 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Change Matters: Medication Change Prediction with Recurrent Residual Networks
May 05, 2021
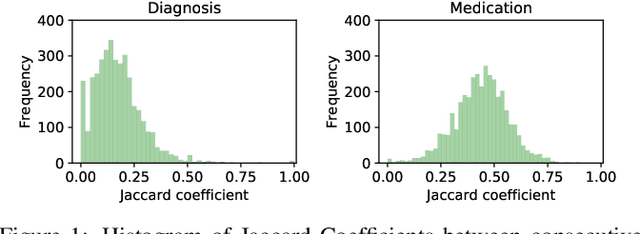
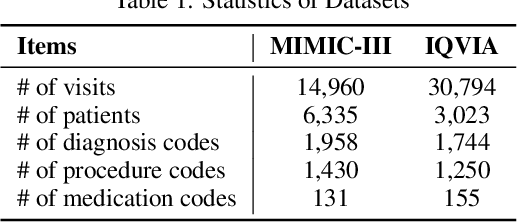
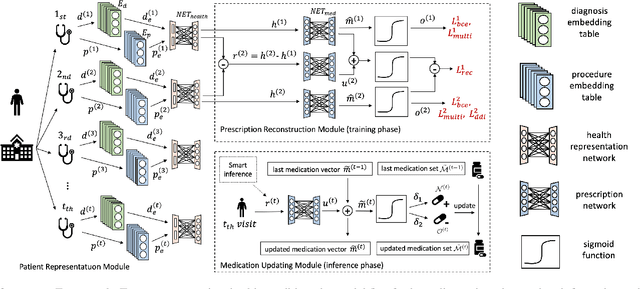
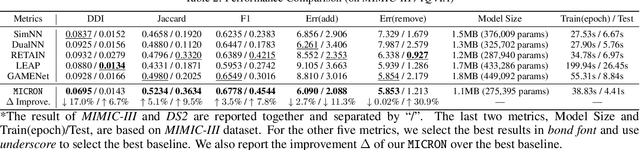
Deep learning is revolutionizing predictive healthcare, including recommending medications to patients with complex health conditions. Existing approaches focus on predicting all medications for the current visit, which often overlaps with medications from previous visits. A more clinically relevant task is to identify medication changes. In this paper, we propose a new recurrent residual network, named MICRON, for medication change prediction. MICRON takes the changes in patient health records as input and learns to update a hidden medication vector and the medication set recurrently with a reconstruction design. The medication vector is like the memory cell that encodes longitudinal information of medications. Unlike traditional methods that require the entire patient history for prediction, MICRON has a residual-based inference that allows for sequential updating based only on new patient features (e.g., new diagnoses in the recent visit) more efficiently. We evaluated MICRON on real inpatient and outpatient datasets. MICRON achieves 3.5% and 7.8% relative improvements over the best baseline in F1 score, respectively. MICRON also requires fewer parameters, which significantly reduces the training time to 38.3s per epoch with 1.5x speed-up.
