 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards More Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark
Paper and Code
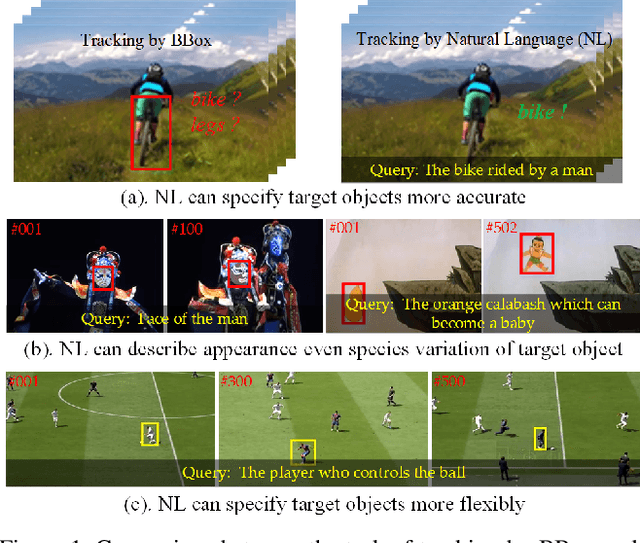
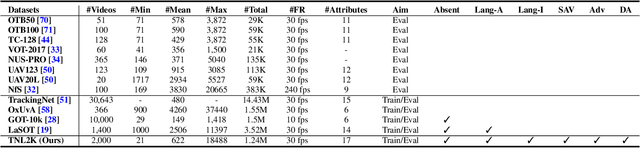

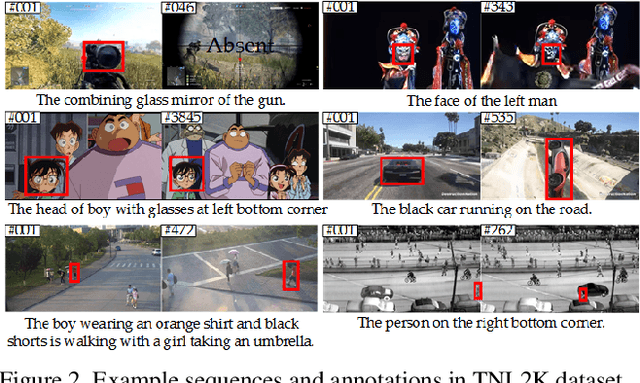
Tracking by natural language specification is a new rising research topic that aims at locating the target object in the video sequence based on its language description. Compared with traditional bounding box (BBox) based tracking, this setting guides object tracking with high-level semantic information, addresses the ambiguity of BBox, and links local and global search organically together. Those benefits may bring more flexible, robust and accurate tracking performance in practical scenarios. However, existing natural language initialized trackers are developed and compared on benchmark datasets proposed for tracking-by-BBox, which can't reflect the true power of tracking-by-language. In this work, we propose a new benchmark specifically dedicated to the tracking-by-language, including a large scale dataset, strong and diverse baseline methods. Specifically, we collect 2k video sequences (contains a total of 1,244,340 frames, 663 words) and split 1300/700 for the train/testing respectively. We densely annotate one sentence in English and corresponding bounding boxes of the target object for each video. We also introduce two new challenges into TNL2K for the object tracking task, i.e., adversarial samples and modality switch. A strong baseline method based on an adaptive local-global-search scheme is proposed for future works to compare. We believe this benchmark will greatly boost related researches on natural language guided tracking.