 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll You Need is "Leet": Evading Hate-speech Detection AI
May 22, 2025Social media and online forums are increasingly becoming popular. Unfortunately, these platforms are being used for spreading hate speech. In this paper, we design black-box techniques to protect users from hate-speech on online platforms by generating perturbations that can fool state of the art deep learning based hate speech detection models thereby decreasing their efficiency. We also ensure a minimal change in the original meaning of hate-speech. Our best perturbation attack is successfully able to evade hate-speech detection for 86.8 % of hateful text.
KernelOracle: Predicting the Linux Scheduler's Next Move with Deep Learning
May 21, 2025Efficient task scheduling is paramount in the Linux kernel, where the Completely Fair Scheduler (CFS) meticulously manages CPU resources to balance high utilization with interactive responsiveness. This research pioneers the use of deep learning techniques to predict the sequence of tasks selected by CFS, aiming to evaluate the feasibility of a more generalized and potentially more adaptive task scheduler for diverse workloads. Our core contributions are twofold: first, the systematic generation and curation of a novel scheduling dataset from a running Linux kernel, capturing real-world CFS behavior; and second, the development, training, and evaluation of a Long Short-Term Memory (LSTM) network designed to accurately forecast the next task to be scheduled. This paper further discusses the practical pathways and implications of integrating such a predictive model into the kernel's scheduling framework. The findings and methodologies presented herein open avenues for data-driven advancements in kernel scheduling, with the full source code provided for reproducibility and further exploration.
ScanBank: A Benchmark Dataset for Figure Extraction from Scanned Electronic Theses and Dissertations
Jun 23, 2021
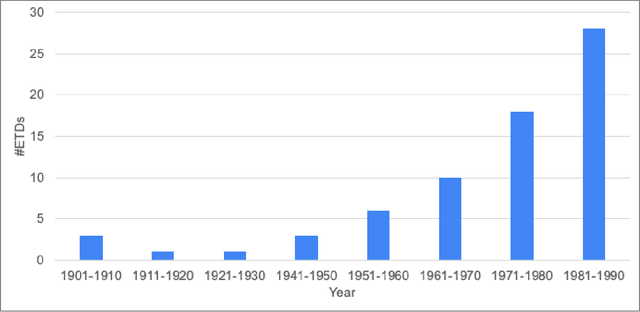

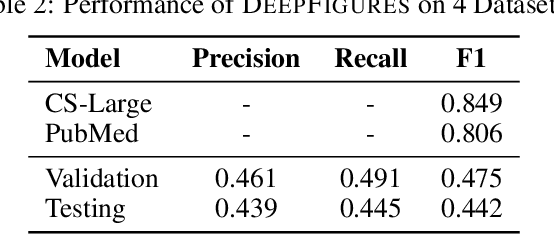
We focus on electronic theses and dissertations (ETDs), aiming to improve access and expand their utility, since more than 6 million are publicly available, and they constitute an important corpus to aid research and education across disciplines. The corpus is growing as new born-digital documents are included, and since millions of older theses and dissertations have been converted to digital form to be disseminated electronically in institutional repositories. In ETDs, as with other scholarly works, figures and tables can communicate a large amount of information in a concise way. Although methods have been proposed for extracting figures and tables from born-digital PDFs, they do not work well with scanned ETDs. Considering this problem, our assessment of state-of-the-art figure extraction systems is that the reason they do not function well on scanned PDFs is that they have only been trained on born-digital documents. To address this limitation, we present ScanBank, a new dataset containing 10 thousand scanned page images, manually labeled by humans as to the presence of the 3.3 thousand figures or tables found therein. We use this dataset to train a deep neural network model based on YOLOv5 to accurately extract figures and tables from scanned ETDs. We pose and answer important research questions aimed at finding better methods for figure extraction from scanned documents. One of those concerns the value for training, of data augmentation techniques applied to born-digital documents which are used to train models better suited for figure extraction from scanned documents. To the best of our knowledge, ScanBank is the first manually annotated dataset for figure and table extraction for scanned ETDs. A YOLOv5-based model, trained on ScanBank, outperforms existing comparable open-source and freely available baseline methods by a considerable margin.