 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
InfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021
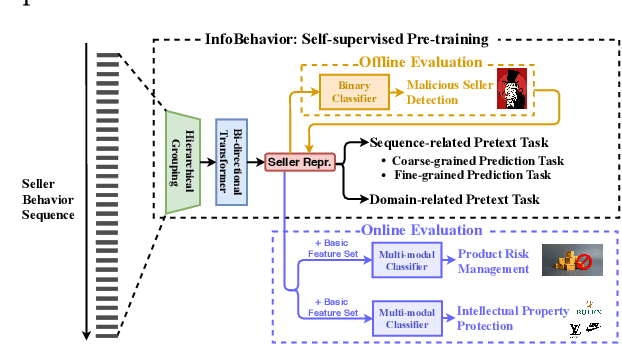
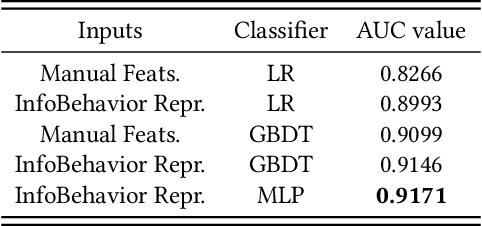
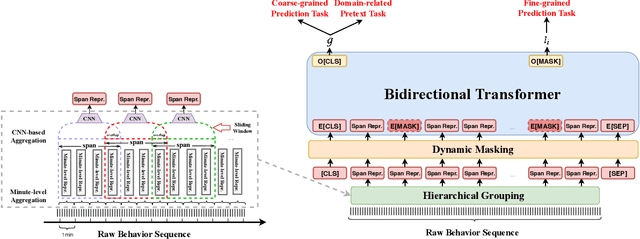
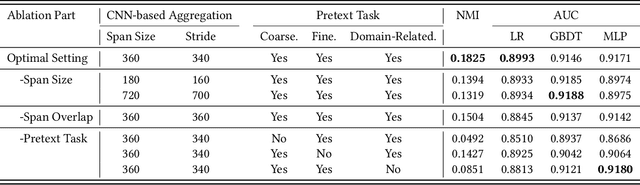
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.
Meta-Reinforcement Learning by Tracking Task Non-stationarity
May 18, 2021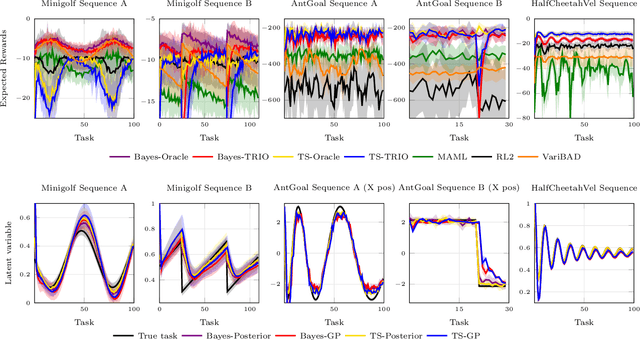
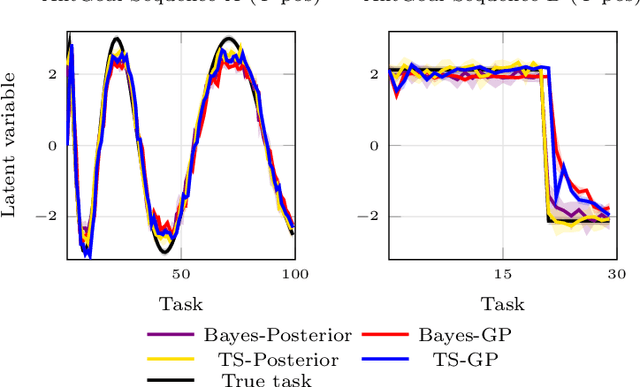
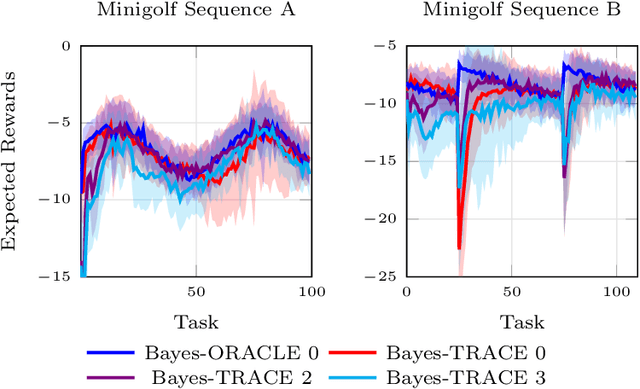
Many real-world domains are subject to a structured non-stationarity which affects the agent's goals and the environmental dynamics. Meta-reinforcement learning (RL) has been shown successful for training agents that quickly adapt to related tasks. However, most of the existing meta-RL algorithms for non-stationary domains either make strong assumptions on the task generation process or require sampling from it at training time. In this paper, we propose a novel algorithm (TRIO) that optimizes for the future by explicitly tracking the task evolution through time. At training time, TRIO learns a variational module to quickly identify latent parameters from experience samples. This module is learned jointly with an optimal exploration policy that takes task uncertainty into account. At test time, TRIO tracks the evolution of the latent parameters online, hence reducing the uncertainty over future tasks and obtaining fast adaptation through the meta-learned policy. Unlike most existing methods, TRIO does not assume Markovian task-evolution processes, it does not require information about the non-stationarity at training time, and it captures complex changes undergoing in the environment. We evaluate our algorithm on different simulated problems and show it outperforms competitive baselines.
ScanBank: A Benchmark Dataset for Figure Extraction from Scanned Electronic Theses and Dissertations
Jun 23, 2021
