 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evaluating the Immediate Applicability of Pose Estimation for Sign Language Recognition
Apr 20, 2021
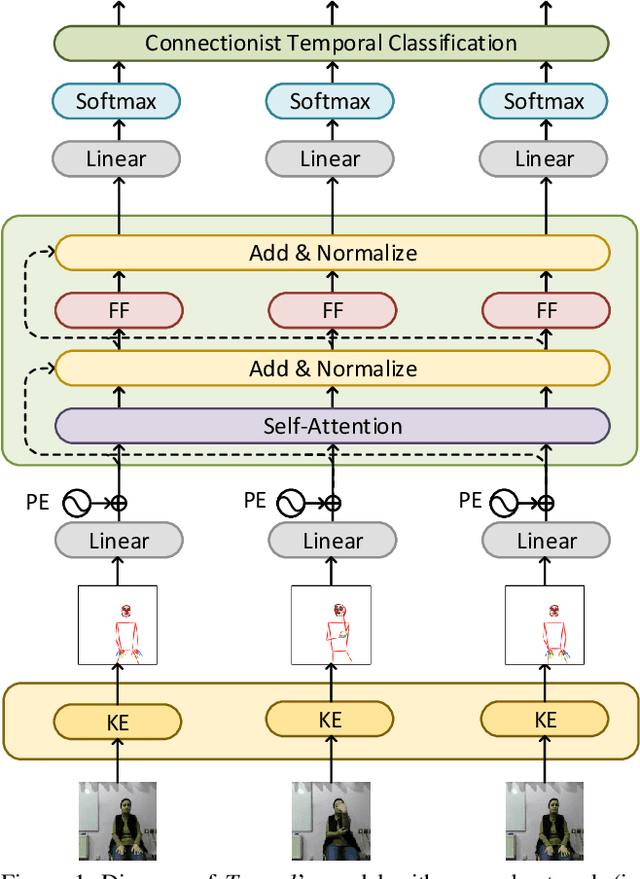
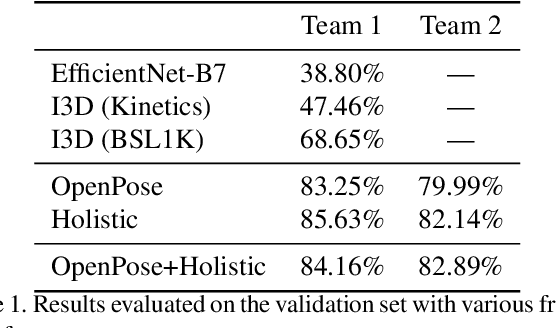
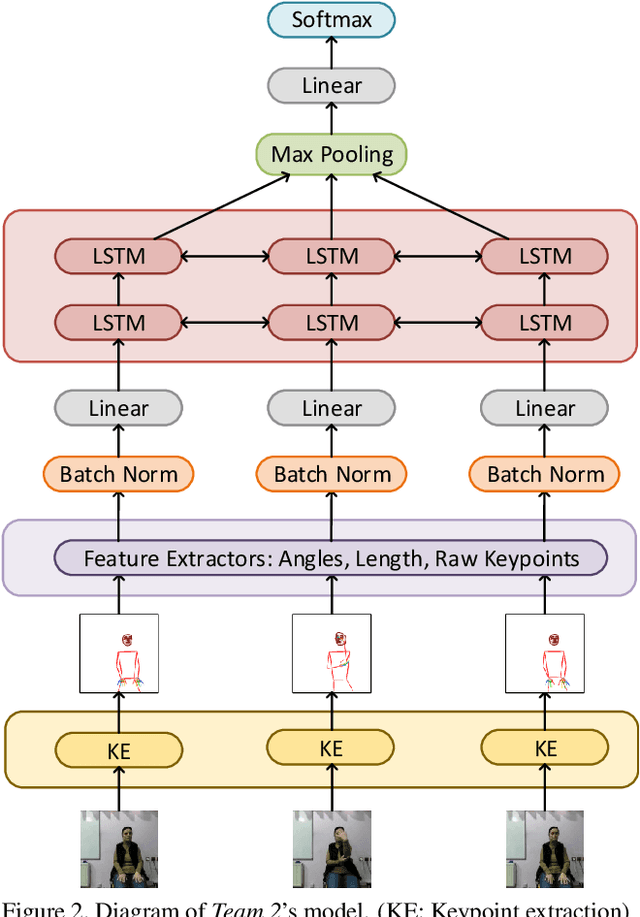
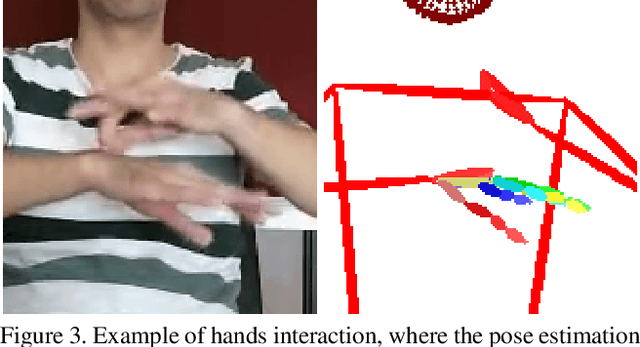
Signed languages are visual languages produced by the movement of the hands, face, and body. In this paper, we evaluate representations based on skeleton poses, as these are explainable, person-independent, privacy-preserving, low-dimensional representations. Basically, skeletal representations generalize over an individual's appearance and background, allowing us to focus on the recognition of motion. But how much information is lost by the skeletal representation? We perform two independent studies using two state-of-the-art pose estimation systems. We analyze the applicability of the pose estimation systems to sign language recognition by evaluating the failure cases of the recognition models. Importantly, this allows us to characterize the current limitations of skeletal pose estimation approaches in sign language recognition.
Cross-Gradient Aggregation for Decentralized Learning from Non-IID data
Mar 02, 2021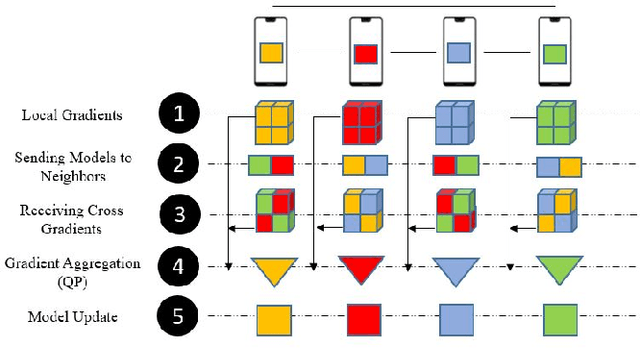

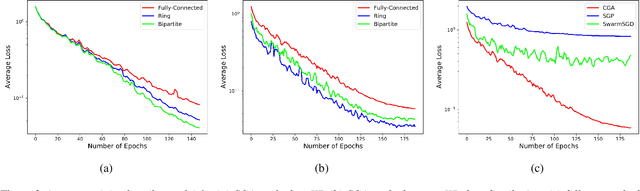
