 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spread Mechanism and Influence Measurement of Online Rumors in China During the COVID-19 Pandemic
Jan 11, 2021
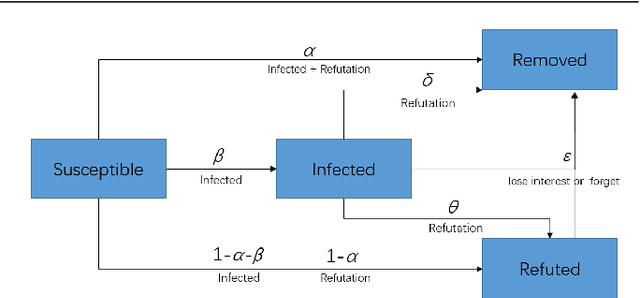

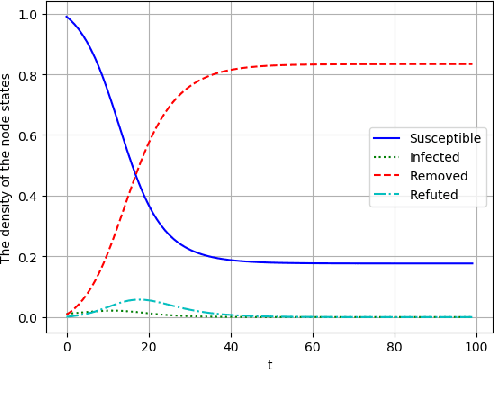
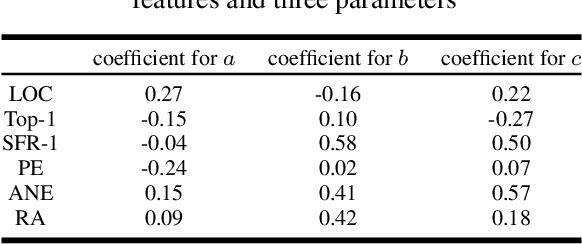
In early 2020, the Corona Virus Disease 2019 (COVID-19) pandemic swept the world.In China, COVID-19 has caused severe consequences. Moreover, online rumors during the COVID-19 pandemic increased people's panic about public health and social stability. At present, understanding and curbing the spread of online rumors is an urgent task. Therefore, we analyzed the rumor spreading mechanism and propose a method to quantify a rumors' influence by the speed of new insiders. The search frequency of the rumor is used as an observation variable of new insiders. The peak coefficient and the attenuation coefficient are calculated for the search frequency, which conforms to the exponential distribution. We designed several rumor features and used the above two coefficients as predictable labels. A 5-fold cross-validation experiment using the mean square error (MSE) as the loss function showed that the decision tree was suitable for predicting the peak coefficient, and the linear regression model was ideal for predicting the attenuation coefficient. Our feature analysis showed that precursor features were the most important for the outbreak coefficient, while location information and rumor entity information were the most important for the attenuation coefficient. Meanwhile, features that were conducive to the outbreak were usually harmful to the continued spread of rumors. At the same time, anxiety was a crucial rumor causing factor. Finally, we discuss how to use deep learning technology to reduce the forecast loss by using the Bidirectional Encoder Representations from Transformers (BERT) model.