FGF-GAN: A Lightweight Generative Adversarial Network for Pansharpening via Fast Guided Filter
Dec 31, 2020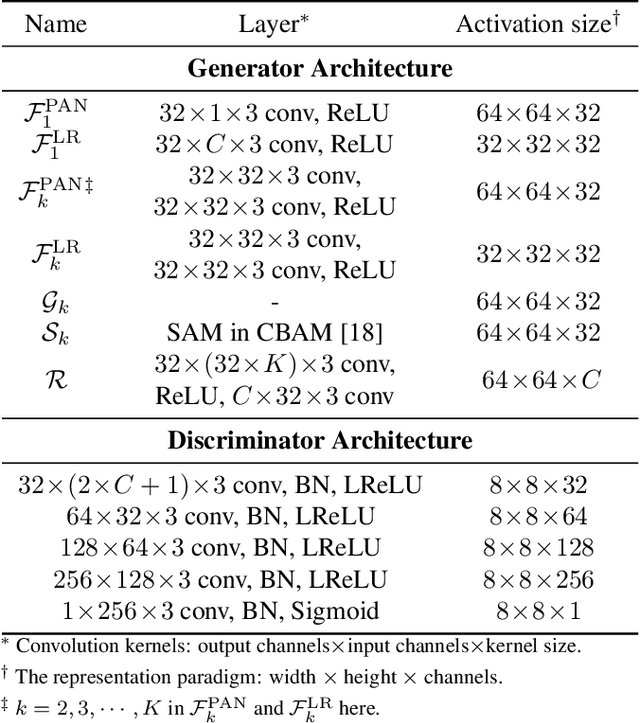
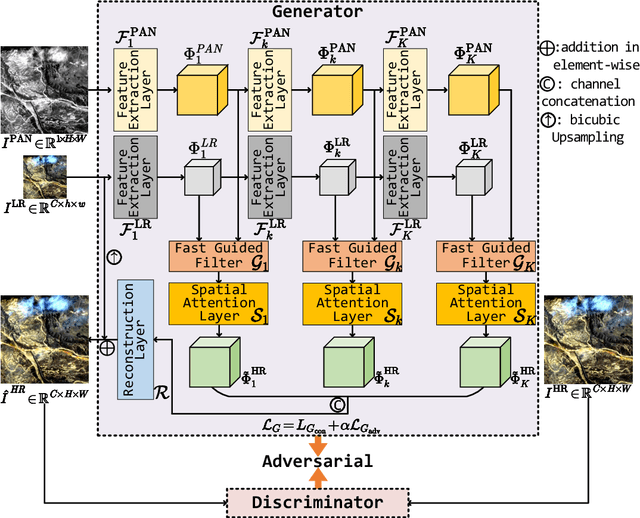

Pansharpening is a widely used image enhancement technique for remote sensing. Its principle is to fuse the input high-resolution single-channel panchromatic (PAN) image and low-resolution multi-spectral image and to obtain a high-resolution multi-spectral (HRMS) image. The existing deep learning pansharpening method has two shortcomings. First, features of two input images need to be concatenated along the channel dimension to reconstruct the HRMS image, which makes the importance of PAN images not prominent, and also leads to high computational cost. Second, the implicit information of features is difficult to extract through the manually designed loss function. To this end, we propose a generative adversarial network via the fast guided filter (FGF) for pansharpening. In generator, traditional channel concatenation is replaced by FGF to better retain the spatial information while reducing the number of parameters. Meanwhile, the fusion objects can be highlighted by the spatial attention module. In addition, the latent information of features can be preserved effectively through adversarial training. Numerous experiments illustrate that our network generates high-quality HRMS images that can surpass existing methods, and with fewer parameters.
Networked Federated Multi-Task Learning
May 26, 2021
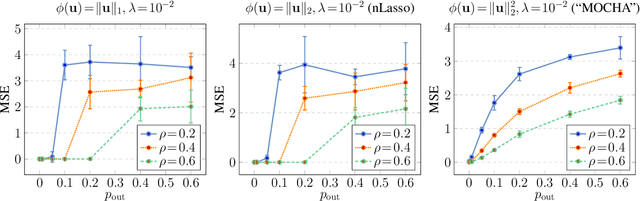
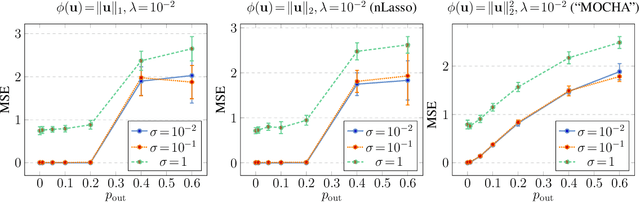
Many important application domains generate distributed collections of heterogeneous local datasets. These local datasets are often related via an intrinsic network structure that arises from domain-specific notions of similarity between local datasets. Different notions of similarity are induced by spatiotemporal proximity, statistical dependencies, or functional relations. We use this network structure to adaptively pool similar local datasets into nearly homogenous training sets for learning tailored models. Our main conceptual contribution is to formulate networked federated learning using the concept of generalized total variation (GTV) minimization as a regularizer. This formulation is highly flexible and can be combined with almost any parametric model including Lasso or deep neural networks. We unify and considerably extend some well-known approaches to federated multi-task learning. Our main algorithmic contribution is a novel federated learning algorithm that is well suited for distributed computing environments such as edge computing over wireless networks. This algorithm is robust against model misspecification and numerical errors arising from limited computational resources including processing time or wireless channel bandwidth. As our main technical contribution, we offer precise conditions on the local models as well on their network structure such that our algorithm learns nearly optimal local models. Our analysis reveals an interesting interplay between the (information-) geometry of local models and the (cluster-) geometry of their network.
