 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Communications using Sparse Signals
Feb 06, 2021

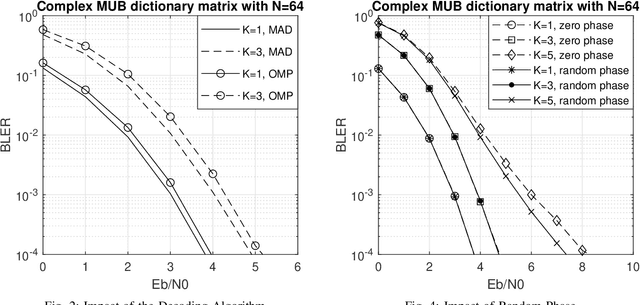
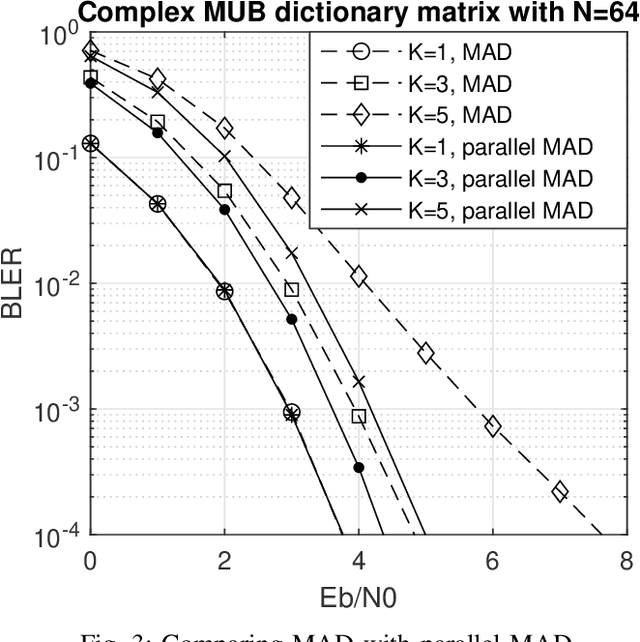
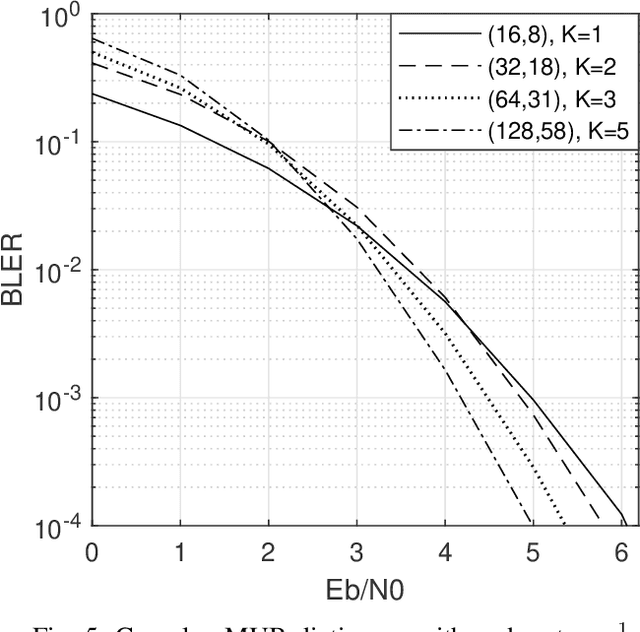
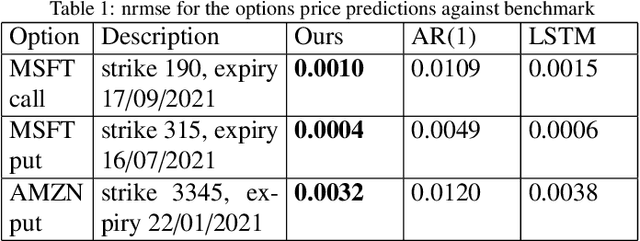
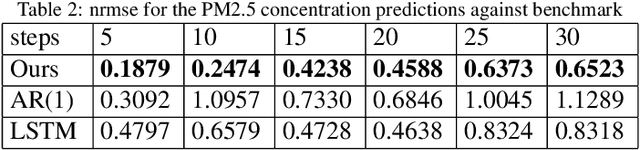
Inspired by compressive sensing principles, we propose novel error control coding techniques for communication systems. The information bits are encoded in the support and the non-zero entries of a sparse signal. By selecting a dictionary matrix with suitable dimensions, the codeword for transmission is obtained by multiplying the dictionary matrix with the sparse signal. Specifically, the codewords are obtained from the sparse linear combinations of the columns of the dictionary matrix. At the decoder, we employ variations of greedy sparse signal recovery algorithms. Using Gold code sequences and mutually unbiased bases from quantum information theory as dictionary matrices, we study the block error rate (BLER) performance of the proposed scheme in the AWGN channel. Our results show that the proposed scheme has a comparable and competitive performance with respect to the several widely used linear codes, for very small to moderate block lengths. In addition, our coding scheme extends straightforwardly to multi-user scenarios such as multiple access channel, broadcast channel, and interference channel. In these multi-user channels, if the users are grouped such that they have similar channel gains and noise levels, the overall BLER performance of our proposed scheme will coincide with an equivalent single-user scenario.