Solid Texture Synthesis using Generative Adversarial Networks
Feb 08, 2021

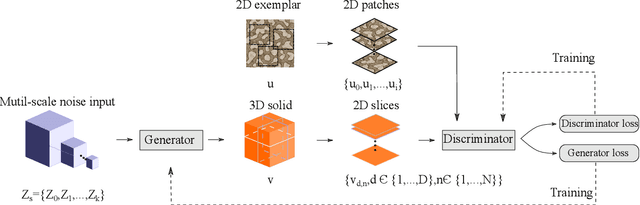
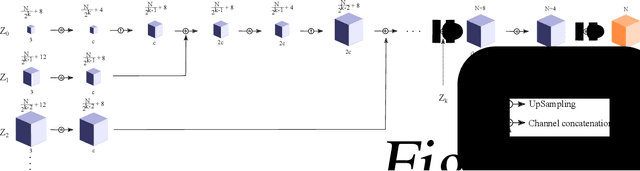
Solid texture synthesis, as an effective way to extend 2D texture to 3D solid texture, exhibits advantages in numerous application domains. However, existing methods generally suffer from synthesis distortion due to the underutilization of texture information. In this paper, we proposed a novel neural network-based approach for the solid texture synthesis based on generative adversarial networks, namely STS-GAN, in which the generator composed of multi-scale modules learns the internal distribution of 2D exemplar and further extends it to a 3D solid texture. In addition, the discriminator evaluates the similarity between 2D exemplar and slices, promoting the generator to synthesize realistic solid texture. Experiment results demonstrate that the proposed method can synthesize high-quality 3D solid texture with similar visual characteristics to the exemplar.
BERT-GT: Cross-sentence n-ary relation extraction with BERT and Graph Transformer
Jan 11, 2021
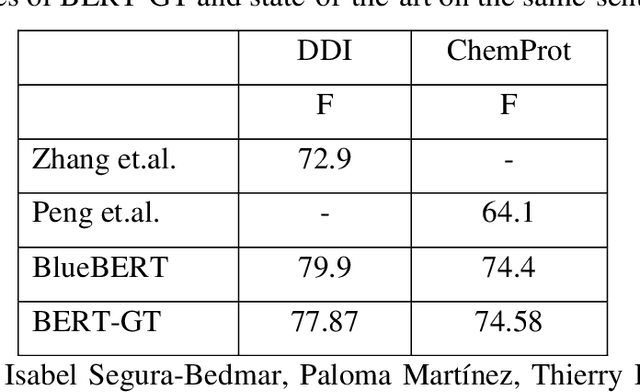
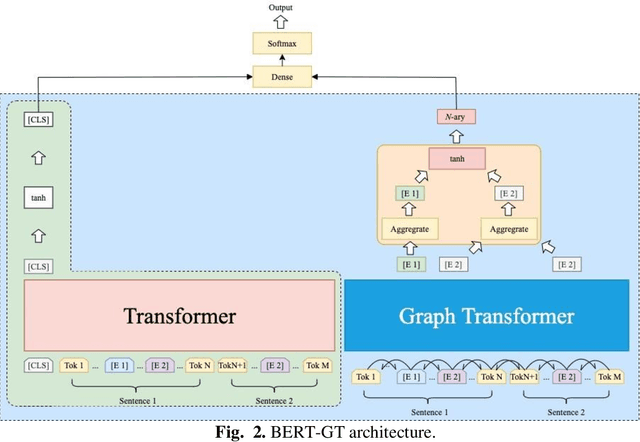
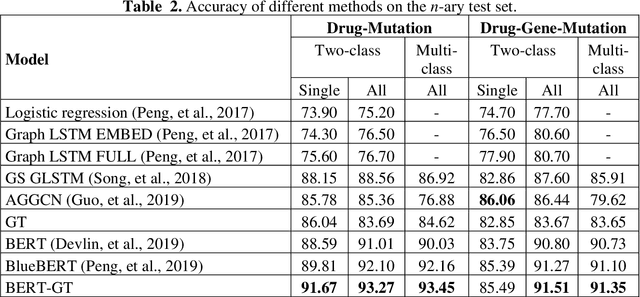
A biomedical relation statement is commonly expressed in multiple sentences and consists of many concepts, including gene, disease, chemical, and mutation. To automatically extract information from biomedical literature, existing biomedical text-mining approaches typically formulate the problem as a cross-sentence n-ary relation-extraction task that detects relations among n entities across multiple sentences, and use either a graph neural network (GNN) with long short-term memory (LSTM) or an attention mechanism. Recently, Transformer has been shown to outperform LSTM on many natural language processing (NLP) tasks. In this work, we propose a novel architecture that combines Bidirectional Encoder Representations from Transformers with Graph Transformer (BERT-GT), through integrating a neighbor-attention mechanism into the BERT architecture. Unlike the original Transformer architecture, which utilizes the whole sentence(s) to calculate the attention of the current token, the neighbor-attention mechanism in our method calculates its attention utilizing only its neighbor tokens. Thus, each token can pay attention to its neighbor information with little noise. We show that this is critically important when the text is very long, as in cross-sentence or abstract-level relation-extraction tasks. Our benchmarking results show improvements of 5.44% and 3.89% in accuracy and F1-measure over the state-of-the-art on n-ary and chemical-protein relation datasets, suggesting BERT-GT is a robust approach that is applicable to other biomedical relation extraction tasks or datasets.
