 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
Dec 23, 2020
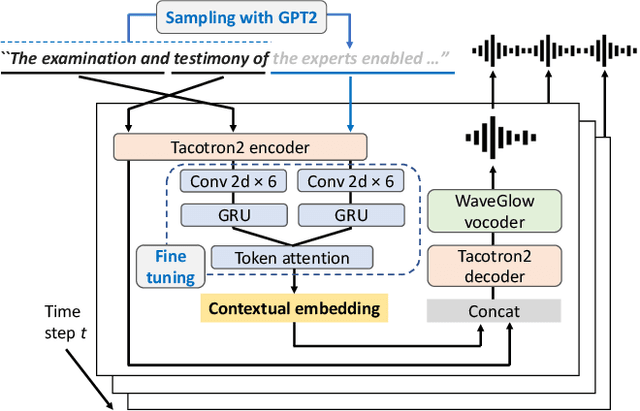
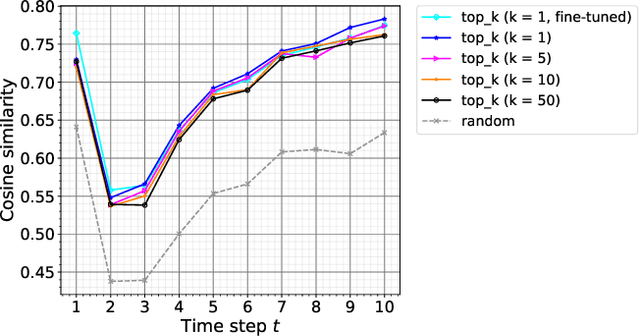
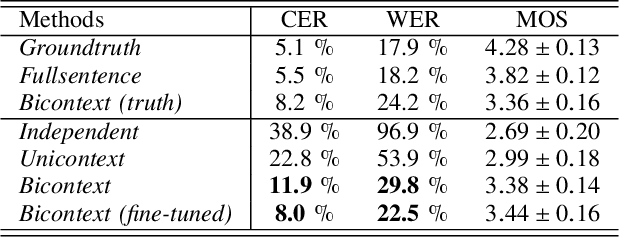
Text-to-speech (TTS) synthesis, a technique for artificially generating human-like utterances from texts, has dramatically evolved with the advances of end-to-end deep neural network-based methods in recent years. The majority of these methods are sentence-level TTS, which can take into account time-series information in the whole sentence. However, it is necessary to establish incremental TTS, which performs synthesis in smaller linguistic units, to realize low-latency synthesis usable for simultaneous speech-to-speech translation systems. In general, incremental TTS is subject to a trade-off between the latency and quality of output speech. It is challenging to produce high-quality speech with a low-latency setup that does not make much use of an unobserved future sentence (hereafter, "lookahead"). This study proposes an incremental TTS method that uses the pseudo lookahead generated with a language model to consider the future contextual information without increasing latency. Our method can be regarded as imitating a human's incremental reading and uses pretrained GPT2, which accounts for the large-scale linguistic knowledge, for the lookahead generation. Evaluation results show that our method 1) achieves higher speech quality without increasing the latency than the method using only observed information and 2) reduces the latency while achieving the equivalent speech quality to waiting for the future context observation.