FatNet: A Feature-attentive Network for 3D Point Cloud Processing
Apr 07, 2021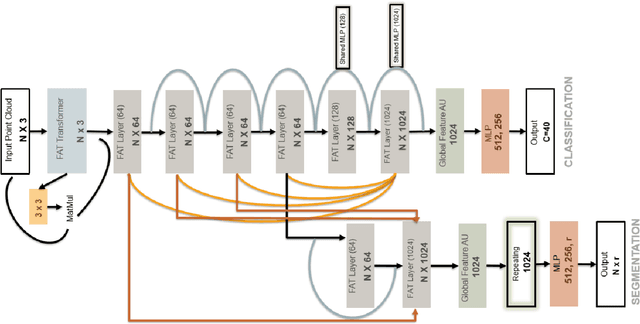
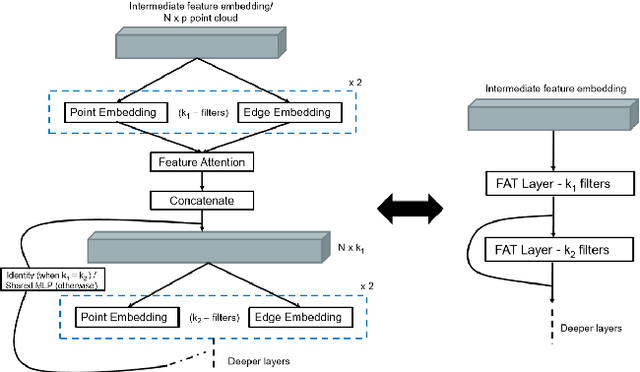
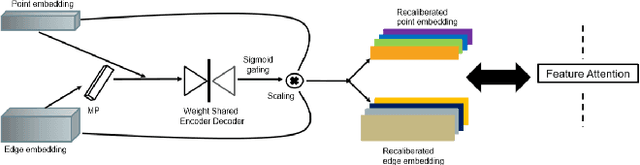
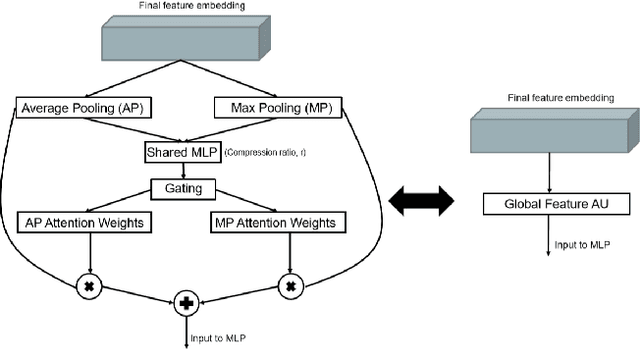
The application of deep learning to 3D point clouds is challenging due to its lack of order. Inspired by the point embeddings of PointNet and the edge embeddings of DGCNNs, we propose three improvements to the task of point cloud analysis. First, we introduce a novel feature-attentive neural network layer, a FAT layer, that combines both global point-based features and local edge-based features in order to generate better embeddings. Second, we find that applying the same attention mechanism across two different forms of feature map aggregation, max pooling and average pooling, gives better performance than either alone. Third, we observe that residual feature reuse in this setting propagates information more effectively between the layers, and makes the network easier to train. Our architecture achieves state-of-the-art results on the task of point cloud classification, as demonstrated on the ModelNet40 dataset, and an extremely competitive performance on the ShapeNet part segmentation challenge.
