 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast constraint satisfaction problem and learning-based algorithm for solving Minesweeper
May 10, 2021
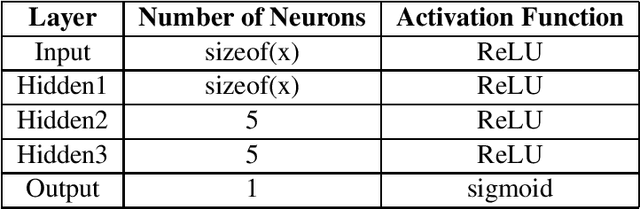
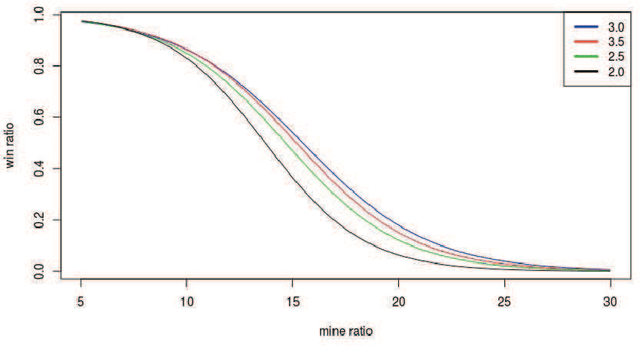
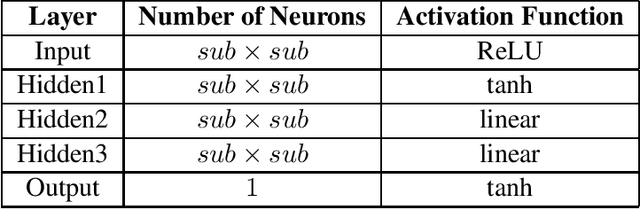
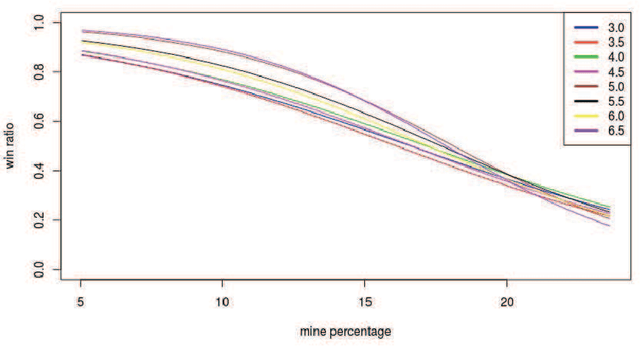
Minesweeper is a popular spatial-based decision-making game that works with incomplete information. As an exemplary NP-complete problem, it is a major area of research employing various artificial intelligence paradigms. The present work models this game as Constraint Satisfaction Problem (CSP) and Markov Decision Process (MDP). We propose a new method named as dependents from the independent set using deterministic solution search (DSScsp) for the faster enumeration of all solutions of a CSP based Minesweeper game and improve the results by introducing heuristics. Using MDP, we implement machine learning methods on these heuristics. We train the classification model on sparse data with results from CSP formulation. We also propose a new rewarding method for applying a modified deep Q-learning for better accuracy and versatile learning in the Minesweeper game. The overall results have been analyzed for different kinds of Minesweeper games and their accuracies have been recorded. Results from these experiments show that the proposed method of MDP based classification model and deep Q-learning overall is the best methods in terms of accuracy for games with given mine densities.
HIN-RNN: A Graph Representation Learning Neural Network for Fraudster Group Detection With No Handcrafted Features
May 25, 2021



Social reviews are indispensable resources for modern consumers' decision making. For financial gain, companies pay fraudsters preferably in groups to demote or promote products and services since consumers are more likely to be misled by a large number of similar reviews from groups. Recent approaches on fraudster group detection employed handcrafted features of group behaviors without considering the semantic relation between reviews from the reviewers in a group. In this paper, we propose the first neural approach, HIN-RNN, a Heterogeneous Information Network (HIN) Compatible RNN for fraudster group detection that requires no handcrafted features. HIN-RNN provides a unifying architecture for representation learning of each reviewer, with the initial vector as the sum of word embeddings of all review text written by the same reviewer, concatenated by the ratio of negative reviews. Given a co-review network representing reviewers who have reviewed the same items with the same ratings and the reviewers' vector representation, a collaboration matrix is acquired through HIN-RNN training. The proposed approach is confirmed to be effective with marked improvement over state-of-the-art approaches on both the Yelp (22% and 12% in terms of recall and F1-value, respectively) and Amazon (4% and 2% in terms of recall and F1-value, respectively) datasets.
