 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Back-tracing Representative Points for Voting-based 3D Object Detection in Point Clouds
Apr 13, 2021
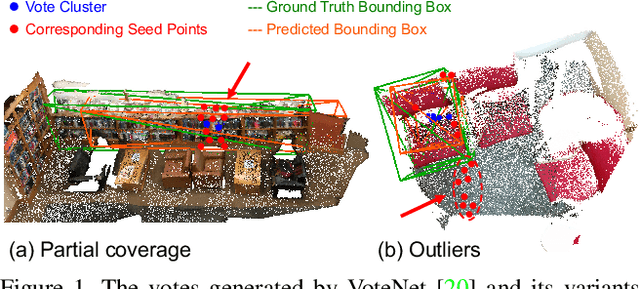
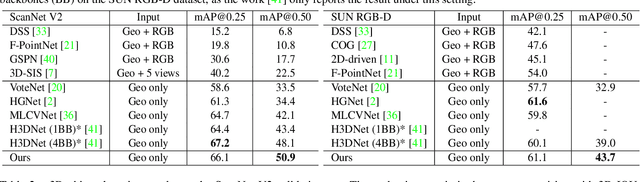
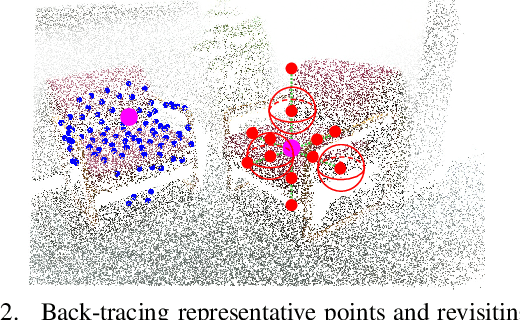

3D object detection in point clouds is a challenging vision task that benefits various applications for understanding the 3D visual world. Lots of recent research focuses on how to exploit end-to-end trainable Hough voting for generating object proposals. However, the current voting strategy can only receive partial votes from the surfaces of potential objects together with severe outlier votes from the cluttered backgrounds, which hampers full utilization of the information from the input point clouds. Inspired by the back-tracing strategy in the conventional Hough voting methods, in this work, we introduce a new 3D object detection method, named as Back-tracing Representative Points Network (BRNet), which generatively back-traces the representative points from the vote centers and also revisits complementary seed points around these generated points, so as to better capture the fine local structural features surrounding the potential objects from the raw point clouds. Therefore, this bottom-up and then top-down strategy in our BRNet enforces mutual consistency between the predicted vote centers and the raw surface points and thus achieves more reliable and flexible object localization and class prediction results. Our BRNet is simple but effective, which significantly outperforms the state-of-the-art methods on two large-scale point cloud datasets, ScanNet V2 (+7.5% in terms of mAP@0.50) and SUN RGB-D (+4.7% in terms of mAP@0.50), while it is still lightweight and efficient. Code will be available at \href{https://github.com/cheng052/BRNet}{this https URL}.