Learning Effective Representations from Global and Local Features for Cross-View Gait Recognition
Nov 03, 2020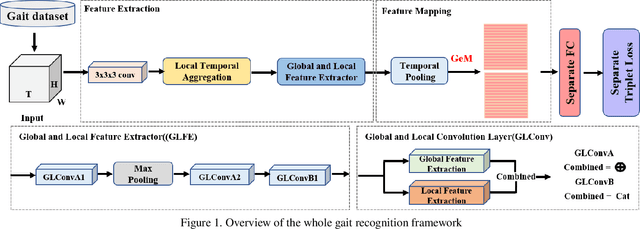
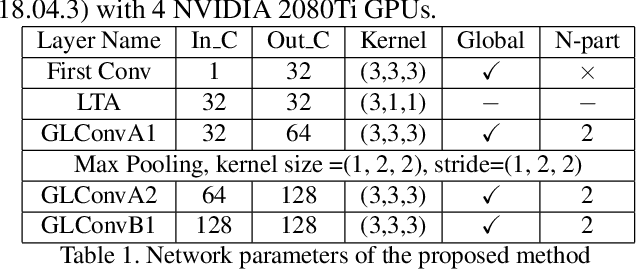
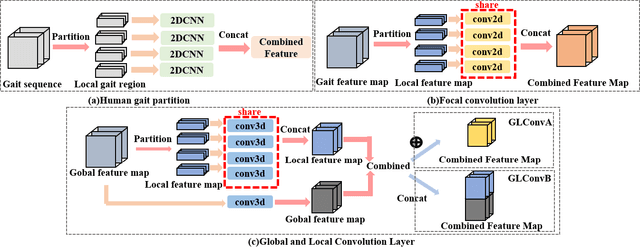
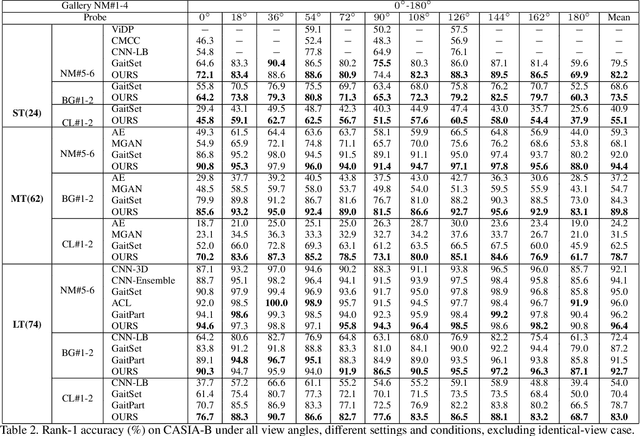
Gait recognition is one of the most important biometric technologies and has been applied in many fields. Recent gait recognition frameworks represent each human gait frame by descriptors extracted from either global appearances or local regions of humans. However, the representations based on global information often neglect the details of the gait frame, while local region based descriptors cannot capture the relations among neighboring regions, thus reducing their discriminativeness. In this paper, we propose a novel feature extraction and fusion framework to achieve discriminative feature representations for gait recognition. Towards this goal, we take advantage of both global visual information and local region details and develop a Global and Local Feature Extractor (GLFE). Specifically, our GLFE module is composed of our newly designed multiple global and local convolutional layers (GLConv) to ensemble global and local features in a principle manner. Furthermore, we present a novel operation, namely Local Temporal Aggregation (LTA), to further preserve the spatial information by reducing the temporal resolution to obtain higher spatial resolution. With the help of our GLFE and LTA, our method significantly improves the discriminativeness of our visual features, thus improving the gait recognition performance. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art gait recognition methods on popular widely-used CASIA-B and OUMVLP datasets.
