 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOC: Spatially-Progressing Object State Change Segmentation in Video
Mar 15, 2025Object state changes in video reveal critical information about human and agent activity. However, existing methods are limited to temporal localization of when the object is in its initial state (e.g., the unchopped avocado) versus when it has completed a state change (e.g., the chopped avocado), which limits applicability for any task requiring detailed information about the progress of the actions and its spatial localization. We propose to deepen the problem by introducing the spatially-progressing object state change segmentation task. The goal is to segment at the pixel-level those regions of an object that are actionable and those that are transformed. We introduce the first model to address this task, designing a VLM-based pseudo-labeling approach, state-change dynamics constraints, and a novel WhereToChange benchmark built on in-the-wild Internet videos. Experiments on two datasets validate both the challenge of the new task as well as the promise of our model for localizing exactly where and how fast objects are changing in video. We further demonstrate useful implications for tracking activity progress to benefit robotic agents. Project page: https://vision.cs.utexas.edu/projects/spoc-spatially-progressing-osc
Ancient Wisdom, Modern Tools: Exploring Retrieval-Augmented LLMs for Ancient Indian Philosophy
Aug 21, 2024LLMs have revolutionized the landscape of information retrieval and knowledge dissemination. However, their application in specialized areas is often hindered by factual inaccuracies and hallucinations, especially in long-tail knowledge distributions. We explore the potential of retrieval-augmented generation (RAG) models for long-form question answering (LFQA) in a specialized knowledge domain. We present VedantaNY-10M, a dataset curated from extensive public discourses on the ancient Indian philosophy of Advaita Vedanta. We develop and benchmark a RAG model against a standard, non-RAG LLM, focusing on transcription, retrieval, and generation performance. Human evaluations by computational linguists and domain experts show that the RAG model significantly outperforms the standard model in producing factual and comprehensive responses having fewer hallucinations. In addition, a keyword-based hybrid retriever that emphasizes unique low-frequency terms further improves results. Our study provides insights into effectively integrating modern large language models with ancient knowledge systems. Project page with dataset and code: https://sites.google.com/view/vedantany-10m
ScrewMimic: Bimanual Imitation from Human Videos with Screw Space Projection
May 06, 2024Bimanual manipulation is a longstanding challenge in robotics due to the large number of degrees of freedom and the strict spatial and temporal synchronization required to generate meaningful behavior. Humans learn bimanual manipulation skills by watching other humans and by refining their abilities through play. In this work, we aim to enable robots to learn bimanual manipulation behaviors from human video demonstrations and fine-tune them through interaction. Inspired by seminal work in psychology and biomechanics, we propose modeling the interaction between two hands as a serial kinematic linkage -- as a screw motion, in particular, that we use to define a new action space for bimanual manipulation: screw actions. We introduce ScrewMimic, a framework that leverages this novel action representation to facilitate learning from human demonstration and self-supervised policy fine-tuning. Our experiments demonstrate that ScrewMimic is able to learn several complex bimanual behaviors from a single human video demonstration, and that it outperforms baselines that interpret demonstrations and fine-tune directly in the original space of motion of both arms. For more information and video results, https://robin-lab.cs.utexas.edu/ScrewMimic/
Sparse Meets Dense: A Hybrid Approach to Enhance Scientific Document Retrieval
Jan 08, 2024



Traditional information retrieval is based on sparse bag-of-words vector representations of documents and queries. More recent deep-learning approaches have used dense embeddings learned using a transformer-based large language model. We show that on a classic benchmark on scientific document retrieval in the medical domain of cystic fibrosis, that both of these models perform roughly equivalently. Notably, dense vectors from the state-of-the-art SPECTER2 model do not significantly enhance performance. However, a hybrid model that we propose combining these methods yields significantly better results, underscoring the merits of integrating classical and contemporary deep learning techniques in information retrieval in the domain of specialized scientific documents.
