 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Covid-19 risk factors: Statistical learning from German healthcare claims data
Feb 04, 2021
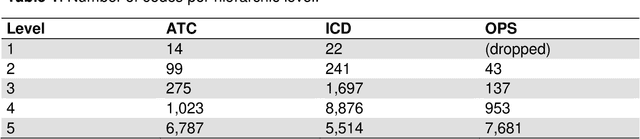
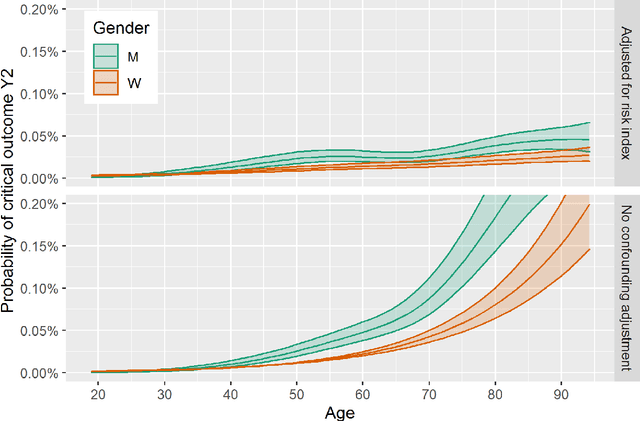
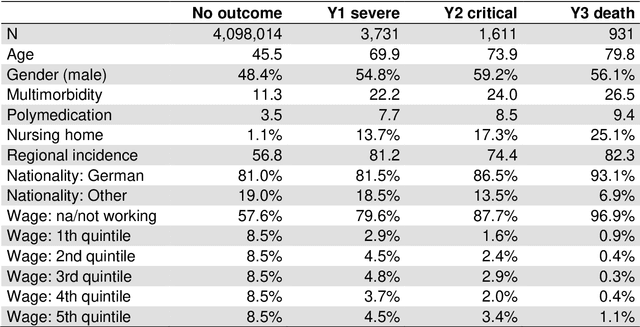
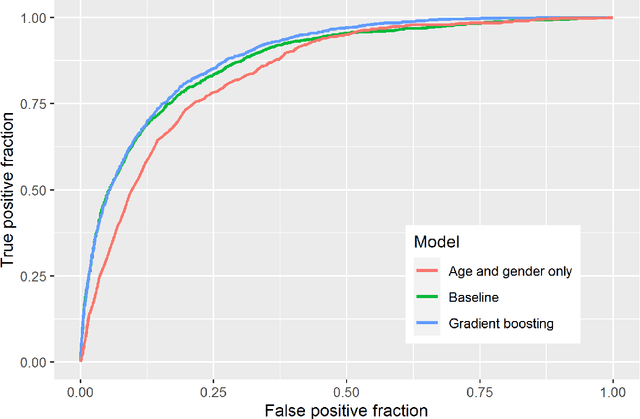
We analyse prior risk factors for severe, critical or fatal courses of Covid-19 based on a retrospective cohort study using claims data of the AOK Bayern. As a methodological contribution, we avoid prior grouping and pre-selection of candidate risk factors and use fine-grained hierarchical information from medical classification systems for diagnoses, pharmaceuticals and procedures, using more than 33,000 covariates. Our approach is competitive to formal analyses using well-specified morbidity groups without needing prior subject-matter knowledge. The methodology and our published coefficients may be of interest for decision makers when prioritizing protective measures towards vulnerable subpopulations as well as for researchers aiming to adjust for confounders in studies of individual risk factors also for smaller cohorts.