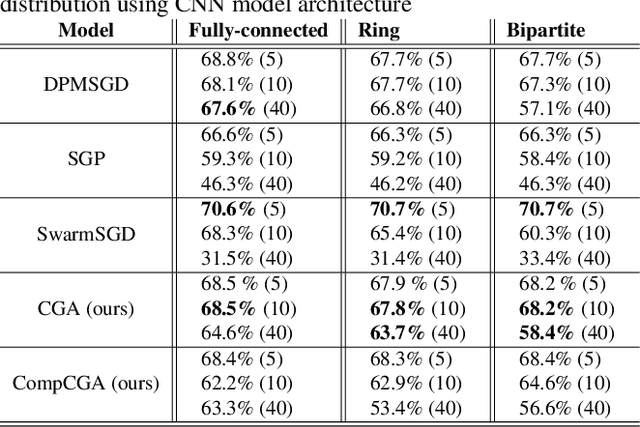
Decentralized learning enables a group of collaborative agents to learn models using a distributed dataset without the need for a central parameter server. Recently, decentralized learning algorithms have demonstrated state-of-the-art results on benchmark data sets, comparable with centralized algorithms. However, the key assumption to achieve competitive performance is that the data is independently and identically distributed (IID) among the agents which, in real-life applications, is often not applicable. Inspired by ideas from continual learning, we propose Cross-Gradient Aggregation (CGA), a novel decentralized learning algorithm where (i) each agent aggregates cross-gradient information, i.e., derivatives of its model with respect to its neighbors' datasets, and (ii) updates its model using a projected gradient based on quadratic programming (QP). We theoretically analyze the convergence characteristics of CGA and demonstrate its efficiency on non-IID data distributions sampled from the MNIST and CIFAR-10 datasets. Our empirical comparisons show superior learning performance of CGA over existing state-of-the-art decentralized learning algorithms, as well as maintaining the improved performance under information compression to reduce peer-to-peer communication overhead.