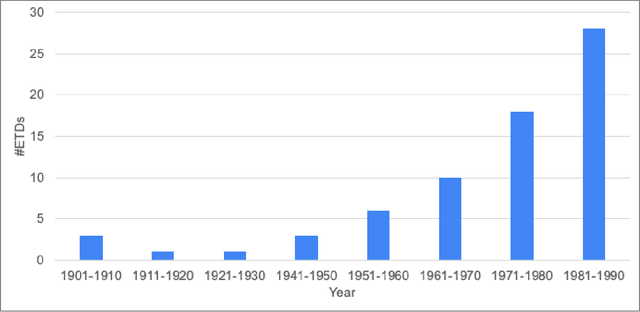

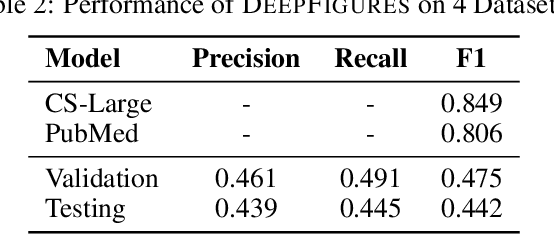
We focus on electronic theses and dissertations (ETDs), aiming to improve access and expand their utility, since more than 6 million are publicly available, and they constitute an important corpus to aid research and education across disciplines. The corpus is growing as new born-digital documents are included, and since millions of older theses and dissertations have been converted to digital form to be disseminated electronically in institutional repositories. In ETDs, as with other scholarly works, figures and tables can communicate a large amount of information in a concise way. Although methods have been proposed for extracting figures and tables from born-digital PDFs, they do not work well with scanned ETDs. Considering this problem, our assessment of state-of-the-art figure extraction systems is that the reason they do not function well on scanned PDFs is that they have only been trained on born-digital documents. To address this limitation, we present ScanBank, a new dataset containing 10 thousand scanned page images, manually labeled by humans as to the presence of the 3.3 thousand figures or tables found therein. We use this dataset to train a deep neural network model based on YOLOv5 to accurately extract figures and tables from scanned ETDs. We pose and answer important research questions aimed at finding better methods for figure extraction from scanned documents. One of those concerns the value for training, of data augmentation techniques applied to born-digital documents which are used to train models better suited for figure extraction from scanned documents. To the best of our knowledge, ScanBank is the first manually annotated dataset for figure and table extraction for scanned ETDs. A YOLOv5-based model, trained on ScanBank, outperforms existing comparable open-source and freely available baseline methods by a considerable margin.