Attention, please! A survey of Neural Attention Models in Deep Learning
Mar 31, 2021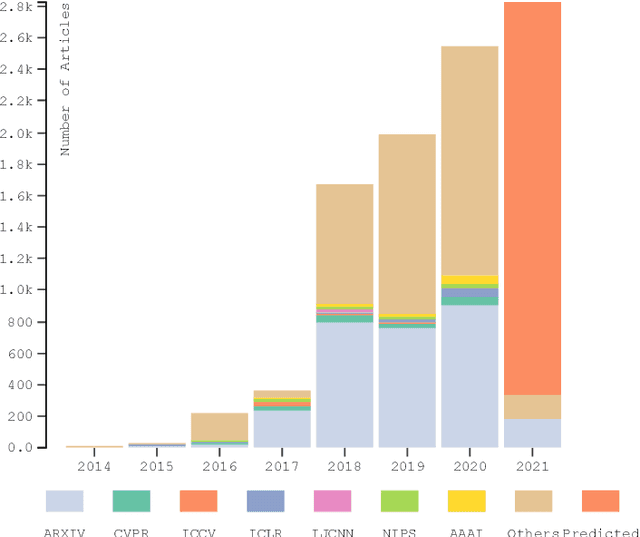
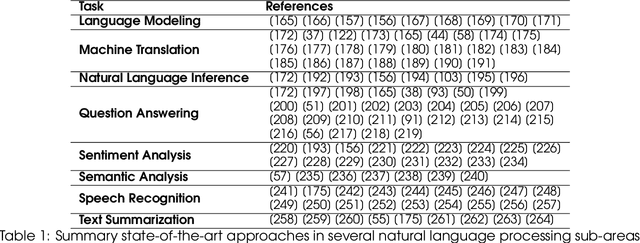
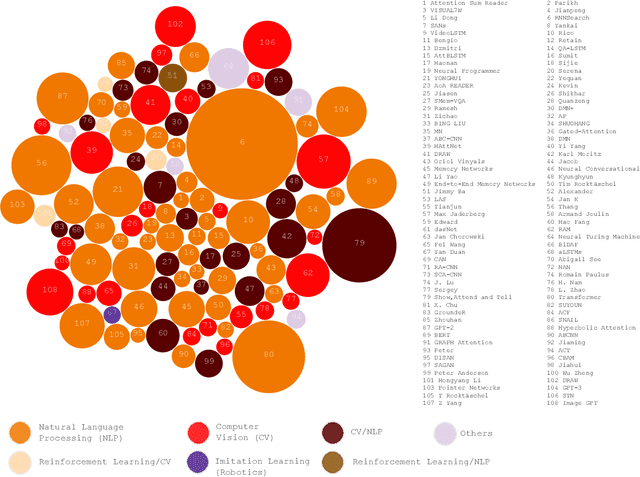
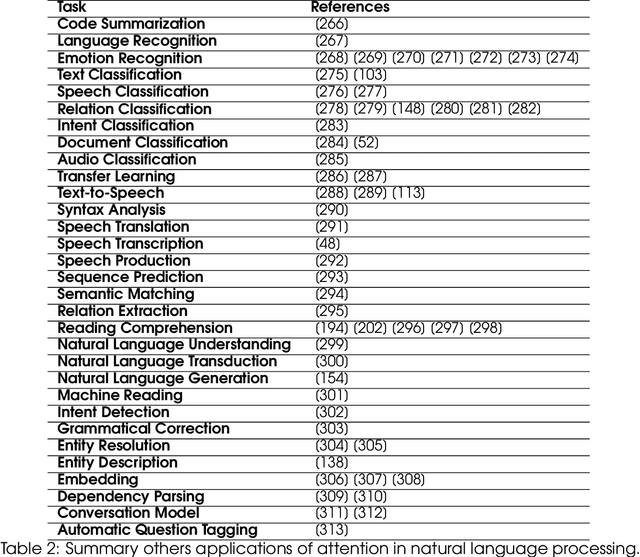
In humans, Attention is a core property of all perceptual and cognitive operations. Given our limited ability to process competing sources, attention mechanisms select, modulate, and focus on the information most relevant to behavior. For decades, concepts and functions of attention have been studied in philosophy, psychology, neuroscience, and computing. For the last six years, this property has been widely explored in deep neural networks. Currently, the state-of-the-art in Deep Learning is represented by neural attention models in several application domains. This survey provides a comprehensive overview and analysis of developments in neural attention models. We systematically reviewed hundreds of architectures in the area, identifying and discussing those in which attention has shown a significant impact. We also developed and made public an automated methodology to facilitate the development of reviews in the area. By critically analyzing 650 works, we describe the primary uses of attention in convolutional, recurrent networks and generative models, identifying common subgroups of uses and applications. Furthermore, we describe the impact of attention in different application domains and their impact on neural networks' interpretability. Finally, we list possible trends and opportunities for further research, hoping that this review will provide a succinct overview of the main attentional models in the area and guide researchers in developing future approaches that will drive further improvements.