ORBIT: Ordering Based Information Transfer Across Space and Time for Global Surface Water Monitoring
Nov 15, 2017
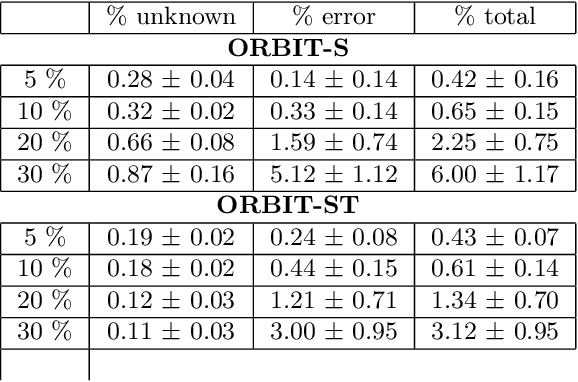
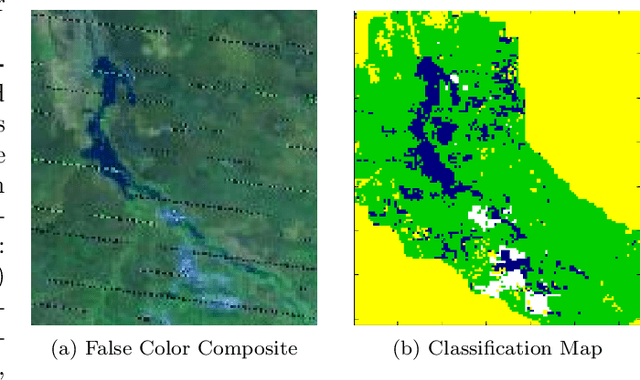
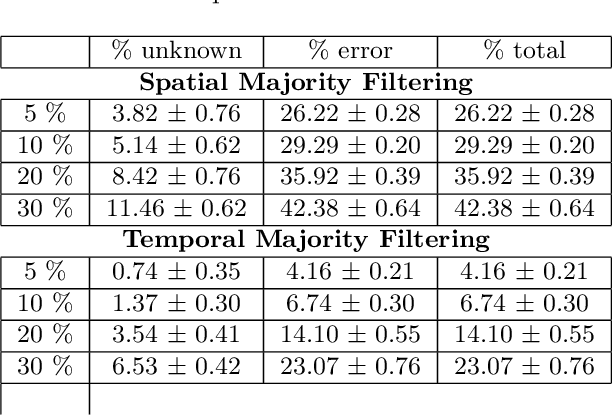
Many earth science applications require data at both high spatial and temporal resolution for effective monitoring of various ecosystem resources. Due to practical limitations in sensor design, there is often a trade-off in different resolutions of spatio-temporal datasets and hence a single sensor alone cannot provide the required information. Various data fusion methods have been proposed in the literature that mainly rely on individual timesteps when both datasets are available to learn a mapping between features values at different resolutions using local relationships between pixels. Earth observation data is often plagued with spatially and temporally correlated noise, outliers and missing data due to atmospheric disturbances which pose a challenge in learning the mapping from a local neighborhood at individual timesteps. In this paper, we aim to exploit time-independent global relationships between pixels for robust transfer of information across different scales. Specifically, we propose a new framework, ORBIT (Ordering Based Information Transfer) that uses relative ordering constraint among pixels to transfer information across both time and scales. The effectiveness of the framework is demonstrated for global surface water monitoring using both synthetic and real-world datasets.
Efficient emotion recognition using hyperdimensional computing with combinatorial channel encoding and cellular automata
Apr 06, 2021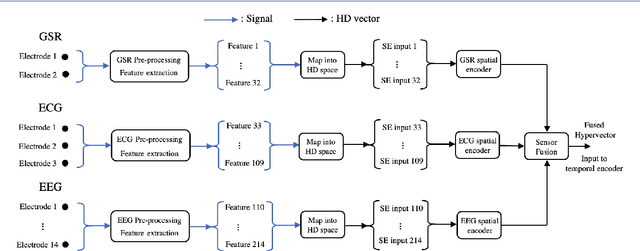
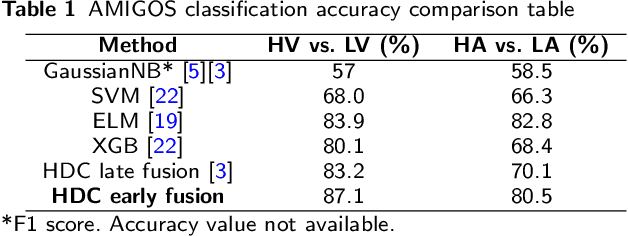
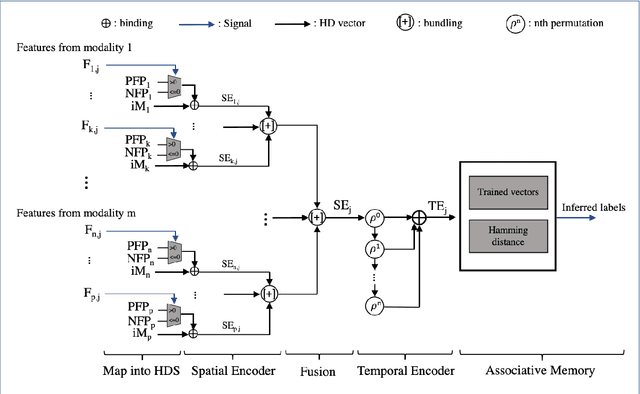
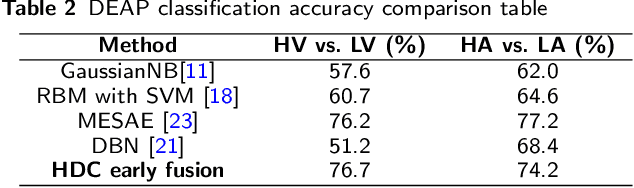
In this paper, a hardware-optimized approach to emotion recognition based on the efficient brain-inspired hyperdimensional computing (HDC) paradigm is proposed. Emotion recognition provides valuable information for human-computer interactions, however the large number of input channels (>200) and modalities (>3) involved in emotion recognition are significantly expensive from a memory perspective. To address this, methods for memory reduction and optimization are proposed, including a novel approach that takes advantage of the combinatorial nature of the encoding process, and an elementary cellular automaton. HDC with early sensor fusion is implemented alongside the proposed techniques achieving two-class multi-modal classification accuracies of >76% for valence and >73% for arousal on the multi-modal AMIGOS and DEAP datasets, almost always better than state of the art. The required vector storage is seamlessly reduced by 98% and the frequency of vector requests by at least 1/5. The results demonstrate the potential of efficient hyperdimensional computing for low-power, multi-channeled emotion recognition tasks.
