 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion with BERT and Attention Mechanism for Fake News Detection
Apr 27, 2021
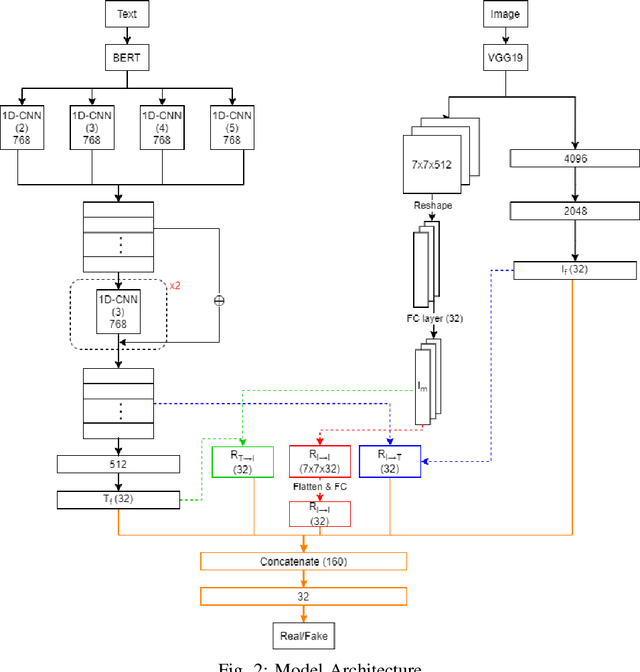
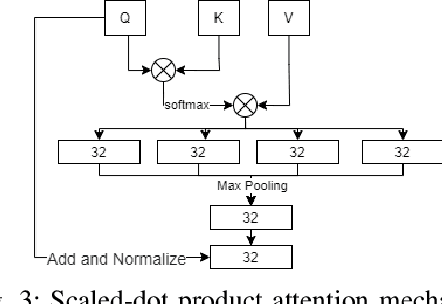

Fake news detection is an important task for increasing the credibility of information on the media since fake news is constantly spreading on social media every day and it is a very serious concern in our society. Fake news is usually created by manipulating images, texts, and videos. In this paper, we present a novel method for detecting fake news by fusing multimodal features derived from textual and visual data. Specifically, we used a pre-trained BERT model to learn text features and a VGG-19 model pre-trained on the ImageNet dataset to extract image features. We proposed a scale-dot product attention mechanism to capture the relationship between text features and visual features. Experimental results showed that our approach performs better than the current state-of-the-art method on a public Twitter dataset by 3.1% accuracy.
An Empirical Study of Using Pre-trained BERT Models for Vietnamese Relation Extraction Task at VLSP 2020
Jan 28, 2021
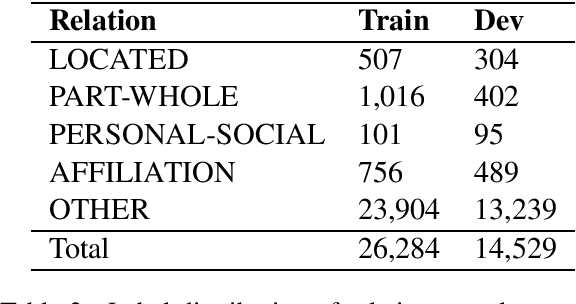


In this paper, we present an empirical study of using pre-trained BERT models for the relation extraction task at the VLSP 2020 Evaluation Campaign. We applied two state-of-the-art BERT-based models: R-BERT and BERT model with entity starts. For each model, we compared two pre-trained BERT models: FPTAI/vibert and NlpHUST/vibert4news. We found that NlpHUST/vibert4news model significantly outperforms FPTAI/vibert for the Vietnamese relation extraction task. Finally, we proposed an ensemble model that combines R-BERT and BERT with entity starts. Our proposed ensemble model slightly improved against two single models on the development data and the test data provided by the task organizers.
ReINTEL Challenge 2020: A Multimodal Ensemble Model for Detecting Unreliable Information on Vietnamese SNS
Dec 18, 2020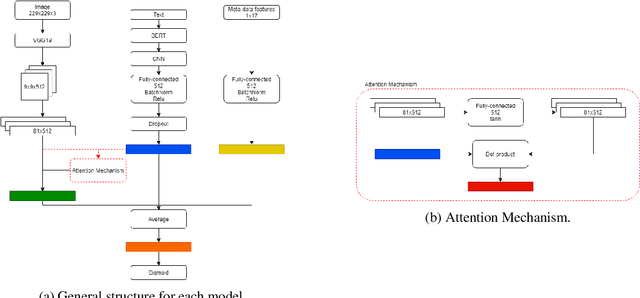
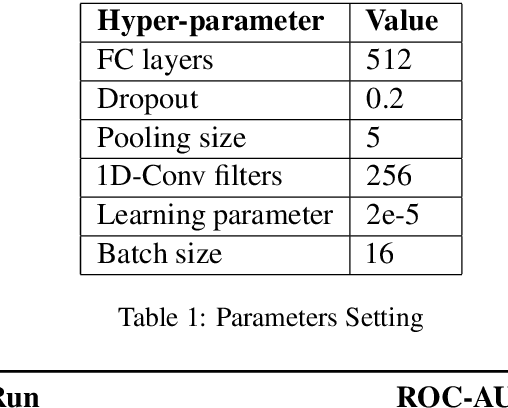
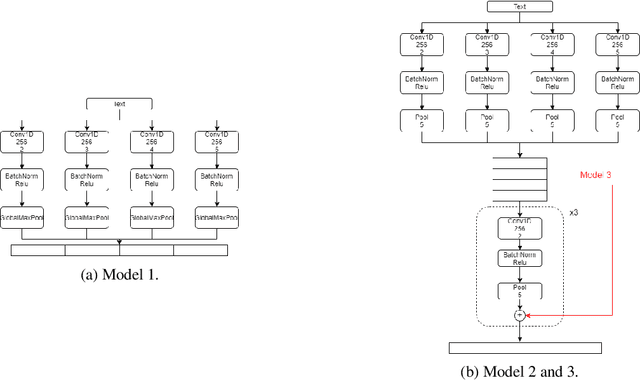