DexVIP: Learning Dexterous Grasping with Human Hand Pose Priors from Video
Feb 01, 2022
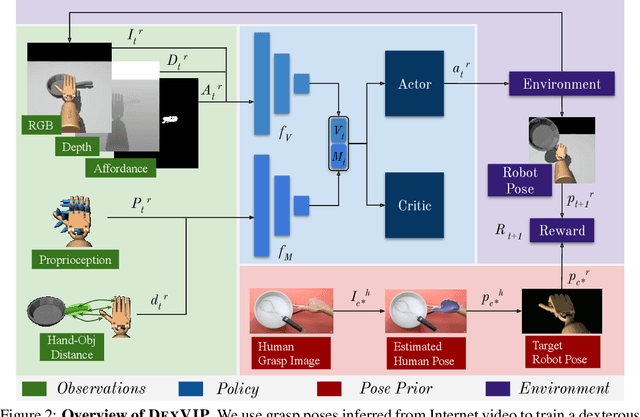

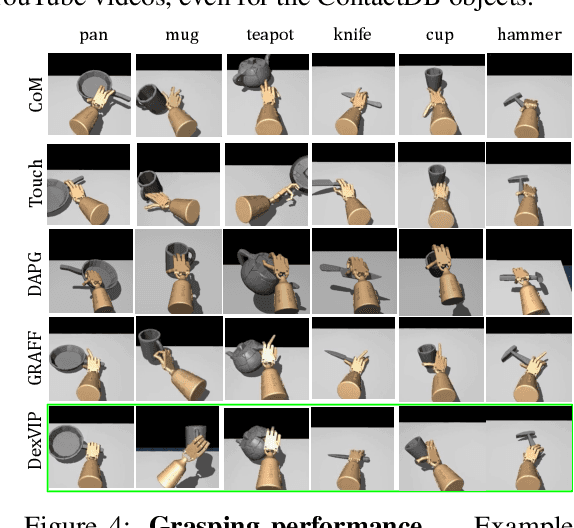
Dexterous multi-fingered robotic hands have a formidable action space, yet their morphological similarity to the human hand holds immense potential to accelerate robot learning. We propose DexVIP, an approach to learn dexterous robotic grasping from human-object interactions present in in-the-wild YouTube videos. We do this by curating grasp images from human-object interaction videos and imposing a prior over the agent's hand pose when learning to grasp with deep reinforcement learning. A key advantage of our method is that the learned policy is able to leverage free-form in-the-wild visual data. As a result, it can easily scale to new objects, and it sidesteps the standard practice of collecting human demonstrations in a lab -- a much more expensive and indirect way to capture human expertise. Through experiments on 27 objects with a 30-DoF simulated robot hand, we demonstrate that DexVIP compares favorably to existing approaches that lack a hand pose prior or rely on specialized tele-operation equipment to obtain human demonstrations, while also being faster to train. Project page: https://vision.cs.utexas.edu/projects/dexvip-dexterous-grasp-pose-prior
Dexterous Robotic Grasping with Object-Centric Visual Affordances
Sep 03, 2020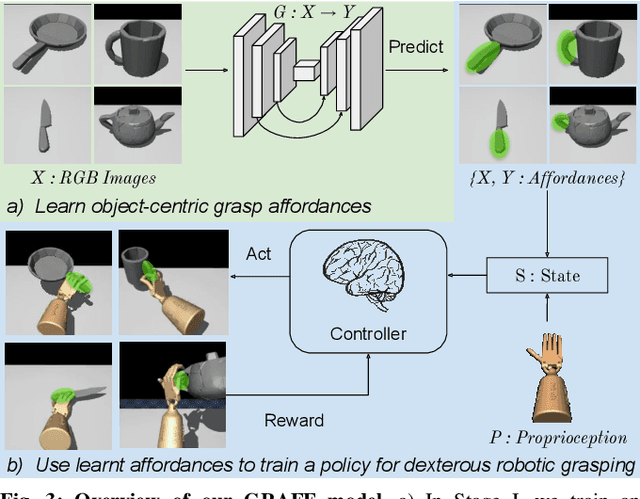
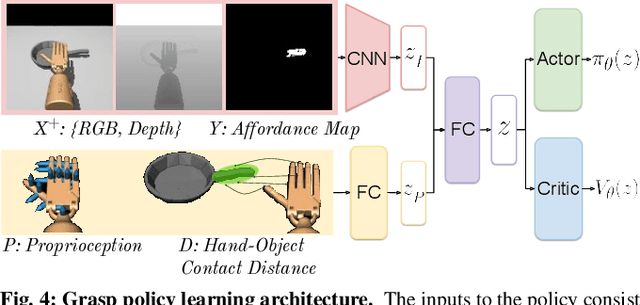

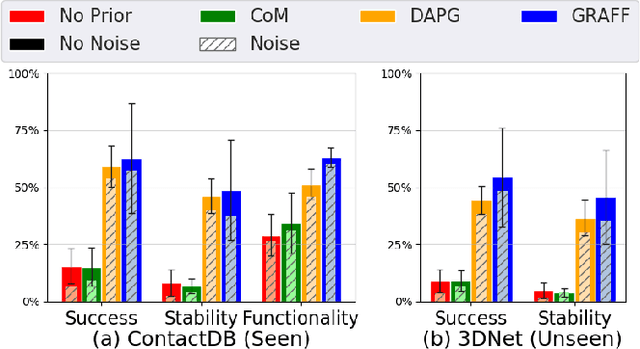
Dexterous robotic hands are appealing for their agility and human-like morphology, yet their high degree of freedom makes learning to manipulate challenging. We introduce an approach for learning dexterous grasping. Our key idea is to embed an object-centric visual affordance model within a deep reinforcement learning loop to learn grasping policies that favor the same object regions favored by people. Unlike traditional approaches that learn from human demonstration trajectories (e.g., hand joint sequences captured with a glove), the proposed prior is object-centric