 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMR-Net: Hierarchical Modular Routing for Cross-Domain Object Detection in Aerial Images
Apr 20, 2026Despite advances in object detection, aerial imagery remains a challenging domain, as models often fail to generalize across variations in spatial resolution, scene composition, and semantic label coverage. Differences in geographic context, sensor characteristics, and object distributions across datasets limit the capacity of conventional models to learn consistent and transferable representations. Shared methods trained on such data tend to impose a unified representation across fundamentally different domains, resulting in poor performance on region-specific content and less flexibility when dealing with novel object categories. To address this, we propose a novel modular learning framework that enables structured specialization in aerial detection. Our method introduces a hierarchical routing mechanism with two levels of modularity: a global expert assignment layer that uses latent geographic embeddings to route datasets to specialized processing modules, and a local scene decomposition mechanism that allocates image subregions to region-specific sub-modules. This allows our method to specialize across datasets and within complex scenes. Additionally, the framework contains a conditional expert module that uses external semantic information (e.g., category names or textual descriptions) to enable detection of novel object categories during inference, without the need for retraining or fine-tuning. By moving beyond monolithic representations, our method offers an adaptive framework for remote sensing object detection. Comprehensive evaluations on four datasets highlight improvements in multi-dataset generalization, regional specialization, and open-category detection.
Fake It Without Making It: Conditioned Face Generation for Accurate 3D Face Shape Estimation
Jul 25, 2023



Accurate 3D face shape estimation is an enabling technology with applications in healthcare, security, and creative industries, yet current state-of-the-art methods either rely on self-supervised training with 2D image data or supervised training with very limited 3D data. To bridge this gap, we present a novel approach which uses a conditioned stable diffusion model for face image generation, leveraging the abundance of 2D facial information to inform 3D space. By conditioning stable diffusion on depth maps sampled from a 3D Morphable Model (3DMM) of the human face, we generate diverse and shape-consistent images, forming the basis of SynthFace. We introduce this large-scale synthesised dataset of 250K photorealistic images and corresponding 3DMM parameters. We further propose ControlFace, a deep neural network, trained on SynthFace, which achieves competitive performance on the NoW benchmark, without requiring 3D supervision or manual 3D asset creation.
Text2Face: A Multi-Modal 3D Face Model
Mar 08, 2023



We present the first 3D morphable modelling approach, whereby 3D face shape can be directly and completely defined using a textual prompt. Building on work in multi-modal learning, we extend the FLAME head model to a common image-and-text latent space. This allows for direct 3D Morphable Model (3DMM) parameter generation and therefore shape manipulation from textual descriptions. Our method, Text2Face, has many applications; for example: generating police photofits where the input is already in natural language. It further enables multi-modal 3DMM image fitting to sketches and sculptures, as well as images.
Laplacian ICP for Progressive Registration of 3D Human Head Meshes
Feb 04, 2023



We present a progressive 3D registration framework that is a highly-efficient variant of classical non-rigid Iterative Closest Points (N-ICP). Since it uses the Laplace-Beltrami operator for deformation regularisation, we view the overall process as Laplacian ICP (L-ICP). This exploits a `small deformation per iteration' assumption and is progressively coarse-to-fine, employing an increasingly flexible deformation model, an increasing number of correspondence sets, and increasingly sophisticated correspondence estimation. Correspondence matching is only permitted within predefined vertex subsets derived from domain-specific feature extractors. Additionally, we present a new benchmark and a pair of evaluation metrics for 3D non-rigid registration, based on annotation transfer. We use this to evaluate our framework on a publicly-available dataset of 3D human head scans (Headspace). The method is robust and only requires a small fraction of the computation time compared to the most popular classical approach, yet has comparable registration performance.
* 7 pages, 6 figures
Accurate Gaze Estimation using an Active-gaze Morphable Model
Jan 30, 2023Rather than regressing gaze direction directly from images, we show that adding a 3D shape model can: i) improve gaze estimation accuracy, ii) perform well with lower resolution inputs and iii) provide a richer understanding of the eye-region and its constituent gaze system. Specifically, we use an `eyes and nose' 3D morphable model (3DMM) to capture the eye-region 3D facial geometry and appearance and we equip this with a geometric vergence model of gaze to give an `active-gaze 3DMM'. We show that our approach achieves state-of-the-art results on the Eyediap dataset and we present an ablation study. Our method can learn with only the ground truth gaze target point and the camera parameters, without access to the ground truth gaze origin points, thus widening the applicability of our approach compared to other methods.
