 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging External Knowledge Resources to Enable Domain-Specific Comprehension
Jan 15, 2024
Machine Reading Comprehension (MRC) has been a long-standing problem in NLP and, with the recent introduction of the BERT family of transformer based language models, it has come a long way to getting solved. Unfortunately, however, when BERT variants trained on general text corpora are applied to domain-specific text, their performance inevitably degrades on account of the domain shift i.e. genre/subject matter discrepancy between the training and downstream application data. Knowledge graphs act as reservoirs for either open or closed domain information and prior studies have shown that they can be used to improve the performance of general-purpose transformers in domain-specific applications. Building on existing work, we introduce a method using Multi-Layer Perceptrons (MLPs) for aligning and integrating embeddings extracted from knowledge graphs with the embeddings spaces of pre-trained language models (LMs). We fuse the aligned embeddings with open-domain LMs BERT and RoBERTa, and fine-tune them for two MRC tasks namely span detection (COVID-QA) and multiple-choice questions (PubMedQA). On the COVID-QA dataset, we see that our approach allows these models to perform similar to their domain-specific counterparts, Bio/Sci-BERT, as evidenced by the Exact Match (EM) metric. With regards to PubMedQA, we observe an overall improvement in accuracy while the F1 stays relatively the same over the domain-specific models.
Semantic Segmentation in Multiple Adverse Weather Conditions with Domain Knowledge Retention
Jan 15, 2024Semantic segmentation's performance is often compromised when applied to unlabeled adverse weather conditions. Unsupervised domain adaptation is a potential approach to enhancing the model's adaptability and robustness to adverse weather. However, existing methods encounter difficulties when sequentially adapting the model to multiple unlabeled adverse weather conditions. They struggle to acquire new knowledge while also retaining previously learned knowledge.To address these problems, we propose a semantic segmentation method for multiple adverse weather conditions that incorporates adaptive knowledge acquisition, pseudolabel blending, and weather composition replay. Our adaptive knowledge acquisition enables the model to avoid learning from extreme images that could potentially cause the model to forget. In our approach of blending pseudo-labels, we not only utilize the current model but also integrate the previously learned model into the ongoing learning process. This collaboration between the current teacher and the previous model enhances the robustness of the pseudo-labels for the current target. Our weather composition replay mechanism allows the model to continuously refine its previously learned weather information while simultaneously learning from the new target domain. Our method consistently outperforms the stateof-the-art methods, and obtains the best performance with averaged mIoU (%) of 65.7 and the lowest forgetting (%) of 3.6 against 60.1 and 11.3, on the ACDC datasets for a four-target continual multi-target domain adaptation.
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Jan 15, 2024Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.
Learn Once Plan Arbitrarily (LOPA): Attention-Enhanced Deep Reinforcement Learning Method for Global Path Planning
Jan 08, 2024Deep reinforcement learning (DRL) methods have recently shown promise in path planning tasks. However, when dealing with global planning tasks, these methods face serious challenges such as poor convergence and generalization. To this end, we propose an attention-enhanced DRL method called LOPA (Learn Once Plan Arbitrarily) in this paper. Firstly, we analyze the reasons of these problems from the perspective of DRL's observation, revealing that the traditional design causes DRL to be interfered by irrelevant map information. Secondly, we develop the LOPA which utilizes a novel attention-enhanced mechanism to attain an improved attention capability towards the key information of the observation. Such a mechanism is realized by two steps: (1) an attention model is built to transform the DRL's observation into two dynamic views: local and global, significantly guiding the LOPA to focus on the key information on the given maps; (2) a dual-channel network is constructed to process these two views and integrate them to attain an improved reasoning capability. The LOPA is validated via multi-objective global path planning experiments. The result suggests the LOPA has improved convergence and generalization performance as well as great path planning efficiency.