QZNs: Quantum Z-numbers
Apr 12, 2021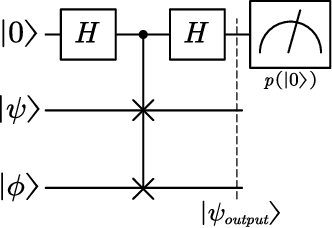
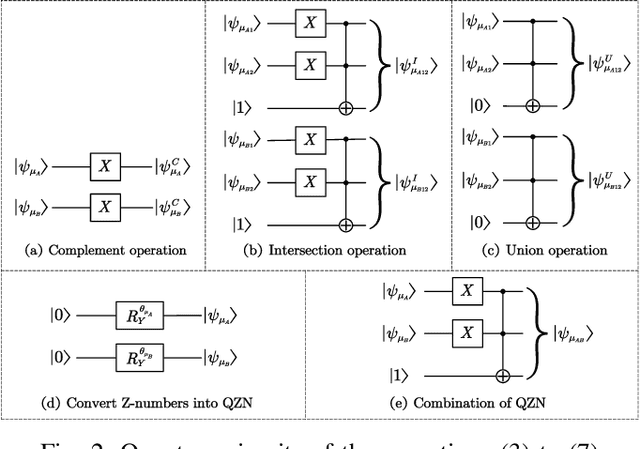
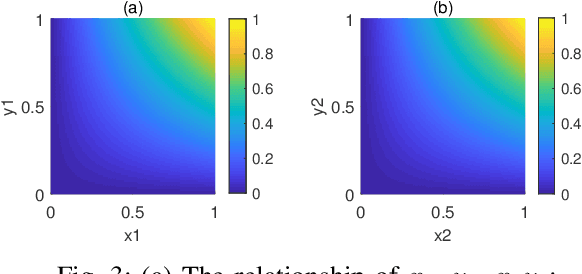
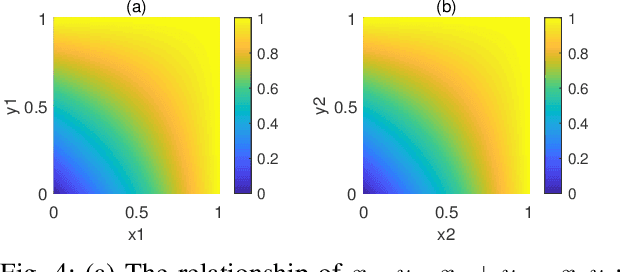
Because of the efficiency of modeling fuzziness and vagueness, Z-number plays an important role in real practice. However, Z-numbers, defined in the real number field, lack the ability to process the quantum information in quantum environment. It is reasonable to generalize Z-number into its quantum counterpart. In this paper, we propose quantum Z-numbers (QZNs), which are the quantum generalization of Z-numbers. In addition, seven basic quantum fuzzy operations of QZNs and their corresponding quantum circuits are presented and illustrated by numerical examples. Moreover, based on QZNs, a novel quantum multi-attributes decision making (MADM) algorithm is proposed and applied in medical diagnosis. The results show that, with the help of quantum computation, the proposed algorithm can make diagnoses correctly and efficiently.
