 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AgentMixer: Multi-Agent Correlated Policy Factorization
Jan 16, 2024
Centralized training with decentralized execution (CTDE) is widely employed to stabilize partially observable multi-agent reinforcement learning (MARL) by utilizing a centralized value function during training. However, existing methods typically assume that agents make decisions based on their local observations independently, which may not lead to a correlated joint policy with sufficient coordination. Inspired by the concept of correlated equilibrium, we propose to introduce a \textit{strategy modification} to provide a mechanism for agents to correlate their policies. Specifically, we present a novel framework, AgentMixer, which constructs the joint fully observable policy as a non-linear combination of individual partially observable policies. To enable decentralized execution, one can derive individual policies by imitating the joint policy. Unfortunately, such imitation learning can lead to \textit{asymmetric learning failure} caused by the mismatch between joint policy and individual policy information. To mitigate this issue, we jointly train the joint policy and individual policies and introduce \textit{Individual-Global-Consistency} to guarantee mode consistency between the centralized and decentralized policies. We then theoretically prove that AgentMixer converges to an $\epsilon$-approximate Correlated Equilibrium. The strong experimental performance on three MARL benchmarks demonstrates the effectiveness of our method.
Knowledge-Centric Templatic Views of Documents
Jan 13, 2024Authors seeking to communicate with broader audiences often compose their ideas about the same underlying knowledge in different documents and formats -- for example, as slide decks, newsletters, reports, brochures, etc. Prior work in document generation has generally considered the creation of each separate format to be different a task, developing independent methods for generation and evaluation. This approach is suboptimal for the advancement of AI-supported content authoring from both research and application perspectives because it leads to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. Thus, in our work, we consider each of these documents to be templatic views of the same underlying knowledge, and we aim to unify the generation and evaluation of these templatic views of documents. We begin by introducing an LLM-powered method to extract the most important information from an input document and represent this information in a structured format. We show that this unified representation can be used to generate multiple templatic views with no supervision and with very little guidance, improving over strong baselines. We additionally introduce a unified evaluation method that is template agnostic, and can be adapted to building document generators for heterogeneous downstream applications. Finally, we conduct a human evaluation, which shows that humans prefer 82% of the downstream documents generated with our method. Furthermore, the newly proposed evaluation metric correlates more highly with human judgement than prior metrics, while providing a unified evaluation method.
LPAC: Learnable Perception-Action-Communication Loops with Applications to Coverage Control
Jan 10, 2024Coverage control is the problem of navigating a robot swarm to collaboratively monitor features or a phenomenon of interest not known a priori. The problem is challenging in decentralized settings with robots that have limited communication and sensing capabilities. This paper proposes a learnable Perception-Action-Communication (LPAC) architecture for the coverage control problem. In the proposed solution, a convolution neural network (CNN) processes localized perception of the environment; a graph neural network (GNN) enables communication of relevant information between neighboring robots; finally, a shallow multi-layer perceptron (MLP) computes robot actions. The GNN in the communication module enables collaboration in the robot swarm by computing what information to communicate with neighbors and how to use received information to take appropriate actions. We train models using imitation learning with a centralized clairvoyant algorithm that is aware of the entire environment. Evaluations show that the LPAC models outperform standard decentralized and centralized coverage control algorithms. The learned policy generalizes to environments different from the training dataset, transfers to larger environments with an increased number of robots, and is robust to noisy position estimates. The results indicate that LPAC architectures are well-suited for decentralized navigation in robot swarms to achieve collaborative behavior.
Limitations of Data-Driven Spectral Reconstruction -- An Optics-Aware Analysis
Jan 08, 2024Hyperspectral imaging empowers computer vision systems with the distinct capability of identifying materials through recording their spectral signatures. Recent efforts in data-driven spectral reconstruction aim at extracting spectral information from RGB images captured by cost-effective RGB cameras, instead of dedicated hardware. In this paper we systematically analyze the performance of such methods, evaluating both the practical limitations with respect to current datasets and overfitting, as well as fundamental limits with respect to the nature of the information encoded in the RGB images, and the dependency of this information on the optical system of the camera. We find that the current models are not robust under slight variations, e.g., in noise level or compression of the RGB file. Both the methods and the datasets are also limited in their ability to cope with metameric colors. This issue can in part be overcome with metameric data augmentation. Moreover, optical lens aberrations can help to improve the encoding of the metameric information into the RGB image, which paves the road towards higher performing spectral imaging and reconstruction approaches.
