 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gated Fusion Network for Dynamic Saliency Prediction
Feb 15, 2021
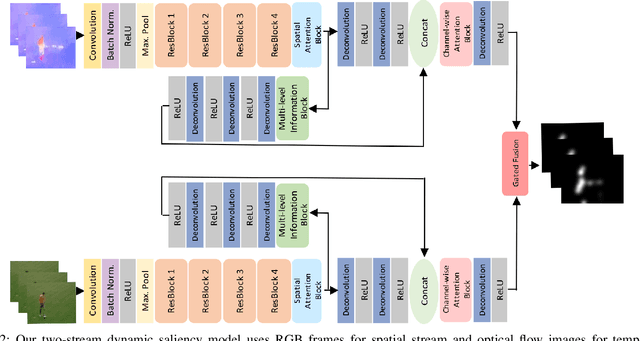
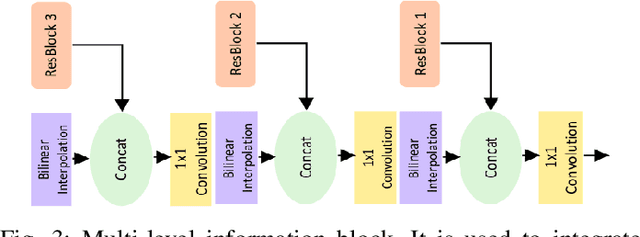
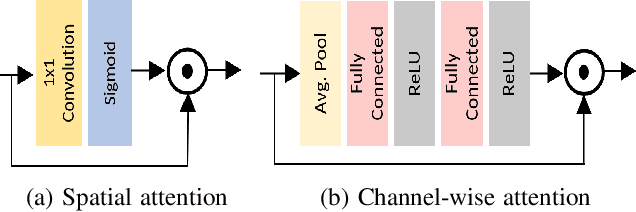
Predicting saliency in videos is a challenging problem due to complex modeling of interactions between spatial and temporal information, especially when ever-changing, dynamic nature of videos is considered. Recently, researchers have proposed large-scale datasets and models that take advantage of deep learning as a way to understand what's important for video saliency. These approaches, however, learn to combine spatial and temporal features in a static manner and do not adapt themselves much to the changes in the video content. In this paper, we introduce Gated Fusion Network for dynamic saliency (GFSalNet), the first deep saliency model capable of making predictions in a dynamic way via gated fusion mechanism. Moreover, our model also exploits spatial and channel-wise attention within a multi-scale architecture that further allows for highly accurate predictions. We evaluate the proposed approach on a number of datasets, and our experimental analysis demonstrates that it outperforms or is highly competitive with the state of the art. Importantly, we show that it has a good generalization ability, and moreover, exploits temporal information more effectively via its adaptive fusion scheme.
Spatio-Temporal Saliency Networks for Dynamic Saliency Prediction
Nov 15, 2017



Computational saliency models for still images have gained significant popularity in recent years. Saliency prediction from videos, on the other hand, has received relatively little interest from the community. Motivated by this, in this work, we study the use of deep learning for dynamic saliency prediction and propose the so-called spatio-temporal saliency networks. The key to our models is the architecture of two-stream networks where we investigate different fusion mechanisms to integrate spatial and temporal information. We evaluate our models on the DIEM and UCF-Sports datasets and present highly competitive results against the existing state-of-the-art models. We also carry out some experiments on a number of still images from the MIT300 dataset by exploiting the optical flow maps predicted from these images. Our results show that considering inherent motion information in this way can be helpful for static saliency estimation.