Stochastic Recurrent Neural Network for Multistep Time Series Forecasting
May 02, 2021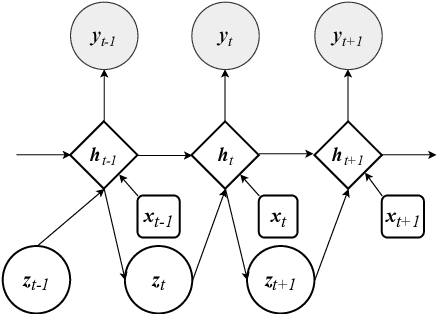
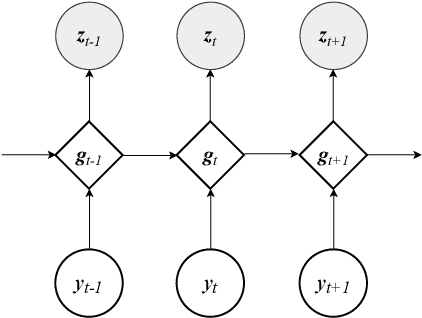
Time series forecasting based on deep architectures has been gaining popularity in recent years due to their ability to model complex non-linear temporal dynamics. The recurrent neural network is one such model capable of handling variable-length input and output. In this paper, we leverage recent advances in deep generative models and the concept of state space models to propose a stochastic adaptation of the recurrent neural network for multistep-ahead time series forecasting, which is trained with stochastic gradient variational Bayes. In our model design, the transition function of the recurrent neural network, which determines the evolution of the hidden states, is stochastic rather than deterministic as in a regular recurrent neural network; this is achieved by incorporating a latent random variable into the transition process which captures the stochasticity of the temporal dynamics. Our model preserves the architectural workings of a recurrent neural network for which all relevant information is encapsulated in its hidden states, and this flexibility allows our model to be easily integrated into any deep architecture for sequential modelling. We test our model on a wide range of datasets from finance to healthcare; results show that the stochastic recurrent neural network consistently outperforms its deterministic counterpart.
Natural Language Inference with a Human Touch: Using Human Explanations to Guide Model Attention
Apr 16, 2021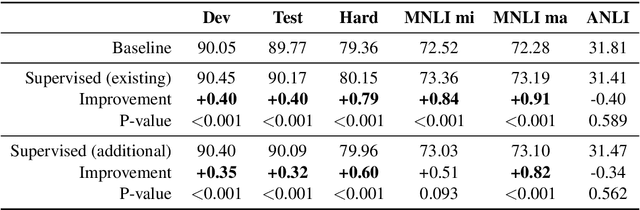
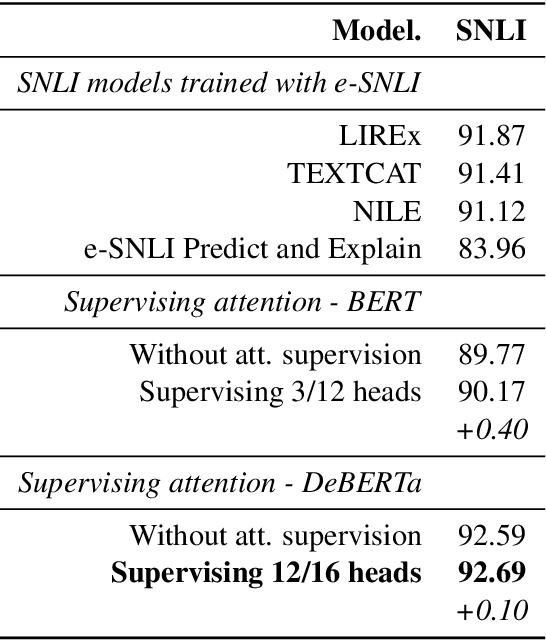
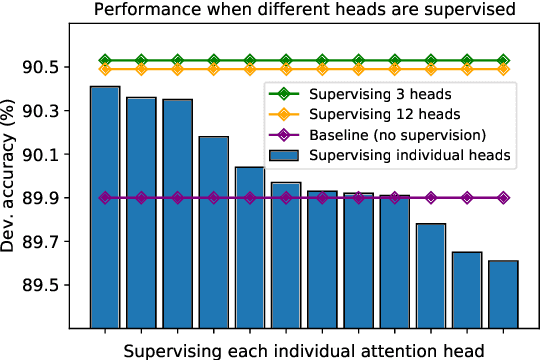
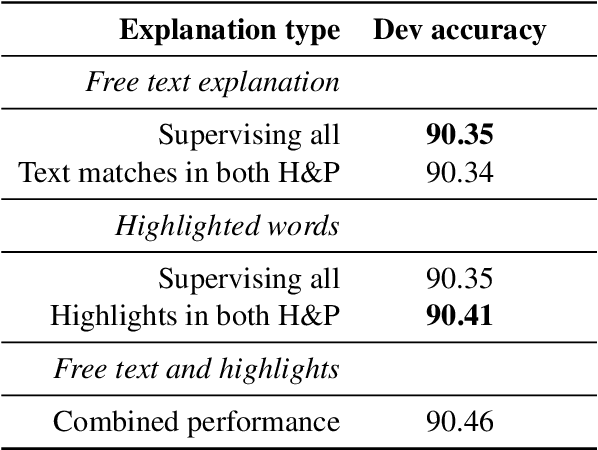
Natural Language Inference (NLI) models are known to learn from biases and artefacts within their training data, impacting how well the models generalise to other unseen datasets. While previous de-biasing approaches focus on preventing models learning from these biases, we instead provide models with information about how a human would approach the task, with the aim of encouraging the model to learn features that will generalise better to out-of-domain datasets. Using natural language explanations, we supervise a model's attention