and image-based, allowing the agent to anticipate useful affordance regions for objects unseen during policy learning. We demonstrate our idea with a 30-DoF five-fingered robotic hand simulator on 40 objects from two datasets, where it successfully and efficiently learns policies for stable grasps. Our affordance-guided policies are significantly more effective, generalize better to novel objects, and train 3 X faster than the baselines. Our work offers a step towards manipulation agents that learn by watching how people use objects, without requiring state and action information about the human body. Project website: http://vision.cs.utexas.edu/projects/graff-dexterous-affordance-grasp
Dense 3D Point Cloud Reconstruction Using a Deep Pyramid Network
Jan 25, 2019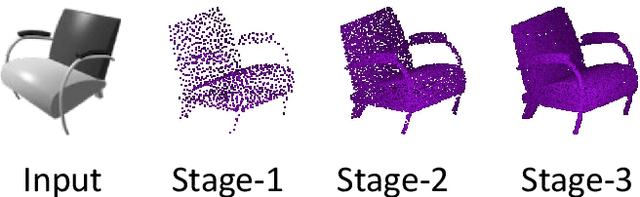
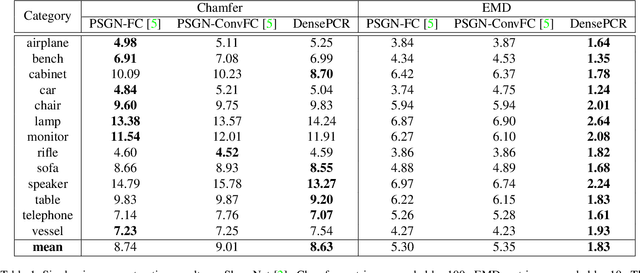
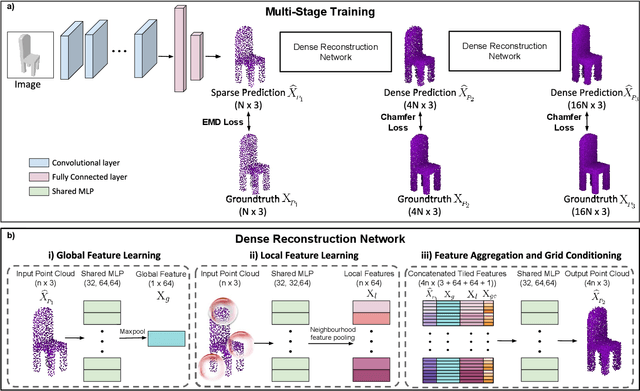
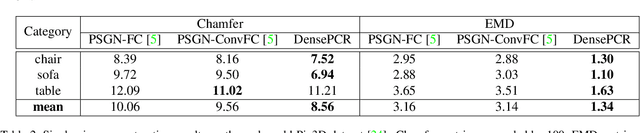
Reconstructing a high-resolution 3D model of an object is a challenging task in computer vision. Designing scalable and light-weight architectures is crucial while addressing this problem. Existing point-cloud based reconstruction approaches directly predict the entire point cloud in a single stage. Although this technique can handle low-resolution point clouds, it is not a viable solution for generating dense, high-resolution outputs. In this work, we introduce DensePCR, a deep pyramidal network for point cloud reconstruction that hierarchically predicts point clouds of increasing resolution. Towards this end, we propose an architecture that first predicts a low-resolution point cloud, and then hierarchically increases the resolution by aggregating local and global point features to deform a grid. Our method generates point clouds that are accurate, uniform and dense. Through extensive quantitative and qualitative evaluation on synthetic and real datasets, we demonstrate that DensePCR outperforms the existing state-of-the-art point cloud reconstruction works, while also providing a light-weight and scalable architecture for predicting high-resolution outputs.