Transfer Learning with Ensembles of Deep Neural Networks for Skin Cancer Classification in Imbalanced Data Sets
Mar 30, 2021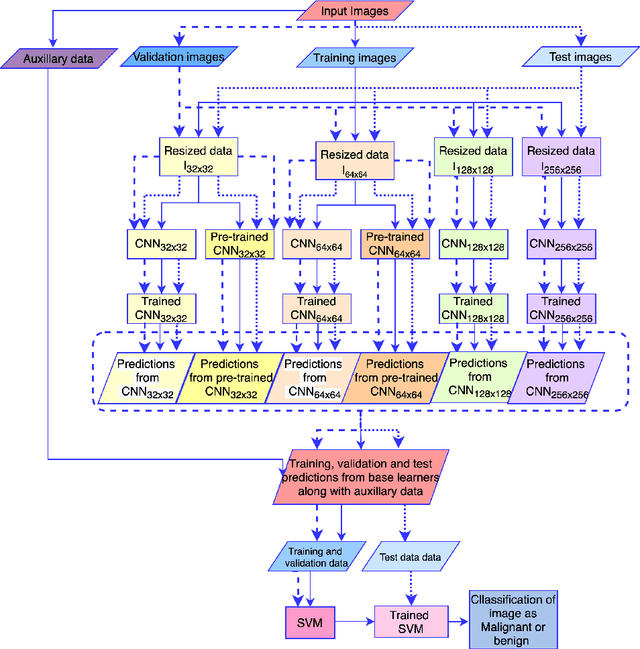
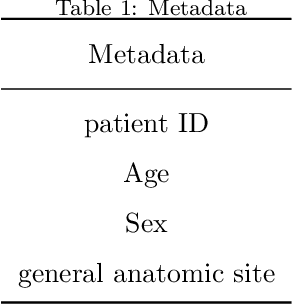
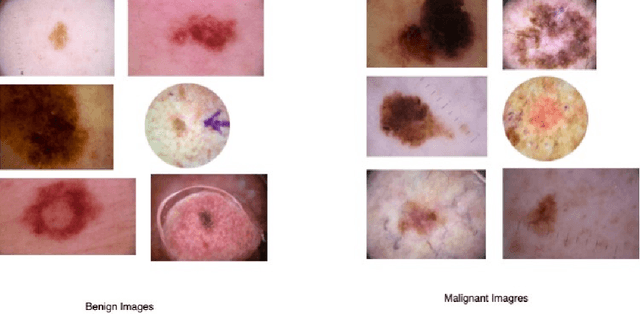
Early diagnosis plays a key role in prevention and treatment of skin cancer.Several machine learning techniques for accurate classification of skin cancer from medical images have been reported. Many of these techniques are based on pre-trained convolutional neural networks (CNNs), which enable training the models based on limited amounts of training data. However, the classification accuracy of these models still tends to be severely limited by the scarcity of representative images from malignant tumours. We propose a novel ensemble-based CNN architecture where multiple CNN models, some of which are pre-trained and some are trained only on the data at hand, along with patient information (meta-data) are combined using a meta-learner. The proposed approach improves the model's ability to handle scarce, imbalanced data. We demonstrate the benefits of the proposed technique using a dataset with 33126 dermoscopic images from 2000 patients.We evaluate the performance of the proposed technique in terms of the F1-measure, area under the ROC curve (AUC-ROC), and area under the PR curve (AUC-PR), and compare it with that of seven different benchmark methods, including two recent CNN-based techniques. The proposed technique achieves superior performance in terms of all the evaluation metrics (F1-measure $0.53$, AUC-PR $0.58$, AUC-ROC $0.97$).
Which Hyperparameters to Optimise? An Investigation of Evoluationary Hyperaprameter Optimisation in Graph Neural Network For Molecular Property Prediction
Apr 13, 2021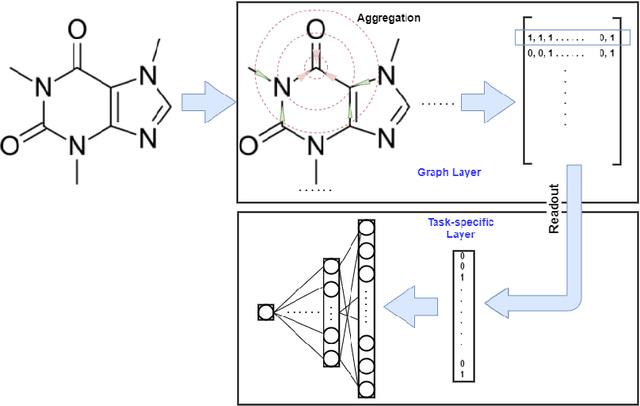

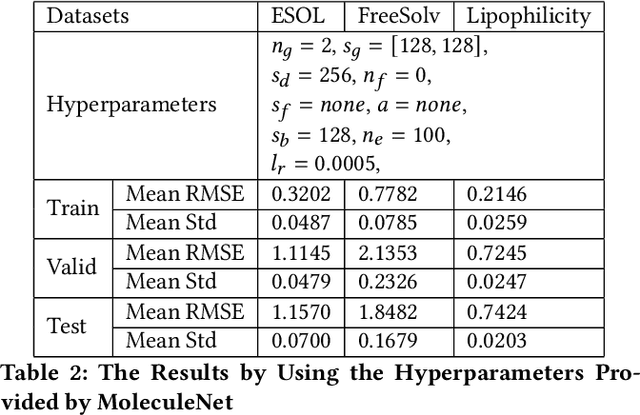
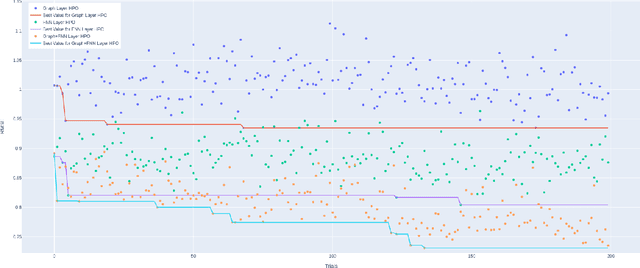
Recently, the study of graph neural network (GNN) has attracted much attention and achieved promising performance in molecular property prediction. Most GNNs for molecular property prediction are proposed based on the idea of learning the representations for the nodes by aggregating the information of their neighbor nodes (e.g. atoms). Then, the representations can be passed to subsequent layers to deal with individual downstream tasks. Therefore, the architectures of GNNs can be considered as being composed of two core parts: graph-related layers and task-specific layers. Facing real-world molecular problems, the hyperparameter optimization for those