Actionable Cognitive Twins for Decision Making in Manufacturing
Mar 23, 2021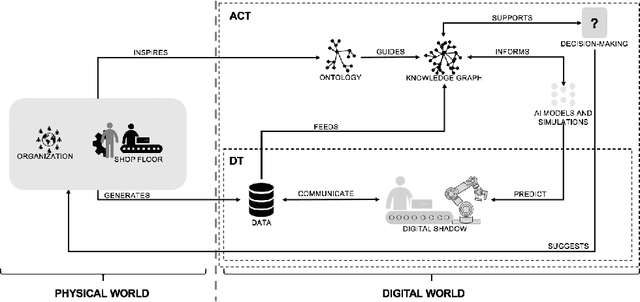
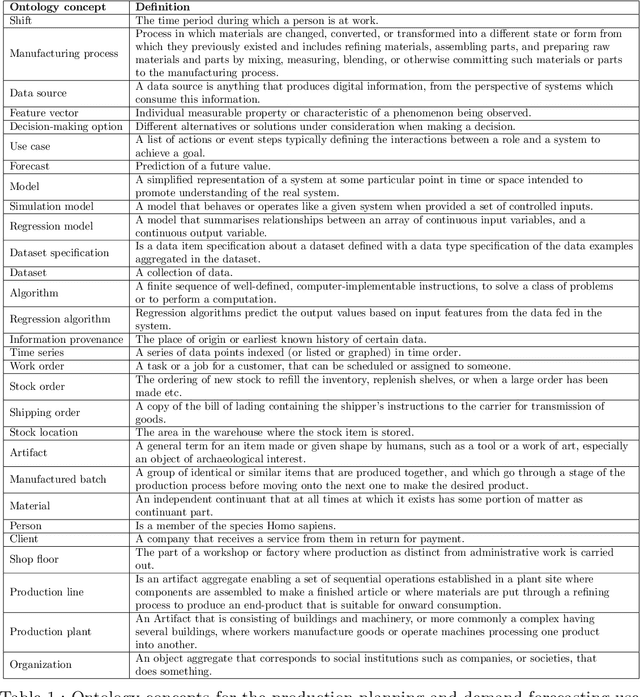
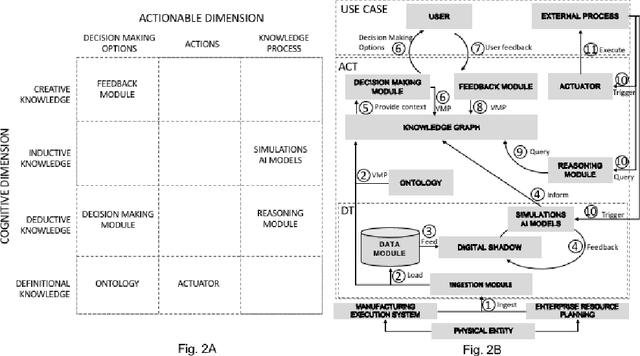
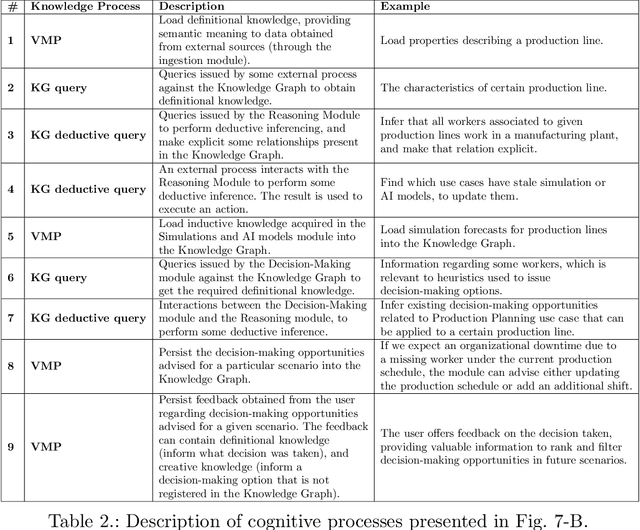
Actionable Cognitive Twins are the next generation Digital Twins enhanced with cognitive capabilities through a knowledge graph and artificial intelligence models that provide insights and decision-making options to the users. The knowledge graph describes the domain-specific knowledge regarding entities and interrelationships related to a manufacturing setting. It also contains information on possible decision-making options that can assist decision-makers, such as planners or logisticians. In this paper, we propose a knowledge graph modeling approach to construct actionable cognitive twins for capturing specific knowledge related to demand forecasting and production planning in a manufacturing plant. The knowledge graph provides semantic descriptions and contextualization of the production lines and processes, including data identification and simulation or artificial intelligence algorithms and forecasts used to support them. Such semantics provide ground for inferencing, relating different knowledge types: creative, deductive, definitional, and inductive. To develop the knowledge graph models for describing the use case completely, systems thinking approach is proposed to design and verify the ontology, develop a knowledge graph and build an actionable cognitive twin. Finally, we evaluate our approach in two use cases developed for a European original equipment manufacturer related to the automotive industry as part of the European Horizon 2020 project FACTLOG.