Enhancing Context Through Contrast
Jan 06, 2024Neural machine translation benefits from semantically rich representations. Considerable progress in learning such representations has been achieved by language modelling and mutual information maximization objectives using contrastive learning. The language-dependent nature of language modelling introduces a trade-off between the universality of the learned representations and the model's performance on the language modelling tasks. Although contrastive learning improves performance, its success cannot be attributed to mutual information alone. We propose a novel Context Enhancement step to improve performance on neural machine translation by maximizing mutual information using the Barlow Twins loss. Unlike other approaches, we do not explicitly augment the data but view languages as implicit augmentations, eradicating the risk of disrupting semantic information. Further, our method does not learn embeddings from scratch and can be generalised to any set of pre-trained embeddings. Finally, we evaluate the language-agnosticism of our embeddings through language classification and use them for neural machine translation to compare with state-of-the-art approaches.
Sparse Meets Dense: A Hybrid Approach to Enhance Scientific Document Retrieval
Jan 08, 2024Traditional information retrieval is based on sparse bag-of-words vector representations of documents and queries. More recent deep-learning approaches have used dense embeddings learned using a transformer-based large language model. We show that on a classic benchmark on scientific document retrieval in the medical domain of cystic fibrosis, that both of these models perform roughly equivalently. Notably, dense vectors from the state-of-the-art SPECTER2 model do not significantly enhance performance. However, a hybrid model that we propose combining these methods yields significantly better results, underscoring the merits of integrating classical and contemporary deep learning techniques in information retrieval in the domain of specialized scientific documents.
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Dec 11, 2023The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo
A Sparse Cross Attention-based Graph Convolution Network with Auxiliary Information Awareness for Traffic Flow Prediction
Dec 14, 2023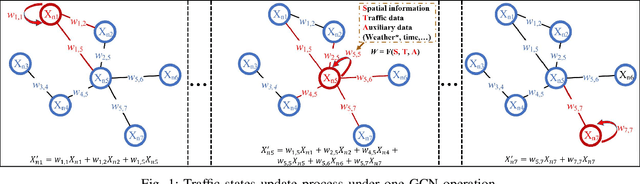
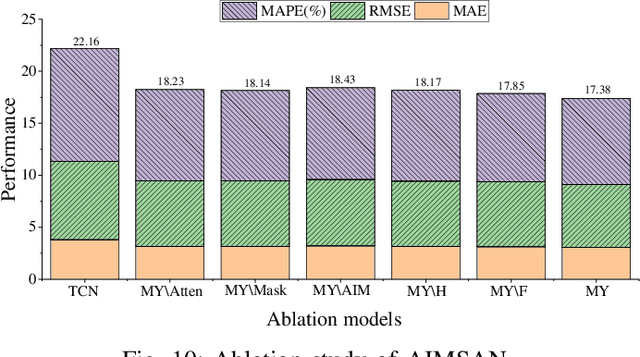
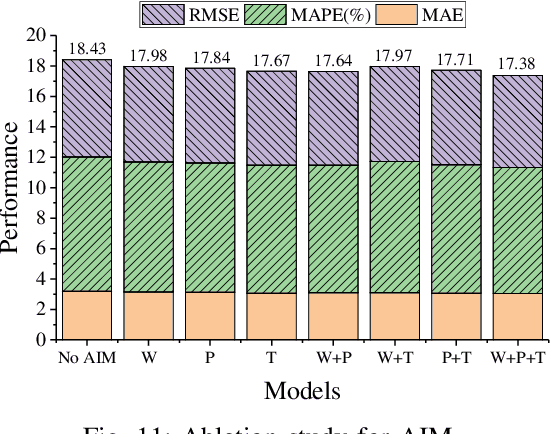
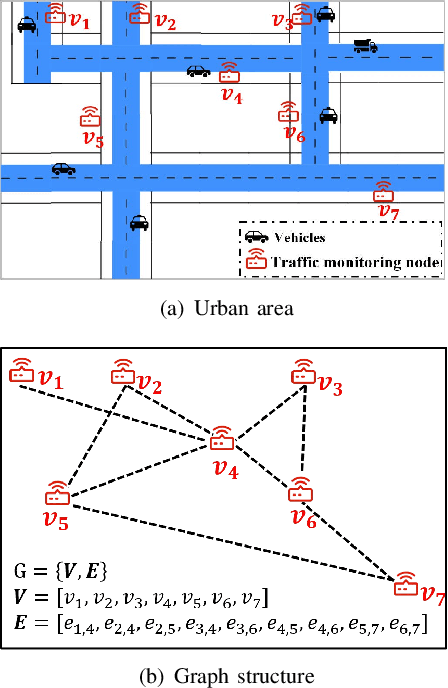
Deep graph convolution networks (GCNs) have recently shown excellent performance in traffic prediction tasks. However, they face some challenges. First, few existing models consider the influence of auxiliary information, i.e., weather and holidays, which may result in a poor grasp of spatial-temporal dynamics of traffic data. Second, both the construction of a dynamic adjacent matrix and regular graph convolution operations have quadratic computation complexity, which restricts the scalability of GCN-based models. To address such challenges, this work proposes a deep encoder-decoder model entitled AIMSAN. It contains an auxiliary information-aware module (AIM) and sparse cross attention-based graph convolution network (SAN). The former learns multi-attribute auxiliary information and obtains its embedded presentation of different time-window