layers are vital. Hyperparameter optimization (HPO) becomes expensive in this situation because evaluating candidate solutions requires massive computational resources to train and validate models. Furthermore, a larger search space often makes the HPO problems more challenging. In this research, we focus on the impact of selecting two types of GNN hyperparameters, those belonging to graph-related layers and those of task-specific layers, on the performance of GNN for molecular property prediction. In our experiments. we employed a state-of-the-art evolutionary algorithm (i.e., CMA-ES) for HPO. The results reveal that optimizing the two types of hyperparameters separately can gain the improvements on GNNs' performance, but optimising both types of hyperparameters simultaneously will lead to predominant improvements. Meanwhile, our study also further confirms the importance of HPO for GNNs in molecular property prediction problems.
Causal Hidden Markov Model for Time Series Disease Forecasting
Mar 30, 2021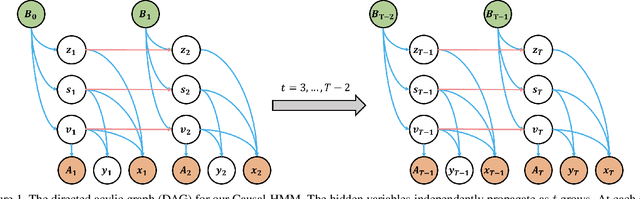
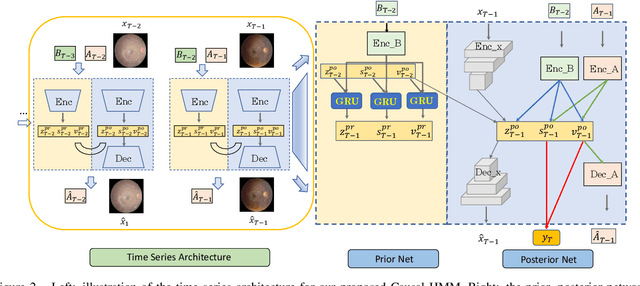
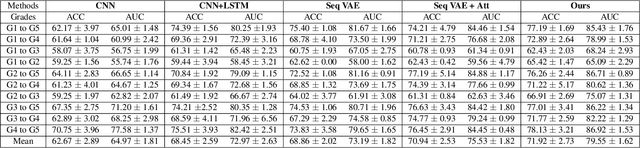
We propose a causal hidden Markov model to achieve robust prediction of irreversible disease at an early stage, which is safety-critical and vital for medical treatment in early stages. Specifically, we introduce the hidden variables which propagate to generate medical data at each time step. To avoid learning spurious correlation (e.g., confounding bias), we explicitly separate these hidden variables into three parts: a) the disease (clinical)-related part; b) the disease (non-clinical)-related part; c) others, with only a),b) causally related to the disease however c) may contain spurious correlations (with the disease) inherited from the data provided. With personal attributes and the disease label respectively provided as side information and supervision, we prove that these disease-related hidden variables can be disentangled from others, implying the avoidance of spurious correlation for generalization to medical data from other (out-of-) distributions. Guaranteed by this result, we propose a sequential variational auto-encoder with a reformulated objective function. We apply our model to the early prediction of peripapillary atrophy and achieve promising results on out-of-distribution test data. Further, the ablation study empirically shows the effectiveness of each component in our method. And the visualization shows the accurate identification of lesion regions from others.