Retrieve-and-Read: Multi-task Learning of Information Retrieval and Reading Comprehension
Aug 31, 2018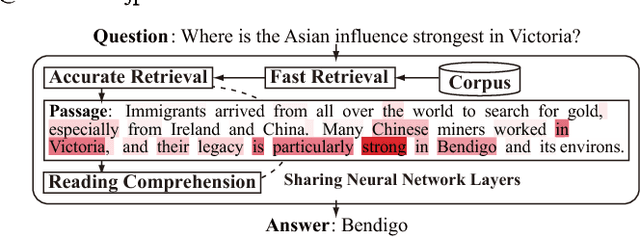
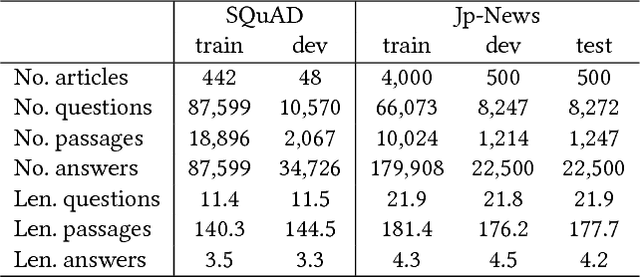
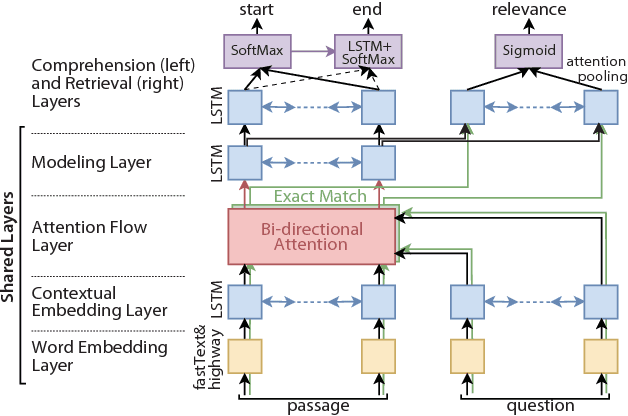
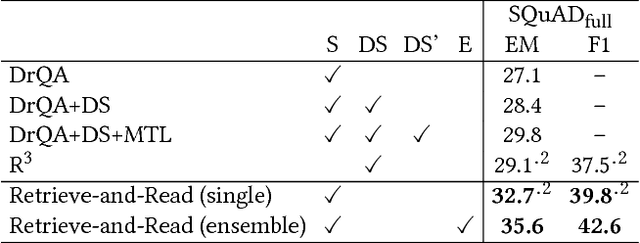
This study considers the task of machine reading at scale (MRS) wherein, given a question, a system first performs the information retrieval (IR) task of finding relevant passages in a knowledge source and then carries out the reading comprehension (RC) task of extracting an answer span from the passages. Previous MRS studies, in which the IR component was trained without considering answer spans, struggled to accurately find a small number of relevant passages from a large set of passages. In this paper, we propose a simple and effective approach that incorporates the IR and RC tasks by using supervised multi-task learning in order that the IR component can be trained by considering answer spans. Experimental results on the standard benchmark, answering SQuAD questions using the full Wikipedia as the knowledge source, showed that our model achieved state-of-the-art performance. Moreover, we thoroughly evaluated the individual contributions of our model components with our new Japanese dataset and SQuAD. The results showed significant improvements in the IR task and provided a new perspective on IR for RC: it is effective to teach which part of the passage answers the question rather than to give only a relevance score to the whole passage.