Listening to the city, attentively: A Spatio-Temporal Attention Boosted Autoencoder for the Short-Term Flow Prediction Problem
Mar 01, 2021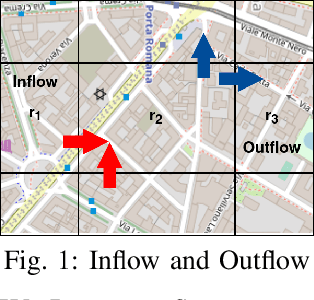
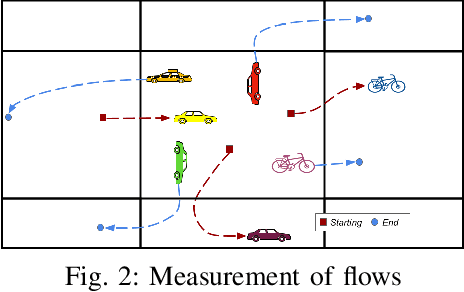
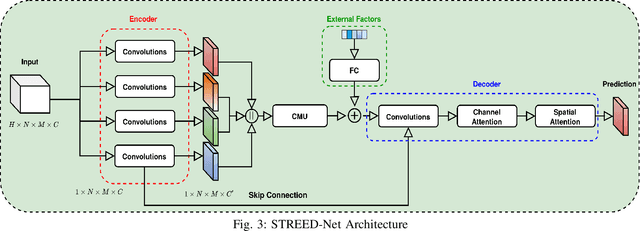
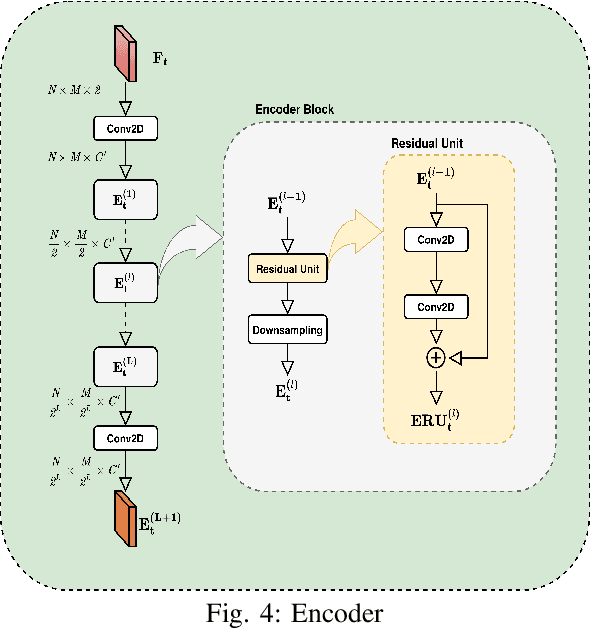
In recent years, the importance of studying traffic flows and making predictions on alternative mobility (sharing services) has become increasingly important, as accurate and timely information on the travel flow is important for the successful implementation of systems that increase the quality of sharing services. This need has been accentuated by the current health crisis that requires alternative transport mobility such as electric bike and electric scooter sharing. Considering the new approaches in the world of deep learning and the difficulty due to the strong spatial and temporal dependence of this problem, we propose a framework, called STREED-Net, with multi-attention (Spatial and Temporal) able to better mining the high-level spatial and temporal features. We conduct experiments on three real datasets to predict the Inflow and Outflow of the different regions into which the city has been divided. The results indicate that the proposed STREED-Net model improves the state-of-the-art for this problem.