The Effectiveness of Temporal Dependency in Deepfake Video Detection
May 13, 2022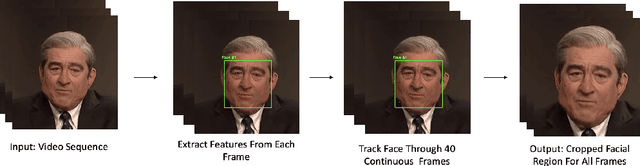
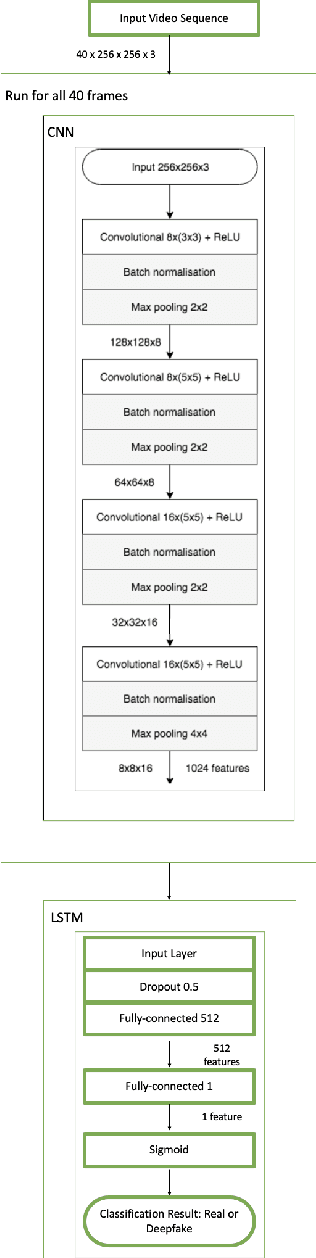
Deepfakes are a form of synthetic image generation used to generate fake videos of individuals for malicious purposes. The resulting videos may be used to spread misinformation, reduce trust in media, or as a form of blackmail. These threats necessitate automated methods of deepfake video detection. This paper investigates whether temporal information can improve the deepfake detection performance of deep learning models. To investigate this, we propose a framework that classifies new and existing approaches by their defining characteristics. These are the types of feature extraction: automatic or manual, and the temporal relationship between frames: dependent or independent. We apply this framework to investigate the effect of temporal dependency on a model's deepfake detection performance. We find that temporal dependency produces a statistically significant (p < 0.05) increase in performance in classifying real images for the model using automatic feature selection, demonstrating that spatio-temporal information can increase the performance of deepfake video detection models.
FatNet: A Feature-attentive Network for 3D Point Cloud Processing
Apr 07, 2021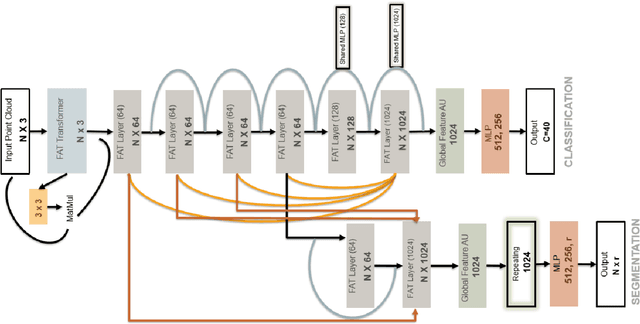
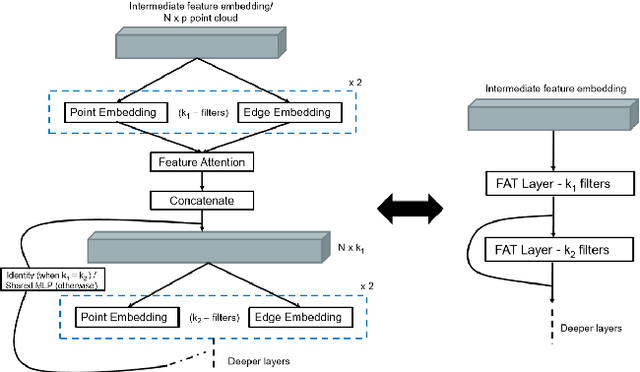
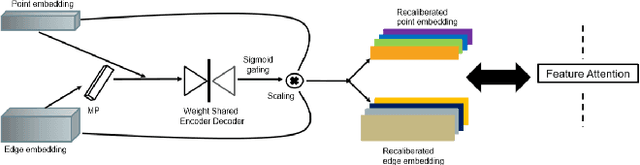
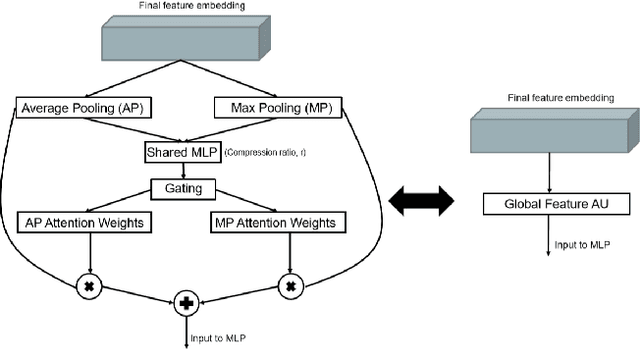
The application of deep learning to 3D point clouds is challenging due to its lack of order. Inspired by the point embeddings of PointNet and the edge embeddings of DGCNNs, we propose three improvements to the task of point cloud analysis. First, we introduce a novel feature-attentive neural