 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ultra-Resolution Cascaded Diffusion Model for Gigapixel Image Synthesis in Histopathology
Dec 02, 2023
Diagnoses from histopathology images rely on information from both high and low resolutions of Whole Slide Images. Ultra-Resolution Cascaded Diffusion Models (URCDMs) allow for the synthesis of high-resolution images that are realistic at all magnification levels, focusing not only on fidelity but also on long-distance spatial coherency. Our model beats existing methods, improving the pFID-50k [2] score by 110.63 to 39.52 pFID-50k. Additionally, a human expert evaluation study was performed, reaching a weighted Mean Absolute Error (MAE) of 0.11 for the Lower Resolution Diffusion Models and a weighted MAE of 0.22 for the URCDM.
PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
Dec 04, 2023We propose the task of Panoptic Scene Completion (PSC) which extends the recently popular Semantic Scene Completion (SSC) task with instance-level information to produce a richer understanding of the 3D scene. Our PSC proposal utilizes a hybrid mask-based technique on the non-empty voxels from sparse multi-scale completions. Whereas the SSC literature overlooks uncertainty which is critical for robotics applications, we instead propose an efficient ensembling to estimate both voxel-wise and instance-wise uncertainties along PSC. This is achieved by building on a multi-input multi-output (MIMO) strategy, while improving performance and yielding better uncertainty for little additional compute. Additionally, we introduce a technique to aggregate permutation-invariant mask predictions. Our experiments demonstrate that our method surpasses all baselines in both Panoptic Scene Completion and uncertainty estimation on three large-scale autonomous driving datasets. Our code and data are available at https://astra-vision.github.io/PaSCo .
Likelihood-Aware Semantic Alignment for Full-Spectrum Out-of-Distribution Detection
Dec 04, 2023Full-spectrum out-of-distribution (F-OOD) detection aims to accurately recognize in-distribution (ID) samples while encountering semantic and covariate shifts simultaneously. However, existing out-of-distribution (OOD) detectors tend to overfit the covariance information and ignore intrinsic semantic correlation, inadequate for adapting to complex domain transformations. To address this issue, we propose a Likelihood-Aware Semantic Alignment (LSA) framework to promote the image-text correspondence into semantically high-likelihood regions. LSA consists of an offline Gaussian sampling strategy which efficiently samples semantic-relevant visual embeddings from the class-conditional Gaussian distribution, and a bidirectional prompt customization mechanism that adjusts both ID-related and negative context for discriminative ID/OOD boundary. Extensive experiments demonstrate the remarkable OOD detection performance of our proposed LSA especially on the intractable Near-OOD setting, surpassing existing methods by a margin of $15.26\%$ and $18.88\%$ on two F-OOD benchmarks, respectively.
Federated Learning with Reduced Information Leakage and Computation
Oct 10, 2023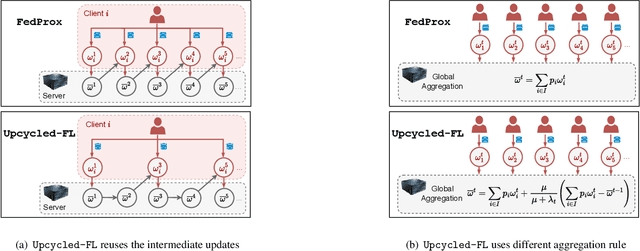
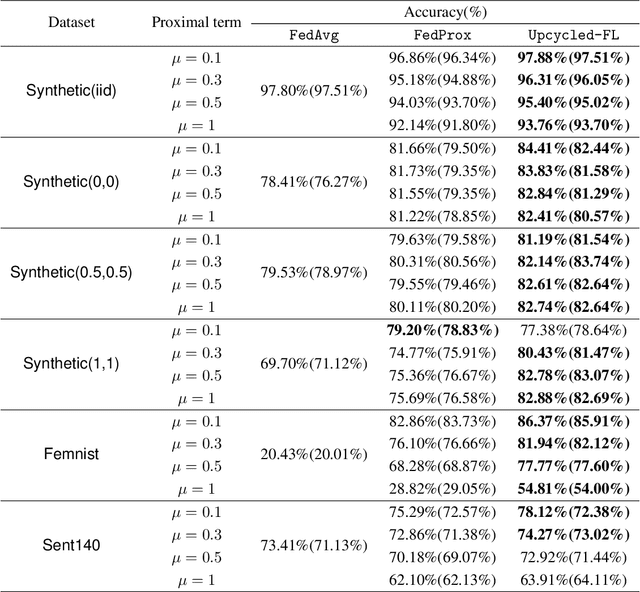
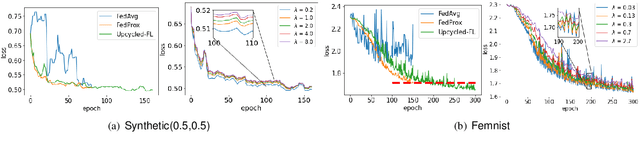
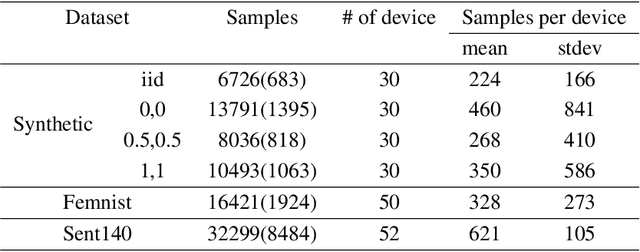
