 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding Creativity: A Human-Aligned Generative Reward Model for Reinforcement Learning in Storytelling
Jan 12, 2026While Large Language Models (LLMs) can generate fluent text, producing high-quality creative stories remains challenging. Reinforcement Learning (RL) offers a promising solution but faces two critical obstacles: designing reliable reward signals for subjective storytelling quality and mitigating training instability. This paper introduces the Reinforcement Learning for Creative Storytelling (RLCS) framework to systematically address both challenges. First, we develop a Generative Reward Model (GenRM) that provides multi-dimensional analysis and explicit reasoning about story preferences, trained through supervised fine-tuning on demonstrations with reasoning chains distilled from strong teacher models, followed by GRPO-based refinement on expanded preference data. Second, we introduce an entropy-based reward shaping strategy that dynamically prioritizes learning on confident errors and uncertain correct predictions, preventing overfitting on already-mastered patterns. Experiments demonstrate that GenRM achieves 68\% alignment with human creativity judgments, and RLCS significantly outperforms strong baselines including Gemini-2.5-Pro in overall story quality. This work provides a practical pipeline for applying RL to creative domains, effectively navigating the dual challenges of reward modeling and training stability.
Spread Mechanism and Influence Measurement of Online Rumors in China During the COVID-19 Pandemic
Jan 11, 2021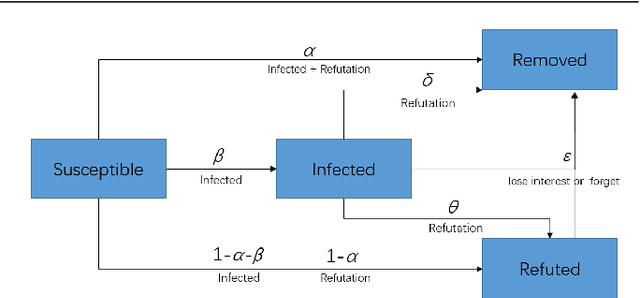

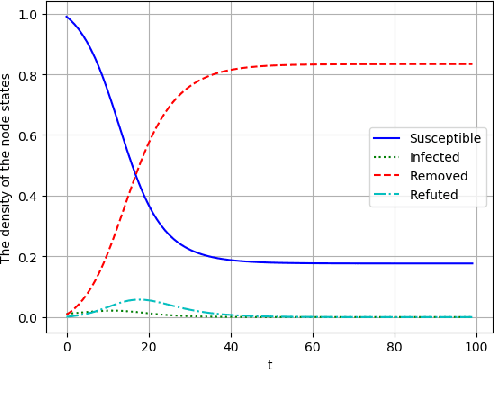
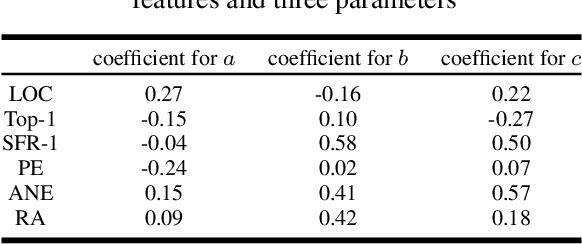
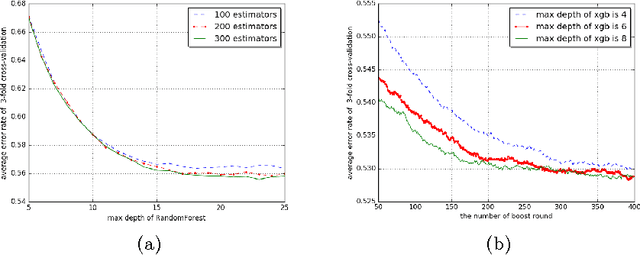
In early 2020, the Corona Virus Disease 2019 (COVID-19) pandemic swept the world.In China, COVID-19 has caused severe consequences. Moreover, online rumors during the COVID-19 pandemic increased people's panic about public health and social stability. At present, understanding and curbing the spread of online rumors is an urgent task. Therefore, we analyzed the rumor spreading mechanism and propose a method to quantify a rumors' influence by the speed of new insiders. The search frequency of the rumor is used as an observation variable of new insiders. The peak coefficient and the attenuation coefficient are calculated for the search frequency, which conforms to the exponential distribution. We designed several rumor features and used the above two coefficients as predictable labels. A 5-fold cross-validation experiment using the mean square error (MSE) as the loss function showed that the decision tree was suitable for predicting the peak coefficient, and the linear regression model was ideal for predicting the attenuation coefficient. Our feature analysis showed that precursor features were the most important for the outbreak coefficient, while location information and rumor entity information were the most important for the attenuation coefficient. Meanwhile, features that were conducive to the outbreak were usually harmful to the continued spread of rumors. At the same time, anxiety was a crucial rumor causing factor. Finally, we discuss how to use deep learning technology to reduce the forecast loss by using the Bidirectional Encoder Representations from Transformers (BERT) model.