* 10 pages, 6 figure. Accepted as a full paper at CIKM 2018
Towards More Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark
Mar 31, 2021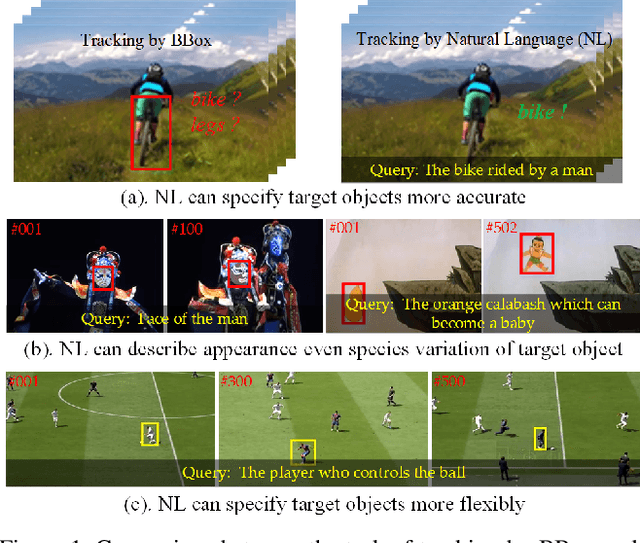
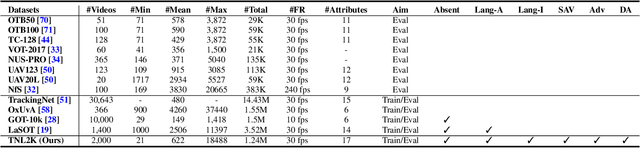

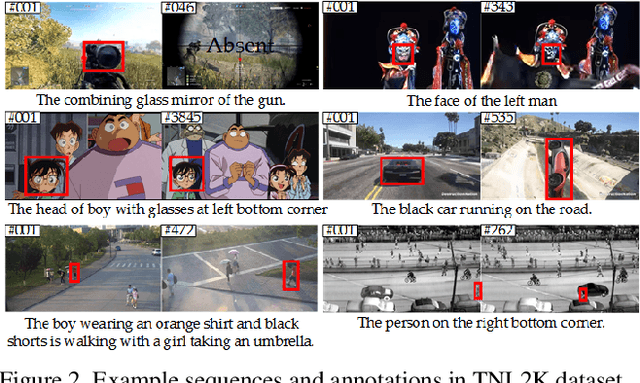
Tracking by natural language specification is a new rising research topic that aims at locating the target object in the video sequence based on its language description. Compared with traditional bounding box (BBox) based tracking, this setting guides object tracking with high-level semantic information, addresses the ambiguity of BBox, and links local and global search organically together. Those benefits may bring more flexible, robust and accurate tracking performance in practical scenarios. However, existing natural language initialized trackers are developed and compared on benchmark datasets proposed for tracking-by-BBox, which can't reflect the true power of tracking-by-language. In this work, we propose a new benchmark specifically dedicated to the tracking-by-language, including a large scale dataset, strong and diverse baseline methods. Specifically, we collect 2k video sequences (contains a total of 1,244,340 frames, 663 words) and split 1300/700 for the train/testing respectively. We densely annotate one sentence in English and corresponding bounding boxes of the target object for each video. We also introduce two new challenges into TNL2K for the object tracking task, i.e., adversarial samples and modality switch. A strong baseline method based on an adaptive local-global-search scheme is proposed for future works to compare. We believe this benchmark will greatly boost related researches on natural language guided tracking.
Adaptive Semiparametric Language Models
Feb 04, 2021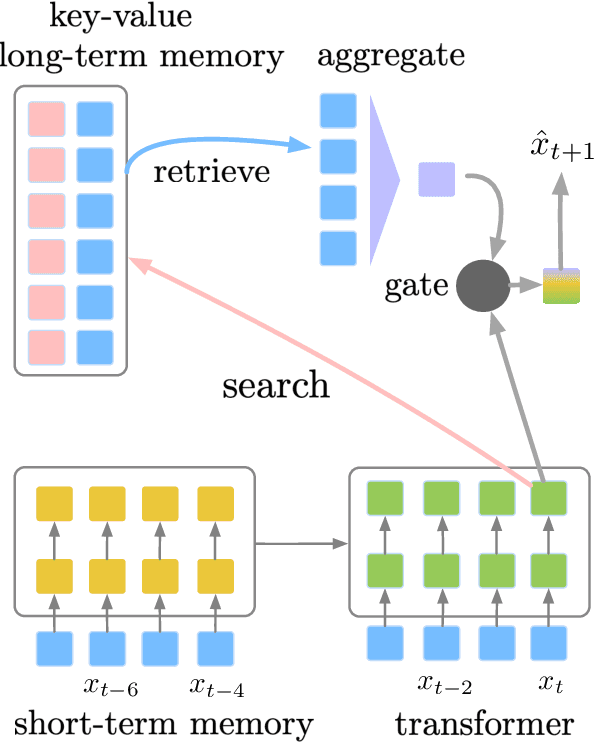
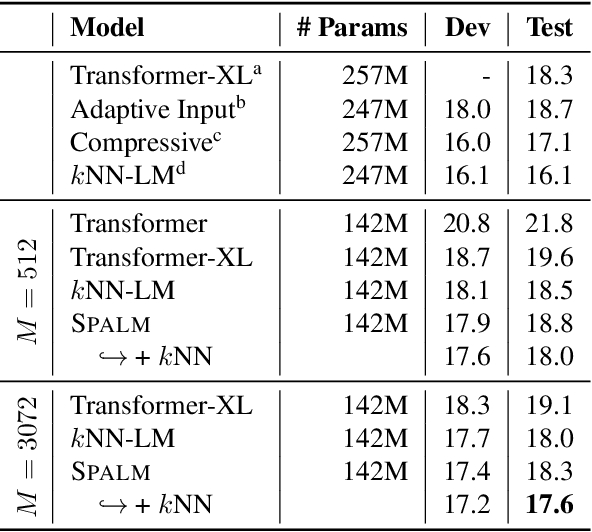
We present a language model that combines a large parametric neural network (i.e., a transformer) with a non-parametric episodic memory component in an integrated architecture. Our model uses extended short-term context by caching local hidden states -- similar to transformer-XL -- and global long-term memory by retrieving a set of nearest neighbor tokens at each timestep. We design a gating function to adaptively combine multiple information sources