network layer, a FAT layer, that combines both global point-based features and local edge-based features in order to generate better embeddings. Second, we find that applying the same attention mechanism across two different forms of feature map aggregation, max pooling and average pooling, gives better performance than either alone. Third, we observe that residual feature reuse in this setting propagates information more effectively between the layers, and makes the network easier to train. Our architecture achieves state-of-the-art results on the task of point cloud classification, as demonstrated on the ModelNet40 dataset, and an extremely competitive performance on the ShapeNet part segmentation challenge.
A Human Ear Reconstruction Autoencoder
Oct 07, 2020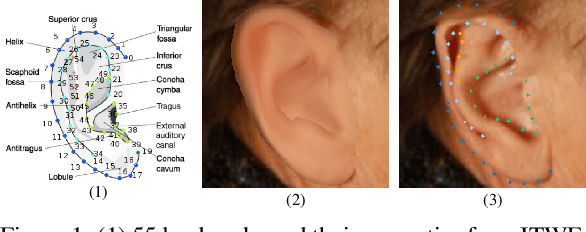

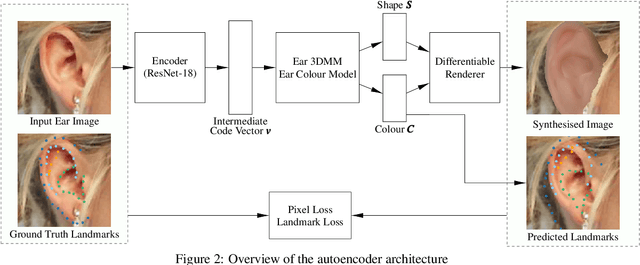
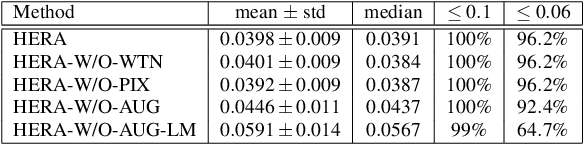
The ear, as an important part of the human head, has received much less attention compared to the human face in the area of computer vision. Inspired by previous work on monocular 3D face reconstruction using an autoencoder structure to achieve self-supervised learning, we aim to utilise such a framework to tackle the 3D ear reconstruction task, where more subtle and difficult curves and features are present on the 2D ear input images. Our Human Ear Reconstruction Autoencoder (HERA) system predicts 3D ear poses and shape parameters for 3D ear meshes, without any supervision to these parameters. To make our approach cover the variance for in-the-wild images, even grayscale images, we propose an in-the-wild ear colour model. The constructed end-to-end self-supervised model is then evaluated both with 2D landmark localisation performance and the appearance of the reconstructed 3D ears.