Mitigating Media Bias through Neutral Article Generation
Apr 01, 2021

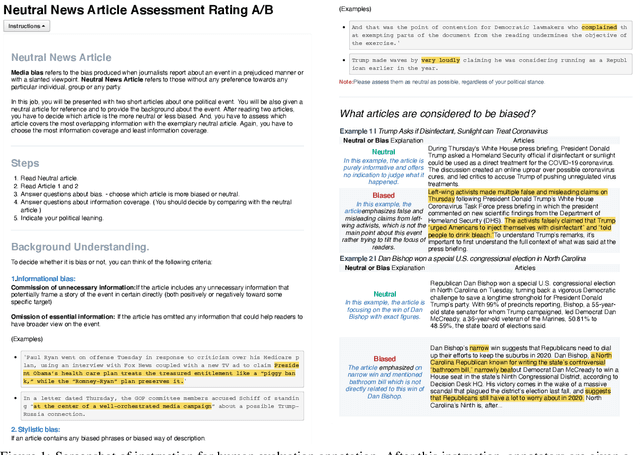

Media bias can lead to increased political polarization, and thus, the need for automatic mitigation methods is growing. Existing mitigation work displays articles from multiple news outlets to provide diverse news coverage, but without neutralizing the bias inherent in each of the displayed articles. Therefore, we propose a new task, a single neutralized article generation out of multiple biased articles, to facilitate more efficient access to balanced and unbiased information. In this paper, we compile a new dataset NeuWS, define an automatic evaluation metric, and provide baselines and multiple analyses to serve as a solid starting point for the proposed task. Lastly, we obtain a human evaluation to demonstrate the alignment between our metric and human judgment.
Smoothness-Aware Quantization Techniques
Jun 07, 2021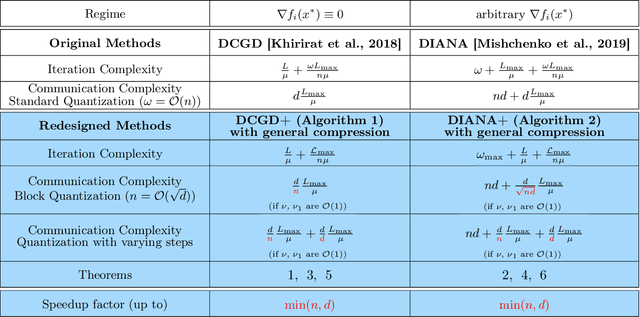
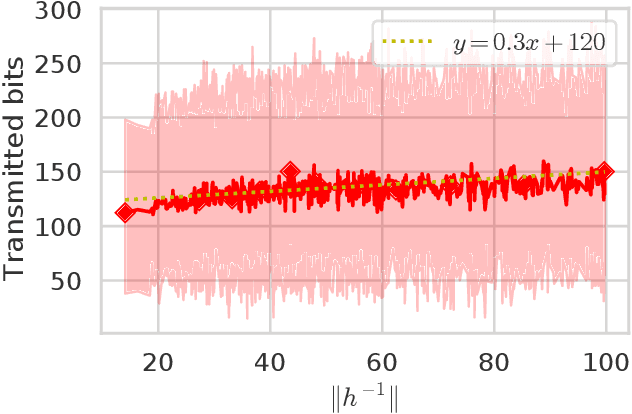
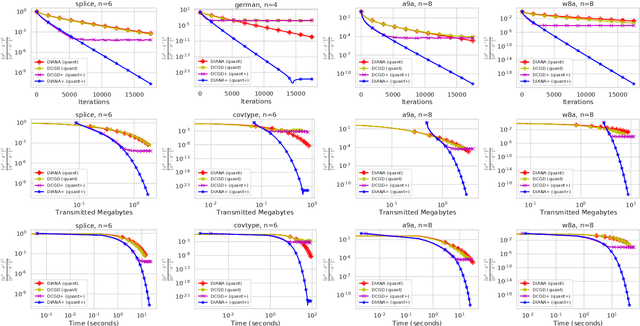
Distributed machine learning has become an indispensable tool for training large supervised machine learning models. To address the high communication costs of distributed training, which is further exacerbated by the fact that modern highly performing models are typically overparameterized, a large body of work has been devoted in recent years to the design of various compression strategies, such as sparsification and quantization, and optimization algorithms capable of using them. Recently, Safaryan et al (2021) pioneered a dramatically different compression design