Socially-Aware Self-Supervised Tri-Training for Recommendation
Jun 07, 2021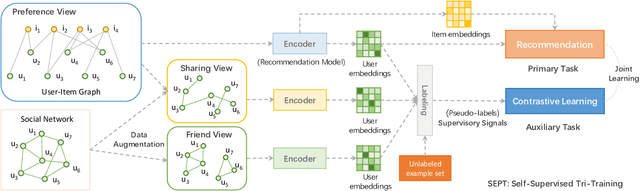
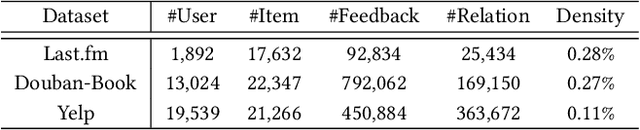
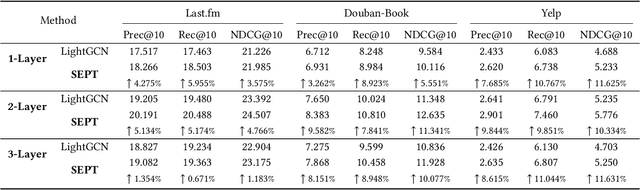
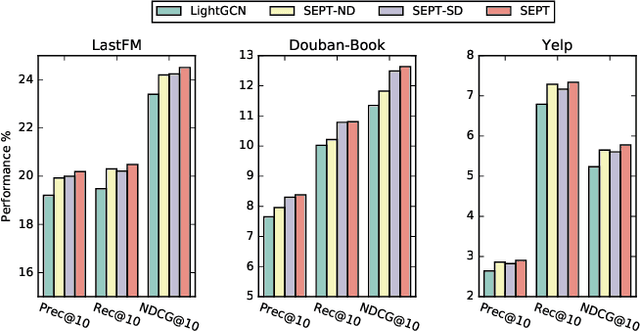
Self-supervised learning (SSL), which can automatically generate ground-truth samples from raw data, holds vast potential to improve recommender systems. Most existing SSL-based methods perturb the raw data graph with uniform node/edge dropout to generate new data views and then conduct the self-discrimination based contrastive learning over different views to learn generalizable representations. Under this scheme, only a bijective mapping is built between nodes in two different views, which means that the self-supervision signals from other nodes are being neglected. Due to the widely observed homophily in recommender systems, we argue that the supervisory signals from other nodes are also highly likely to benefit the representation learning for recommendation. To capture these signals, a general socially-aware SSL framework that integrates tri-training is proposed in this paper. Technically, our framework first augments the user data views with the user social information. And then under the regime of tri-training for multi-view encoding, the framework builds three graph encoders (one for recommendation) upon the augmented views and iteratively improves each encoder with self-supervision signals from other users, generated by the other two encoders. Since the tri-training operates on the augmented views of the same data sources for self-supervision signals, we name it self-supervised tri-training. Extensive experiments on multiple real-world datasets consistently validate the effectiveness of the self-supervised tri-training framework for improving recommendation. The code is released at https://github.com/Coder-Yu/QRec.
