 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Radio Archives for Low-Resource Speech Recognition: Towards an Intelligent Virtual Assistant for Illiterate Users
Apr 27, 2021


For many of the 700 million illiterate people around the world, speech recognition technology could provide a bridge to valuable information and services. Yet, those most in need of this technology are often the most underserved by it. In many countries, illiterate people tend to speak only low-resource languages, for which the datasets necessary for speech technology development are scarce. In this paper, we investigate the effectiveness of unsupervised speech representation learning on noisy radio broadcasting archives, which are abundant even in low-resource languages. We make three core contributions. First, we release two datasets to the research community. The first, West African Radio Corpus, contains 142 hours of audio in more than 10 languages with a labeled validation subset. The second, West African Virtual Assistant Speech Recognition Corpus, consists of 10K labeled audio clips in four languages. Next, we share West African wav2vec, a speech encoder trained on the noisy radio corpus, and compare it with the baseline Facebook speech encoder trained on six times more data of higher quality. We show that West African wav2vec performs similarly to the baseline on a multilingual speech recognition task, and significantly outperforms the baseline on a West African language identification task. Finally, we share the first-ever speech recognition models for Maninka, Pular and Susu, languages spoken by a combined 10 million people in over seven countries, including six where the majority of the adult population is illiterate. Our contributions offer a path forward for ethical AI research to serve the needs of those most disadvantaged by the digital divide.
A Forward-Backward Approach for Visualizing Information Flow in Deep Networks
Nov 16, 2017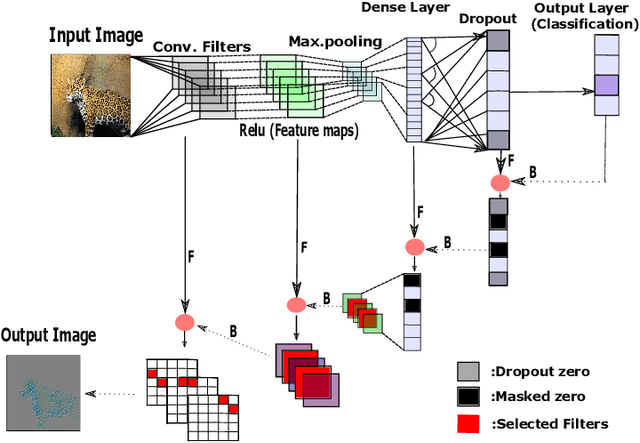

We introduce a new, systematic framework for visualizing information flow in deep networks. Specifically, given any trained deep convolutional network model and a given test image, our method produces a compact support in the image domain that corresponds to a (high-resolution) feature that contributes to the given explanation. Our method is both computationally efficient as well as numerically robust. We present several preliminary numerical results that support the benefits of our framework over existing methods.
Metric-Type Identification for Multi-Level Header Numerical Tables in Scientific Papers
Feb 01, 2021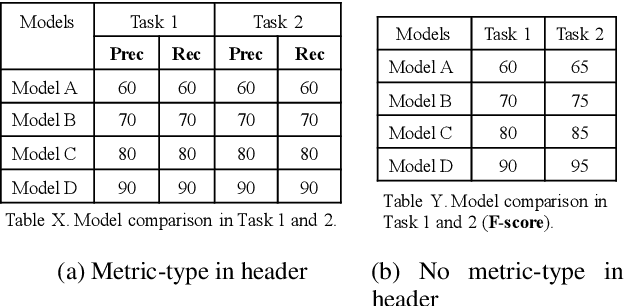