Federated learning (FL) is a distributed learning paradigm that allows multiple decentralized clients to collaboratively learn a common model without sharing local data. Although local data is not exposed directly, privacy concerns nonetheless exist as clients' sensitive information can be inferred from intermediate computations. Moreover, such information leakage accumulates substantially over time as the same data is repeatedly used during the iterative learning process. As a result, it can be particularly difficult to balance the privacy-accuracy trade-off when designing privacy-preserving FL algorithms. In this paper, we introduce Upcycled-FL, a novel federated learning framework with first-order approximation applied at every even iteration. Under this framework, half of the FL updates incur no information leakage and require much less computation. We first conduct the theoretical analysis on the convergence (rate) of Upcycled-FL, and then apply perturbation mechanisms to preserve privacy. Experiments on real-world data show that Upcycled-FL consistently outperforms existing methods over heterogeneous data, and significantly improves privacy-accuracy trade-off while reducing 48% of the training time on average.
Single-Cell Clustering via Dual-Graph Alignment
Nov 28, 2023In recent years, the field of single-cell RNA sequencing has seen a surge in the development of clustering methods. These methods enable the identification of cell subpopulations, thereby facilitating the understanding of tumor microenvironments. Despite their utility, most existing clustering algorithms primarily focus on the attribute information provided by the cell matrix or the network structure between cells, often neglecting the network between genes. This oversight could lead to loss of information and clustering results that lack clinical significance. To address this limitation, we develop an advanced single-cell clustering model incorporating dual-graph alignment, which integrates gene network information into the clustering process based on self-supervised and unsupervised optimization. Specifically, we designed a graph-based autoencoder enhanced by an attention mechanism to effectively capture relationships between cells. Moreover, we performed the node2vec method on Protein-Protein Interaction (PPI) networks to derive the gene network structure and maintained this structure throughout the clustering process. Our proposed method has been demonstrated to be effective through experimental results, showcasing its ability to optimize clustering outcomes while preserving the original associations between cells and genes. This research contributes to obtaining accurate cell subpopulations and generates clustering results that more closely resemble real-world biological scenarios. It provides better insights into the characteristics and distribution of diseased cells, ultimately building a foundation for early disease diagnosis and treatment.
HKUST at SemEval-2023 Task 1: Visual Word Sense Disambiguation with Context Augmentation and Visual Assistance
Nov 30, 2023Visual Word Sense Disambiguation (VWSD) is a multi-modal task that aims to select, among a batch of candidate images, the one that best entails the target word's meaning within a limited context. In this paper, we propose a multi-modal retrieval framework that maximally leverages pretrained Vision-Language models, as well as open knowledge bases and datasets. Our system consists of the following key components: (1) Gloss matching: a pretrained bi-encoder model is used to match contexts with proper senses of the target words; (2) Prompting: matched glosses and other textual information, such as synonyms, are incorporated using a prompting template; (3) Image retrieval: semantically matching images are retrieved from large open datasets using prompts as queries; (4) Modality fusion: contextual information from different modalities are fused and used for prediction. Although our system does not produce the most competitive results at SemEval-2023 Task 1, we are still able to beat nearly half of the teams. More importantly, our experiments reveal acute insights for the field of Word Sense Disambiguation (WSD) and multi-modal learning. Our code is available on GitHub.
