 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction via Shapley Value Regression
May 07, 2025



Shapley values have several desirable, theoretically well-supported, properties for explaining black-box model predictions. Traditionally, Shapley values are computed post-hoc, leading to additional computational cost at inference time. To overcome this, a novel method, called ViaSHAP, is proposed, that learns a function to compute Shapley values, from which the predictions can be derived directly by summation. Two approaches to implement the proposed method are explored; one based on the universal approximation theorem and the other on the Kolmogorov-Arnold representation theorem. Results from a large-scale empirical investigation are presented, showing that ViaSHAP using Kolmogorov-Arnold Networks performs on par with state-of-the-art algorithms for tabular data. It is also shown that the explanations of ViaSHAP are significantly more accurate than the popular approximator FastSHAP on both tabular data and images.
Obtaining Example-Based Explanations from Deep Neural Networks
Feb 27, 2025



Most techniques for explainable machine learning focus on feature attribution, i.e., values are assigned to the features such that their sum equals the prediction. Example attribution is another form of explanation that assigns weights to the training examples, such that their scalar product with the labels equals the prediction. The latter may provide valuable complementary information to feature attribution, in particular in cases where the features are not easily interpretable. Current example-based explanation techniques have targeted a few model types only, such as k-nearest neighbors and random forests. In this work, a technique for obtaining example-based explanations from deep neural networks (EBE-DNN) is proposed. The basic idea is to use the deep neural network to obtain an embedding, which is employed by a k-nearest neighbor classifier to form a prediction; the example attribution can hence straightforwardly be derived from the latter. Results from an empirical investigation show that EBE-DNN can provide highly concentrated example attributions, i.e., the predictions can be explained with few training examples, without reducing accuracy compared to the original deep neural network. Another important finding from the empirical investigation is that the choice of layer to use for the embeddings may have a large impact on the resulting accuracy.
Explaining Predictions by Characteristic Rules
May 31, 2024Characteristic rules have been advocated for their ability to improve interpretability over discriminative rules within the area of rule learning. However, the former type of rule has not yet been used by techniques for explaining predictions. A novel explanation technique, called CEGA (Characteristic Explanatory General Association rules), is proposed, which employs association rule mining to aggregate multiple explanations generated by any standard local explanation technique into a set of characteristic rules. An empirical investigation is presented, in which CEGA is compared to two state-of-the-art methods, Anchors and GLocalX, for producing local and aggregated explanations in the form of discriminative rules. The results suggest that the proposed approach provides a better trade-off between fidelity and complexity compared to the two state-of-the-art approaches; CEGA and Anchors significantly outperform GLocalX with respect to fidelity, while CEGA and GLocalX significantly outperform Anchors with respect to the number of generated rules. The effect of changing the format of the explanations of CEGA to discriminative rules and using LIME and SHAP as local explanation techniques instead of Anchors are also investigated. The results show that the characteristic explanatory rules still compete favorably with rules in the standard discriminative format. The results also indicate that using CEGA in combination with either SHAP or Anchors consistently leads to a higher fidelity compared to using LIME as the local explanation technique.
* Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2022
Bounding the Expected Robustness of Graph Neural Networks Subject to Node Feature Attacks
Apr 27, 2024



Graph Neural Networks (GNNs) have demonstrated state-of-the-art performance in various graph representation learning tasks. Recently, studies revealed their vulnerability to adversarial attacks. In this work, we theoretically define the concept of expected robustness in the context of attributed graphs and relate it to the classical definition of adversarial robustness in the graph representation learning literature. Our definition allows us to derive an upper bound of the expected robustness of Graph Convolutional Networks (GCNs) and Graph Isomorphism Networks subject to node feature attacks. Building on these findings, we connect the expected robustness of GNNs to the orthonormality of their weight matrices and consequently propose an attack-independent, more robust variant of the GCN, called the Graph Convolutional Orthonormal Robust Networks (GCORNs). We further introduce a probabilistic method to estimate the expected robustness, which allows us to evaluate the effectiveness of GCORN on several real-world datasets. Experimental experiments showed that GCORN outperforms available defense methods. Our code is publicly available at: \href{https://github.com/Sennadir/GCORN}{https://github.com/Sennadir/GCORN}.
A Simple and Yet Fairly Effective Defense for Graph Neural Networks
Feb 21, 2024