Tracking Cells and their Lineages via Labeled Random Finite Sets
Apr 22, 2021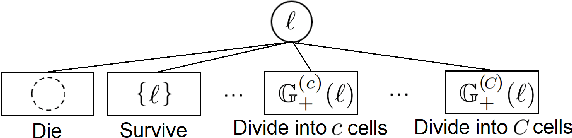
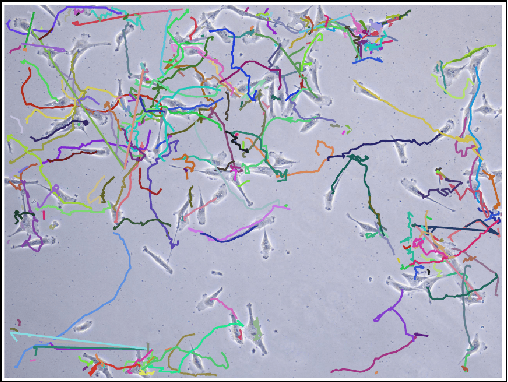
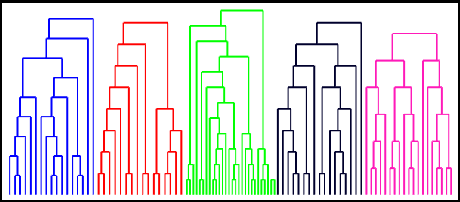
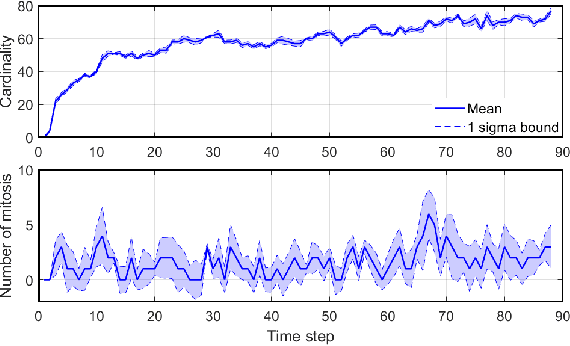
Determining the trajectories of cells and their lineages or ancestries in live-cell experiments are fundamental to the understanding of how cells behave and divide. This paper proposes novel online algorithms for jointly tracking and resolving lineages of an unknown and time-varying number of cells from time-lapse video data. Our approach involves modeling the cell ensemble as a labeled random finite set with labels representing cell identities and lineages. A spawning model is developed to take into account cell lineages and changes in cell appearance prior to division. We then derive analytic filters to propagate multi-object distributions that contain information on the current cell ensemble including their lineages. We also develop numerical implementations of the resulting multi-object filters. Experiments using simulation, synthetic cell migration video, and real time-lapse sequence, are presented to demonstrate the capability of the solutions.
Encoding Longer-term Contextual Multi-modal Information in a Predictive Coding Model
Apr 17, 2018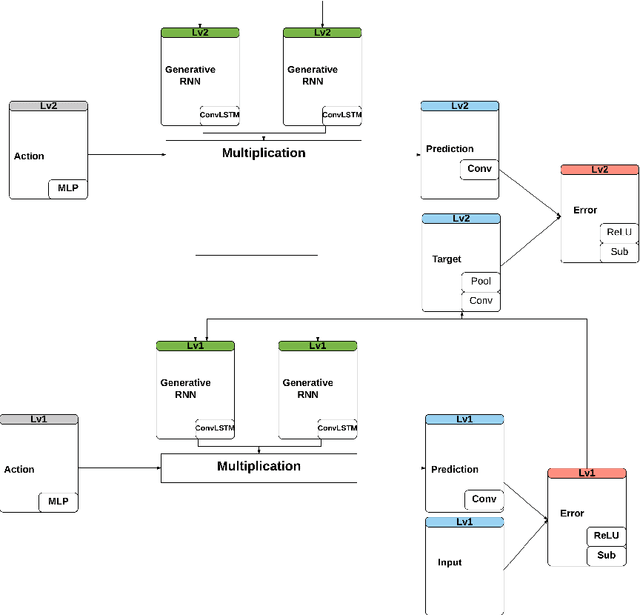
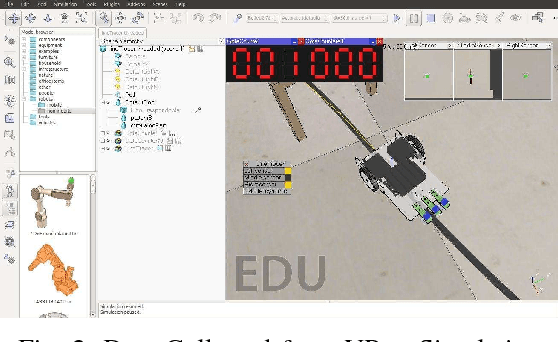


Studies suggest that within the hierarchical architecture, the topological higher level possibly represents a conscious category of the current sensory events with slower changing activities. They attempt to predict the activities on the lower level by relaying the predicted information. On the other hand, the incoming sensory information corrects such prediction of the events on the higher level by the novel or surprising signal. We propose a predictive hierarchical artificial neural network model that examines this hypothesis on neurorobotic platforms, based on the AFA-PredNet model. In this neural network model, there are different temporal scales of predictions exist on different levels of the hierarchical predictive coding, which are defined in the temporal parameters in the neurons. Also, both the fast and the slow-changing neural activities are modulated by the active motor activities. A neurorobotic experiment based on the architecture was also conducted based on the data collected from the VRep simulator.