Directed Acyclic Graph Neural Networks
Jan 22, 2021



Graph-structured data ubiquitously appears in science and engineering. Graph neural networks (GNNs) are designed to exploit the relational inductive bias exhibited in graphs; they have been shown to outperform other forms of neural networks in scenarios where structure information supplements node features. The most common GNN architecture aggregates information from neighborhoods based on message passing. Its generality has made it broadly applicable. In this paper, we focus on a special, yet widely used, type of graphs -- DAGs -- and inject a stronger inductive bias -- partial ordering -- into the neural network design. We propose the \emph{directed acyclic graph neural network}, DAGNN, an architecture that processes information according to the flow defined by the partial order. DAGNN can be considered a framework that entails earlier works as special cases (e.g., models for trees and models updating node representations recurrently), but we identify several crucial components that prior architectures lack. We perform comprehensive experiments, including ablation studies, on representative DAG datasets (i.e., source code, neural architectures, and probabilistic graphical models) and demonstrate the superiority of DAGNN over simpler DAG architectures as well as general graph architectures.
Consistency-based Active Learning for Object Detection
Mar 18, 2021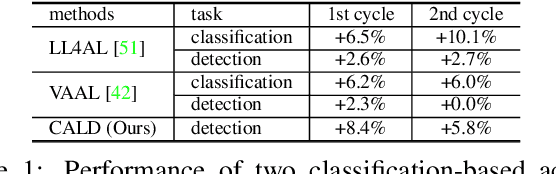
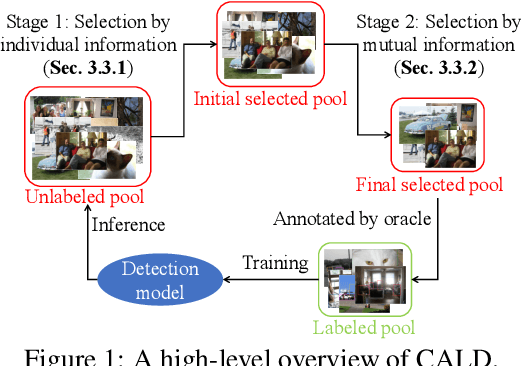
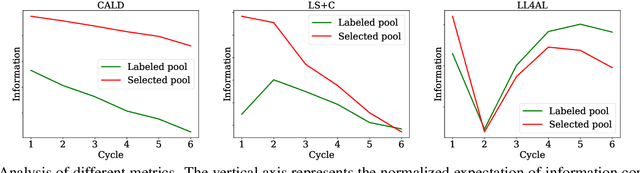
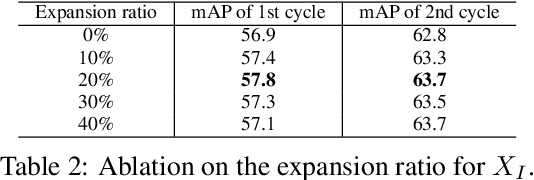
Active learning aims to improve the performance of task model by selecting the most informative samples with a limited budget. Unlike most recent works that focused on applying active learning for image classification, we propose an effective Consistency-based Active Learning method for object Detection (CALD), which fully explores the consistency between original and augmented data. CALD has three appealing benefits. (i) CALD is systematically designed by