to make a prediction. This mechanism allows the model to use either local context, short-term memory, or long-term memory (or any combination of them) on an ad hoc basis depending on the context. Experiments on word-based and character-based language modeling datasets demonstrate the efficacy of our proposed method compared to strong baselines.
Multilingual Knowledge Graph Completion with Joint Relation and Entity Alignment
Apr 18, 2021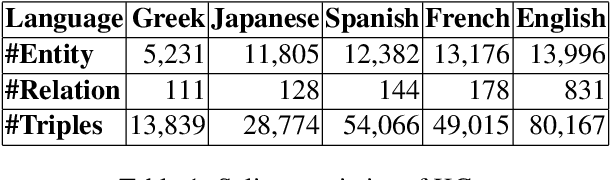
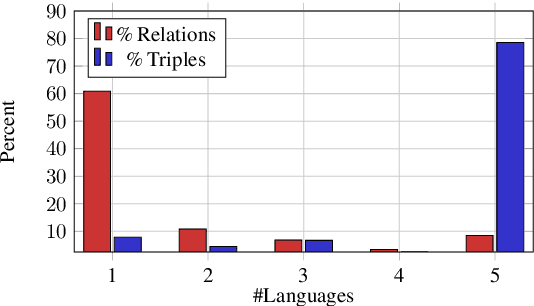
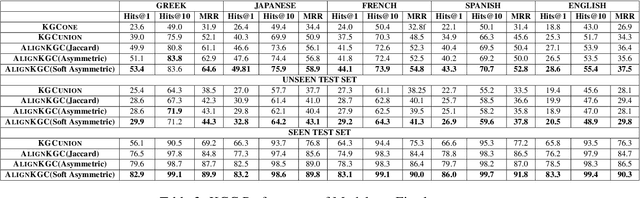

Knowledge Graph Completion (KGC) predicts missing facts in an incomplete Knowledge Graph. Almost all of existing KGC research is applicable to only one KG at a time, and in one language only. However, different language speakers may maintain separate KGs in their language and no individual KG is expected to be complete. Moreover, common entities or relations in these KGs have different surface forms and IDs, leading to ID proliferation. Entity alignment (EA) and relation alignment (RA) tasks resolve this by recognizing pairs of entity (relation) IDs in different KGs that represent the same entity (relation). This can further help prediction of missing facts, since knowledge from one KG is likely to benefit completion of another. High confidence predictions may also add valuable information for the alignment tasks. In response, we study the novel task of jointly training multilingual KGC, relation alignment and entity alignment models. We present ALIGNKGC, which uses some seed alignments to jointly optimize all three of KGC, EA and RA losses. A key component of ALIGNKGC is an embedding based soft notion of asymmetric overlap defined on the (subject, object) set signatures of relations this aids in better predicting relations that are equivalent to or implied by other relations. Extensive experiments with DBPedia in five languages establish the benefits of joint training for all tasks, achieving 10-32 MRR improvements of ALIGNKGC over a strong state-of-the-art single-KGC system completion model over each monolingual KG . Further, ALIGNKGC achieves reasonable gains in EA and RA tasks over a vanilla completion model over a KG that combines all facts without alignment, underscoring the value of joint training for these tasks.