Extractive Summarization of Call Transcripts
Mar 19, 2021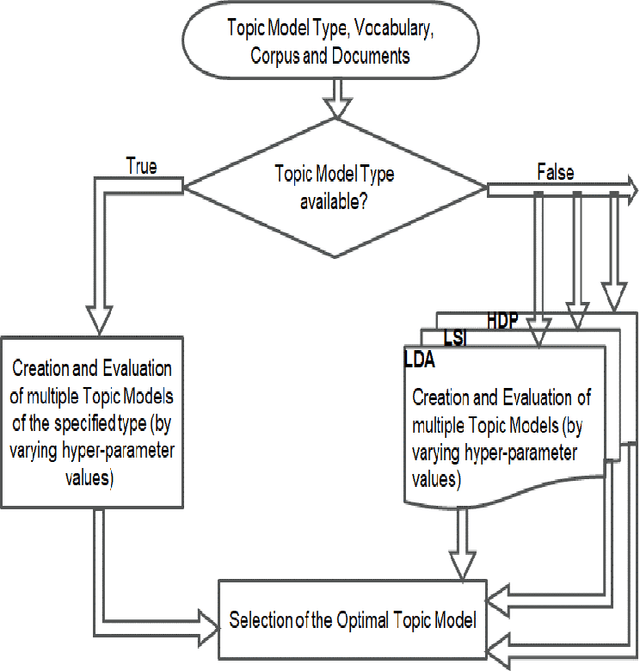
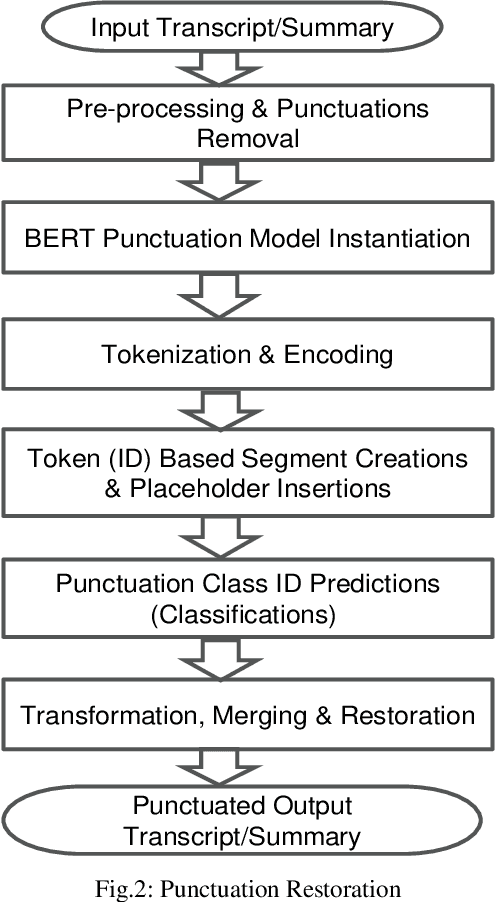
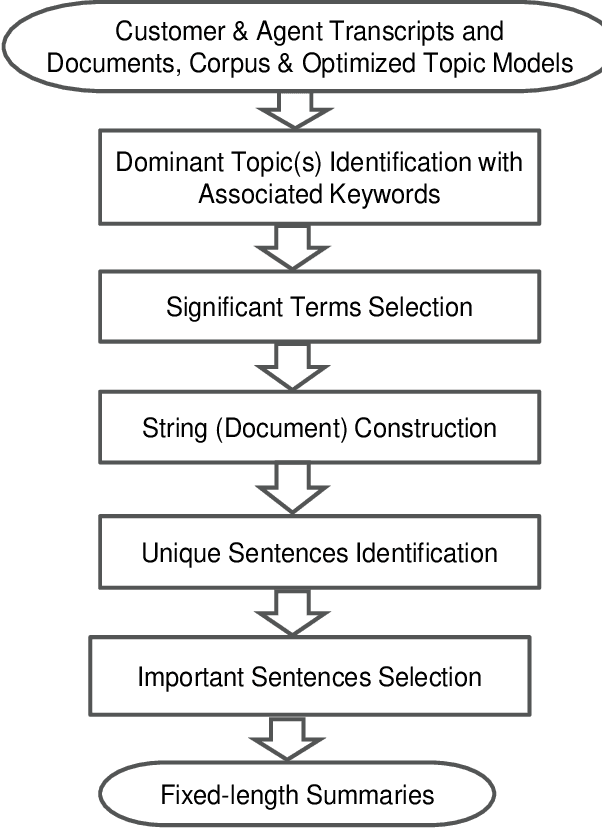
Text summarization is the process of extracting the most important information from the text and presenting it concisely in fewer sentences. Call transcript is a text that involves textual description of a phone conversation between a customer (caller) and agent(s) (customer representatives). This paper presents an indigenously developed method that combines topic modeling and sentence selection with punctuation restoration in condensing ill-punctuated or un-punctuated call transcripts to produce summaries that are more readable. Extensive testing, evaluation and comparisons have demonstrated the efficacy of this summarizer for call transcript summarization.
A toolbox for neuromorphic sensing in robotics
Mar 03, 2021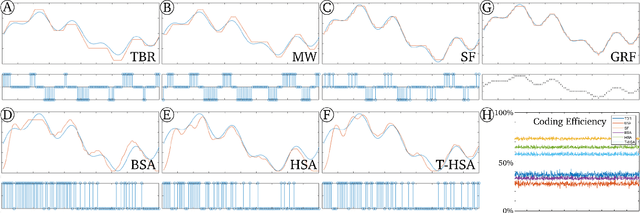