investigating the weaknesses of existing active learning methods, which do not take the unique challenges of object detection into account. (ii) CALD unifies box regression and classification with a single metric, which is not concerned by active learning methods for classification. CALD also focuses on the most informative local region rather than the whole image, which is beneficial for object detection. (iii) CALD not only gauges individual information for sample selection, but also leverages mutual information to encourage a balanced data distribution. Extensive experiments show that CALD significantly outperforms existing state-of-the-art task-agnostic and detection-specific active learning methods on general object detection datasets. Based on the Faster R-CNN detector, CALD consistently surpasses the baseline method (random selection) by 2.9/2.8/0.8 mAP on average on PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO. Code is available at \url{https://github.com/we1pingyu/CALD}
Learning to Stop with Surprisingly Few Samples
Feb 22, 2021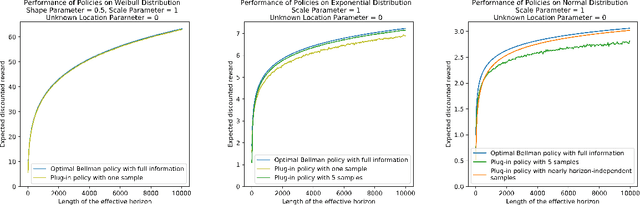
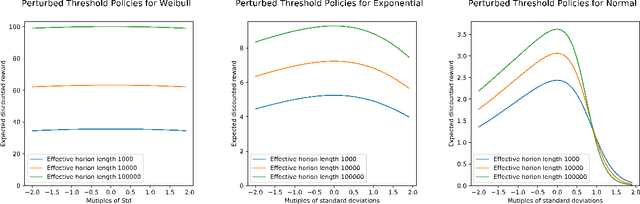
We consider a discounted infinite horizon optimal stopping problem. If the underlying distribution is known a priori, the solution of this problem is obtained via dynamic programming (DP) and is given by a well known threshold rule. When information on this distribution is lacking, a natural (though naive) approach is "explore-then-exploit," whereby the unknown distribution or its parameters are estimated over an initial exploration phase, and this estimate is then used in the DP to determine actions over the residual exploitation phase. We show: (i) with proper tuning, this approach leads to performance comparable to the full information DP solution; and (ii) despite common wisdom on the sensitivity of such "plug in" approaches in DP due to propagation of estimation errors, a surprisingly "short" (logarithmic in the horizon) exploration horizon suffices to obtain said performance. In cases where the underlying distribution is heavy-tailed, these observations are even more pronounced: a ${\it single \, sample}$ exploration phase suffices.