Denoise and Contrast for Category Agnostic Shape Completion
Mar 30, 2021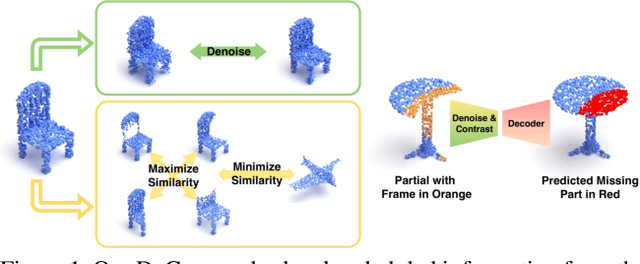
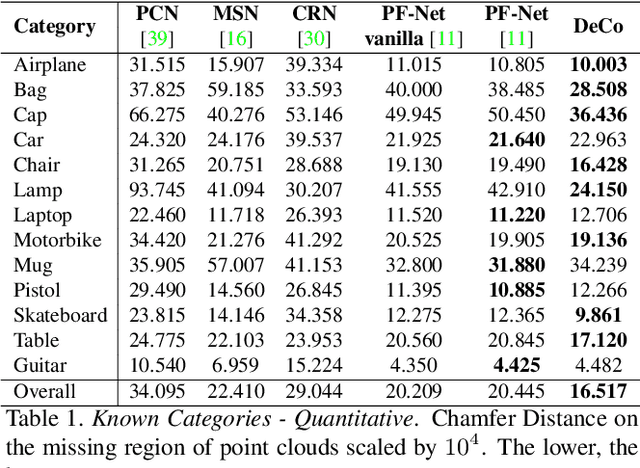
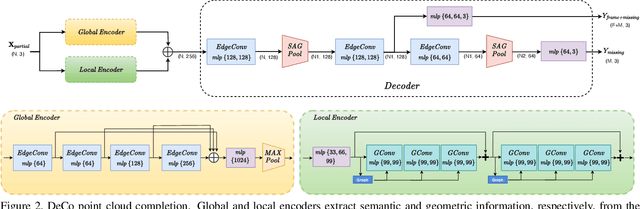
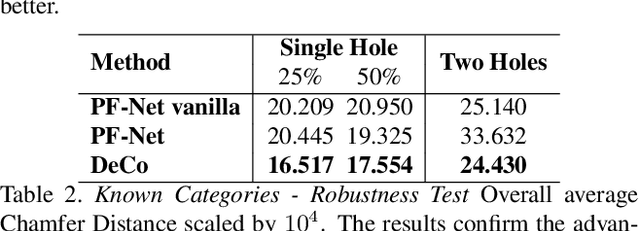
In this paper, we present a deep learning model that exploits the power of self-supervision to perform 3D point cloud completion, estimating the missing part and a context region around it. Local and global information are encoded in a combined embedding. A denoising pretext task provides the network with the needed local cues, decoupled from the high-level semantics and naturally shared over multiple classes. On the other hand, contrastive learning maximizes the agreement between variants of the same shape with different missing portions, thus producing a representation which captures the global appearance of the shape. The combined embedding inherits category-agnostic properties from the chosen pretext tasks. Differently from existing approaches, this allows to better generalize the completion properties to new categories unseen at training time. Moreover, while decoding the obtained joint representation, we better blend the reconstructed missing part with the partial shape by paying attention to its known surrounding region and reconstructing this frame as auxiliary objective. Our extensive experiments and detailed ablation on the ShapeNet dataset show the effectiveness of each part of the method with new state of the art results. Our quantitative and qualitative analysis confirms how our approach is able to work on novel categories without relying neither on classification and shape symmetry priors, nor on adversarial training procedures.