Generating Ten BCI Commands Using Four Simple Motor Imageries
May 30, 2021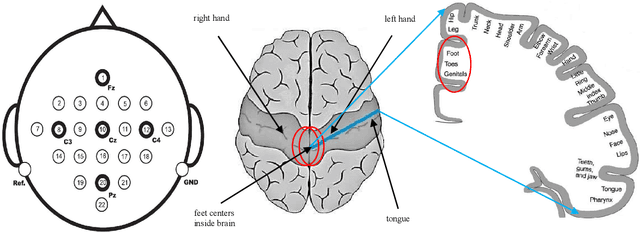
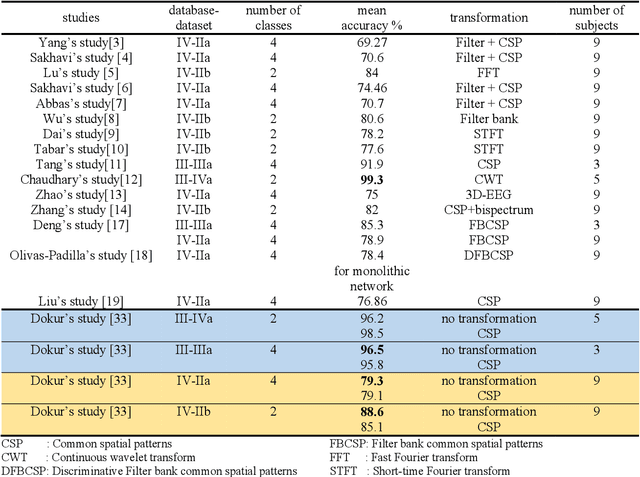
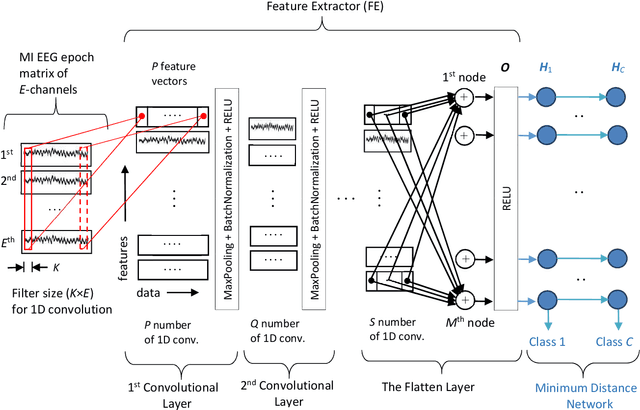
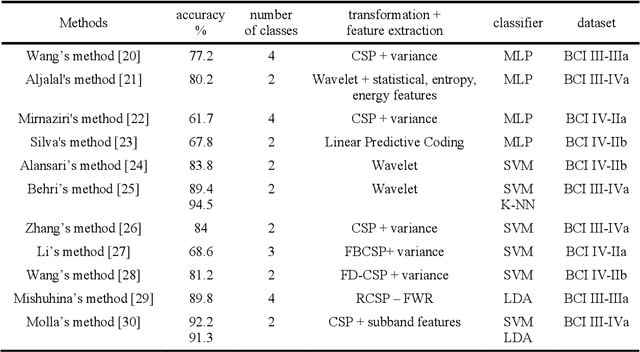
The brain computer interface (BCI) systems are utilized for transferring information among humans and computers by analyzing electroencephalogram (EEG) recordings.The process of mentally previewing a motor movement without generating the corporal output can be described as motor imagery (MI).In this emerging research field, the number of commands is also limited in relation to the number of MI tasks; in the current literature, mostly two or four commands (classes) are studied. As a solution to this problem, it is recommended to use mental tasks as well as MI tasks. Unfortunately, the use of this approach reduces the classification performance of MI EEG signals. The fMRI analyses show that the resources in the brain associated with the motor imagery can be activated independently. It is assumed that the brain activity induced by the MI of the combination of body parts corresponds to the superposition of the activities generated during each body parts's simple MI. In this study, in order to create more than four BCI commands, we suggest to generate combined MI EEG signals artificially by using left hand, right hand, tongue, and feet motor imageries in pairs. A maximum of ten different BCI commands can be generated by using four motor imageries in pairs.This study aims to achieve high classification performances for BCI commands produced from four motor imageries by implementing a small-sized deep neural network (DNN).The presented method is evaluated on the four-class datasets of BCI Competitions III and IV, and an average classification performance of 81.8% is achieved for ten classes. The above assumption is also validated on a different dataset which consists of simple and combined MI EEG signals acquired in real time. Trained with the artificially generated combined MI EEG signals, DivFE resulted in an average of 76.5% success rate for the combined MI EEG signals acquired in real-time.
A Framework for Unsupervised Classificiation and Data Mining of Tweets about Cyber Vulnerabilities
Apr 23, 2021