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision
Nov 28, 2018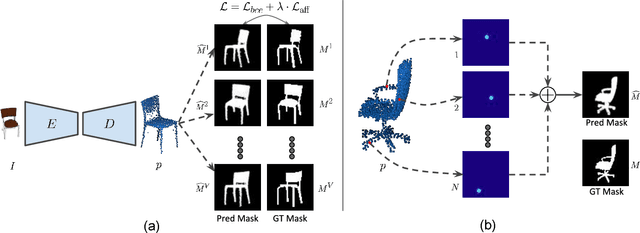

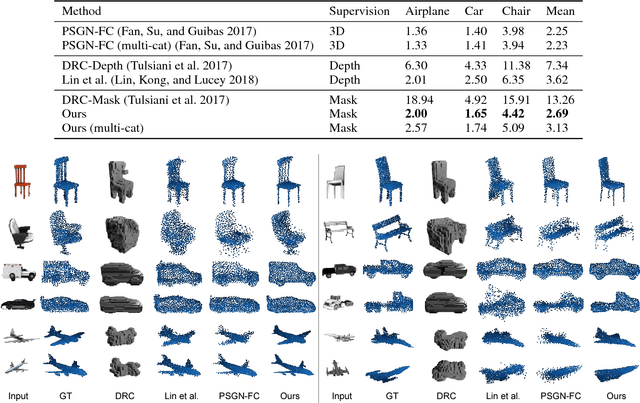
Knowledge of 3D properties of objects is a necessity in order to build effective computer vision systems. However, lack of large scale 3D datasets can be a major constraint for data-driven approaches in learning such properties. We consider the task of single image 3D point cloud reconstruction, and aim to utilize multiple foreground masks as our supervisory data to alleviate the need for large scale 3D datasets. A novel differentiable projection module, called 'CAPNet', is introduced to obtain such 2D masks from a predicted 3D point cloud. The key idea is to model the projections as a continuous approximation of the points in the point cloud. To overcome the challenges of sparse projection maps, we propose a loss formulation termed 'affinity loss' to generate outlier-free reconstructions. We significantly outperform the existing projection based approaches on a large-scale synthetic dataset. We show the utility and generalizability of such a 2D supervised approach through experiments on a real-world dataset, where lack of 3D data can be a serious concern. To further enhance the reconstructions, we also propose a test stage optimization procedure to obtain reconstructions that display high correspondence with the observed input image.
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image
Sep 30, 2018
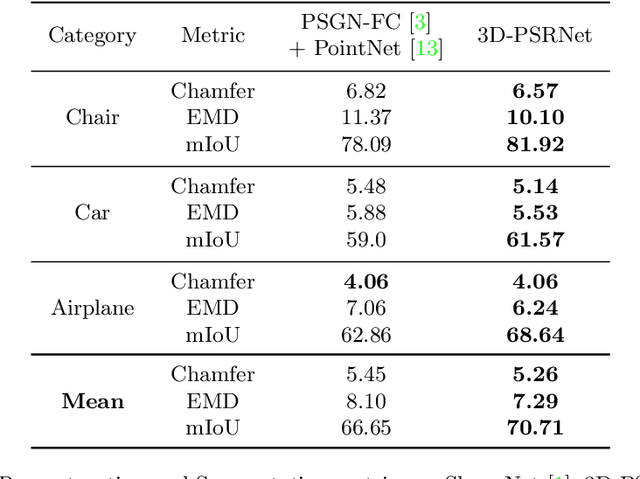
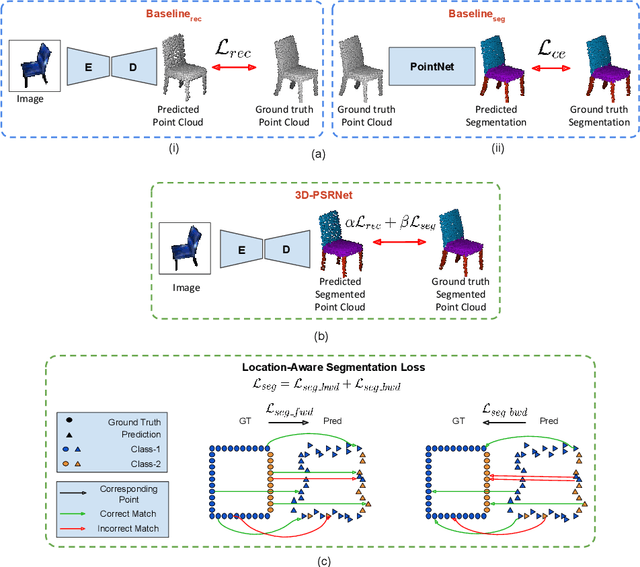
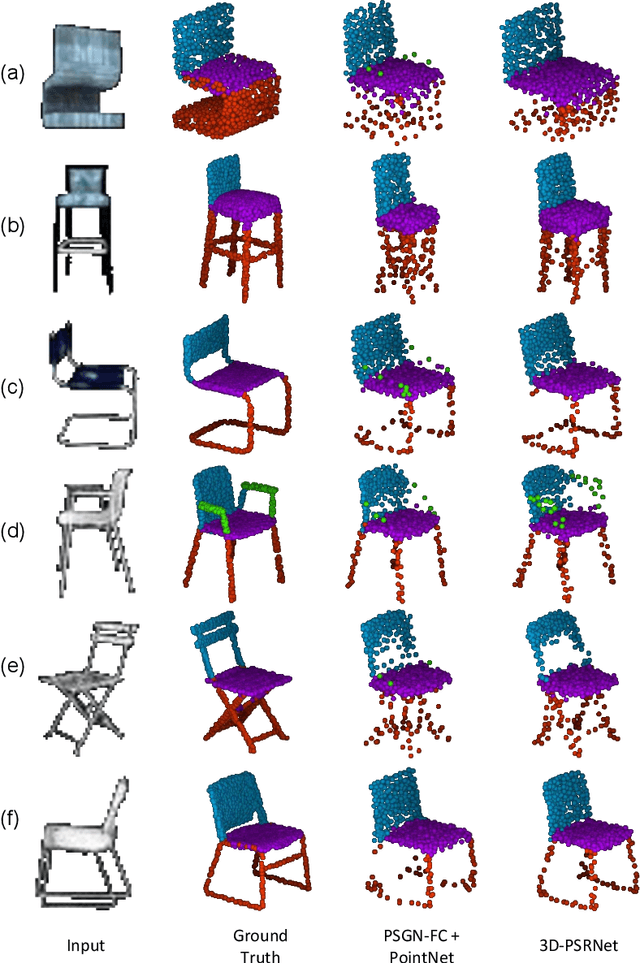
