 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Sensitivity of Classification Models with the Error Sensitivity Profile
Apr 28, 2026The quality of training data is critical to the performance of machine learning models. In this paper, the Error Sensitivity Profile (ESP) is proposed. It quantifies the sensitivity of model performance to errors in a single feature or in multiple features. By leveraging ESP, data-cleaning efforts can be prioritized based on error types and features most likely to affect model performance. To support the computation of this metric, an integrated suite of tools, called \dirty, is created. We conduct an extensive experimental study on two widely used datasets using 14 classification models, revealing that performance degradation is not always predictable from simple correlations with the target variable.
How Data Quality Affects Machine Learning Models for Credit Risk Assessment
Nov 14, 2025Machine Learning (ML) models are being increasingly employed for credit risk evaluation, with their effectiveness largely hinging on the quality of the input data. In this paper we investigate the impact of several data quality issues, including missing values, noisy attributes, outliers, and label errors, on the predictive accuracy of the machine learning model used in credit risk assessment. Utilizing an open-source dataset, we introduce controlled data corruption using the Pucktrick library to assess the robustness of 10 frequently used models like Random Forest, SVM, and Logistic Regression and so on. Our experiments show significant differences in model robustness based on the nature and severity of the data degradation. Moreover, the proposed methodology and accompanying tools offer practical support for practitioners seeking to enhance data pipeline robustness, and provide researchers with a flexible framework for further experimentation in data-centric AI contexts.
Optimizing Large Language Models for ESG Activity Detection in Financial Texts
Feb 28, 2025The integration of Environmental, Social, and Governance (ESG) factors into corporate decision-making is a fundamental aspect of sustainable finance. However, ensuring that business practices align with evolving regulatory frameworks remains a persistent challenge. AI-driven solutions for automatically assessing the alignment of sustainability reports and non-financial disclosures with specific ESG activities could greatly support this process. Yet, this task remains complex due to the limitations of general-purpose Large Language Models (LLMs) in domain-specific contexts and the scarcity of structured, high-quality datasets. In this paper, we investigate the ability of current-generation LLMs to identify text related to environmental activities. Furthermore, we demonstrate that their performance can be significantly enhanced through fine-tuning on a combination of original and synthetically generated data. To this end, we introduce ESG-Activities, a benchmark dataset containing 1,325 labelled text segments classified according to the EU ESG taxonomy. Our experimental results show that fine-tuning on ESG-Activities significantly enhances classification accuracy, with open models such as Llama 7B and Gemma 7B outperforming large proprietary solutions in specific configurations. These findings have important implications for financial analysts, policymakers, and AI researchers seeking to enhance ESG transparency and compliance through advanced natural language processing techniques.
Listening to the city, attentively: A Spatio-Temporal Attention Boosted Autoencoder for the Short-Term Flow Prediction Problem
Mar 01, 2021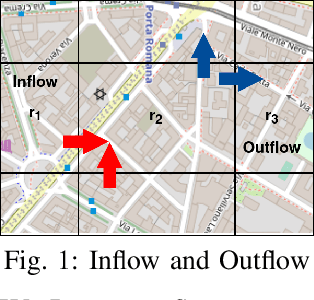
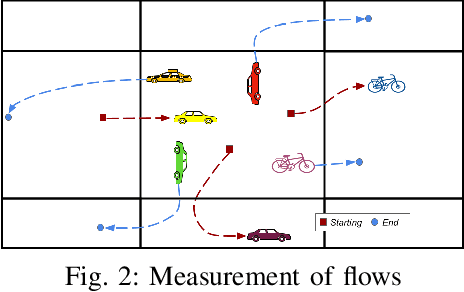
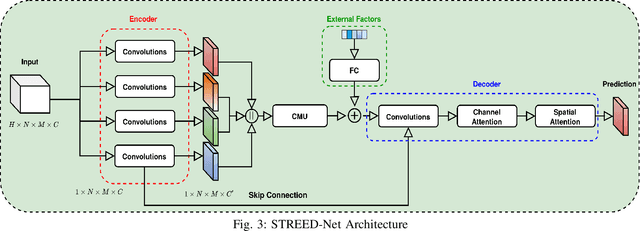
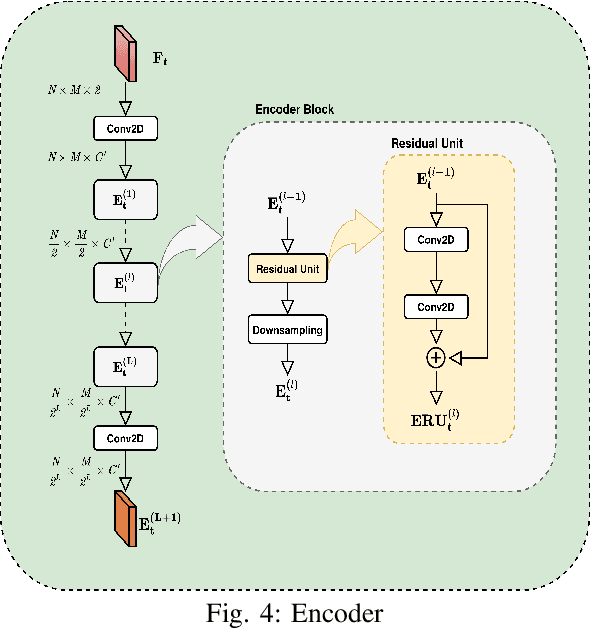
In recent years, the importance of studying traffic flows and making predictions on alternative mobility (sharing services) has become increasingly important, as accurate and timely information on the travel flow is important for the successful implementation of systems that increase the quality of sharing services. This need has been accentuated by the current health crisis that requires alternative transport mobility such as electric bike and electric scooter sharing. Considering the new approaches in the world of deep learning and the difficulty due to the strong spatial and temporal dependence of this problem, we propose a framework, called STREED-Net, with multi-attention (Spatial and Temporal) able to better mining the high-level spatial and temporal features. We conduct experiments on three real datasets to predict the Inflow and Outflow of the different regions into which the city has been divided. The results indicate that the proposed STREED-Net model improves the state-of-the-art for this problem.