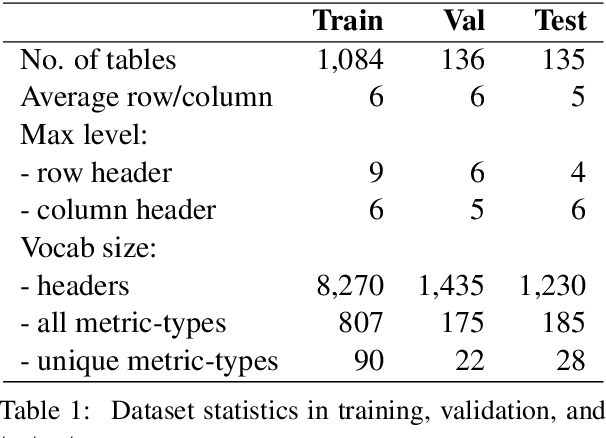
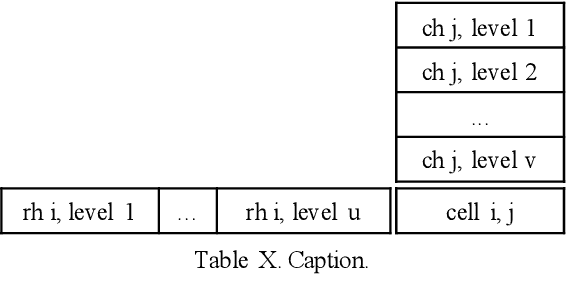
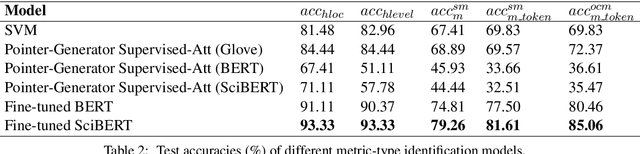
Numerical tables are widely used to present experimental results in scientific papers. For table understanding, a metric-type is essential to discriminate numbers in the tables. We introduce a new information extraction task, metric-type identification from multi-level header numerical tables, and provide a dataset extracted from scientific papers consisting of header tables, captions, and metric-types. We then propose two joint-learning neural classification and generation schemes featuring pointer-generator-based and BERT-based models. Our results show that the joint models can handle both in-header and out-of-header metric-type identification problems.
EPSR: Edge Profile Super resolution
Nov 09, 2020
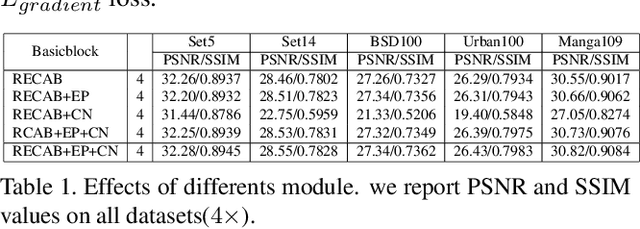
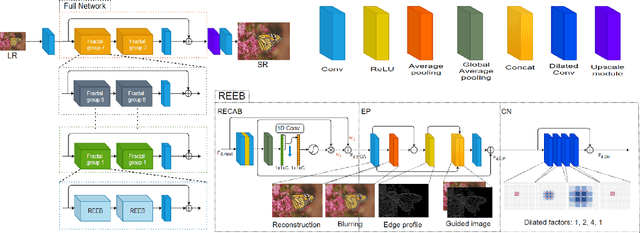
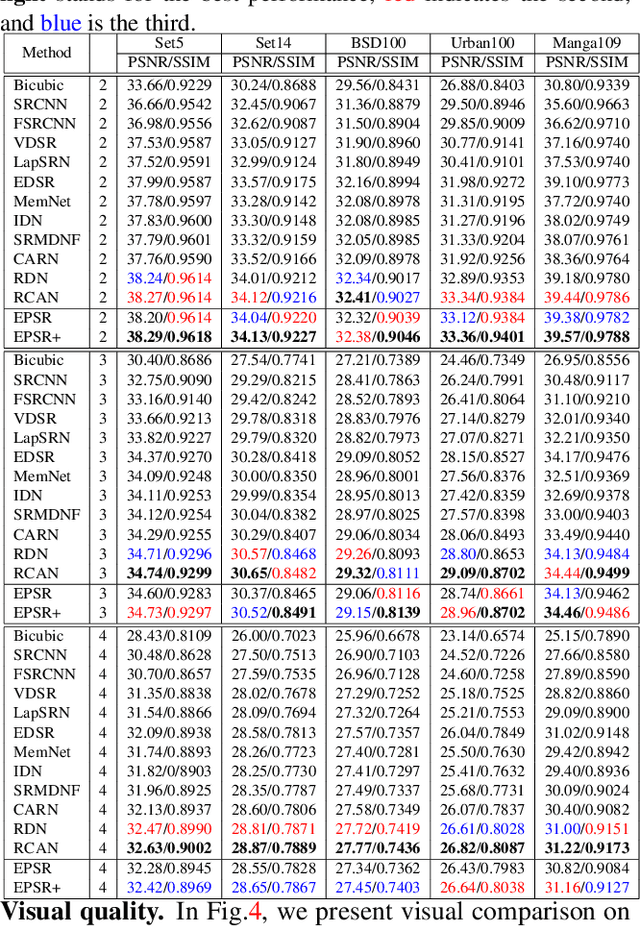
Recently numerous deep convolutional neural networks(CNNs) have been explored in single image super-resolution(SISR) and they achieved significant performance. However, most deep CNN-based SR mainly focuses on designing wider or deeper architecture and it is hard to find methods that utilize image properties in SISR. In this paper, by developing an edge-profile approach based on end-to-end CNN model to SISR problem, we propose an edge profile super resolution(EPSR). Specifically, we construct a residual edge enhance block(REEB), which consists of residual efficient channel attention block(RECAB), edge profile(EP) module, and context network(CN) module. RE-CAB extracts adaptively rescale channel-wise features by considering interdependencies among channels efficiently.From the features, EP module generates edge-guided features by extracting edge profile itself, and then CN module enhances details by exploiting contextual information of the features. To utilize various information from low to high frequency components, we design a fractal skip connection(FSC) structure. Since self-similarity of the architecture, FSC structure allows our EPSR to bypass abundant information into each REEB block. Experimental results present that our EPSR achieves competitive performance against state-of-the-art methods.
Human Pose Transfer by Adaptive Hierarchical Deformation