Disentangled Representation Learning for Astronomical Chemical Tagging
Mar 10, 2021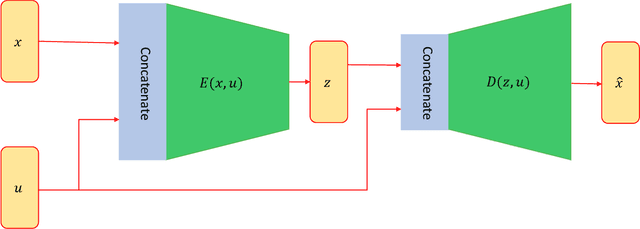

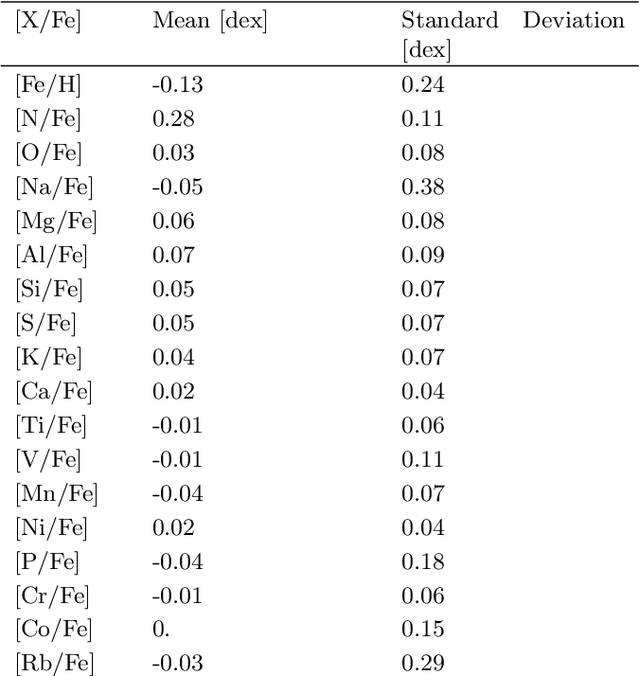
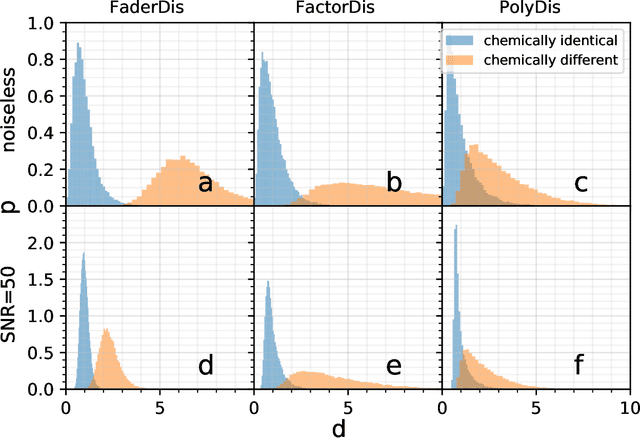
Modern astronomical surveys are observing spectral data for millions of stars. These spectra contain chemical information that can be used to trace the Galaxy's formation and chemical enrichment history. However, extracting the information from spectra, and making precise and accurate chemical abundance measurements are challenging. Here, we present a data-driven method for isolating the chemical factors of variation in stellar spectra from those of other parameters (i.e. \teff, \logg, \feh). This enables us to build a spectral projection for each star with these parameters removed. We do this with no ab initio knowledge of elemental abundances themselves, and hence bypass the uncertainties and systematics associated with modeling that rely on synthetic stellar spectra. To remove known non-chemical factors of variation, we develop and implement a neural network architecture that learns a disentangled spectral representation. We simulate our recovery of chemically identical stars using the disentangled spectra in a synthetic APOGEE-like dataset. We show that this recovery declines as a function of the signal to noise ratio, but that our neural network architecture outperforms simpler modeling choices. Our work demonstrates the feasibility of data-driven abundance-free chemical tagging.
A Conceptual Framework for Implicit Evaluation of Conversational Search Interfaces
Apr 08, 2021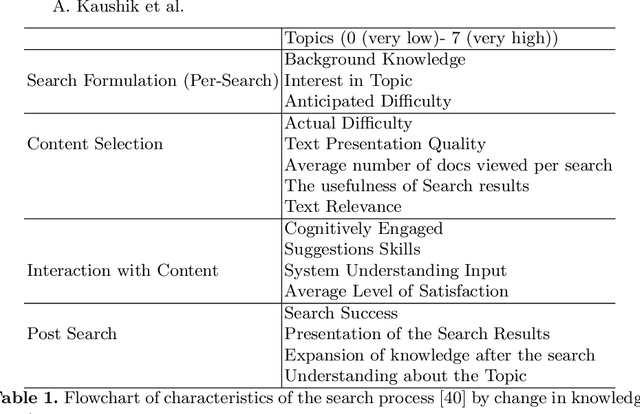
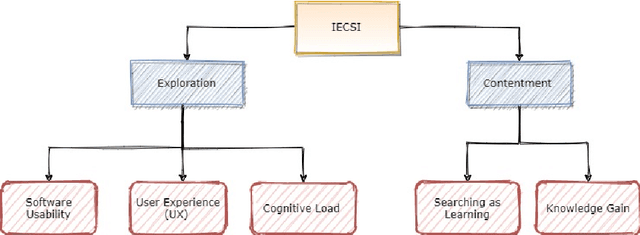
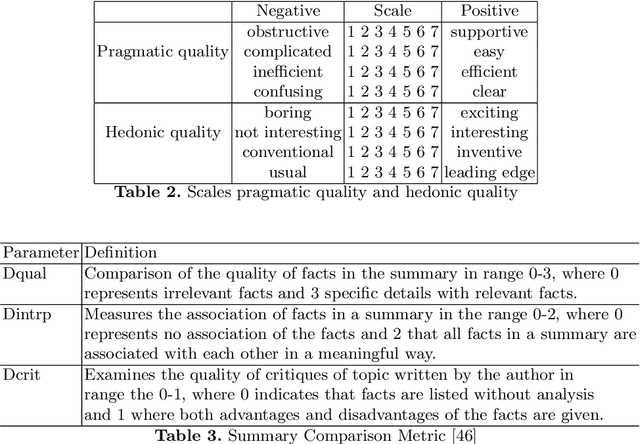
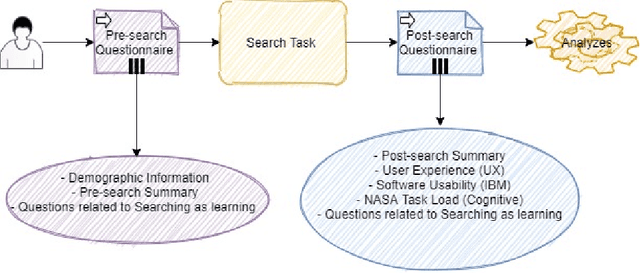