approach: they first use the local training data to form local {\em smoothness matrices}, and then propose to design a compressor capable of exploiting the smoothness information contained therein. While this novel approach leads to substantial savings in communication, it is limited to sparsification as it crucially depends on the linearity of the compression operator. In this work, we resolve this problem by extending their smoothness-aware compression strategy to arbitrary unbiased compression operators, which also includes sparsification. Specializing our results to quantization, we observe significant savings in communication complexity compared to standard quantization. In particular, we show theoretically that block quantization with $n$ blocks outperforms single block quantization, leading to a reduction in communication complexity by an $\mathcal{O}(n)$ factor, where $n$ is the number of nodes in the distributed system. Finally, we provide extensive numerical evidence that our smoothness-aware quantization strategies outperform existing quantization schemes as well the aforementioned smoothness-aware sparsification strategies with respect to all relevant success measures: the number of iterations, the total amount of bits communicated, and wall-clock time.
Task-driven Semantic Coding via Reinforcement Learning
Jun 07, 2021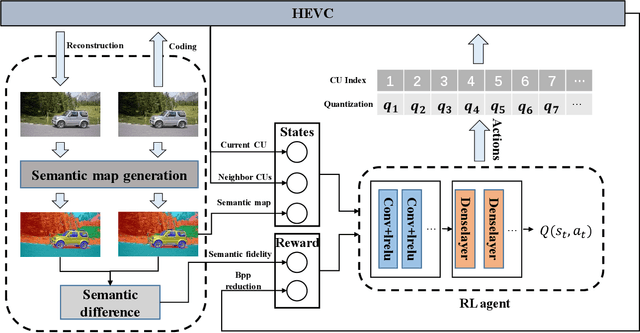
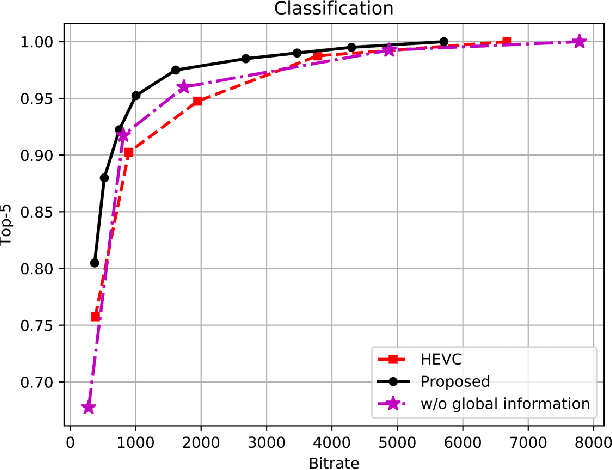
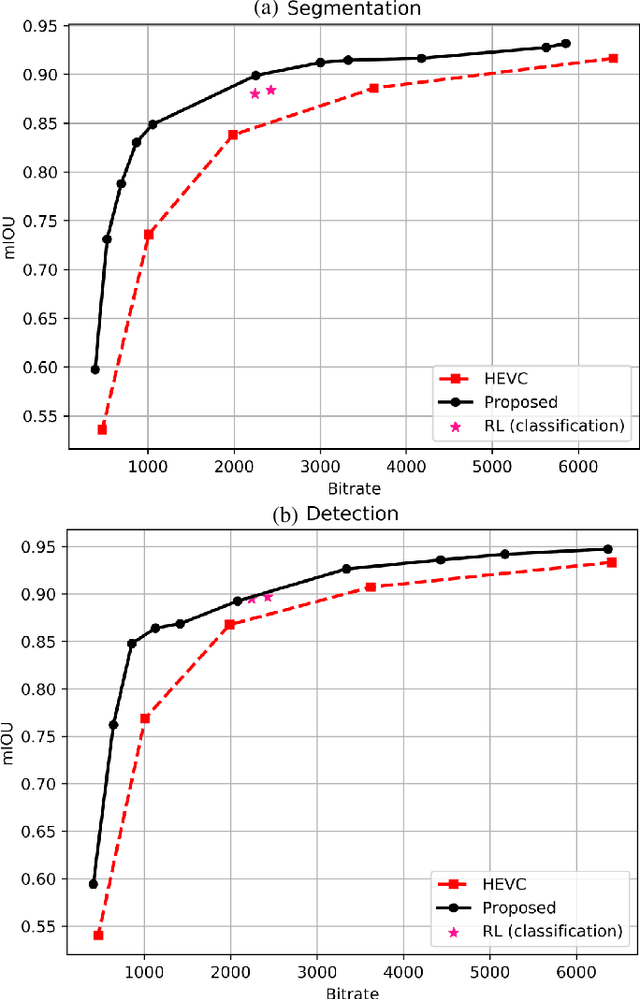
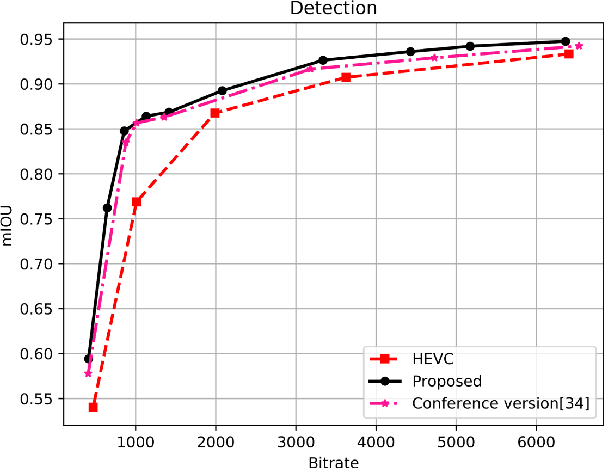