Dec 13, 2020Human pose transfer, as a misaligned image generation task, is very challenging. Existing methods cannot effectively utilize the input information, which often fail to preserve the style and shape of hair and clothes. In this paper, we propose an adaptive human pose transfer network with two hierarchical deformation levels. The first level generates human semantic parsing aligned with the target pose, and the second level generates the final textured person image in the target pose with the semantic guidance. To avoid the drawback of vanilla convolution that treats all the pixels as valid information, we use gated convolution in both two levels to dynamically select the important features and adaptively deform the image layer by layer. Our model has very few parameters and is fast to converge. Experimental results demonstrate that our model achieves better performance with more consistent hair, face and clothes with fewer parameters than state-of-the-art methods. Furthermore, our method can be applied to clothing texture transfer.
* 13 pages, 10 figures. Code is available at https://github.com/Zhangjinso/PINet_PG
Neural population geometry: An approach for understanding biological and artificial neural networks
Apr 14, 2021

Advances in experimental neuroscience have transformed our ability to explore the structure and function of neural circuits. At the same time, advances in machine learning have unleashed the remarkable computational power of artificial neural networks (ANNs). While these two fields have different tools and applications, they present a similar challenge: namely, understanding how information is embedded and processed through high-dimensional representations to solve complex tasks. One approach to addressing this challenge is to utilize mathematical and computational tools to analyze the geometry of these high-dimensional representations, i.e., neural population geometry. We review examples of geometrical approaches providing insight into the function of biological and artificial neural networks: representation untangling in perception, a geometric theory of classification capacity, disentanglement and abstraction in cognitive systems, topological representations underlying cognitive maps, dynamic untangling in motor systems, and a dynamical approach to cognition. Together, these findings illustrate an exciting trend at the intersection of machine learning, neuroscience, and geometry, in which neural population geometry provides a useful population-level mechanistic descriptor underlying task implementation. Importantly, geometric descriptions are applicable across sensory modalities, brain regions, network architectures and timescales. Thus, neural population geometry has the potential to unify our understanding of structure and function in biological and artificial neural networks, bridging the gap between single neurons, populations and behavior.
