribution and estimate how disease subjects like Alzheimer's Disease (AD) deviate from the norm. Existing variational autoencoder (VAE)-based normative models using multimodal neuroimaging data aggregate information from multiple modalities by estimating product or averaging of unimodal latent posteriors. This can often lead to uninformative joint latent distributions which affects the estimation of subject-level deviations. In this work, we addressed the prior limitations by adopting the Mixture-of-Product-of-Experts (MoPoE) technique which allows better modelling of the joint latent posterior. Our model labelled subjects as outliers by calculating deviations from the multimodal latent space. Further, we identified which latent dimensions and brain regions were associated with abnormal deviations due to AD pathology.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023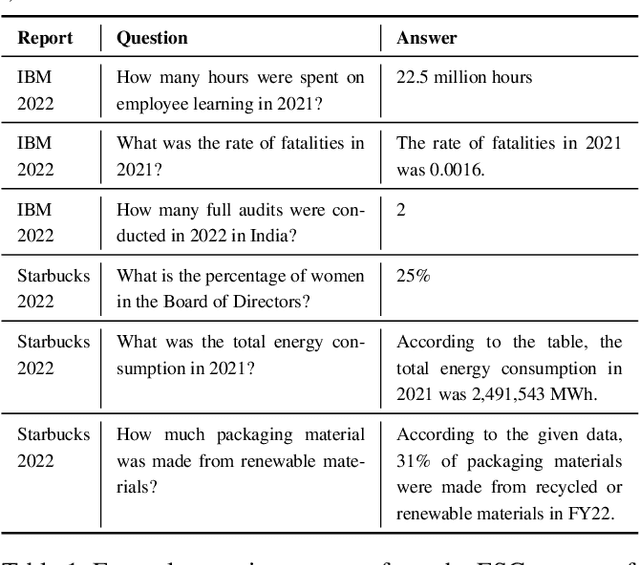
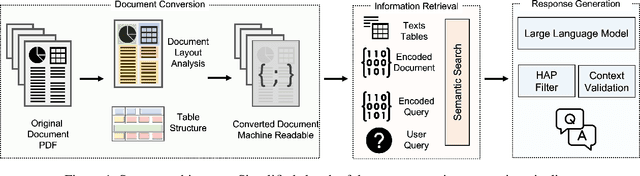
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
Multi-Rate Variable-Length CSI Compression for FDD Massive MIMO
Nov 30, 2023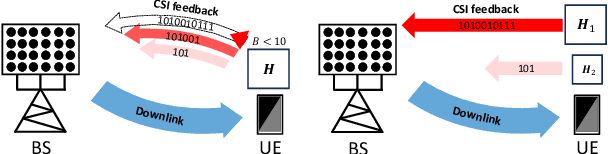
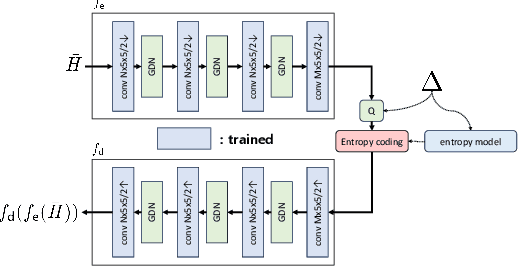
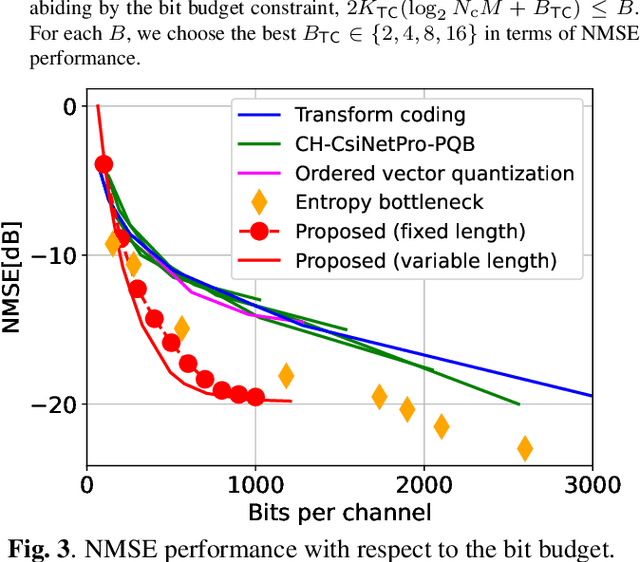
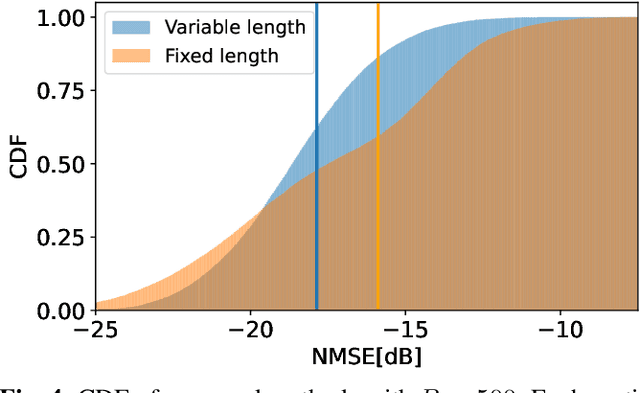
For frequency-division-duplexing (FDD) systems, channel state information (CSI) should be fed back from the user terminal to the base station. This feedback overhead becomes problematic as the number of antennas grows. To alleviate this issue, we propose a flexible CSI compression method using variational autoencoder (VAE) with an entropy bottleneck structure, which can support multi-rate and variable-length operation. Numerical study confirms that the proposed method outperforms the existing CSI compression techniques in terms of normalized mean squared error.
Generalized Large-Scale Data Condensation via Various Backbone and Statistical Matching
Nov 29, 2023The lightweight "local-match-global" matching introduced by SRe2L successfully creates a distilled dataset with comprehensive information on the full 224x224 ImageNet-1k. However, this one-sided approach is limited to a particular backbone, layer, and statistics, which limits the improvement of the generalization of a distilled dataset. We suggest that sufficient and various "local-match-global" matching are more precise and effective than a single one and has the ability to create a distilled dataset with richer information and better generalization. We call this perspective "generalized matching" and propose Generalized Various Backbone and Statistical Matching (G-VBSM) in this work, which aims to create a synthetic dataset with densities, ensuring consistency with the complete dataset across various backbones, layers, and statistics. As experimentally demonstrated, G-VBSM is the first algorithm to obtain strong performance across both small-scale and large-scale datasets. Specifically, G-VBSM achieves a performance of 38.7% on CIFAR-100 with 128-width ConvNet, 47.6% on Tiny-ImageNet with ResNet18, and 31.4% on the full 224x224 ImageNet-1k with ResNet18, under images per class (IPC) 10, 50, and 10, respectively. These results surpass all SOTA methods by margins of 3.9%, 6.5%, and 10.1%, respectively.