A Dynamic Battery State-of-Health Forecasting Model for Electric Trucks: Li-Ion Batteries Case-Study
Mar 30, 2021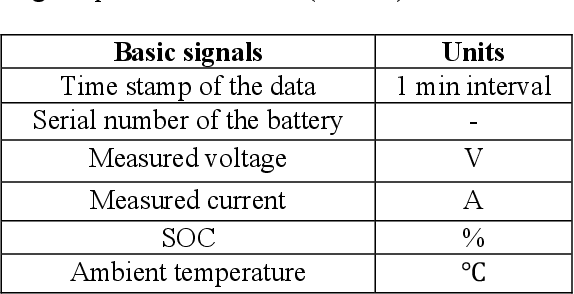
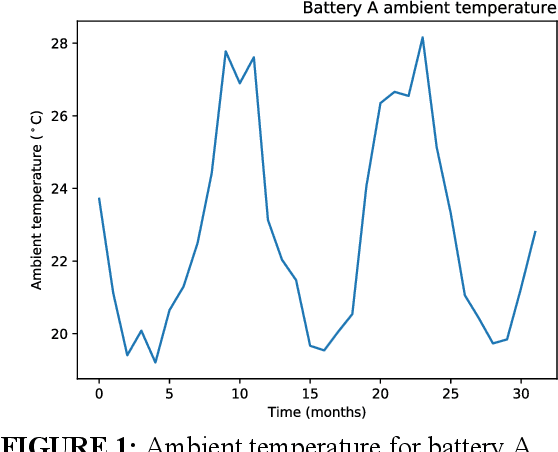
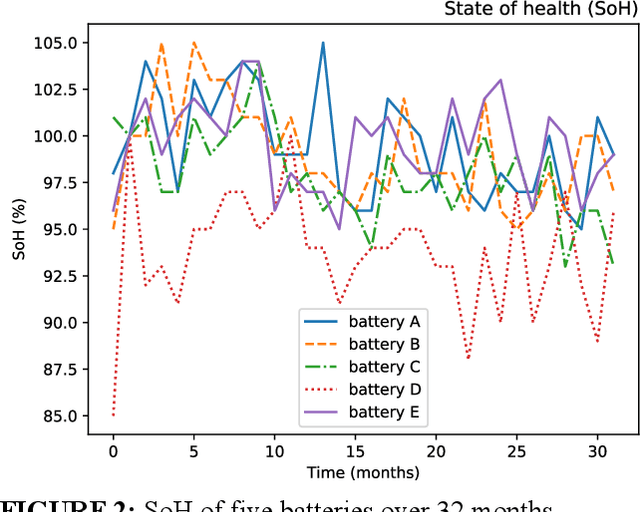
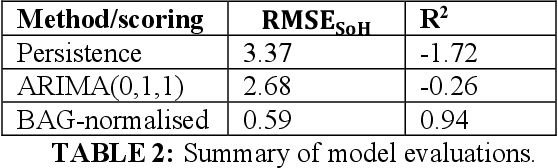
It is of extreme importance to monitor and manage the battery health to enhance the performance and decrease the maintenance cost of operating electric vehicles. This paper concerns the machine-learning-enabled state-of-health (SoH) prognosis for Li-ion batteries in electric trucks, where they are used as energy sources. The paper proposes methods to calculate SoH and cycle life for the battery packs. We propose autoregressive integrated modeling average (ARIMA) and supervised learning (bagging with decision tree as the base estimator; BAG) for forecasting the battery SoH in order to maximize the battery availability for forklift operations. As the use of data-driven methods for battery prognostics is increasing, we demonstrate the capabilities of ARIMA and under circumstances when there is little prior information available about the batteries. For this work, we had a unique data set of 31 lithium-ion battery packs from forklifts in commercial operations. On the one hand, results indicate that the developed ARIMA model provided relevant tools to analyze the data from several batteries. On the other hand, BAG model results suggest that the developed supervised learning model using decision trees as base estimator yields better forecast accuracy in the presence of large variation in data for one battery.