Fast and Robust Symmetric Image Registration Based on Intensity and Spatial Information
Jul 30, 2018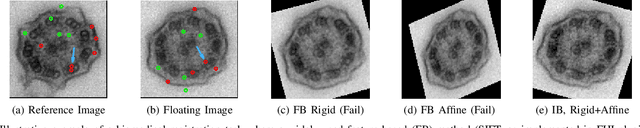
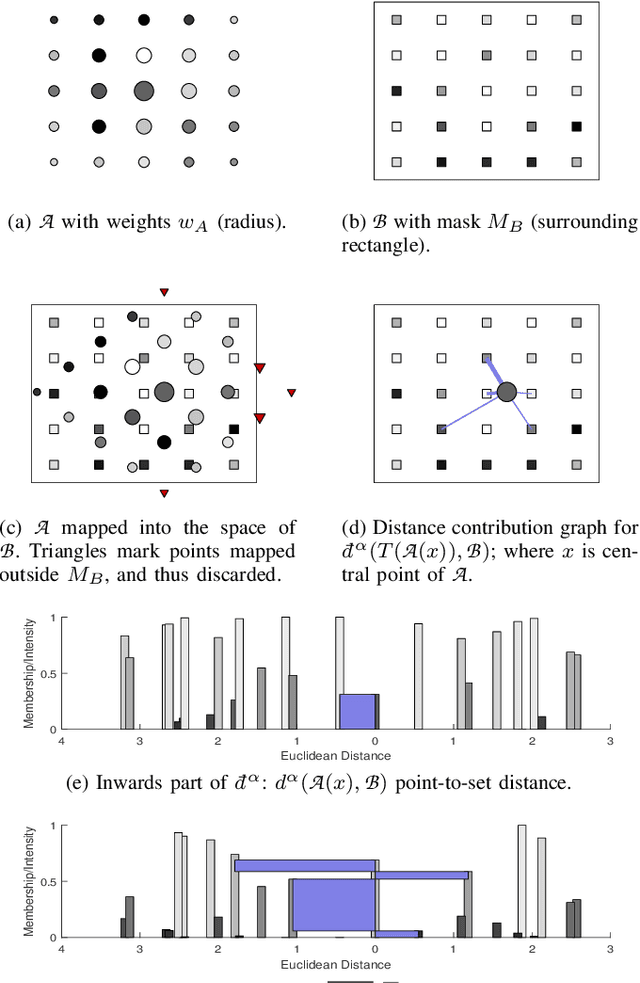
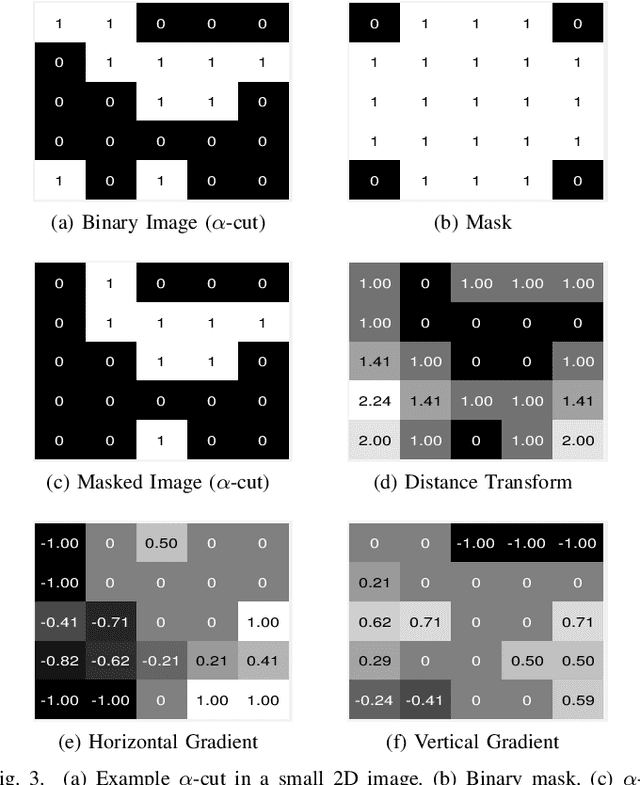
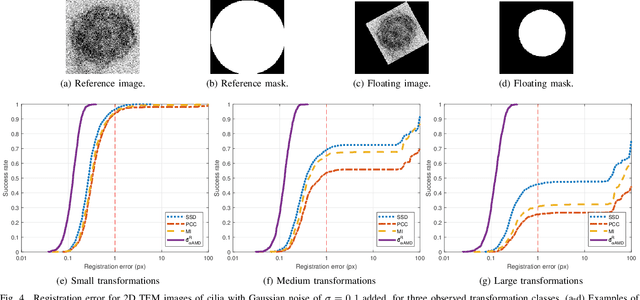
Intensity-based image registration approaches rely on similarity measures to guide the search for geometric correspondences with high affinity between images. The properties of the used measure are vital for the robustness and accuracy of the registration. In this study a symmetric, intensity interpolation-free, affine registration framework based on a combination of intensity and spatial information is proposed. The excellent performance of the framework is demonstrated on a combination of synthetic tests, recovering known transformations in the presence of noise, and real applications in biomedical and medical image registration, for both 2D and 3D images. The method exhibits greater robustness and higher accuracy than similarity measures in common use, when inserted into a standard gradient-based registration framework available as part of the open source Insight Segmentation and Registration Toolkit (ITK). The method is also empirically shown to have a low computational cost, making it practical for real applications. Source code is available.