weights to encourage more attention to be paid to the words present in these explanations. For the first time, we show that training with human generated explanations can simultaneously improve performance both in-distribution and out-of-distribution for NLI, whereas most related work on robustness involves a trade-off between the two. Training with the human explanations encourages models to attend more broadly across the sentences, paying more attention to words in the premise and less attention to stop-words and punctuation. The supervised models attend to words humans believe are important, creating more robust and better performing NLI models.
Verification of Image-based Neural Network Controllers Using Generative Models
May 14, 2021

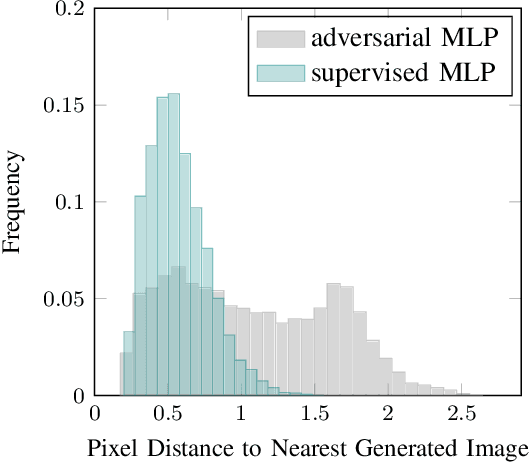
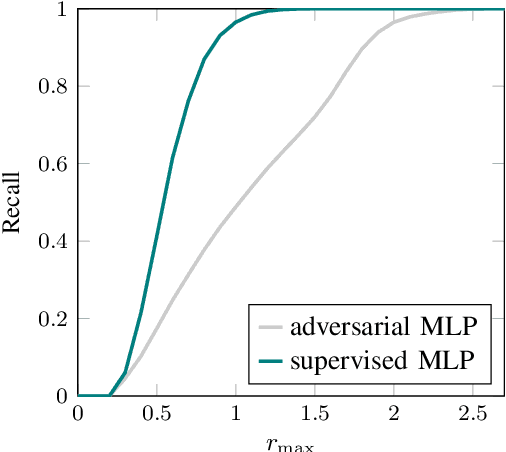
Neural networks are often used to process information from image-based sensors to produce control actions. While they are effective for this task, the complex nature of neural networks makes their output difficult to verify and predict, limiting their use in safety-critical systems. For this reason, recent work has focused on combining techniques in formal methods and reachability analysis to obtain guarantees on the closed-loop performance of neural network controllers. However, these techniques do not scale to the high-dimensional and complicated input space of image-based neural network controllers. In this work, we propose a method to address these challenges by training a generative adversarial network (GAN) to map states to plausible input images. By concatenating the generator network with the control network, we obtain a network with a low-dimensional input space. This insight allows us to use existing closed-loop verification tools to obtain formal guarantees on the performance of image-based controllers. We apply our approach to provide safety guarantees for an image-based neural network controller for an autonomous aircraft taxi problem. We guarantee that the controller will keep the aircraft on the runway and guide the aircraft towards the center of the runway. The guarantees we provide are with respect to the set of input images modeled by our generator network, so we provide a recall metric to evaluate how well the generator captures the space of plausible images.