FGLP: A Federated Fine-Grained Location Prediction System for Mobile Users
Jun 13, 2021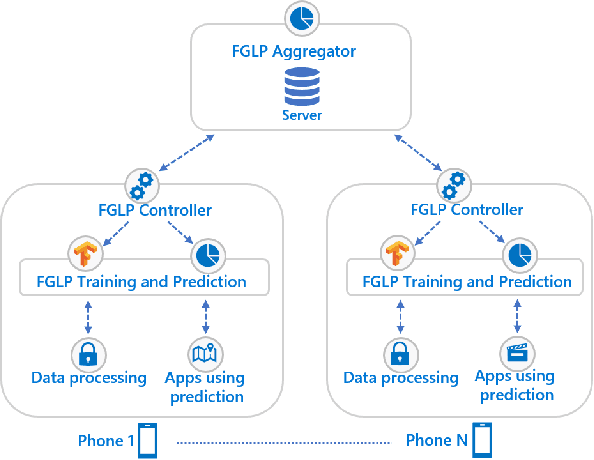
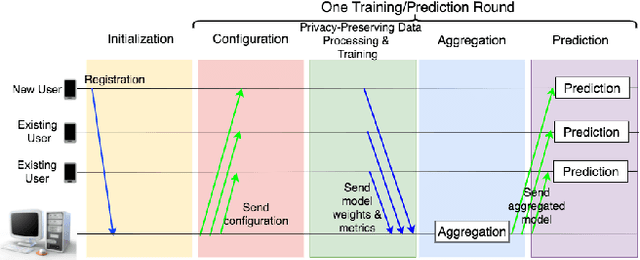
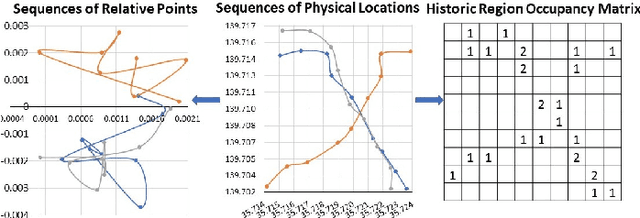
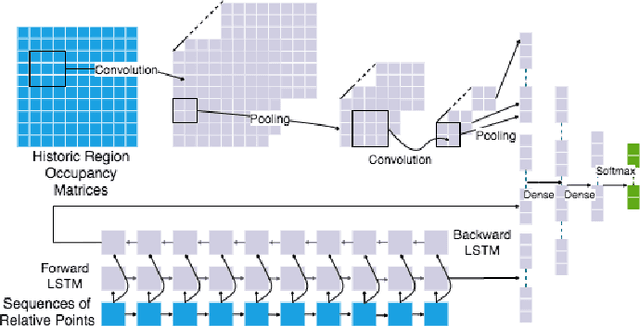
Fine-grained location prediction on smart phones can be used to improve app/system performance. Application scenarios include video quality adaptation as a function of the 5G network quality at predicted user locations, and augmented reality apps that speed up content rendering based on predicted user locations. Such use cases require prediction error in the same range as the GPS error, and no existing works on location prediction can achieve this level of accuracy. We present a system for fine-grained location prediction (FGLP) of mobile users, based on GPS traces collected on the phones. FGLP has two components: a federated learning framework and a prediction model. The framework runs on the phones of the users and also on a server that coordinates learning from all users in the system. FGLP represents the user location data as relative points in an abstract 2D space, which enables learning across different physical spaces. The model merges Bidirectional Long Short-Term Memory (BiLSTM) and Convolutional Neural Networks (CNN), where BiLSTM learns the speed and direction of the mobile users, and CNN learns information such as user movement preferences. FGLP uses federated learning to protect user privacy and reduce bandwidth consumption. Our experimental results, using a dataset with over 600,000 users, demonstrate that FGLP outperforms baseline models in terms of prediction accuracy. We also demonstrate that FGLP works well in conjunction with transfer learning, which enables model reusability. Finally, benchmark results on several types of Android phones demonstrate FGLP's feasibility in real life.