Cascaded Semantic and Positional Self-Attention Network for Document Classification
Sep 19, 2020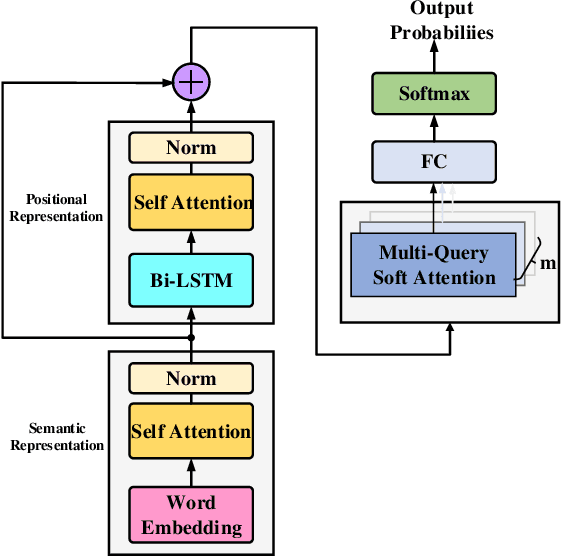

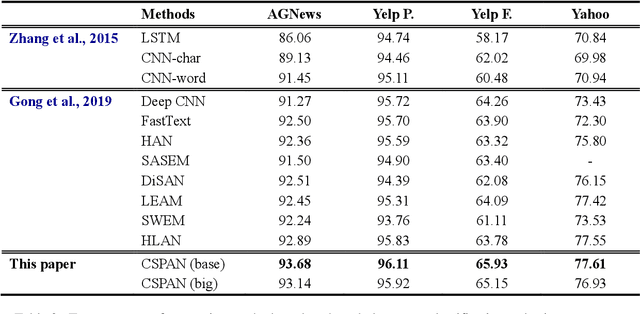
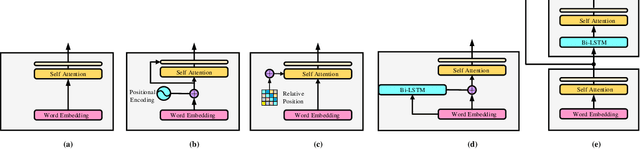
Transformers have shown great success in learning representations for language modelling. However, an open challenge still remains on how to systematically aggregate semantic information (word embedding) with positional (or temporal) information (word orders). In this work, we propose a new architecture to aggregate the two sources of information using cascaded semantic and positional self-attention network (CSPAN) in the context of document classification. The CSPAN uses a semantic self-attention layer cascaded with Bi-LSTM to process the semantic and positional information in a sequential manner, and then adaptively combine them together through a residue connection. Compared with commonly used positional encoding schemes, CSPAN can exploit the interaction between semantics and word positions in a more interpretable and adaptive manner, and the classification performance can be notably improved while simultaneously preserving a compact model size and high convergence rate. We evaluate the CSPAN model on several benchmark data sets for document classification with careful ablation studies, and demonstrate the encouraging results compared with state of the art.