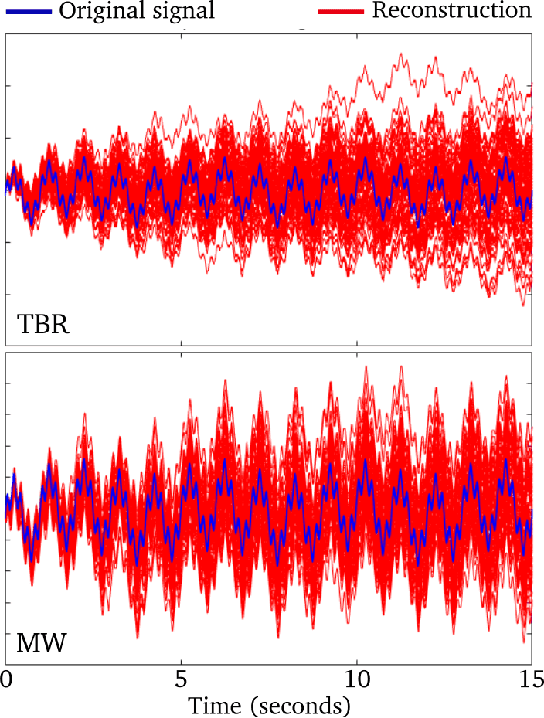
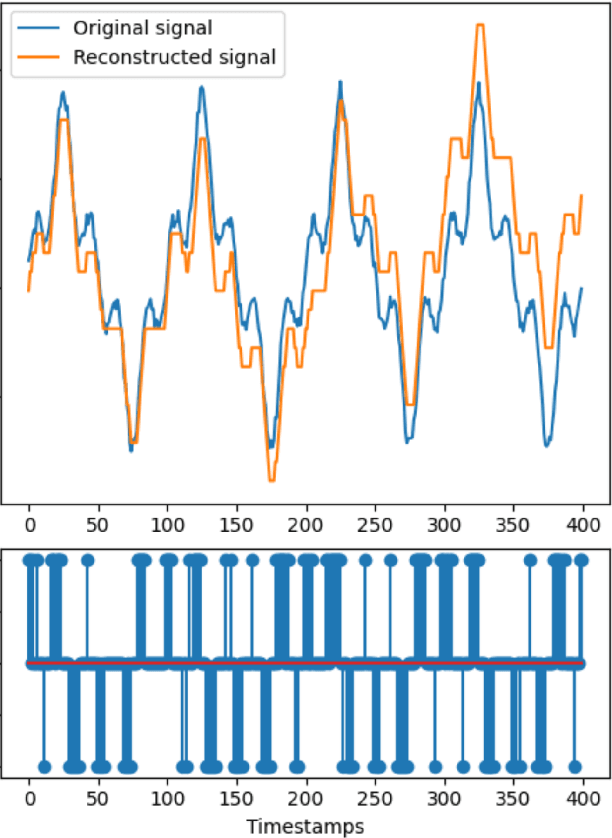
The third generation of artificial intelligence (AI) introduced by neuromorphic computing is revolutionizing the way robots and autonomous systems can sense the world, process the information, and interact with their environment. The promises of high flexibility, energy efficiency, and robustness of neuromorphic systems is widely supported by software tools for simulating spiking neural networks, and hardware integration (neuromorphic processors). Yet, while efforts have been made on neuromorphic vision (event-based cameras), it is worth noting that most of the sensors available for robotics remain inherently incompatible with neuromorphic computing, where information is encoded into spikes. To facilitate the use of traditional sensors, we need to convert the output signals into streams of spikes, i.e., a series of events (+1, -1) along with their corresponding