Combining Pre-trained Word Embeddings and Linguistic Features for Sequential Metaphor Identification
Apr 07, 2021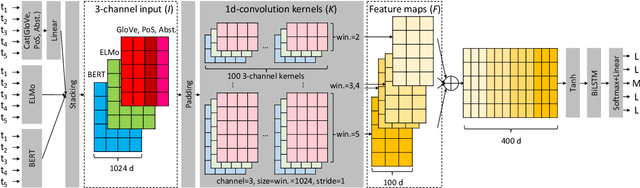
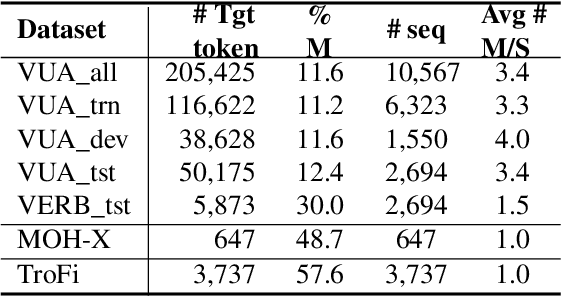
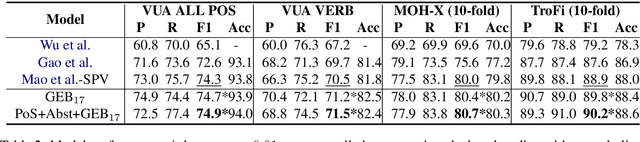
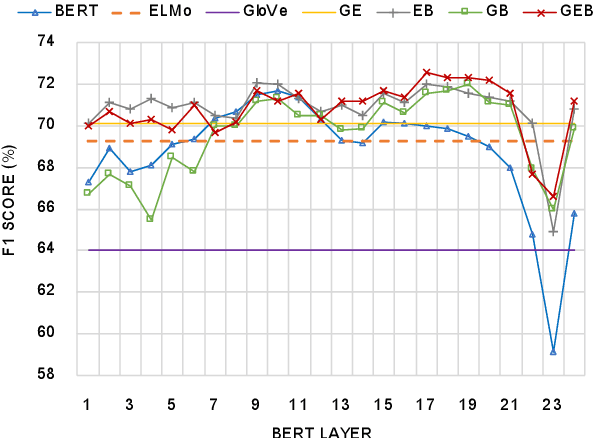
We tackle the problem of identifying metaphors in text, treated as a sequence tagging task. The pre-trained word embeddings GloVe, ELMo and BERT have individually shown good performance on sequential metaphor identification. These embeddings are generated by different models, training targets and corpora, thus encoding different semantic and syntactic information. We show that leveraging GloVe, ELMo and feature-based BERT based on a multi-channel CNN and a Bidirectional LSTM model can significantly outperform any single word embedding method and the combination of the two embeddings. Incorporating linguistic features into our model can further improve model performance, yielding state-of-the-art performance on three public metaphor datasets. We also provide in-depth analysis on the effectiveness of leveraging multiple word embeddings, including analysing the spatial distribution of different embedding methods for metaphors and literals, and showing how well the embeddings complement each other in different genres and parts of speech.