DRL-Assisted Resource Allocation for NOMA-MEC Offloading with Hybrid SIC
Apr 07, 2021
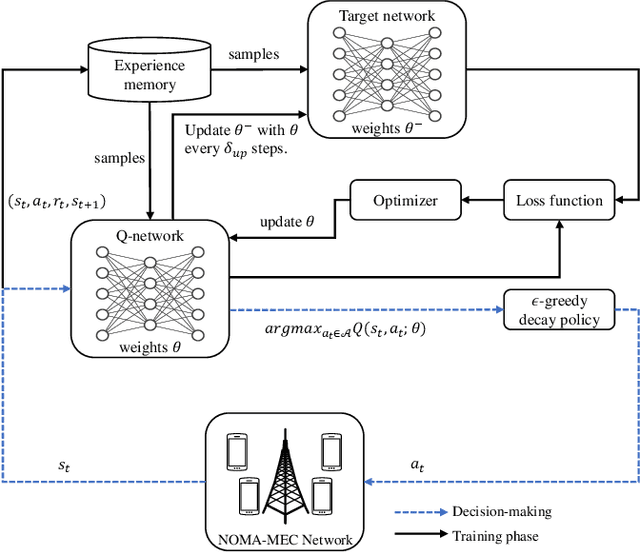
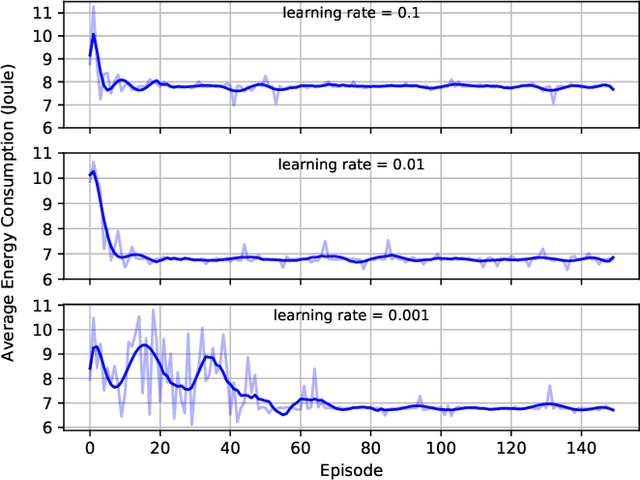
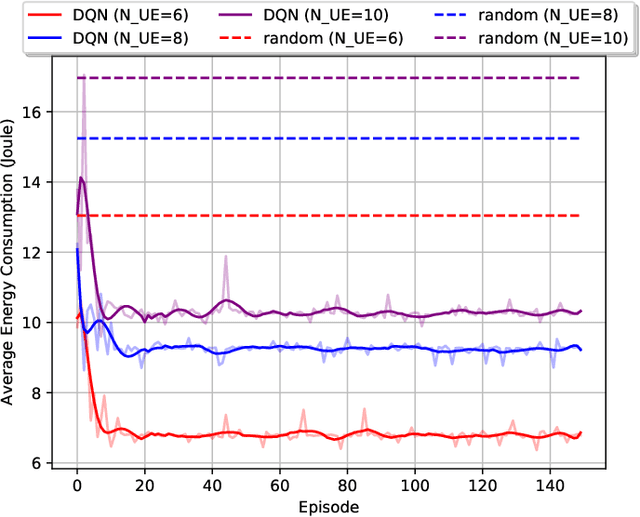
Multi-access edge computing (MEC) and non-orthogonal multiple access (NOMA) have been regarded as promising technologies to improve computation capability and offloading efficiency of the mobile devices in the sixth generation (6G) mobile system. This paper mainly focuses on the hybrid NOMA-MEC system, where multiple users are first grouped into pairs, and users in each pair offload their tasks simultaneously by NOMA, and then a dedicated time duration is scheduled to the more delay-tolerable user for uploading the remaining data by orthogonal multiple access (OMA). For the conventional NOMA uplink transmission, successive interference cancellation (SIC) is applied to decode the superposed signals successively according to the channel state information (CSI) or the quality of service (QoS) requirement. In this work, we integrate the hybrid SIC scheme which dynamically adapts the SIC decoding order among all NOMA groups. To solve the user grouping problem, a deep reinforcement learning (DRL) based algorithm is proposed to obtain a close-to-optimal user grouping policy. Moreover, we optimally minimize the offloading energy consumption by obtaining the closed-form solution to the resource allocation problem. Simulation results show that the proposed algorithm converges fast, and the NOMA-MEC scheme outperforms the existing orthogonal multiple access (OMA) scheme.