* This paper has first been published at the Proceedings of the ASME 2020 International Mechanical Engineering Congress and Exposition IMECE2020 held on November 16-19, 2020, Portland, OR, USA
Digital rock reconstruction with user-defined properties using conditional generative adversarial networks
Nov 29, 2020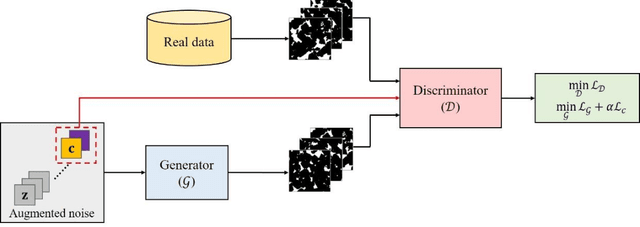
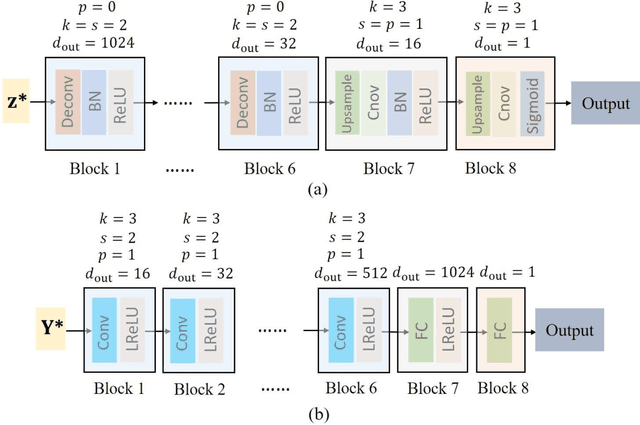

Uncertainty is ubiquitous with flow in subsurface rocks because of their inherent heterogeneity and lack of in-situ measurements. To complete uncertainty analysis in a multi-scale manner, it is a prerequisite to provide sufficient rock samples. Even though the advent of digital rock technology offers opportunities to reproduce rocks, it still cannot be utilized to provide massive samples due to its high cost, thus leading to the development of diversified mathematical methods. Among them, two-point statistics (TPS) and multi-point statistics (MPS) are commonly utilized, which feature incorporating low-order and high-order statistical information, respectively. Recently, generative adversarial networks (GANs) are becoming increasingly popular since they can reproduce training images with excellent visual and consequent geologic realism. However, standard GANs can only incorporate information from data, while leaving no interface for user-defined properties, and thus may limit the diversity of reconstructed samples. In this study, we propose conditional GANs for digital rock reconstruction, aiming to reproduce samples not only similar to the real training data, but also satisfying user-specified properties. In fact, the proposed framework can realize the targets of MPS and TPS simultaneously by incorporating high-order information directly from rock images with the GANs scheme, while preserving low-order counterparts through conditioning. We conduct three reconstruction experiments, and the results demonstrate that rock type, rock porosity, and correlation length can be successfully conditioned to affect the reconstructed rock images. Furthermore, in contrast to existing GANs, the proposed conditioning enables learning of multiple rock types simultaneously, and thus invisibly saves the computational cost.