Divided We Stand: A Novel Residual Group Attention Mechanism for Medical Image Segmentation
Dec 04, 2019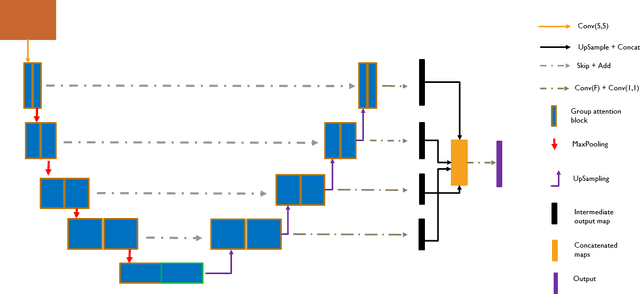
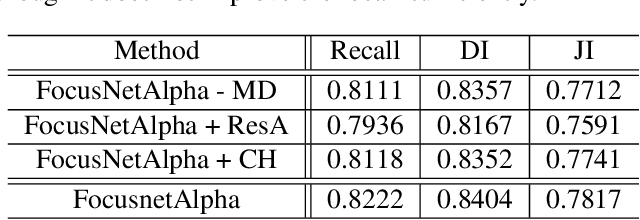
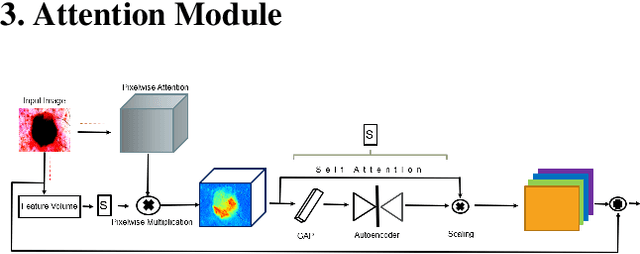

Given that convolutional neural networks extract features via learning convolution kernels, it makes sense to design better kernels which can in turn lead to better feature extraction. In this paper, we propose a new residual block for convolutional neural networks in the context of medical image segmentation. We combine attention mechanisms with group convolutions to create our group attention mechanism, which forms the fundamental building block of FocusNetAlpha - our convolutional autoencoder. We adapt a hybrid loss based on balanced cross entropy, tversky loss and the adaptive logarithmic loss to create a loss function that converges faster and more accurately to the minimum solution. On comparison with the different residual block variants, we observed a 5.6% increase in the IoU on the ISIC 2017 dataset over the basic residual block and a 1.3% increase over the resneXt group convolution block. Our results show that FocusNetAlpha achieves state-of-the-art results across all metrics for the ISIC 2018 melanoma segmentation, cell nuclei segmentation and the DRIVE retinal blood vessel segmentation datasets with fewer parameters and FLOPs. Our code and pre-trained models will be publicly available on GitHub to maximize reproducibility.
Towards a complete 3D morphable model of the human head
Nov 18, 2019

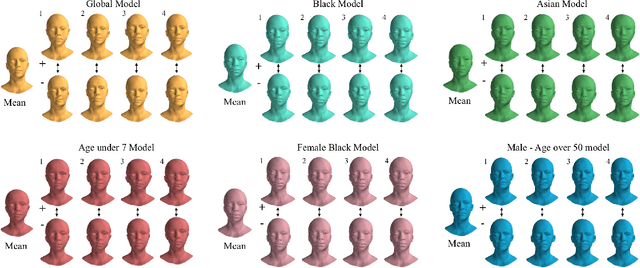
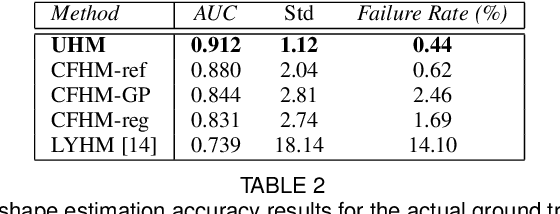
Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D shapes and textures of an object class. Here we present the most complete 3DMM of the human head to date that includes face, cranium, ears, eyes, teeth and tongue. To achieve this, we propose two methods for combining existing 3DMMs of different overlapping head parts: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Thus we build a new combined face-and-head shape model that blends the variability and facial detail of an existing face model (the LSFM) with the full head modelling capability of an existing head model (the LYHM). Then we construct and fuse a highly-detailed ear model to extend the variation of the ear shape. Eye and eye region models are incorporated into the head model, along with basic models of the teeth, tongue and inner mouth cavity. The new model achieves state-of-the-art performance. We use our model to reconstruct full head representations from single, unconstrained images allowing us to parameterize craniofacial shape and texture, along with the ear shape, eye gaze and eye color.