Hyperspectral Image Semantic Segmentation in Cityscapes
Dec 18, 2020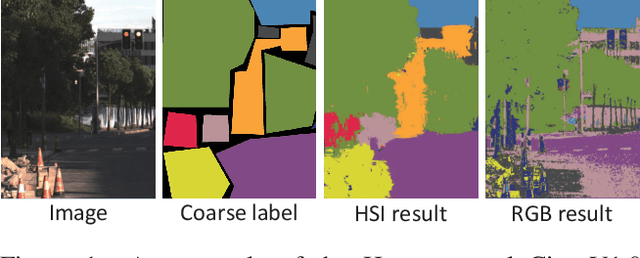



High-resolution hyperspectral images (HSIs) contain the response of each pixel in different spectral bands, which can be used to effectively distinguish various objects in complex scenes. While HSI cameras have become low cost, algorithms based on it has not been well exploited. In this paper, we focus on a novel topic, semi-supervised semantic segmentation in cityscapes using HSIs.It is based on the idea that high-resolution HSIs in city scenes contain rich spectral information, which can be easily associated to semantics without manual labeling. Therefore, it enables low cost, highly reliable semantic segmentation in complex scenes.Specifically, in this paper, we introduce a semi-supervised HSI semantic segmentation network, which utilizes spectral information to improve the coarse labels to a finer degree.The experimental results show that our method can obtain highly competitive labels and even have higher edge fineness than artificial fine labels in some classes. At the same time, the results also show that the optimized labels can effectively improve the effect of semantic segmentation. The combination of HSIs and semantic segmentation proves that HSIs have great potential in high-level visual tasks.
VIO-Aided Structure from Motion Under Challenging Environments
Jan 26, 2021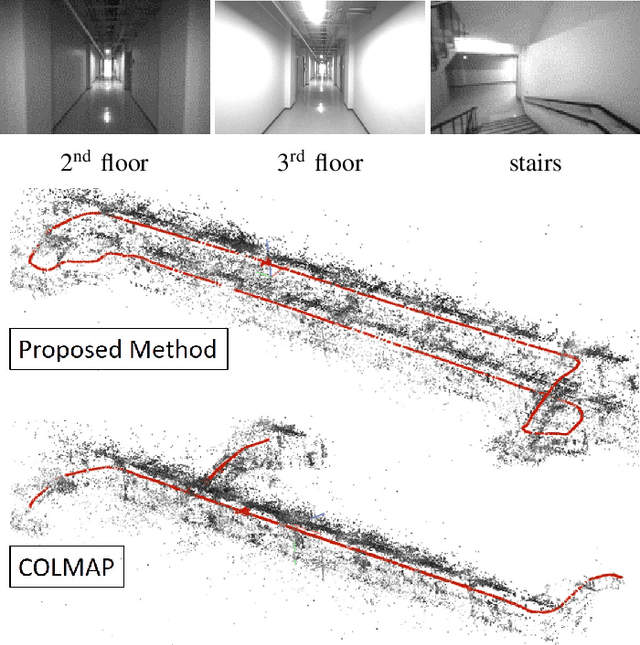
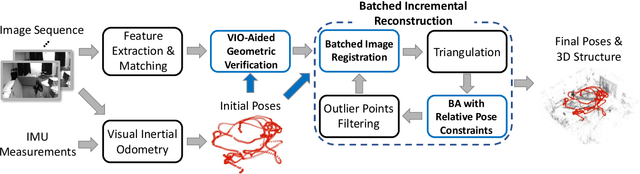
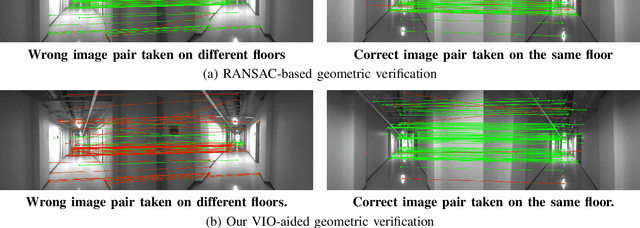

In this paper, we present a robust and efficient Structure from Motion pipeline for accurate 3D reconstruction under challenging environments by leveraging the camera pose information from a visual-inertial odometry. Specifically, we propose a geometric verification method to filter out mismatches by considering the prior geometric configuration of candidate image pairs. Furthermore, we introduce an efficient and scalable reconstruction approach that relies on batched image registration and robust bundle adjustment, both leveraging the reliable local odometry estimation. Extensive experimental results show that our pipeline performs better than the state-of-the-art SfM approaches in terms of reconstruction accuracy and robustness for challenging sequential image collections.