Multimodal Fusion with BERT and Attention Mechanism for Fake News Detection
Apr 23, 2021
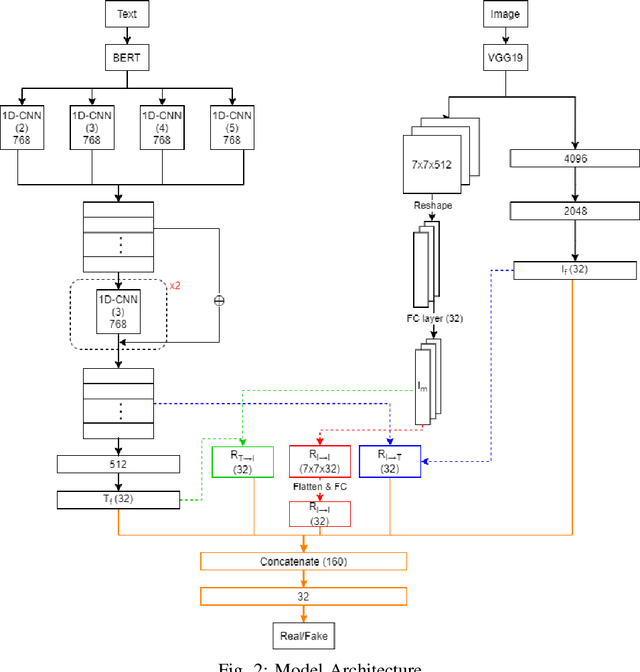
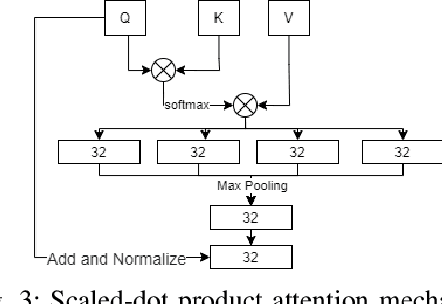

Fake news detection is an important task for increasing the credibility of information on the media since fake news is constantly spreading on social media every day and it is a very serious concern in our society. Fake news is usually created by manipulating images, texts, and videos. In this paper, we present a novel method for detecting fake news by fusing multimodal features derived from textual and visual data. Specifically, we used a pre-trained BERT model to learn text features and a VGG-19 model pre-trained on the ImageNet dataset to extract image features. We proposed a scale-dot product attention mechanism to capture the relationship between text features and visual features. Experimental results showed that our approach performs better than the current state-of-the-art method on a public Twitter dataset by 3.1% accuracy.
Investigation of Uncertainty of Deep Learning-based Object Classification on Radar Spectra
Jun 01, 2021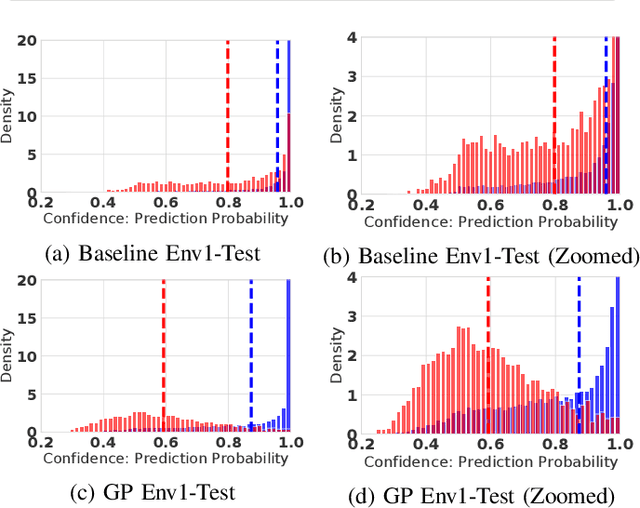
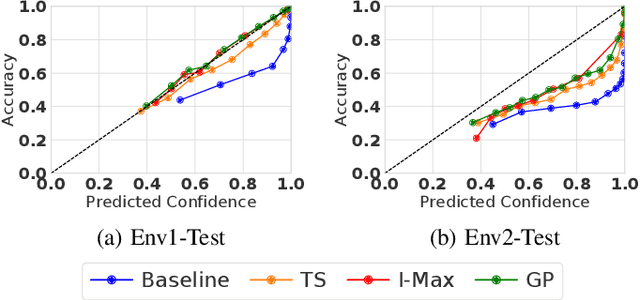
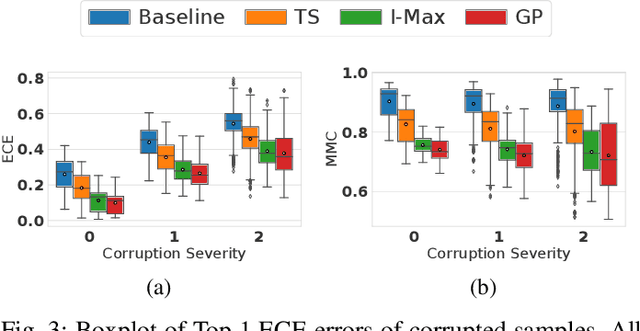

Deep learning (DL) has recently attracted increasing interest to improve object type classification for automotive radar.In addition to high accuracy, it is crucial for decision making in autonomous vehicles to evaluate the reliability of the predictions; however, decisions of DL networks are non-transparent. Current DL research has investigated how uncertainties of predictions can be quantified, and in this article, we evaluate the potential of these methods for safe, automotive radar perception. In particular we evaluate how uncertainty quantification can support radar perception under (1) domain