Structure-aware Pre-training for Table Understanding with Tree-based Transformers
Oct 21, 2020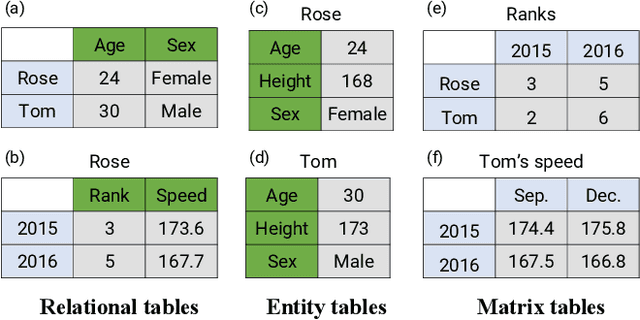
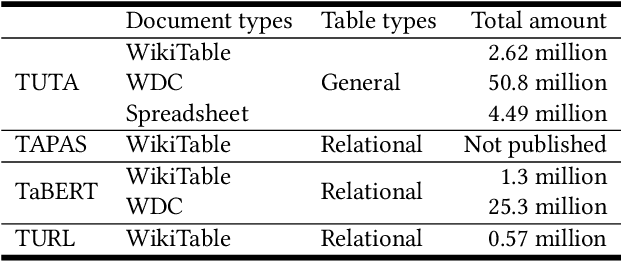
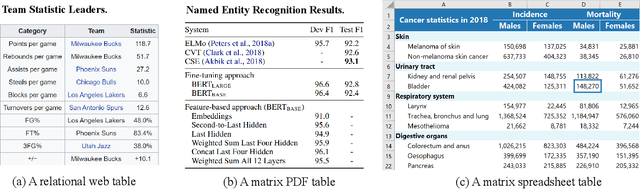

Tables are widely used with various structures to organize and present data. Recent attempts on table understanding mainly focus on relational tables, yet overlook to other common table structures. In this paper, we propose TUTA, a unified pre-training architecture for understanding generally structured tables. Since understanding a table needs to leverage both spatial, hierarchical, and semantic information, we adapt the self-attention strategy with several key structure-aware mechanisms. First, we propose a novel tree-based structure called a bi-dimensional coordinate tree, to describe both the spatial and hierarchical information in tables. Upon this, we extend the pre-training architecture with two core mechanisms, namely the tree-based attention and tree-based position embedding. Moreover, to capture table information in a progressive manner, we devise three pre-training objectives to enable representations at the token, cell, and table levels. TUTA pre-trains on a wide range of unlabeled tables and fine-tunes on a critical task in the field of table structure understanding, i.e. cell type classification. Experiment results show that TUTA is highly effective, achieving state-of-the-art on four well-annotated cell type classification datasets.
Towards interpretability of Mixtures of Hidden Markov Models
Mar 23, 2021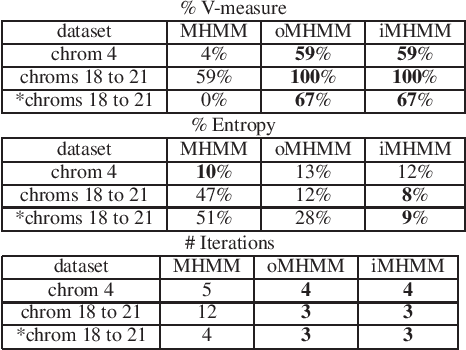
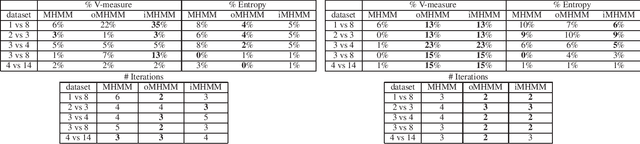
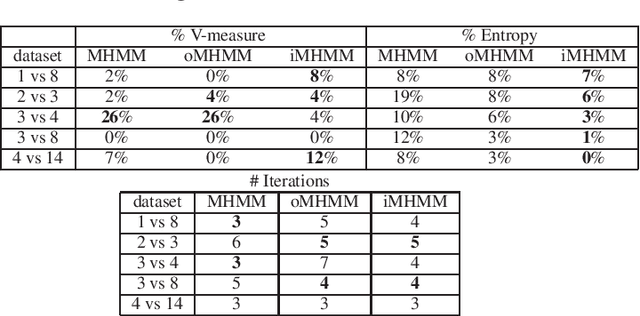
Mixtures of Hidden Markov Models (MHMMs) are frequently used for clustering of sequential data. An important aspect of MHMMs, as of any clustering approach, is that they can be interpretable, allowing for novel insights to be gained from the data. However, without a proper way of measuring interpretability, the evaluation of novel contributions is difficult and it becomes practically impossible to devise techniques that directly optimize this property. In this work, an information-theoretic measure (entropy) is proposed for interpretability of MHMMs, and based on that, a novel approach to improve model interpretability is proposed, i.e., an entropy-regularized Expectation Maximization (EM) algorithm. The new approach aims for reducing the entropy of the Markov chains (involving state transition matrices) within an MHMM, i.e., assigning higher weights to common state transitions during clustering. It is argued that this entropy reduction, in general, leads to improved interpretability since the most influential and important state transitions of the clusters can be more easily identified. An empirical investigation shows that it is possible to improve the interpretability of MHMMs, as measured by entropy, without sacrificing (but rather improving) clustering performance and computational costs, as measured by the v-measure and number of EM iterations, respectively.