Hyperspectral Image Super-Resolution in Arbitrary Input-Output Band Settings
Mar 19, 2021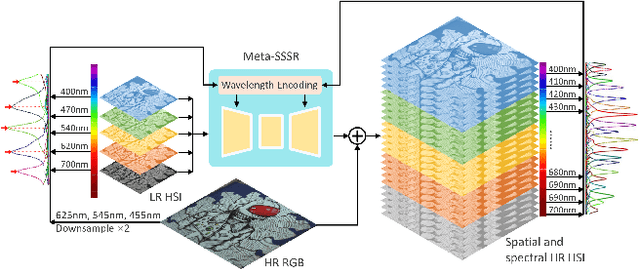
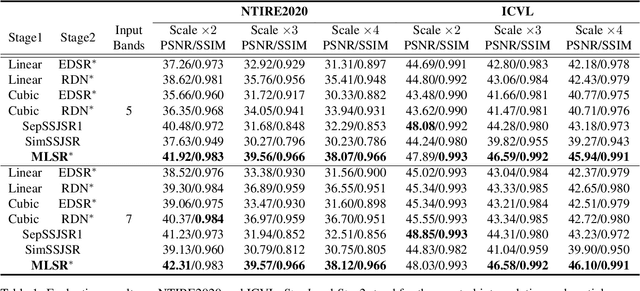
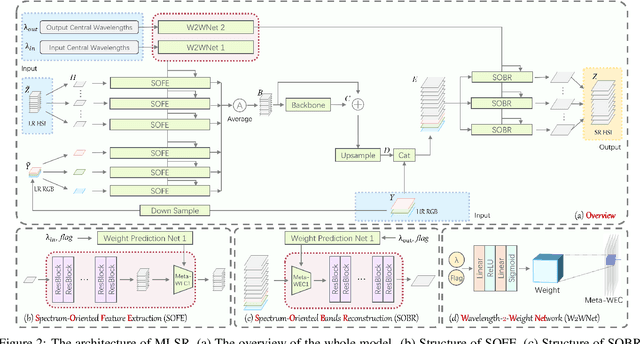

Hyperspectral images (HSIs) with narrow spectral bands can capture rich spectral information, making them suitable for many computer vision tasks. One of the fundamental limitations of HSI is its low spatial resolution, and several recent works on super-resolution(SR) have been proposed to tackle this challenge. However, due to HSI cameras' diversity, different cameras capture images with different spectral response functions and the number of total channels. The existing HSI datasets are usually small and consequently insufficient for modeling. We propose a Meta-Learning-Based Super-Resolution(MLSR) model, which can take in HSI images at an arbitrary number of input bands' peak wavelengths and generate super-resolved HSIs with an arbitrary number of output bands' peak wavelengths. We artificially create sub-datasets by sampling the bands from NTIRE2020 and ICVL datasets to simulate the cross-dataset settings and perform HSI SR with spectral interpolation and extrapolation on them. We train a single MLSR model for all sub-datasets and train dedicated baseline models for each sub-dataset. The results show the proposed model has the same level or better performance compared to the-state-of-the-art HSI SR methods.