shift, (2) corruptions of input signals, and (3) in the presence of unknown objects. We find that in agreement with phenomena observed in the literature,deep radar classifiers are overly confident, even in their wrong predictions. This raises concerns about the use of the confidence values for decision making under uncertainty, as the model fails to notify when it cannot handle an unknown situation. Accurate confidence values would allow optimal integration of multiple information sources, e.g. via sensor fusion. We show that by applying state-of-the-art post-hoc uncertainty calibration, the quality of confidence measures can be significantly improved,thereby partially resolving the over-confidence problem. Our investigation shows that further research into training and calibrating DL networks is necessary and offers great potential for safe automotive object classification with radar sensors.
* 6 pages
Self-harm: detection and support on Twitter
Apr 01, 2021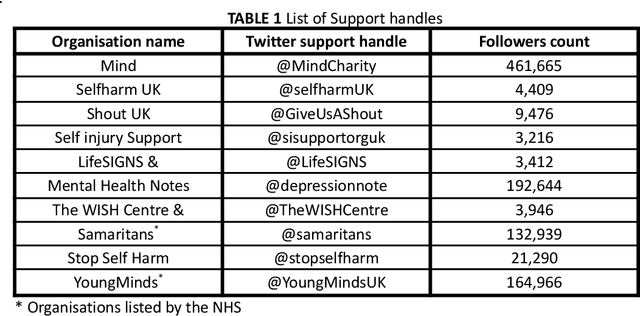
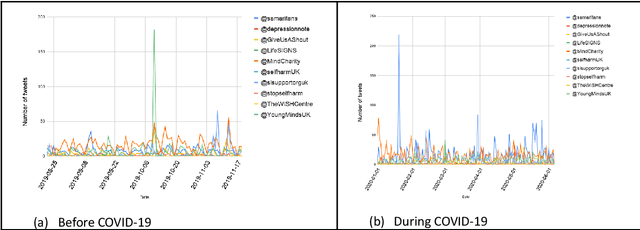
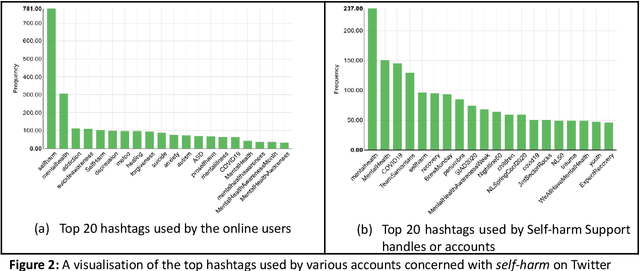
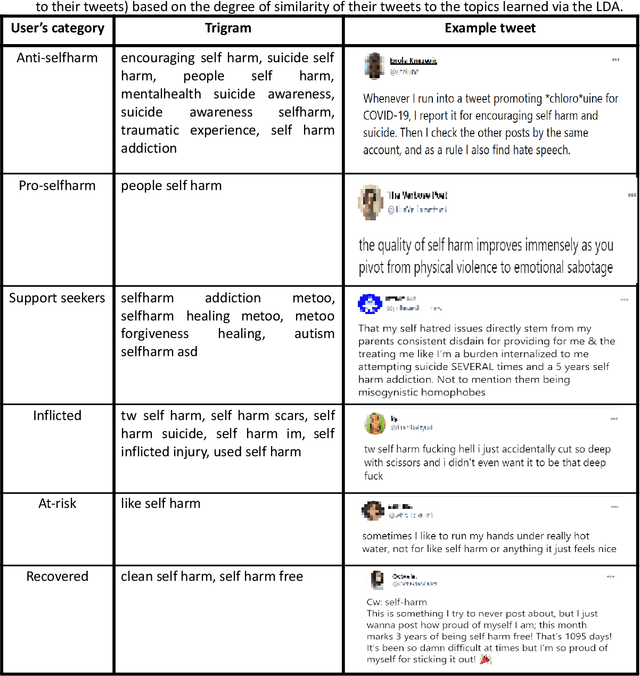
Since the advent of online social media platforms such as Twitter and Facebook, useful health-related studies have been conducted using the information posted by online participants. Personal health-related issues such as mental health, self-harm and depression have been studied because users often share their stories on such platforms. Online users resort to sharing because the empathy and support from online communities are crucial in helping the affected individuals. A preliminary analysis shows how contents related to non-suicidal self-injury (NSSI) proliferate on Twitter. Thus, we use Twitter to collect relevant data, analyse, and proffer ways of supporting users prone to NSSI behaviour. Our approach