Transformer-based Video Saliency Prediction with High Temporal Dimension Decoding
Jan 15, 2024In recent years, finding an effective and efficient strategy for exploiting spatial and temporal information has been a hot research topic in video saliency prediction (VSP). With the emergence of spatio-temporal transformers, the weakness of the prior strategies, e.g., 3D convolutional networks and LSTM-based networks, for capturing long-range dependencies has been effectively compensated. While VSP has drawn benefits from spatio-temporal transformers, finding the most effective way for aggregating temporal features is still challenging. To address this concern, we propose a transformer-based video saliency prediction approach with high temporal dimension decoding network (THTD-Net). This strategy accounts for the lack of complex hierarchical interactions between features that are extracted from the transformer-based spatio-temporal encoder: in particular, it does not require multiple decoders and aims at gradually reducing temporal features' dimensions in the decoder. This decoder-based architecture yields comparable performance to multi-branch and over-complicated models on common benchmarks such as DHF1K, UCF-sports and Hollywood-2.
PolMERLIN: Self-Supervised Polarimetric Complex SAR Image Despeckling with Masked Networks
Jan 15, 2024Despeckling is a crucial noise reduction task in improving the quality of synthetic aperture radar (SAR) images. Directly obtaining noise-free SAR images is a challenging task that has hindered the development of accurate despeckling algorithms. The advent of deep learning has facilitated the study of denoising models that learn from only noisy SAR images. However, existing methods deal solely with single-polarization images and cannot handle the multi-polarization images captured by modern satellites. In this work, we present an extension of the existing model for generating single-polarization SAR images to handle multi-polarization SAR images. Specifically, we propose a novel self-supervised despeckling approach called channel masking, which exploits the relationship between polarizations. Additionally, we utilize a spatial masking method that addresses pixel-to-pixel correlations to further enhance the performance of our approach. By effectively incorporating multiple polarization information, our method surpasses current state-of-the-art methods in quantitative evaluation in both synthetic and real-world scenarios.
Contrastive Loss Based Frame-wise Feature disentanglement for Polyphonic Sound Event Detection
Jan 11, 2024Overlapping sound events are ubiquitous in real-world environments, but existing end-to-end sound event detection (SED) methods still struggle to detect them effectively. A critical reason is that these methods represent overlapping events using shared and entangled frame-wise features, which degrades the feature discrimination. To solve the problem, we propose a disentangled feature learning framework to learn a category-specific representation. Specifically, we employ different projectors to learn the frame-wise features for each category. To ensure that these feature does not contain information of other categories, we maximize the common information between frame-wise features within the same category and propose a frame-wise contrastive loss. In addition, considering that the labeled data used by the proposed method is limited, we propose a semi-supervised frame-wise contrastive loss that can leverage large amounts of unlabeled data to achieve feature disentanglement. The experimental results demonstrate the effectiveness of our method.