Spatial-Temporal Tensor Graph Convolutional Network for Traffic Prediction
Mar 10, 2021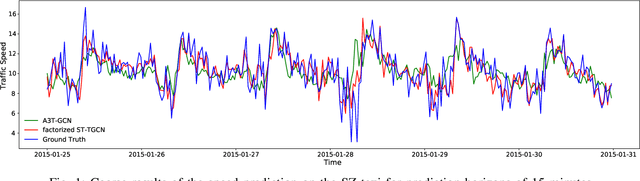
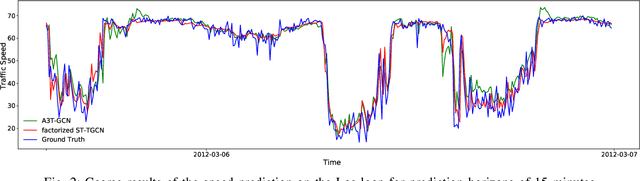
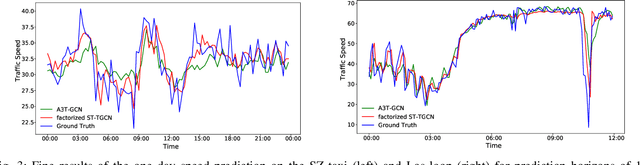
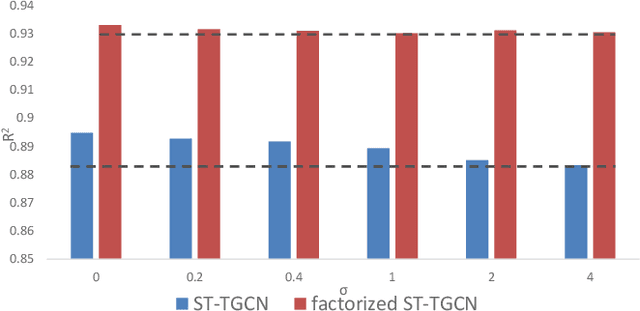
Accurate traffic prediction is crucial to the guidance and management of urban traffics. However, most of the existing traffic prediction models do not consider the computational burden and memory space when they capture spatial-temporal dependence among traffic data. In this work, we propose a factorized Spatial-Temporal Tensor Graph Convolutional Network to deal with traffic speed prediction. Traffic networks are modeled and unified into a graph that integrates spatial and temporal information simultaneously. We further extend graph convolution into tensor space and propose a tensor graph convolution network to extract more discriminating features from spatial-temporal graph data. To reduce the computational burden, we take Tucker tensor decomposition and derive factorized a tensor convolution, which performs separate filtering in small-scale space, time, and feature modes. Besides, we can benefit from noise suppression of traffic data when discarding those trivial components in the process of tensor decomposition. Extensive experiments on two real-world traffic speed datasets demonstrate our method is more effective than those traditional traffic prediction methods, and meantime achieves state-of-the-art performance.