utilises a custom crawler to retrieve relevant tweets from self-reporting users and relevant organisations interested in combating self-harm. Through textual analysis, we identify six major categories of self-harming users consisting of inflicted, anti-self-harm, support seekers, recovered, pro-self-harm and at risk. The inflicted category dominates the collection. From an engagement perspective, we show how online users respond to the information posted by self-harm support organisations on Twitter. By noting the most engaged organisations, we apply a useful technique to uncover the organisations' strategy. The online participants show a strong inclination towards online posts associated with mental health related attributes. Our study is based on the premise that social media can be used as a tool to support proactive measures to ease the negative impact of self-harm. Consequently, we proffer ways to prevent potential users from engaging in self-harm and support affected users through a set of recommendations. To support further research, the dataset will be made available for interested researchers.
Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting
Feb 03, 2021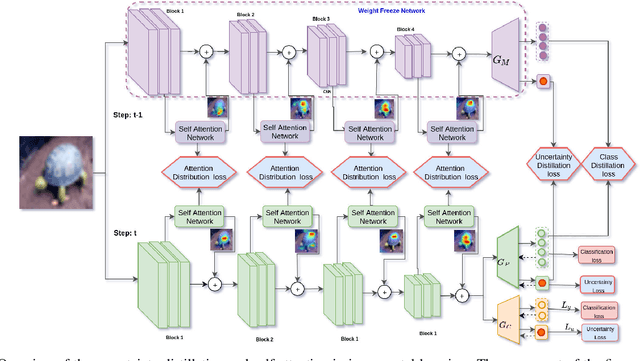
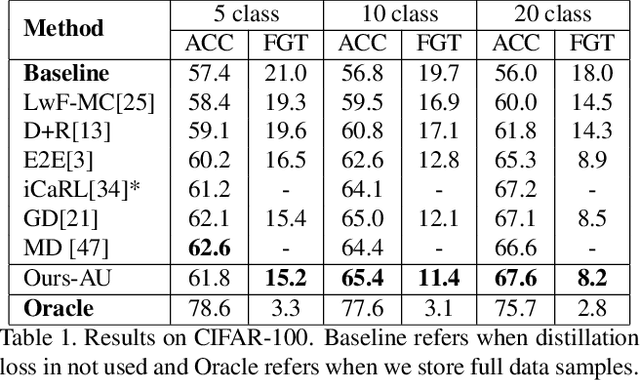
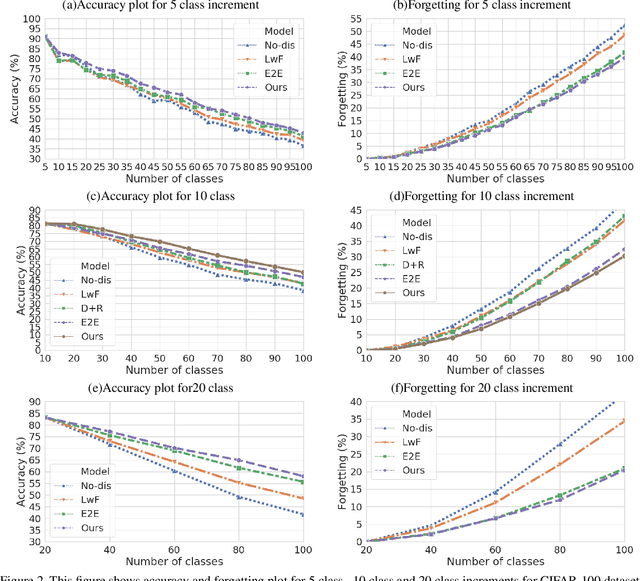
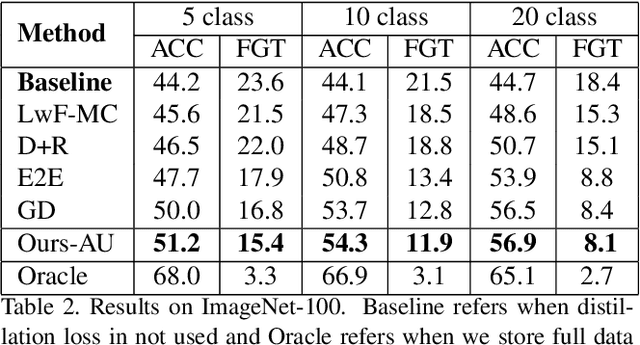
One of the major limitations of deep learning models is that they face catastrophic forgetting in an incremental learning scenario. There have been several approaches proposed to tackle the problem of incremental learning. Most of these methods are based on knowledge distillation and do not adequately utilize the information provided by older task models, such as uncertainty estimation in predictions. The predictive uncertainty provides the distributional information can be applied to