Task-driven semantic video/image coding has drawn considerable attention with the development of intelligent media applications, such as license plate detection, face detection, and medical diagnosis, which focuses on maintaining the semantic information of videos/images. Deep neural network (DNN)-based codecs have been studied for this purpose due to their inherent end-to-end optimization mechanism. However, the traditional hybrid coding framework cannot be optimized in an end-to-end manner, which makes task-driven semantic fidelity metric unable to be automatically integrated into the rate-distortion optimization process. Therefore, it is still attractive and challenging to implement task-driven semantic coding with the traditional hybrid coding framework, which should still be widely used in practical industry for a long time. To solve this challenge, we design semantic maps for different tasks to extract the pixelwise semantic fidelity for videos/images. Instead of directly integrating the semantic fidelity metric into traditional hybrid coding framework, we implement task-driven semantic coding by implementing semantic bit allocation based on reinforcement learning (RL). We formulate the semantic bit allocation problem as a Markov decision process (MDP) and utilize one RL agent to automatically determine the quantization parameters (QPs) for different coding units (CUs) according to the task-driven semantic fidelity metric. Extensive experiments on different tasks, such as classification, detection and segmentation, have demonstrated the superior performance of our approach by achieving an average bitrate saving of 34.39% to 52.62% over the High Efficiency Video Coding (H.265/HEVC) anchor under equivalent task-related semantic fidelity.