Conversational search (CS) has recently become a significant focus of the information retrieval (IR) research community. Multiple studies have been conducted which explore the concept of conversational search. Understanding and advancing research in CS requires careful and detailed evaluation. Existing CS studies have been limited to evaluation based on simple user feedback on task completion. We propose a CS evaluation framework which includes multiple dimensions: search experience, knowledge gain, software usability, cognitive load and user experience, based on studies of conversational systems and IR. We introduce these evaluation criteria and propose their use in a framework for the evaluation of CS systems.
Nearly Minimax Optimal Adversarial Imitation Learning with Known and Unknown Transitions
Jun 19, 2021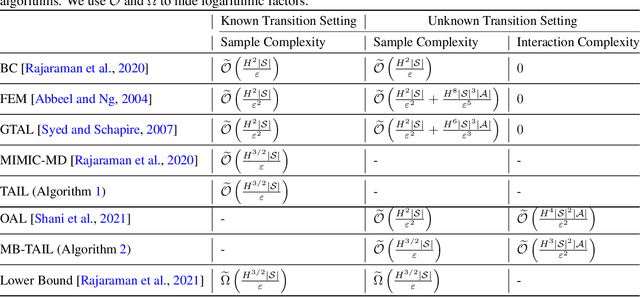
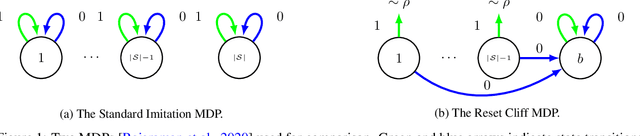
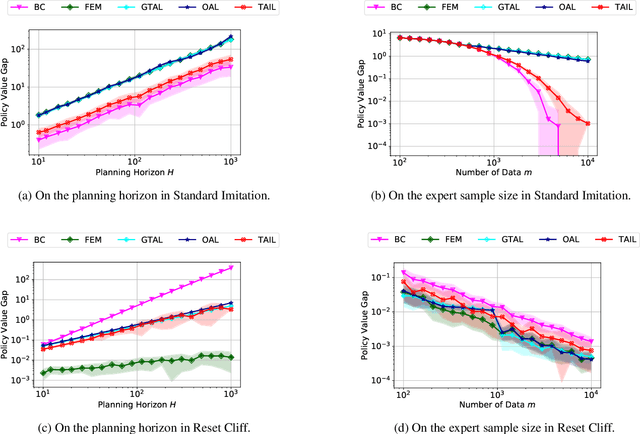

This paper is dedicated to designing provably efficient adversarial imitation learning (AIL) algorithms that directly optimize policies from expert demonstrations. Firstly, we develop a transition-aware AIL algorithm named TAIL with an expert sample complexity of $\tilde{O}(H^{3/2} |S|/\varepsilon)$ under the known transition setting, where $H$ is the planning horizon, $|S|$ is the state space size and $\varepsilon$ is desired policy value gap. This improves upon the previous best bound of $\tilde{O}(H^2 |S| / \varepsilon^2)$ for AIL methods and matches the lower bound of $\tilde{\Omega} (H^{3/2} |S|/\varepsilon)$ in [Rajaraman et al., 2021] up to a logarithmic factor. The key ingredient of TAIL is a fine-grained estimator for expert state-action distribution, which explicitly utilizes the transition function information. Secondly, considering practical settings where the transition functions are usually unknown but environment interaction is allowed, we accordingly develop a model-based transition-aware AIL algorithm named MB-TAIL. In particular, MB-TAIL builds an empirical transition model by interacting with the environment and performs imitation under the recovered empirical model. The interaction complexity of MB-TAIL is $\tilde{O} (H^3 |S|^2 |A| / \varepsilon^2)$, which improves the best known result of $\tilde{O} (H^4 |S|^2 |A| / \varepsilon^2)$ in [Shani et al., 2021]. Finally, our theoretical results are supported by numerical evaluation and detailed analysis on two challenging MDPs.