mitigate catastrophic forgetting in a deep learning framework. In the proposed work, we consider a Bayesian formulation to obtain the data and model uncertainties. We also incorporate self-attention framework to address the incremental learning problem. We define distillation losses in terms of aleatoric uncertainty and self-attention. In the proposed work, we investigate different ablation analyses on these losses. Furthermore, we are able to obtain better results in terms of accuracy on standard benchmarks.
* Accepted WACV 2021
A Novel Framework for Recurrent Neural Networks with Enhancing Information Processing and Transmission between Units
Jun 02, 2018
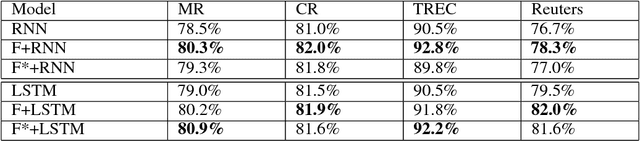

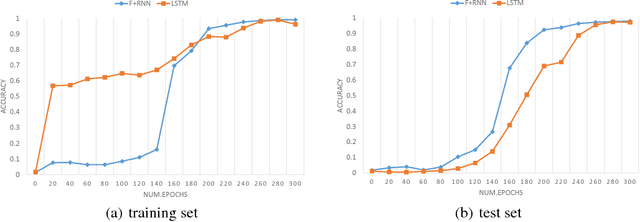
This paper proposes a novel framework for recurrent neural networks (RNNs) inspired by the human memory models in the field of cognitive neuroscience to enhance information processing and transmission between adjacent RNNs' units. The proposed framework for RNNs consists of three stages that is working memory, forget, and long-term store. The first stage includes taking input data into sensory memory and transferring it to working memory for preliminary treatment. And the second stage mainly focuses on proactively forgetting the secondary information rather than the primary in the working memory. And finally, we get the long-term store normally using some kind of RNN's unit. Our framework, which is generalized and simple, is evaluated on 6 datasets which fall into 3 different tasks, corresponding to text classification, image classification and language modelling. Experiments reveal that our framework can obviously improve the performance of traditional recurrent neural networks. And exploratory task shows the ability of our framework of correctly forgetting the secondary information.