timestamps. In this paper, we propose a review of the coding algorithms from a robotics perspective and further supported by a benchmark to assess their performance. We also introduce a ROS (Robot Operating System) toolbox to encode and decode input signals coming from any type of sensor available on a robot. This initiative is meant to stimulate and facilitate robotic integration of neuromorphic AI, with the opportunity to adapt traditional off-the-shelf sensors to spiking neural nets within one of the most powerful robotic tools, ROS.
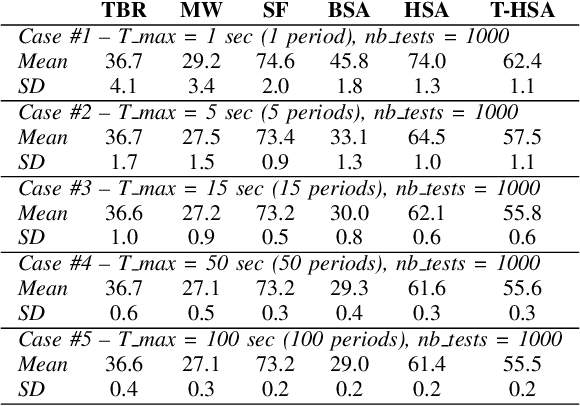
TI-Capsule: Capsule Network for Stock Exchange Prediction
Feb 15, 2021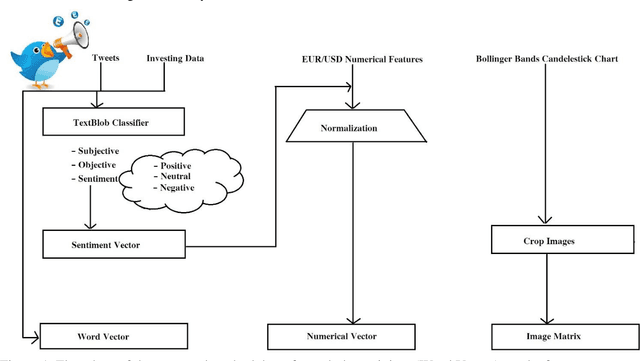
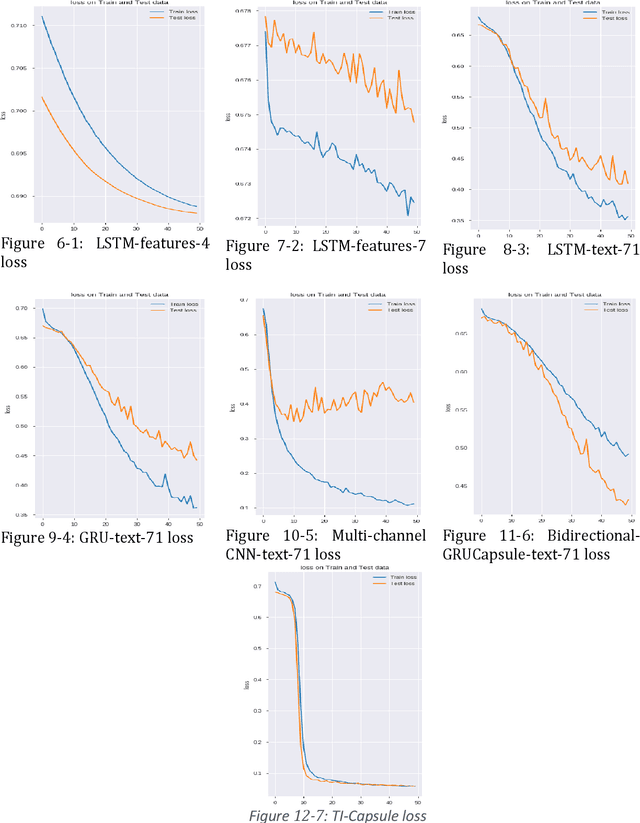
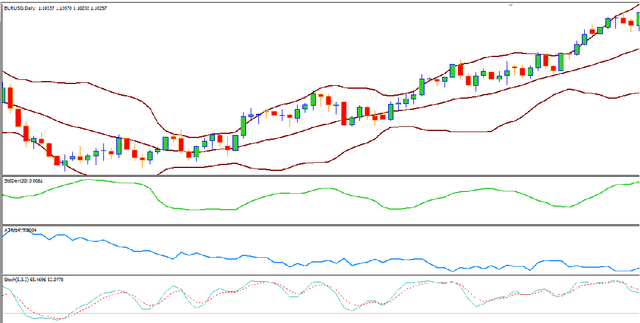
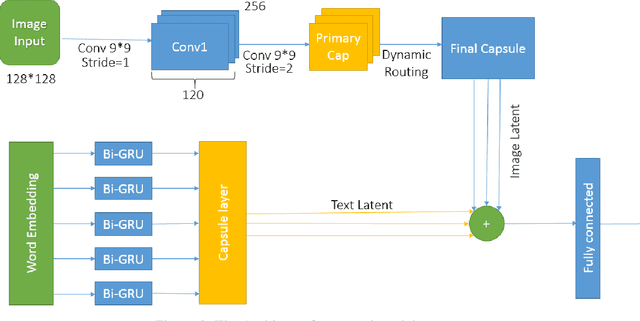
Today, the use of social networking data has attracted a lot of academic and commercial attention in predicting the stock market. In most studies in this area, the sentiment analysis of the content of user posts on social networks is used to predict market fluctuations. Predicting stock marketing is challenging because of the variables involved. In the short run, the market behaves like a voting machine, but in the long run, it acts like a weighing machine. The purpose of this study is to predict EUR/USD stock behavior using Capsule Network on finance texts and Candlestick images. One of the most important features of Capsule Network is the maintenance of features in a vector, which also takes into account the space between features. The proposed model, TI-Capsule (Text and Image information based Capsule Neural Network), is trained with both the text and image information simultaneously. Extensive experiments carried on the collected dataset have demonstrated the effectiveness of TI-Capsule in solving the stock exchange prediction problem with 91% accuracy.