Sub-GMN: The Subgraph Matching Network Model
Apr 30, 2021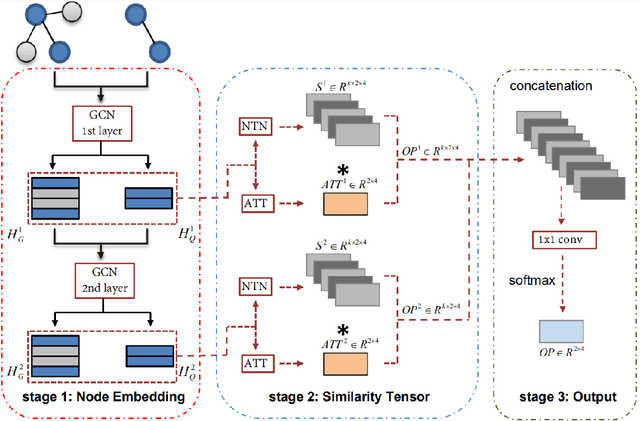


As one of the most fundamental tasks in graph theory, subgraph matching is a crucial task in many fields, ranging from information retrieval, computer vision, biology, chemistry and natural language processing. Yet subgraph matching problem remains to be an NP-complete problem. This study proposes an end-to-end learning-based approximate method for subgraph matching task, called subgraph matching network (Sub-GMN). The proposed Sub-GMN firstly uses graph representation learning to map nodes to node-level embedding. It then combines metric learning and attention mechanisms to model the relationship between matched nodes in the data graph and query graph. To test the performance of the proposed method, we applied our method on two databases. We used two existing methods, GNN and FGNN as baseline for comparison. Our experiment shows that, on dataset 1, on average the accuracy of Sub-GMN are 12.21\% and 3.2\% higher than that of GNN and FGNN respectively. On average running time Sub-GMN runs 20-40 times faster than FGNN. In addition, the average F1-score of Sub-GMN on all experiments with dataset 2 reached 0.95, which demonstrates that Sub-GMN outputs more correct node-to-node matches. Comparing with the previous GNNs-based methods for subgraph matching task, our proposed Sub-GMN allows varying query and data graphes in the test/application stage, while most previous GNNs-based methods can only find a matched subgraph in the data graph during the test/application for the same query graph used in the training stage. Another advantage of our proposed Sub-GMN is that it can output a list of node-to-node matches, while most existing end-to-end GNNs based methods cannot provide the matched node pairs.
Comparison of Possibilistic Fuzzy Local Information C-Means and Possibilistic K-Nearest Neighbors for Synthetic Aperture Sonar Image Segmentation
Apr 01, 2019Synthetic aperture sonar (SAS) imagery can generate high resolution images of the seafloor. Thus, segmentation algorithms can be used to partition the images into different seafloor environments. In this paper, we compare two possibilistic segmentation approaches. Possibilistic approaches allow for the ability to detect novel or outlier environments as well as well known classes. The Possibilistic Fuzzy Local Information C-Means (PFLICM) algorithm has been previously applied to segment SAS imagery. Additionally, the Possibilistic K-Nearest Neighbors (PKNN) algorithm has been used in other domains such as landmine detection and hyperspectral imagery. In this paper, we compare the segmentation performance of a semi-supervised approach using PFLICM and a supervised method using Possibilistic K-NN. We include final segmentation results on multiple SAS images and a quantitative assessment of each algorithm.
Weakly supervised segmentation with cross-modality equivariant constraints