Hand-Based Person Identification using Global and Part-Aware Deep Feature Representation Learning
Jan 19, 2021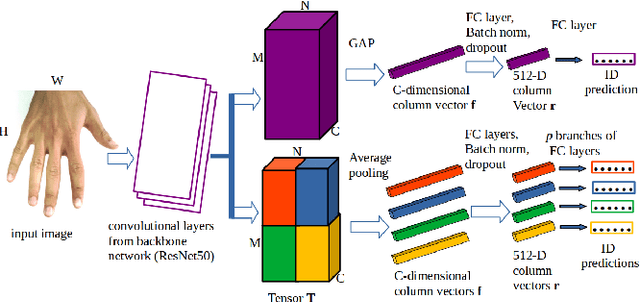

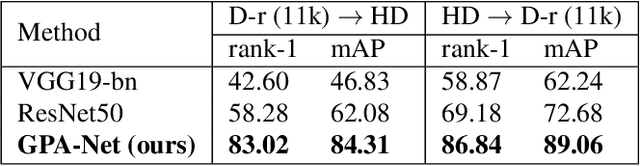

In cases of serious crime, including sexual abuse, often the only available information with demonstrated potential for identification is images of the hands. Since this evidence is captured in uncontrolled situations, it is difficult to analyse. As global approaches to feature comparison are limited in this case, it is important to extend to consider local information. In this work, we propose hand-based person identification by learning both global and local deep feature representation. Our proposed method, Global and Part-Aware Network (GPA-Net), creates global and local branches on the conv-layer for learning robust discriminative global and part-level features. For learning the local (part-level) features, we perform uniform partitioning on the conv-layer in both horizontal and vertical directions. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. We make extensive evaluations on two large multi-ethnic and publicly available hand datasets, demonstrating that our proposed method significantly outperforms competing approaches.
Local Memory Attention for Fast Video Semantic Segmentation
Jan 05, 2021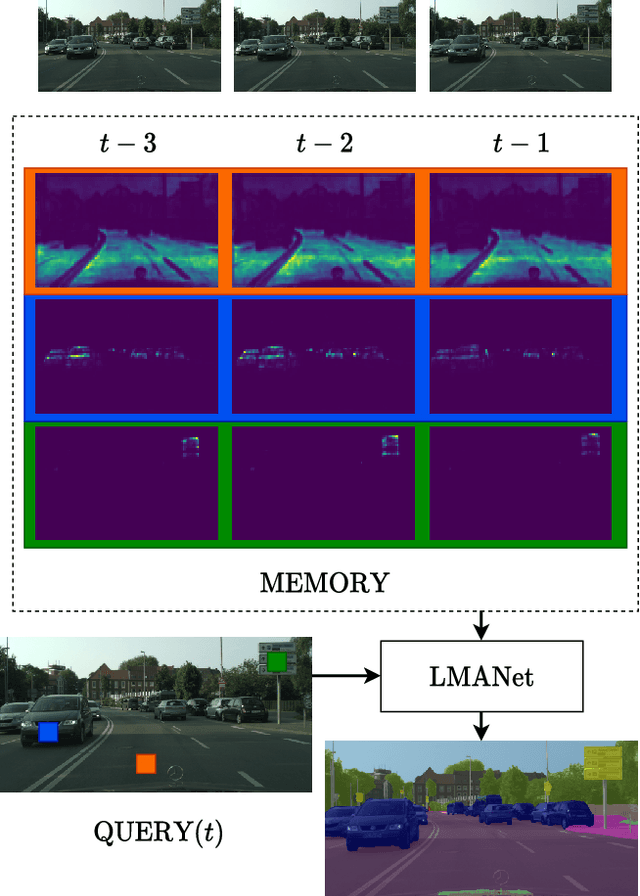
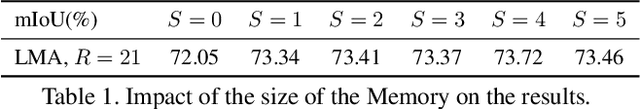
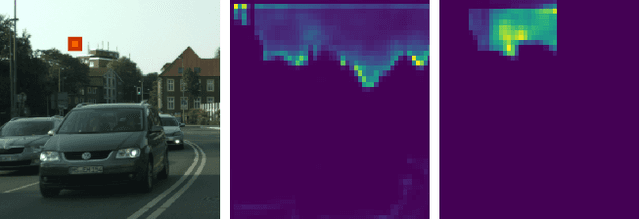

We propose a novel neural network module that transforms an existing single-frame semantic segmentation model into a video semantic segmentation pipeline. In contrast to prior works, we strive towards a simple and general module that can be integrated into virtually any single-frame architecture. Our approach aggregates a rich representation of the semantic information in past frames into a memory module. Information stored in