A Gated Fusion Network for Dynamic Saliency Prediction
Feb 15, 2021
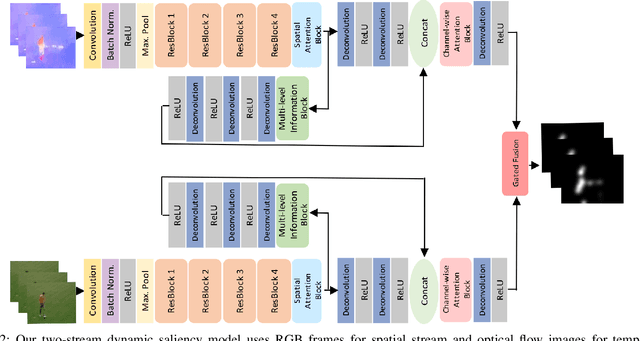
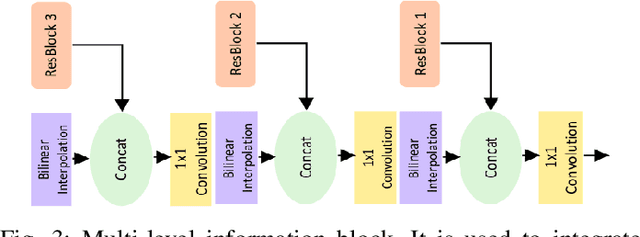
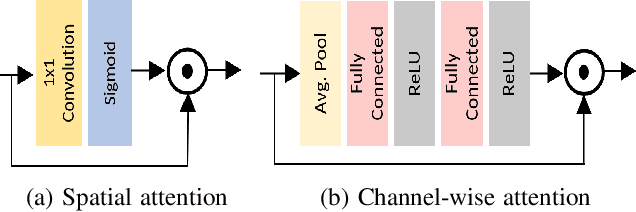
Predicting saliency in videos is a challenging problem due to complex modeling of interactions between spatial and temporal information, especially when ever-changing, dynamic nature of videos is considered. Recently, researchers have proposed large-scale datasets and models that take advantage of deep learning as a way to understand what's important for video saliency. These approaches, however, learn to combine spatial and temporal features in a static manner and do not adapt themselves much to the changes in the video content. In this paper, we introduce Gated Fusion Network for dynamic saliency (GFSalNet), the first deep saliency model capable of making predictions in a dynamic way via gated fusion mechanism. Moreover, our model also exploits spatial and channel-wise attention within a multi-scale architecture that further allows for highly accurate predictions. We evaluate the proposed approach on a number of datasets, and our experimental analysis demonstrates that it outperforms or is highly competitive with the state of the art. Importantly, we show that it has a good generalization ability, and moreover, exploits temporal information more effectively via its adaptive fusion scheme.
Self-attention Comparison Module for Boosting Performance on Retrieval-based Open-Domain Dialog Systems
Dec 21, 2020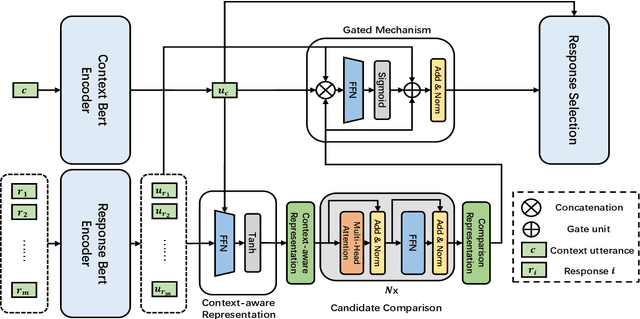
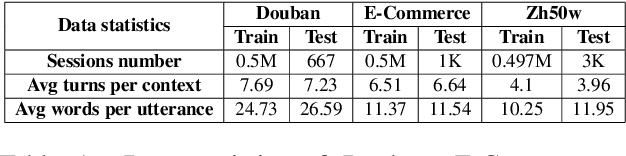
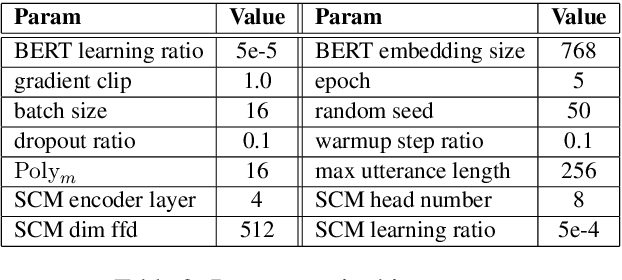

Since the pre-trained language models are widely used, retrieval-based open-domain dialog systems, have attracted considerable attention from researchers recently. Most of the previous works select a suitable response only according to the matching degree between the query and each individual candidate response. Although good performance has been achieved, these recent works ignore the comparison among the candidate responses, which could provide rich information for selecting the most appropriate response. Intuitively, better decisions could be made when the models can get access to the comparison information among all the candidate responses. In order to leverage the comparison information among the candidate responses, in this paper, we propose a novel and plug-in Self-attention Comparison Module for retrieval-based open-domain dialog systems, called SCM. Extensive experiment results demonstrate that our proposed self-attention comparison module effectively boosts the performance of the existing retrieval-based open-domain dialog systems. Besides, we have publicly released our source codes for future research.