In this paper, we present our methods for unrealiable information identification task at VLSP 2020 ReINTEL Challenge. The task is to classify a piece of information into reliable or unreliable category. We propose a novel multimodal ensemble model which combines two multimodal models to solve the task. In each multimodal model, we combined feature representations acquired from three different data types: texts, images, and metadata. Multimodal features are derived from three neural networks and fused for classification. Experimental results showed that our proposed multimodal ensemble model improved against single models in term of ROC AUC score. We obtained 0.9445 AUC score on the private test of the challenge.
A Feature-Based Model for Nested Named-Entity Recognition at VLSP-2018 NER Evaluation Campaign
Mar 22, 2018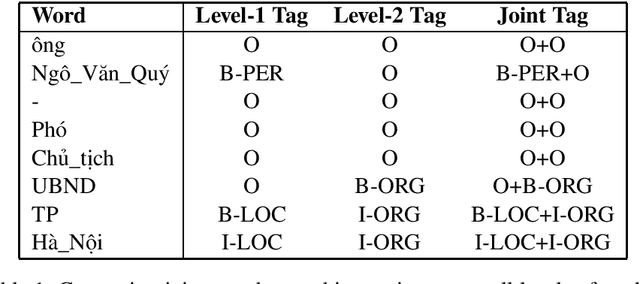
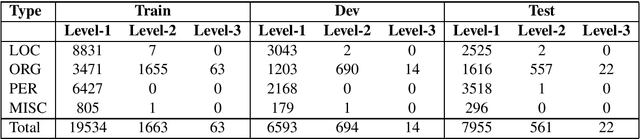
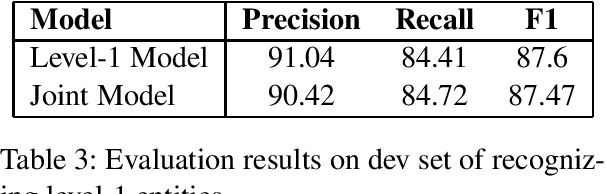

In this report, we describe our participant named-entity recognition system at VLSP 2018 evaluation campaign. We formalized the task as a sequence labeling problem using BIO encoding scheme. We applied a feature-based model which combines word, word-shape features, Brown-cluster-based features, and word-embedding-based features. We compare several methods to deal with nested entities in the dataset. We showed that combining tags of entities at all levels for training a sequence labeling model (joint-tag model) improved the accuracy of nested named-entity recognition.
A Feature-Rich Vietnamese Named-Entity Recognition Model
Mar 12, 2018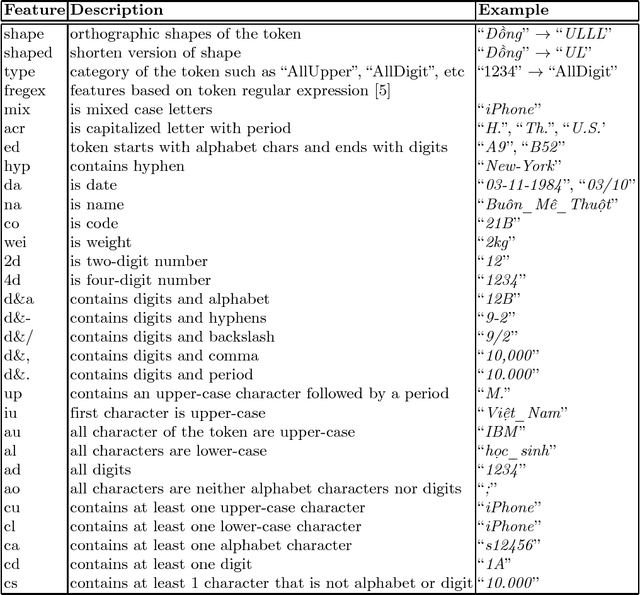
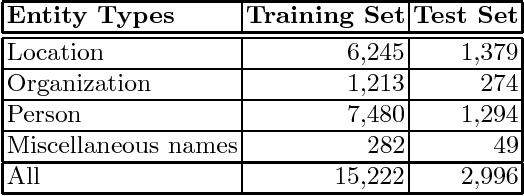


In this paper, we present a feature-based named-entity recognition (NER) model that achieves the start-of-the-art accuracy for Vietnamese language. We combine word, word-shape features, PoS, chunk, Brown-cluster-based features, and word-embedding-based features in the Conditional Random Fields (CRF) model. We also explore the effects of word segmentation, PoS tagging, and chunking results of many popular Vietnamese NLP toolkits on the accuracy of the proposed feature-based NER model. Up to now, our work is the first work that systematically performs an extrinsic evaluation of basic Vietnamese NLP toolkits on the downstream NER task. Experimental results show that while automatically-generated word segmentation is useful, PoS and chunking information generated by Vietnamese NLP tools does not show their benefits for the proposed feature-based NER model.