Graph Neural Networks (GNNs) have emerged as the dominant approach for machine learning on graph-structured data. However, concerns have arisen regarding the vulnerability of GNNs to small adversarial perturbations. Existing defense methods against such perturbations suffer from high time complexity and can negatively impact the model's performance on clean graphs. To address these challenges, this paper introduces NoisyGNNs, a novel defense method that incorporates noise into the underlying model's architecture. We establish a theoretical connection between noise injection and the enhancement of GNN robustness, highlighting the effectiveness of our approach. We further conduct extensive empirical evaluations on the node classification task to validate our theoretical findings, focusing on two popular GNNs: the GCN and GIN. The results demonstrate that NoisyGNN achieves superior or comparable defense performance to existing methods while minimizing added time complexity. The NoisyGNN approach is model-agnostic, allowing it to be integrated with different GNN architectures. Successful combinations of our NoisyGNN approach with existing defense techniques demonstrate even further improved adversarial defense results. Our code is publicly available at: https://github.com/Sennadir/NoisyGNN.
Example-Based Explanations of Random Forest Predictions
Nov 24, 2023



A random forest prediction can be computed by the scalar product of the labels of the training examples and a set of weights that are determined by the leafs of the forest into which the test object falls; each prediction can hence be explained exactly by the set of training examples for which the weights are non-zero. The number of examples used in such explanations is shown to vary with the dimensionality of the training set and hyperparameters of the random forest algorithm. This means that the number of examples involved in each prediction can to some extent be controlled by varying these parameters. However, for settings that lead to a required predictive performance, the number of examples involved in each prediction may be unreasonably large, preventing the user to grasp the explanations. In order to provide more useful explanations, a modified prediction procedure is proposed, which includes only the top-weighted examples. An investigation on regression and classification tasks shows that the number of examples used in each explanation can be substantially reduced while maintaining, or even improving, predictive performance compared to the standard prediction procedure.
Approximating Score-based Explanation Techniques Using Conformal Regression
Aug 23, 2023



Score-based explainable machine-learning techniques are often used to understand the logic behind black-box models. However, such explanation techniques are often computationally expensive, which limits their application in time-critical contexts. Therefore, we propose and investigate the use of computationally less costly regression models for approximating the output of score-based explanation techniques, such as SHAP. Moreover, validity guarantees for the approximated values are provided by the employed inductive conformal prediction framework. We propose several non-conformity measures designed to take the difficulty of approximating the explanations into account while keeping the computational cost low. We present results from a large-scale empirical investigation, in which the approximate explanations generated by our proposed models are evaluated with respect to efficiency (interval size). The results indicate that the proposed method can significantly improve execution time compared to the fast version of SHAP, TreeSHAP. The results also suggest that the proposed method can produce tight intervals, while providing validity guarantees. Moreover, the proposed approach allows for comparing explanations of different approximation methods and selecting a method based on how informative (tight) are the predicted intervals.
* 20 pages, 14 figures, The 12th Symposium on Conformal and Probabilistic Prediction with Applications (COPA 2023)
Interpretable Graph Neural Networks for Tabular Data
Aug 17, 2023