Many cyber network defense tools rely on the National Vulnerability Database (NVD) to provide timely information on known vulnerabilities that exist within systems on a given network. However, recent studies have indicated that the NVD is not always up to date, with known vulnerabilities being discussed publicly on social media platforms, like Twitter and Reddit, months before they are published to the NVD. To that end, we present a framework for unsupervised classification to filter tweets for relevance to cyber security. We consider and evaluate two unsupervised machine learning techniques for inclusion in our framework, and show that zero-shot classification using a Bidirectional and Auto-Regressive Transformers (BART) model outperforms the other technique with 83.52% accuracy and a F1 score of 83.88, allowing for accurate filtering of tweets without human intervention or labelled data for training. Additionally, we discuss different insights that can be derived from these cyber-relevant tweets, such as trending topics of tweets and the counts of Twitter mentions for Common Vulnerabilities and Exposures (CVEs), that can be used in an alert or report to augment current NVD-based risk assessment tools.
Evolution of artificial intelligence languages, a systematic literature review
Jan 27, 2021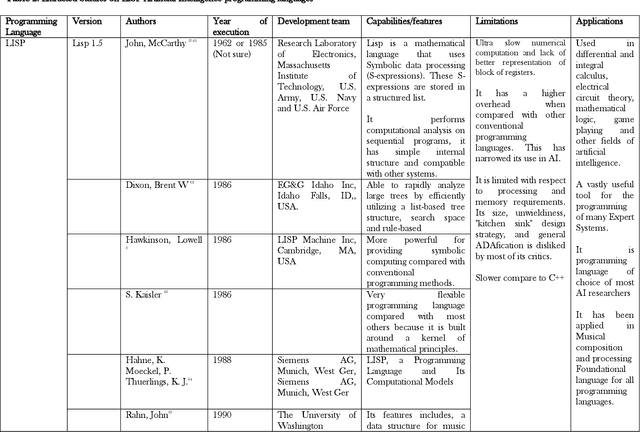
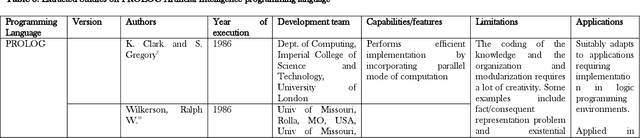


The field of Artificial Intelligence (AI) has undoubtedly received significant attention in recent years. AI is being adopted to provide solutions to problems in fields such as medicine, engineering, education, government and several other domains. In order to analyze the state of the art of research in the field of AI, we present a systematic literature review focusing on the Evolution of AI programming languages. We followed the systematic literature review method by searching relevant databases like SCOPUS, IEEE Xplore and Google Scholar. EndNote reference manager was used to catalog the relevant extracted papers. Our search returned a total of 6565 documents, whereof 69 studies were retained. Of the 69 retained studies, 15 documents discussed LISP programming language, another 34 discussed PROLOG programming language, the remaining 20 documents were spread between Logic and Object Oriented Programming (LOOP), ARCHLOG, Epistemic Ontology Language with Constraints (EOLC), Python, C++, ADA and JAVA programming languages. This review provides information on the year of implementation, development team, capabilities, limitations and applications of each of the AI programming languages discussed. The information in this review could guide practitioners and researchers in AI to make the right choice of languages to implement their novel AI methods.