Some Pragmatic Prevention's Guidelines regarding SARS-CoV-2 and COVID-19 in Latin-America inspired by mixed Machine Learning Techniques and Artificial Mathematical Intelligence. Case Study: Colombia
May 12, 2021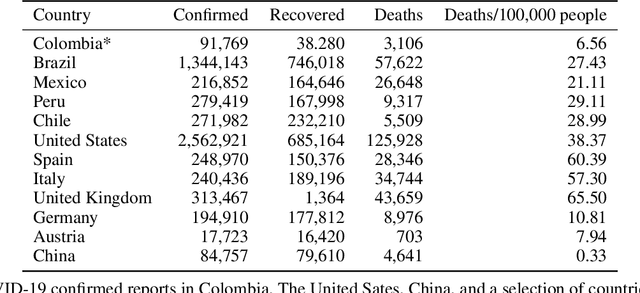
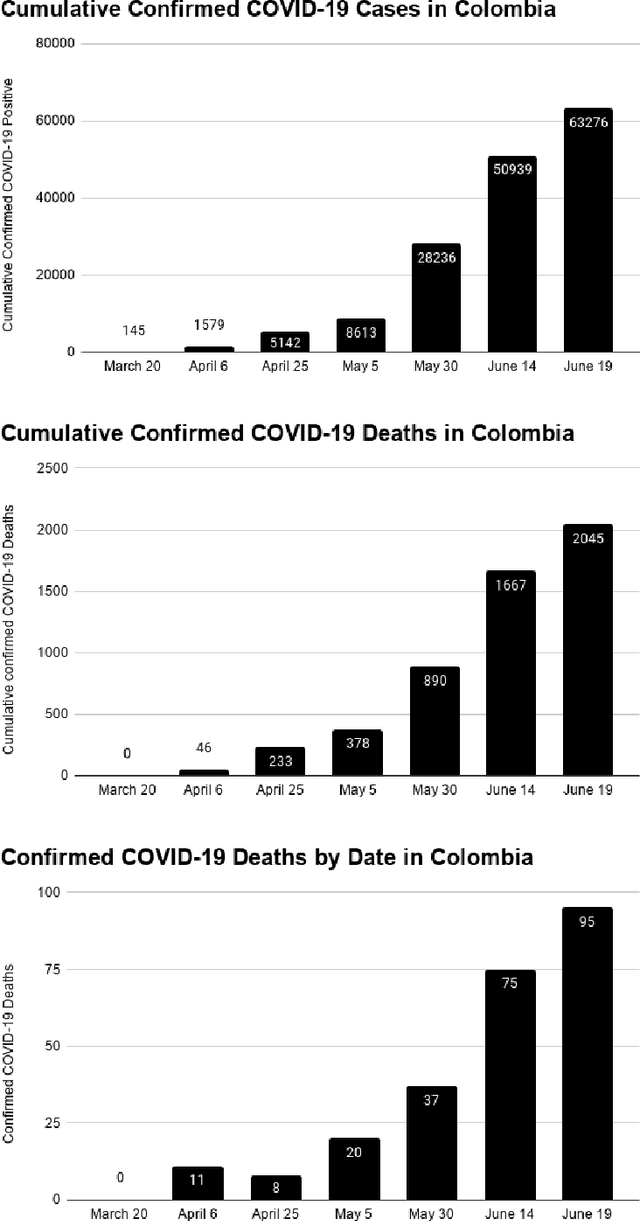


We use an enhanced methodology combining specific forms of AI techniques, opinion mining and artificial mathematical intelligence (AMI), with public data on the spread of the coronavirus SARS-CoV-2 and the incidence of COVID-19 disease in Colombia during the first three months since the first reported positive case. The results obtained, together with conceptual tools coming from the global taxonomy of fundamental cognitive mechanisms emerging in AMI and with suitable contextual information from Colombian public health and mainstream social media, allowed us to stating specific preventive guidelines for a better restructuring of initial safe and stable life conditions in Colombia, and in an extended manner in similar Latin American Countries. More specifically, we describe three major guidelines: 1) regular creative visualization and effective planning, 2) the continuous use of constructive linguistic frameworks, and 3) frequent and moderate use of kinesthetic routines. They should be understood as effective tools from a cognitive and behavioural perspective, rather than from a biological one. Even more, the first two guidelines should be acknowledged in integral cooperation with the third one regarding the global effect of COVID-19 in human beings as a whole, this includes the mind and body.