Singular Regularization with Information Bottleneck Improves Model's Adversarial Robustness
Dec 04, 2023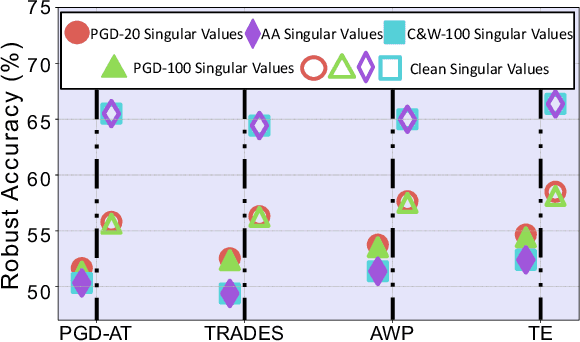
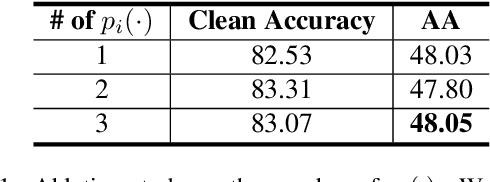

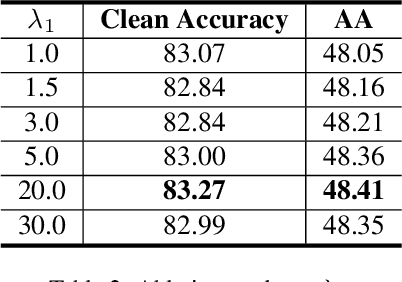
Adversarial examples are one of the most severe threats to deep learning models. Numerous works have been proposed to study and defend adversarial examples. However, these works lack analysis of adversarial information or perturbation, which cannot reveal the mystery of adversarial examples and lose proper interpretation. In this paper, we aim to fill this gap by studying adversarial information as unstructured noise, which does not have a clear pattern. Specifically, we provide some empirical studies with singular value decomposition, by decomposing images into several matrices, to analyze adversarial information for different attacks. Based on the analysis, we propose a new module to regularize adversarial information and combine information bottleneck theory, which is proposed to theoretically restrict intermediate representations. Therefore, our method is interpretable. Moreover, the fashion of our design is a novel principle that is general and unified. Equipped with our new module, we evaluate two popular model structures on two mainstream datasets with various adversarial attacks. The results indicate that the improvement in robust accuracy is significant. On the other hand, we prove that our method is efficient with only a few additional parameters and able to be explained under regional faithfulness analysis.
Automatic 3D Multi-modal Ultrasound Segmentation of Human Placenta using Fusion Strategies and Deep Learning
Jan 17, 2024Purpose: Ultrasound is the most commonly used medical imaging modality for diagnosis and screening in clinical practice. Due to its safety profile, noninvasive nature and portability, ultrasound is the primary imaging modality for fetal assessment in pregnancy. Current ultrasound processing methods are either manual or semi-automatic and are therefore laborious, time-consuming and prone to errors, and automation would go a long way in addressing these challenges. Automated identification of placental changes at earlier gestation could facilitate potential therapies for conditions such as fetal growth restriction and pre-eclampsia that are currently detected only at late gestational age, potentially preventing perinatal morbidity and mortality. Methods: We propose an automatic three-dimensional multi-modal (B-mode and power Doppler) ultrasound segmentation of the human placenta using deep learning combined with different fusion strategies.We collected data containing Bmode and power Doppler ultrasound scans for 400 studies. Results: We evaluated different fusion strategies and state-of-the-art image segmentation networks for placenta segmentation based on standard overlap- and boundary-based metrics. We found that multimodal information in the form of B-mode and power Doppler scans outperform any single modality. Furthermore, we found that B-mode and power Doppler input scans fused at the data level provide the best results with a mean Dice Similarity Coefficient (DSC) of 0.849. Conclusion: We conclude that the multi-modal approach of combining B-mode and power Doppler scans is effective in segmenting the placenta from 3D ultrasound scans in a fully automated manner and is robust to quality variation of the datasets.
Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
Jan 12, 2024Large language models (LLMs) are capable of many natural language tasks, yet they are far from perfect. In health applications, grounding and interpreting domain-specific and non-linguistic data is important. This paper investigates the capacity of LLMs to deliver multi-modal health predictions based on contextual information (e.g. user demographics, health knowledge) and physiological data (e.g. resting heart rate, sleep minutes). We present a comprehensive evaluation of eight state-of-the-art LLMs with diverse prompting and fine-tuning techniques on six public health datasets (PM-Data, LifeSnaps, GLOBEM, AW_FB, MIT-BIH & MIMIC-III). Our experiments cover thirteen consumer health prediction tasks in mental health, activity, metabolic, sleep, and cardiac assessment. Our fine-tuned model, Health-Alpaca exhibits comparable performance to larger models (GPT-3.5 and GPT-4), achieving the best performance in 5 out of 13 tasks. Ablation studies highlight the effectiveness of context enhancement strategies, and generalization capability of the fine-tuned models across training datasets and the size of training samples. Notably, we observe that our context enhancement can yield up to 23.8% improvement in performance. While constructing contextually rich prompts (combining user context, health knowledge and temporal information) exhibits synergistic improvement, the inclusion of health knowledge context in prompts significantly enhances overall performance.