DelugeNets: Deep Networks with Efficient and Flexible Cross-layer Information Inflows
Aug 23, 2017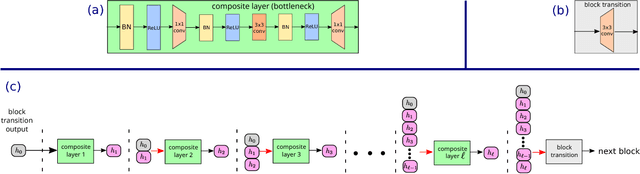
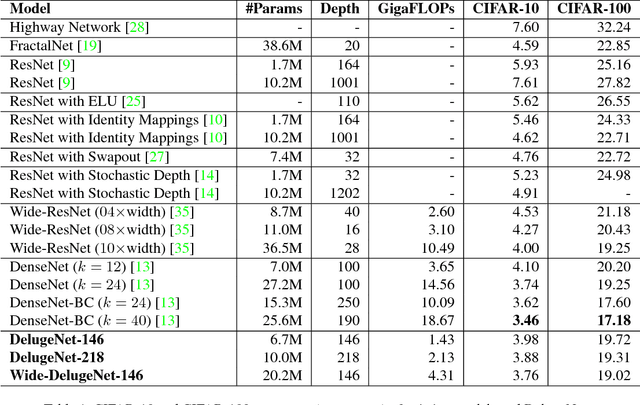
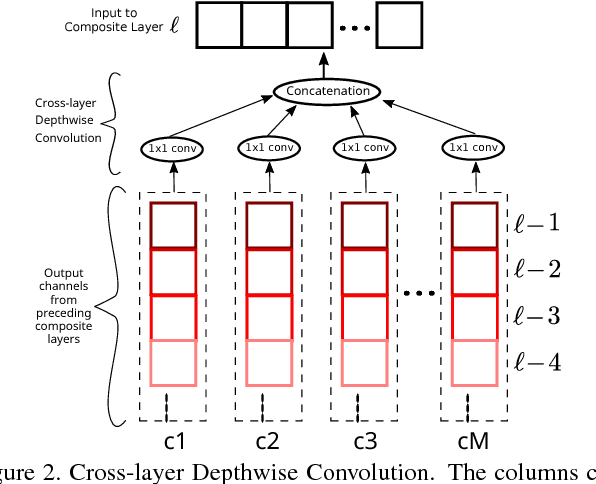
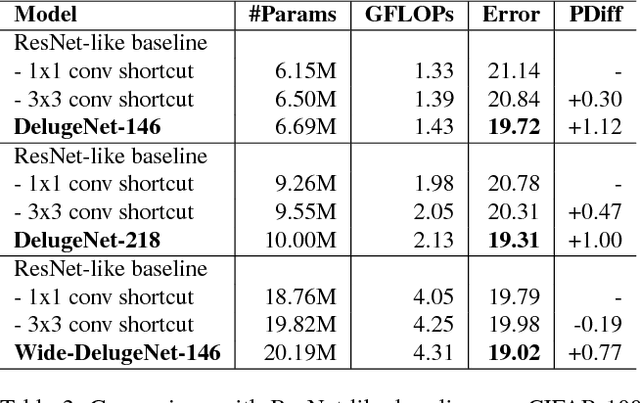
Deluge Networks (DelugeNets) are deep neural networks which efficiently facilitate massive cross-layer information inflows from preceding layers to succeeding layers. The connections between layers in DelugeNets are established through cross-layer depthwise convolutional layers with learnable filters, acting as a flexible yet efficient selection mechanism. DelugeNets can propagate information across many layers with greater flexibility and utilize network parameters more effectively compared to ResNets, whilst being more efficient than DenseNets. Remarkably, a DelugeNet model with just model complexity of 4.31 GigaFLOPs and 20.2M network parameters, achieve classification errors of 3.76% and 19.02% on CIFAR-10 and CIFAR-100 dataset respectively. Moreover, DelugeNet-122 performs competitively to ResNet-200 on ImageNet dataset, despite costing merely half of the computations needed by the latter.