We propose a mechanism to reconstruct part annotated 3D point clouds of objects given just a single input image. We demonstrate that jointly training for both reconstruction and segmentation leads to improved performance in both the tasks, when compared to training for each task individually. The key idea is to propagate information from each task so as to aid the other during the training procedure. Towards this end, we introduce a location-aware segmentation loss in the training regime. We empirically show the effectiveness of the proposed loss in generating more faithful part reconstructions while also improving segmentation accuracy. We thoroughly evaluate the proposed approach on different object categories from the ShapeNet dataset to obtain improved results in reconstruction as well as segmentation.
3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image
Jul 20, 2018

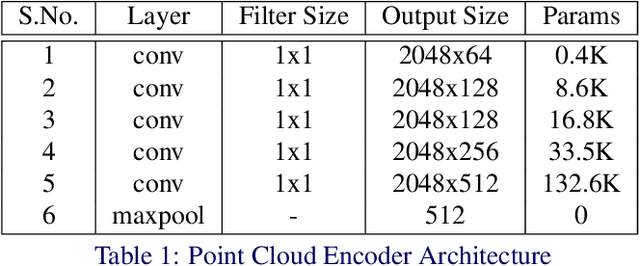

3D reconstruction from single view images is an ill-posed problem. Inferring the hidden regions from self-occluded images is both challenging and ambiguous. We propose a two-pronged approach to address these issues. To better incorporate the data prior and generate meaningful reconstructions, we propose 3D-LMNet, a latent embedding matching approach for 3D reconstruction. We first train a 3D point cloud auto-encoder and then learn a mapping from the 2D image to the corresponding learnt embedding. To tackle the issue of uncertainty in the reconstruction, we predict multiple reconstructions that are consistent with the input view. This is achieved by learning a probablistic latent space with a novel view-specific diversity loss. Thorough quantitative and qualitative analysis is performed to highlight the significance of the proposed approach. We outperform state-of-the-art approaches on the task of single-view 3D reconstruction on both real and synthetic datasets while generating multiple plausible reconstructions, demonstrating the generalizability and utility of our approach.