the memory is then accessed through an attention mechanism. This provides temporal appearance cues from prior frames, which are then fused with an encoding of the current frame through a second attention-based module. The segmentation decoder processes the fused representation to predict the final semantic segmentation. We integrate our approach into two popular semantic segmentation networks: ERFNet and PSPNet. We observe an improvement in segmentation performance on Cityscapes by 1.7% and 2.1% in mIoU respectively, while increasing inference time of ERFNet by only 1.5ms.
V2F-Net: Explicit Decomposition of Occluded Pedestrian Detection
Apr 07, 2021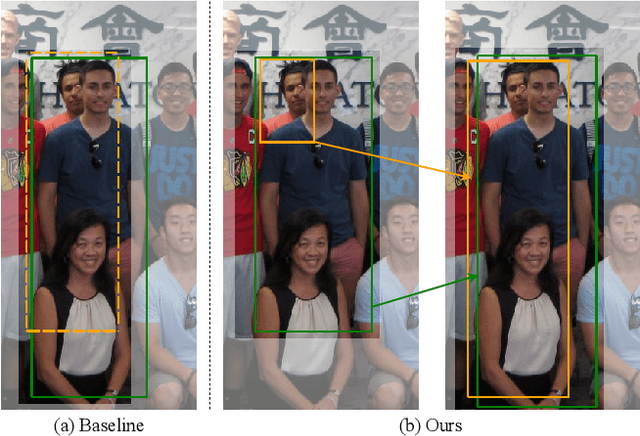
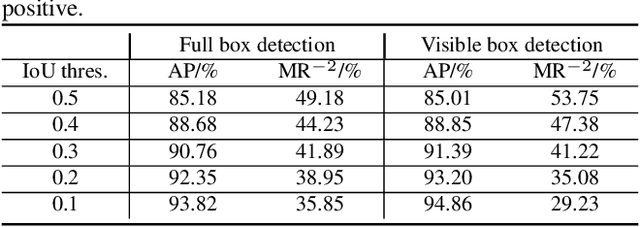
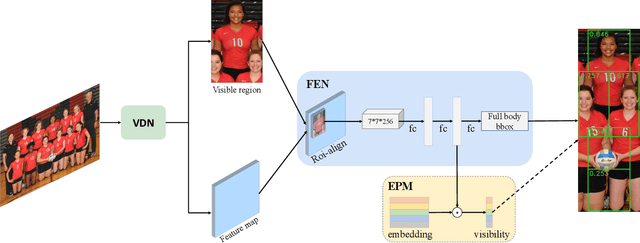
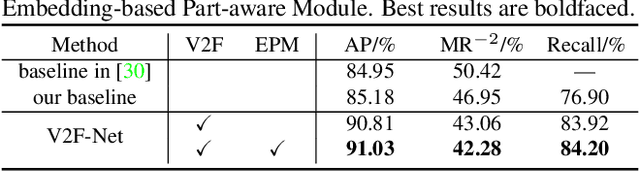
Occlusion is very challenging in pedestrian detection. In this paper, we propose a simple yet effective method named V2F-Net, which explicitly decomposes occluded pedestrian detection into visible region detection and full body estimation. V2F-Net consists of two sub-networks: Visible region Detection Network (VDN) and Full body Estimation Network (FEN). VDN tries to localize visible regions and FEN estimates full-body box on the basis of the visible box. Moreover, to further improve the estimation of full body, we propose a novel Embedding-based Part-aware Module (EPM). By supervising the visibility for each part, the network is encouraged to extract features with essential part information. We experimentally show the effectiveness of V2F-Net by conducting several experiments on two challenging datasets. V2F-Net achieves 5.85% AP gains on CrowdHuman and 2.24% MR-2 improvements on CityPersons compared to FPN baseline. Besides, the consistent gain on both one-stage and two-stage detector validates the generalizability of our method.