Streaming computation of optimal weak transport barycenters
Feb 26, 2021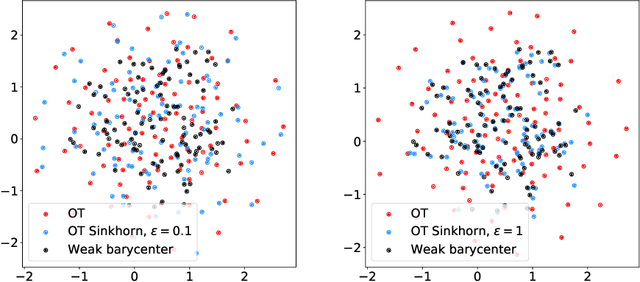
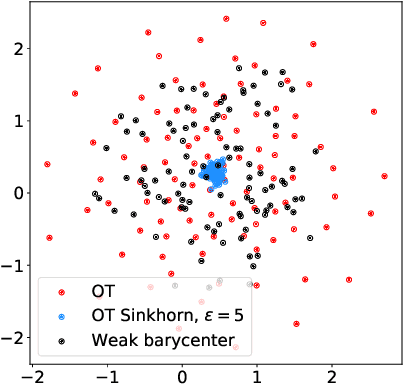
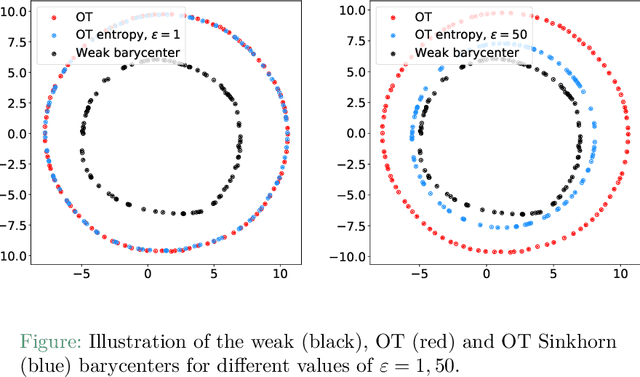
We introduce the weak barycenter of a family of probability distributions, based on the recently developed notion of optimal weak transport of measures arXiv:1412.7480(v4). We provide a theoretical analysis of the weak barycenter and its relationship to the classic Wasserstein barycenter, and discuss its meaning in the light of convex ordering between probability measures. In particular, we argue that, rather than averaging the information of the input distributions as done by the usual optimal transport barycenters, weak barycenters contain geometric information shared across all input distributions, which can be interpreted as a latent random variable affecting all the measures. We also provide iterative algorithms to compute a weak barycenter for either finite or infinite families of arbitrary measures (with finite moments of order 2), which are particularly well suited for the streaming setting, i.e., when measures arrive sequentially. In particular, our streaming computation of weak barycenters does not require to smooth empirical measures or to define a common grid for them, as some of the previous approaches to Wasserstin barycenters do. The concept of weak barycenter and our computation approaches are illustrated on synthetic examples, validated on 2D real-world data and compared to the classical Wasserstein barycenters.