Data in tabular format is frequently occurring in real-world applications. Graph Neural Networks (GNNs) have recently been extended to effectively handle such data, allowing feature interactions to be captured through representation learning. However, these approaches essentially produce black-box models, in the form of deep neural networks, precluding users from following the logic behind the model predictions. We propose an approach, called IGNNet (Interpretable Graph Neural Network for tabular data), which constrains the learning algorithm to produce an interpretable model, where the model shows how the predictions are exactly computed from the original input features. A large-scale empirical investigation is presented, showing that IGNNet is performing on par with state-of-the-art machine-learning algorithms that target tabular data, including XGBoost, Random Forests, and TabNet. At the same time, the results show that the explanations obtained from IGNNet are aligned with the true Shapley values of the features without incurring any additional computational overhead.
Image Keypoint Matching using Graph Neural Networks
May 27, 2022Image matching is a key component of many tasks in computer vision and its main objective is to find correspondences between features extracted from different natural images. When images are represented as graphs, image matching boils down to the problem of graph matching which has been studied intensively in the past. In recent years, graph neural networks have shown great potential in the graph matching task, and have also been applied to image matching. In this paper, we propose a graph neural network for the problem of image matching. The proposed method first generates initial soft correspondences between keypoints using localized node embeddings and then iteratively refines the initial correspondences using a series of graph neural network layers. We evaluate our method on natural image datasets with keypoint annotations and show that, in comparison to a state-of-the-art model, our method speeds up inference times without sacrificing prediction accuracy.
Towards interpretability of Mixtures of Hidden Markov Models
Mar 23, 2021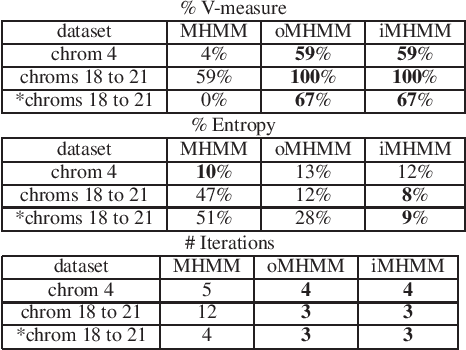
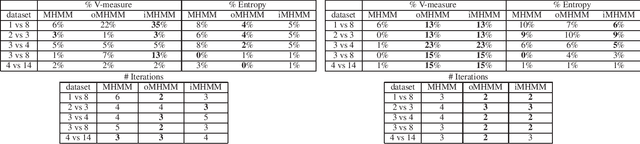
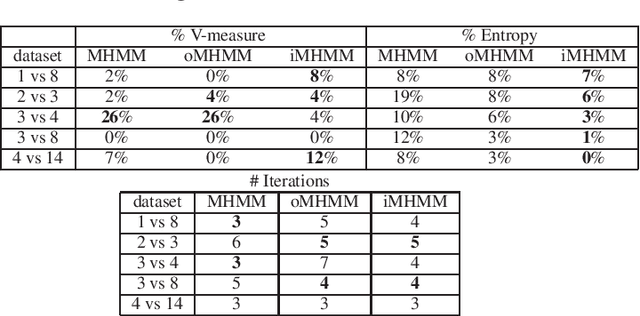
Mixtures of Hidden Markov Models (MHMMs) are frequently used for clustering of sequential data. An important aspect of MHMMs, as of any clustering approach, is that they can be interpretable, allowing for novel insights to be gained from the data. However, without a proper way of measuring interpretability, the evaluation of novel contributions is difficult and it becomes practically impossible to devise techniques that directly optimize this property. In this work, an information-theoretic measure (entropy) is proposed for interpretability of MHMMs, and based on that, a novel approach to improve model interpretability is proposed, i.e., an entropy-regularized Expectation Maximization (EM) algorithm. The new approach aims for reducing the entropy of the Markov chains (involving state transition matrices) within an MHMM, i.e., assigning higher weights to common state transitions during clustering. It is argued that this entropy reduction, in general, leads to improved interpretability since the most influential and important state transitions of the clusters can be more easily identified. An empirical investigation shows that it is possible to improve the interpretability of MHMMs, as measured by entropy, without sacrificing (but rather improving) clustering performance and computational costs, as measured by the v-measure and number of EM iterations, respectively.