 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegradSim: Differentiable simulation for system identification and visuomotor control
Apr 06, 2021
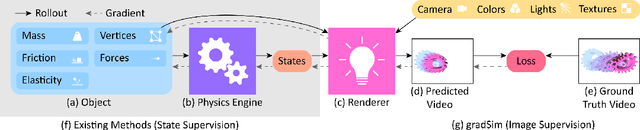
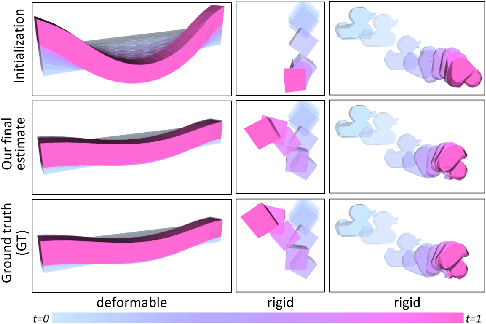

We consider the problem of estimating an object's physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph -- spanning from the dynamics and through the rendering process -- enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.
The AI Driving Olympics at NeurIPS 2018
Mar 06, 2019
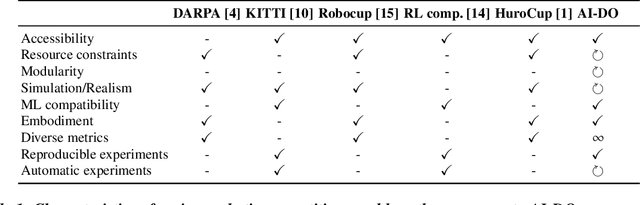
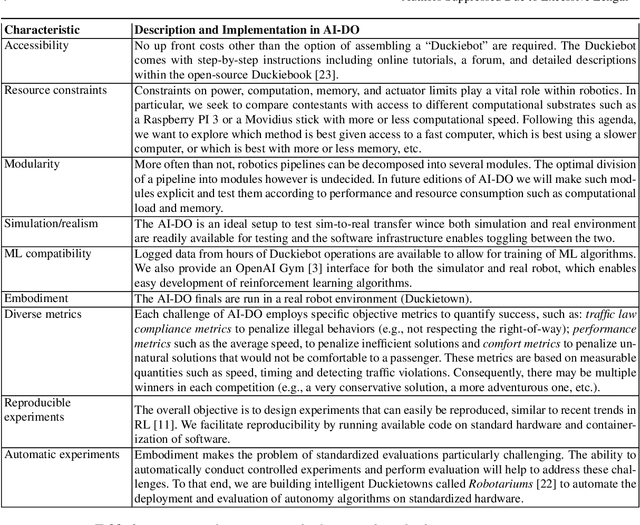

Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the 'AI Driving Olympics' (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called 'Duckietown', AI-DO includes a series of tasks of increasing complexity -- from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.
Multi-objective training of Generative Adversarial Networks with multiple discriminators
Jan 24, 2019

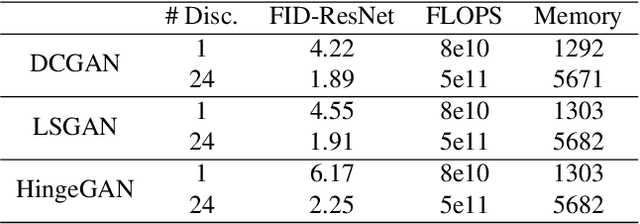
Recent literature has demonstrated promising results for training Generative Adversarial Networks by employing a set of discriminators, in contrast to the traditional game involving one generator against a single adversary. Such methods perform single-objective optimization on some simple consolidation of the losses, e.g. an arithmetic average. In this work, we revisit the multiple-discriminator setting by framing the simultaneous minimization of losses provided by different models as a multi-objective optimization problem. Specifically, we evaluate the performance of multiple gradient descent and the hypervolume maximization algorithm on a number of different datasets. Moreover, we argue that the previously proposed methods and hypervolume maximization can all be seen as variations of multiple gradient descent in which the update direction can be computed efficiently. Our results indicate that hypervolume maximization presents a better compromise between sample quality and computational cost than previous methods.
Deep Pepper: Expert Iteration based Chess agent in the Reinforcement Learning Setting
Oct 17, 2018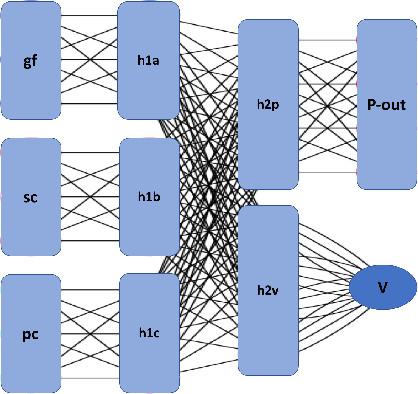
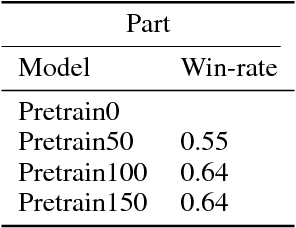
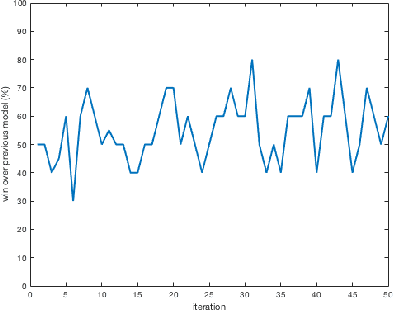
An almost-perfect chess playing agent has been a long standing challenge in the field of Artificial Intelligence. Some of the recent advances demonstrate we are approaching that goal. In this project, we provide methods for faster training of self-play style algorithms, mathematical details of the algorithm used, various potential future directions, and discuss most of the relevant work in the area of computer chess. Deep Pepper uses embedded knowledge to accelerate the training of the chess engine over a "tabula rasa" system such as Alpha Zero. We also release our code to promote further research.