The automatic detection of lumber anatomy in epidural injections for ultrasound guidance
Dec 07, 2023The purpose of this paper is to help the anesthesiologist to find the epidural depth automatically to make the first attempt to enter the path of the needle into the patient's body while it is clogged with bone and avoid causing a puncture in the surrounding areas of the patient`s back. In this regard, a morphology-based bone enhancement and detection followed by a Ramer-Douglas-Peucker algorithm and Hough transform is proposed. The proposed algorithm is tested on synthetic and real ultrasound images of laminar bone, and the results are compared with the template matching based Ligamentum Flavum (LF) detection method. Results indicate that the proposed method can faster detect the diagonal shape of the laminar bone and its corresponding epidural depth. Furthermore, the proposed method is reliable enough providing anesthesiologists with real-time information while an epidural needle insertion is performed. It has to be noted that using the ultrasound images is to help anesthesiologists to perform the blind injection, and due to quite a lot of errors occurred in ultrasound-imaging-based methods, these methods can not completely replace the tissue pressure-based method. And in the end, when the needle is injected into the area (dura space) measurements can only be trusted to the extent of tissue resistance. Despite the fairly limited amount of training data available in this study, a significant improvement of the segmentation speed of lumbar bones and epidural depth in ultrasound scans with a rational accuracy compared to the LF-based detection method was found.
Cooperative Dual Attention for Audio-Visual Speech Enhancement with Facial Cues
Nov 24, 2023In this work, we focus on leveraging facial cues beyond the lip region for robust Audio-Visual Speech Enhancement (AVSE). The facial region, encompassing the lip region, reflects additional speech-related attributes such as gender, skin color, nationality, etc., which contribute to the effectiveness of AVSE. However, static and dynamic speech-unrelated attributes also exist, causing appearance changes during speech. To address these challenges, we propose a Dual Attention Cooperative Framework, DualAVSE, to ignore speech-unrelated information, capture speech-related information with facial cues, and dynamically integrate it with the audio signal for AVSE. Specifically, we introduce a spatial attention-based visual encoder to capture and enhance visual speech information beyond the lip region, incorporating global facial context and automatically ignoring speech-unrelated information for robust visual feature extraction. Additionally, a dynamic visual feature fusion strategy is introduced by integrating a temporal-dimensional self-attention module, enabling the model to robustly handle facial variations. The acoustic noise in the speaking process is variable, impacting audio quality. Therefore, a dynamic fusion strategy for both audio and visual features is introduced to address this issue. By integrating cooperative dual attention in the visual encoder and audio-visual fusion strategy, our model effectively extracts beneficial speech information from both audio and visual cues for AVSE. Thorough analysis and comparison on different datasets, including normal and challenging cases with unreliable or absent visual information, consistently show our model outperforming existing methods across multiple metrics.
Efficient Expansion and Gradient Based Task Inference for Replay Free Incremental Learning
Dec 02, 2023This paper proposes a simple but highly efficient expansion-based model for continual learning. The recent feature transformation, masking and factorization-based methods are efficient, but they grow the model only over the global or shared parameter. Therefore, these approaches do not fully utilize the previously learned information because the same task-specific parameter forgets the earlier knowledge. Thus, these approaches show limited transfer learning ability. Moreover, most of these models have constant parameter growth for all tasks, irrespective of the task complexity. Our work proposes a simple filter and channel expansion based method that grows the model over the previous task parameters and not just over the global parameter. Therefore, it fully utilizes all the previously learned information without forgetting, which results in better knowledge transfer. The growth rate in our proposed model is a function of task complexity; therefore for a simple task, the model has a smaller parameter growth while for complex tasks, the model requires more parameters to adapt to the current task. Recent expansion based models show promising results for task incremental learning (TIL). However, for class incremental learning (CIL), prediction of task id is a crucial challenge; hence, their results degrade rapidly as the number of tasks increase. In this work, we propose a robust task prediction method that leverages entropy weighted data augmentations and the models gradient using pseudo labels. We evaluate our model on various datasets and architectures in the TIL, CIL and generative continual learning settings. The proposed approach shows state-of-the-art results in all these settings. Our extensive ablation studies show the efficacy of the proposed components.
PointNeRF++: A multi-scale, point-based Neural Radiance Field
Dec 04, 2023Point clouds offer an attractive source of information to complement images in neural scene representations, especially when few images are available. Neural rendering methods based on point clouds do exist, but they do not perform well when the point cloud quality is low -- e.g., sparse or incomplete, which is often the case with real-world data. We overcome these problems with a simple representation that aggregates point clouds at multiple scale levels with sparse voxel grids at different resolutions. To deal with point cloud sparsity, we average across multiple scale levels -- but only among those that are valid, i.e., that have enough neighboring points in proximity to the ray of a pixel. To help model areas without points, we add a global voxel at the coarsest scale, thus unifying "classical" and point-based NeRF formulations. We validate our method on the NeRF Synthetic, ScanNet, and KITTI-360 datasets, outperforming the state of the art by a significant margin.