SAFEval: Summarization Asks for Fact-based Evaluation
Mar 23, 2021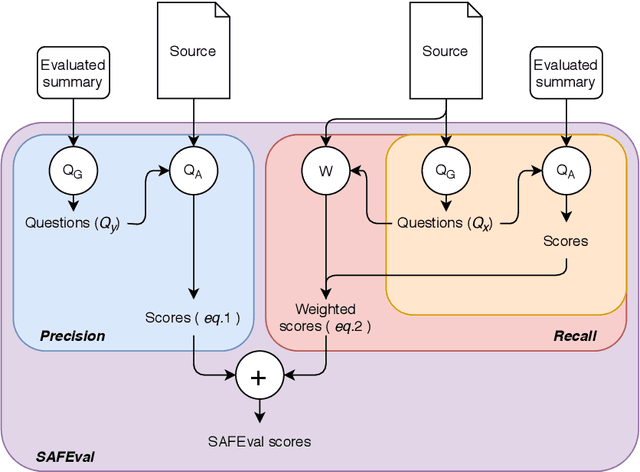
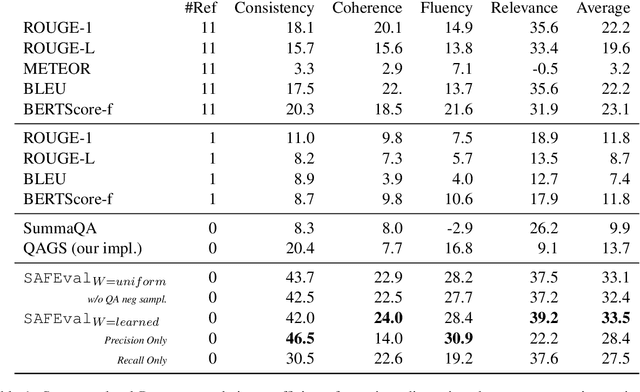

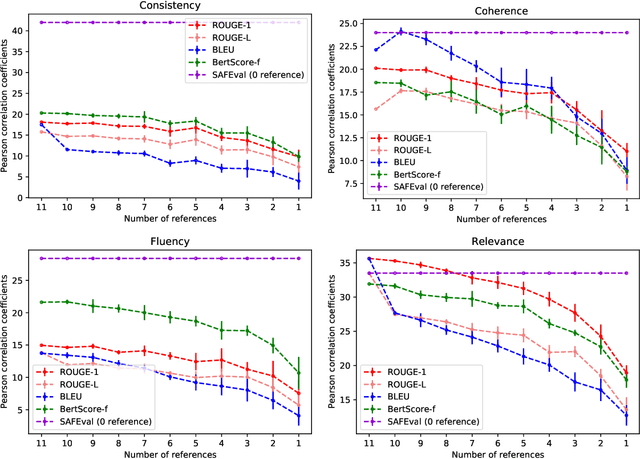
Summarization evaluation remains an open research problem: current metrics such as ROUGE are known to be limited and to correlate poorly with human judgments. To alleviate this issue, recent work has proposed evaluation metrics which rely on question answering models to assess whether a summary contains all the relevant information in its source document. Though promising, the proposed approaches have so far failed to correlate better than ROUGE with human judgments. In this paper, we extend previous approaches and propose a unified framework, named SAFEval. In contrast to established metrics such as ROUGE or BERTScore, SAFEval does not require any ground-truth reference. Nonetheless, SAFEval substantially improves the correlation with human judgments over four evaluation dimensions (consistency, coherence, fluency, and relevance), as shown in the extensive experiments we report.