Machine Learned Resume-Job Matching Solution
Jul 26, 2016


Job search through online matching engines nowadays are very prominent and beneficial to both job seekers and employers. But the solutions of traditional engines without understanding the semantic meanings of different resumes have not kept pace with the incredible changes in machine learning techniques and computing capability. These solutions are usually driven by manual rules and predefined weights of keywords which lead to an inefficient and frustrating search experience. To this end, we present a machine learned solution with rich features and deep learning methods. Our solution includes three configurable modules that can be plugged with little restrictions. Namely, unsupervised feature extraction, base classifiers training and ensemble method learning. In our solution, rather than using manual rules, machine learned methods to automatically detect the semantic similarity of positions are proposed. Then four competitive "shallow" estimators and "deep" estimators are selected. Finally, ensemble methods to bag these estimators and aggregate their individual predictions to form a final prediction are verified. Experimental results of over 47 thousand resumes show that our solution can significantly improve the predication precision current position, salary, educational background and company scale.
An Empirical Study on Sentiment Classification of Chinese Review using Word Embedding
Nov 05, 2015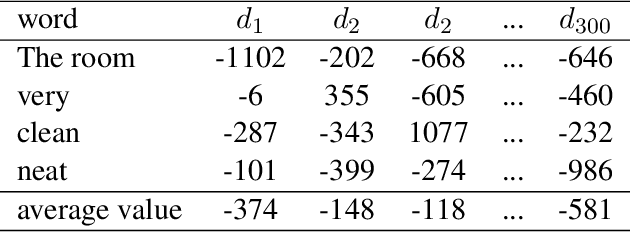
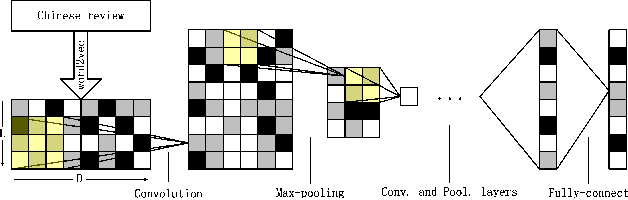
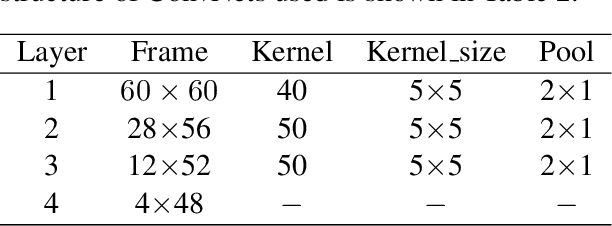
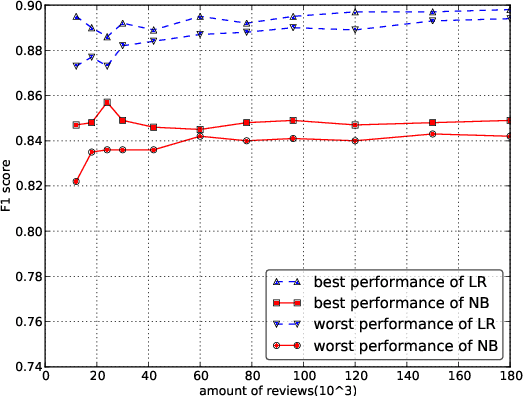
In this article, how word embeddings can be used as features in Chinese sentiment classification is presented. Firstly, a Chinese opinion corpus is built with a million comments from hotel review websites. Then the word embeddings which represent each comment are used as input in different machine learning methods for sentiment classification, including SVM, Logistic Regression, Convolutional Neural Network (CNN) and ensemble methods. These methods get better performance compared with N-gram models using Naive Bayes (NB) and Maximum Entropy (ME). Finally, a combination of machine learning methods is proposed which presents an outstanding performance in precision, recall and F1 score. After selecting the most useful methods to construct the combinational model and testing over the corpus, the final F1 score is 0.920.