Inheritance-guided Hierarchical Assignment for Clinical Automatic Diagnosis
Jan 27, 2021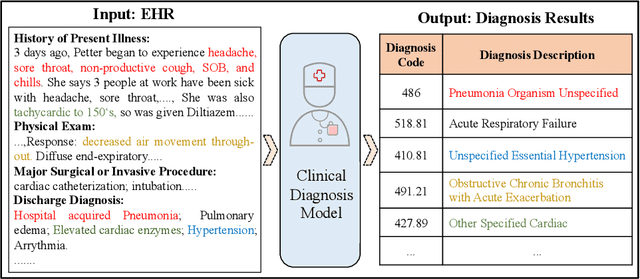
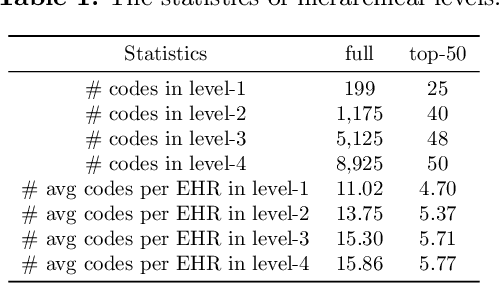
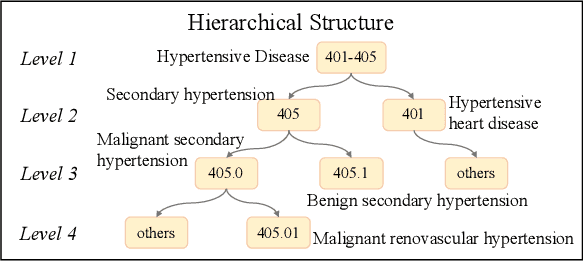
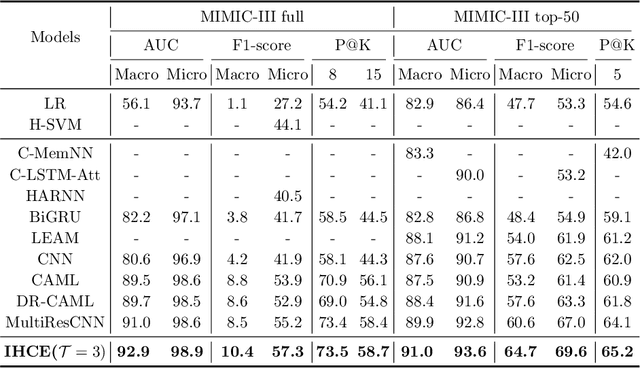
Clinical diagnosis, which aims to assign diagnosis codes for a patient based on the clinical note, plays an essential role in clinical decision-making. Considering that manual diagnosis could be error-prone and time-consuming, many intelligent approaches based on clinical text mining have been proposed to perform automatic diagnosis. However, these methods may not achieve satisfactory results due to the following challenges. First, most of the diagnosis codes are rare, and the distribution is extremely unbalanced. Second, existing methods are challenging to capture the correlation between diagnosis codes. Third, the lengthy clinical note leads to the excessive dispersion of key information related to codes. To tackle these challenges, we propose a novel framework to combine the inheritance-guided hierarchical assignment and co-occurrence graph propagation for clinical automatic diagnosis. Specifically, we propose a hierarchical joint prediction strategy to address the challenge of unbalanced codes distribution. Then, we utilize graph convolutional neural networks to obtain the correlation and semantic representations of medical ontology. Furthermore, we introduce multi attention mechanisms to extract crucial information. Finally, extensive experiments on MIMIC-III dataset clearly validate the effectiveness of our method.