Polarimetric Monocular Dense Mapping Using Relative Deep Depth Prior
Feb 10, 2021
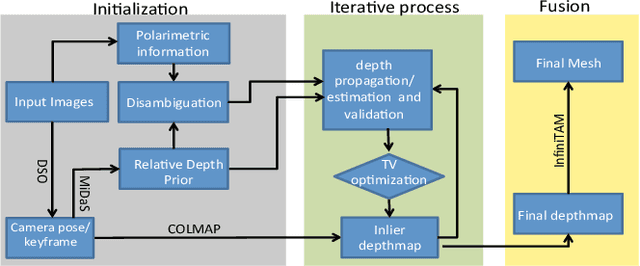


This paper is concerned with polarimetric dense map reconstruction based on a polarization camera with the help of relative depth information as a prior. In general, polarization imaging is able to reveal information about surface normal such as azimuth and zenith angles, which can support the development of solutions to the problem of dense reconstruction, especially in texture-poor regions. However, polarimetric shape cues are ambiguous due to two types of polarized reflection (specular/diffuse). Although methods have been proposed to address this issue, they either are offline and therefore not practical in robotics applications, or use incomplete polarimetric cues, leading to sub-optimal performance. In this paper, we propose an online reconstruction method that uses full polarimetric cues available from the polarization camera. With our online method, we can propagate sparse depth values both along and perpendicular to iso-depth contours. Through comprehensive experiments on challenging image sequences, we demonstrate that our method is able to significantly improve the accuracy of the depthmap as well as increase its density, specially in regions of poor texture.
ExcavatorCovid: Extracting Events and Relations from Text Corpora for Temporal and Causal Analysis for COVID-19
May 05, 2021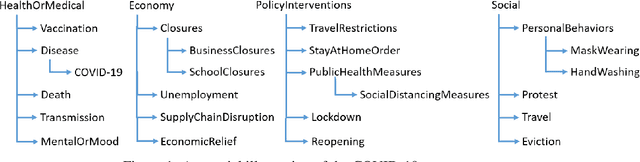
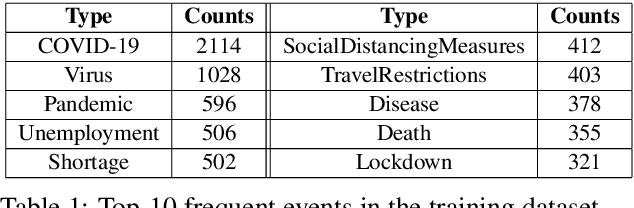
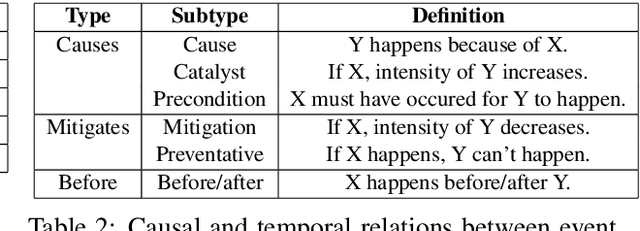
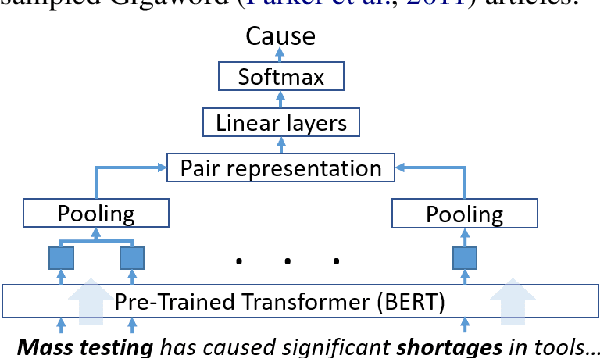
Timely responses from policy makers to mitigate the impact of the COVID-19 pandemic rely on a comprehensive grasp of events, their causes, and their impacts. These events are reported at such a speed and scale as to be overwhelming. In this paper, we present ExcavatorCovid, a machine reading system that ingests open-source text documents (e.g., news and scientific publications), extracts COVID19 related events and relations between them, and builds a Temporal and Causal Analysis Graph (TCAG). Excavator will help government agencies alleviate the information overload, understand likely downstream effects of political and economic decisions and events related to the pandemic, and respond in a timely manner to mitigate the impact of COVID-19. We expect the utility of Excavator to outlive the COVID-19 pandemic: analysts and decision makers will be empowered by Excavator to better understand and solve complex problems in the future. An interactive TCAG visualization is available at http://afrl402.bbn.com:5050/index.html. We also released a demonstration video at https://vimeo.com/528619007.