Apr 06, 2021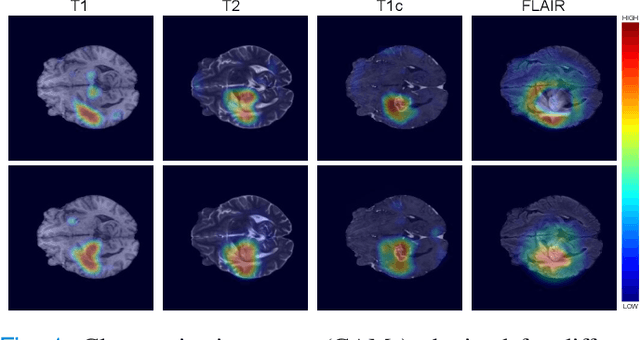
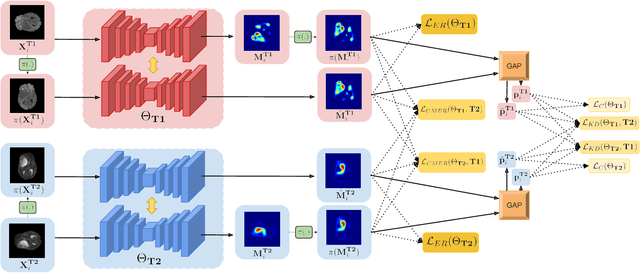
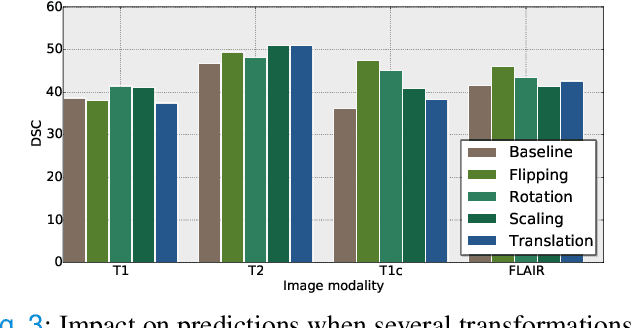
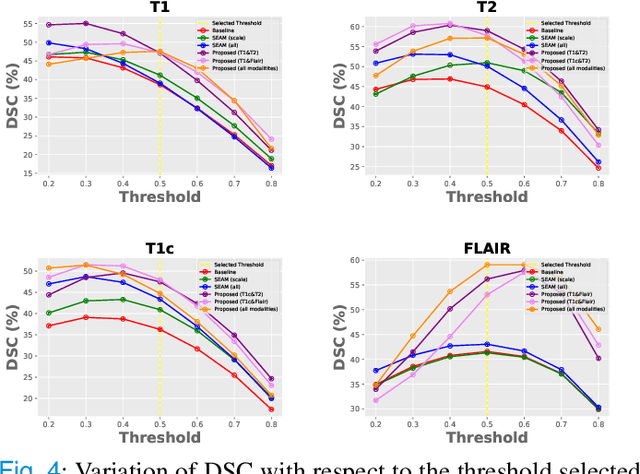
Weakly supervised learning has emerged as an appealing alternative to alleviate the need for large labeled datasets in semantic segmentation. Most current approaches exploit class activation maps (CAMs), which can be generated from image-level annotations. Nevertheless, resulting maps have been demonstrated to be highly discriminant, failing to serve as optimal proxy pixel-level labels. We present a novel learning strategy that leverages self-supervision in a multi-modal image scenario to significantly enhance original CAMs. In particular, the proposed method is based on two observations. First, the learning of fully-supervised segmentation networks implicitly imposes equivariance by means of data augmentation, whereas this implicit constraint disappears on CAMs generated with image tags. And second, the commonalities between image modalities can be employed as an efficient self-supervisory signal, correcting the inconsistency shown by CAMs obtained across multiple modalities. To effectively train our model, we integrate a novel loss function that includes a within-modality and a cross-modality equivariant term to explicitly impose these constraints during training. In addition, we add a KL-divergence on the class prediction distributions to facilitate the information exchange between modalities, which, combined with the equivariant regularizers further improves the performance of our model. Exhaustive experiments on the popular multi-modal BRATS dataset demonstrate that our approach outperforms relevant recent literature under the same learning conditions.
Reinforcement Learning with Prototypical Representations
Feb 22, 2021
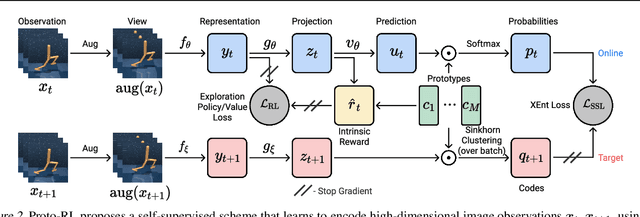
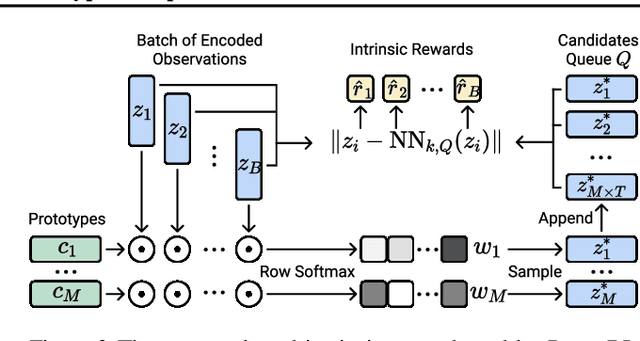
Learning effective representations in image-based environments is crucial for sample efficient Reinforcement Learning (RL). Unfortunately, in RL, representation learning is confounded with the exploratory experience of the agent -- learning a useful representation requires diverse data, while effective exploration is only possible with coherent representations. Furthermore, we would like to learn representations that not only generalize across tasks but also accelerate downstream exploration for efficient task-specific training. To address these challenges we propose Proto-RL, a self-supervised framework that ties representation learning with exploration through prototypical representations. These prototypes simultaneously serve as a summarization of the exploratory experience of an agent as well as a basis for representing observations. We pre-train these task-agnostic representations and prototypes on environments without downstream task information. This enables state-of-the-art downstream policy learning on a set of difficult continuous control tasks.