Synergy Between Semantic Segmentation and Image Denoising via Alternate Boosting
Feb 24, 2021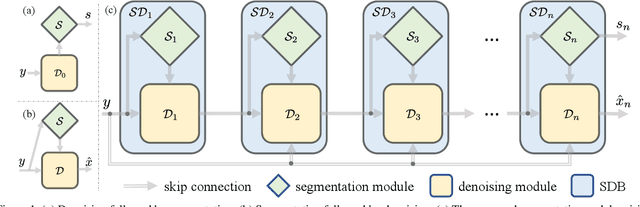
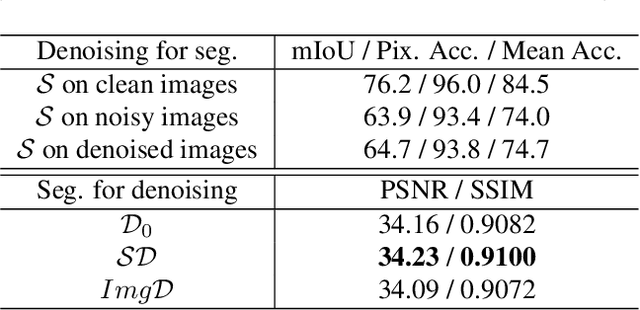
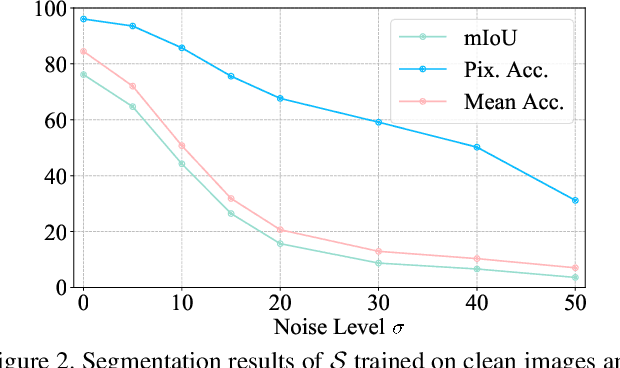
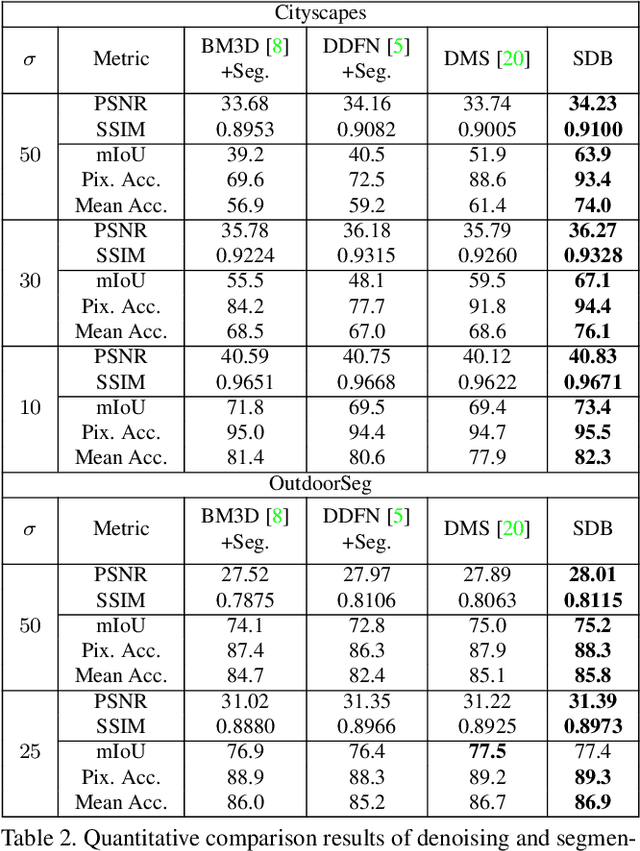
The capability of image semantic segmentation may be deteriorated due to noisy input image, where image denoising prior to segmentation helps. Both image denoising and semantic segmentation have been developed significantly with the advance of deep learning. Thus, we are interested in the synergy between them by using a holistic deep model. We observe that not only denoising helps combat the drop of segmentation accuracy due to noise, but also pixel-wise semantic information boosts the capability of denoising. We then propose a boosting network to perform denoising and segmentation alternately. The proposed network is composed of multiple segmentation and denoising blocks (SDBs), each of which estimates semantic map then uses the map to regularize denoising. Experimental results show that the denoised image quality is improved substantially and the segmentation accuracy is improved to close to that of clean images. Our code and models will be made publicly available.