NICE: An Algorithm for Nearest Instance Counterfactual Explanations
Apr 15, 2021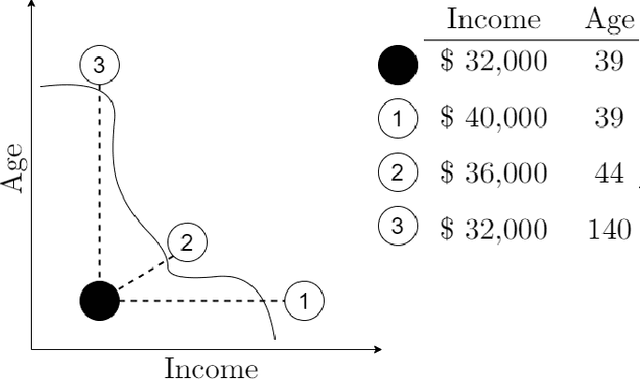
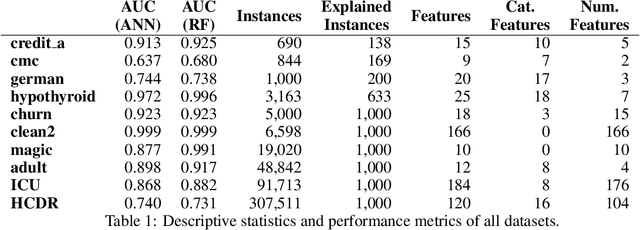

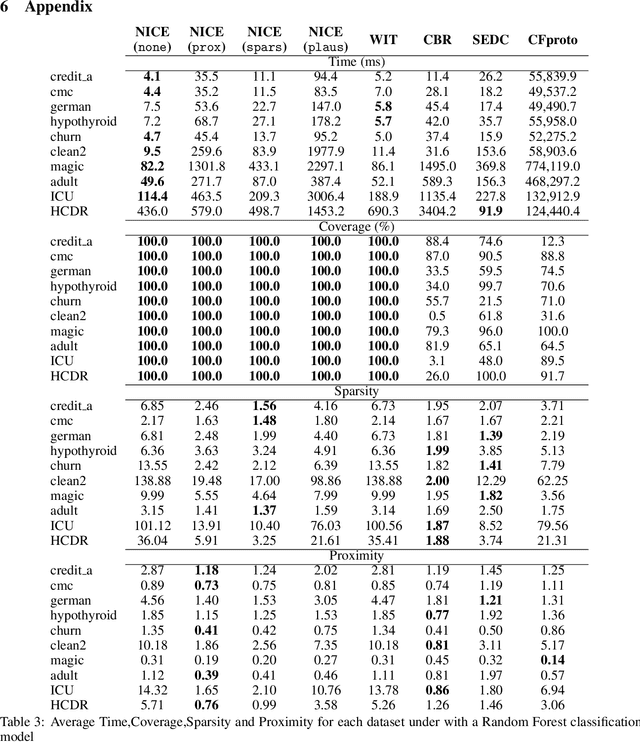
In this paper we suggest NICE: a new algorithm to generate counterfactual explanations for heterogeneous tabular data. The design of our algorithm specifically takes into account algorithmic requirements that often emerge in real-life deployments: the ability to provide an explanation for all predictions, being efficient in run-time, and being able to handle any classification model (also non-differentiable ones). More specifically, our approach exploits information from a nearest instance tospeed up the search process. We propose four versions of NICE, where three of them optimize the explanations for one of the following properties: sparsity, proximity or plausibility. An extensive empirical comparison on 10 datasets shows that our algorithm performs better on all properties than the current state-of-the-art. These analyses show a trade-off between on the one hand plausiblity and on the other hand proximity or sparsity, with our different optimization methods offering the choice to select the preferred trade-off. An open-source implementation of NICE can be found at https://github.com/ADMAntwerp/NICE.
gradSim: Differentiable simulation for system identification and visuomotor control
Apr 06, 2021
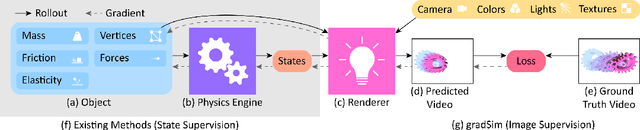
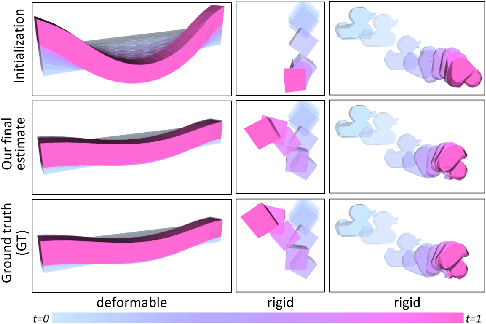

We consider the problem of estimating an object's physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph -- spanning from the dynamics and through the rendering process -- enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.