Active Learning for Segmentation by Optimizing Content Information for Maximal Entropy
Jul 18, 2018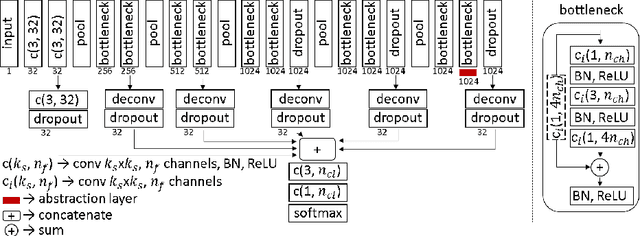

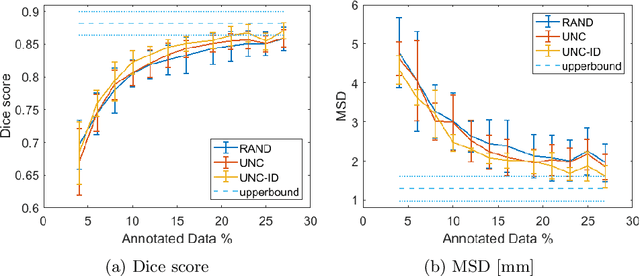
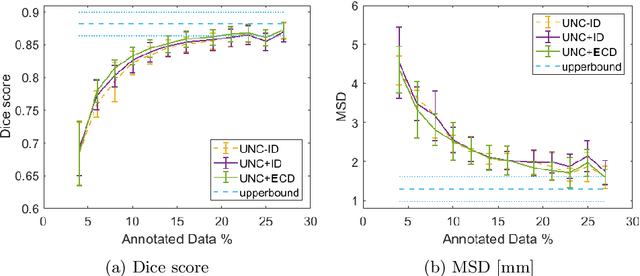
Segmentation is essential for medical image analysis tasks such as intervention planning, therapy guidance, diagnosis, treatment decisions. Deep learning is becoming increasingly prominent for segmentation, where the lack of annotations, however, often becomes the main limitation. Due to privacy concerns and ethical considerations, most medical datasets are created, curated, and allow access only locally. Furthermore, current deep learning methods are often suboptimal in translating anatomical knowledge between different medical imaging modalities. Active learning can be used to select an informed set of image samples to request for manual annotation, in order to best utilize the limited annotation time of clinical experts for optimal outcomes, which we focus on in this work. Our contributions herein are two fold: (1) we enforce domain-representativeness of selected samples using a proposed penalization scheme to maximize information at the network abstraction layer, and (2) we propose a Borda-count based sample querying scheme for selecting samples for segmentation. Comparative experiments with baseline approaches show that the samples queried with our proposed method, where both above contributions are combined, result in significantly improved segmentation performance for this active learning task.