sizes. The latter uses a cross-attention mechanism to construct dynamic adjacent matrices by fusing traffic data and embedded auxiliary data. Then, SAN applies diffusion GCN on traffic data to mine rich spatial-temporal dynamics. Furthermore, AIMSAN considers and uses the spatial sparseness of traffic nodes to reduce the quadratic computation complexity. Experimental results on three public traffic datasets demonstrate that the proposed method outperforms other counterparts in terms of various performance indices. Specifically, the proposed method has competitive performance with the state-of-the-art algorithms but saves 35.74% of GPU memory usage, 42.25% of training time, and 45.51% of validation time on average.
Cross-Attention Watermarking of Large Language Models
Jan 12, 2024A new approach to linguistic watermarking of language models is presented in which information is imperceptibly inserted into the output text while preserving its readability and original meaning. A cross-attention mechanism is used to embed watermarks in the text during inference. Two methods using cross-attention are presented that minimize the effect of watermarking on the performance of a pretrained model. Exploration of different training strategies for optimizing the watermarking and of the challenges and implications of applying this approach in real-world scenarios clarified the tradeoff between watermark robustness and text quality. Watermark selection substantially affects the generated output for high entropy sentences. This proactive watermarking approach has potential application in future model development.
CrisisKAN: Knowledge-infused and Explainable Multimodal Attention Network for Crisis Event Classification
Jan 11, 2024Pervasive use of social media has become the emerging source for real-time information (like images, text, or both) to identify various events. Despite the rapid growth of image and text-based event classification, the state-of-the-art (SOTA) models find it challenging to bridge the semantic gap between features of image and text modalities due to inconsistent encoding. Also, the black-box nature of models fails to explain the model's outcomes for building trust in high-stakes situations such as disasters, pandemic. Additionally, the word limit imposed on social media posts can potentially introduce bias towards specific events. To address these issues, we proposed CrisisKAN, a novel Knowledge-infused and Explainable Multimodal Attention Network that entails images and texts in conjunction with external knowledge from Wikipedia to classify crisis events. To enrich the context-specific understanding of textual information, we integrated Wikipedia knowledge using proposed wiki extraction algorithm. Along with this, a guided cross-attention module is implemented to fill the semantic gap in integrating visual and textual data. In order to ensure reliability, we employ a model-specific approach called Gradient-weighted Class Activation Mapping (Grad-CAM) that provides a robust explanation of the predictions of the proposed model. The comprehensive experiments conducted on the CrisisMMD dataset yield in-depth analysis across various crisis-specific tasks and settings. As a result, CrisisKAN outperforms existing SOTA methodologies and provides a novel view in the domain of explainable multimodal event classification.