Adversarial Examples for Unsupervised Machine Learning Models
Mar 02, 2021

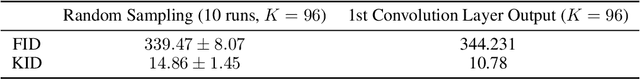
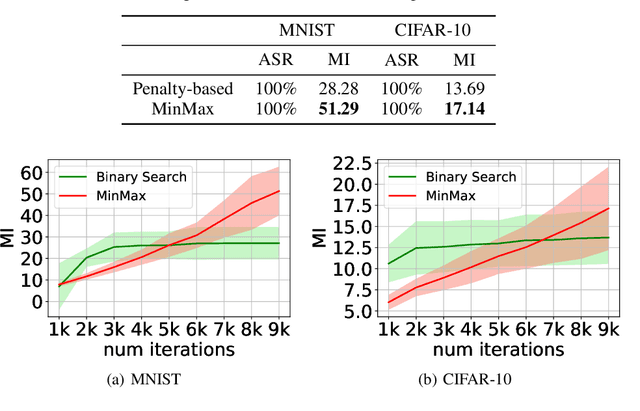
Adversarial examples causing evasive predictions are widely used to evaluate and improve the robustness of machine learning models. However, current studies on adversarial examples focus on supervised learning tasks, relying on the ground-truth data label, a targeted objective, or supervision from a trained classifier. In this paper, we propose a framework of generating adversarial examples for unsupervised models and demonstrate novel applications to data augmentation. Our framework exploits a mutual information neural estimator as an information-theoretic similarity measure to generate adversarial examples without supervision. We propose a new MinMax algorithm with provable convergence guarantees for efficient generation of unsupervised adversarial examples. Our framework can also be extended to supervised adversarial examples. When using unsupervised adversarial examples as a simple plug-in data augmentation tool for model retraining, significant improvements are consistently observed across different unsupervised tasks and datasets, including data reconstruction, representation learning, and contrastive learning. Our results show novel methods and advantages in studying and improving robustness of unsupervised learning problems via adversarial examples. Our codes are available at https://github.com/IBM/UAE.
Variance-Dependent Best Arm Identification
Jun 19, 2021We study the problem of identifying the best arm in a stochastic multi-armed bandit game. Given a set of $n$ arms indexed from $1$ to $n$, each arm $i$ is associated with an unknown reward distribution supported on $[0,1]$ with mean $\theta_i$ and variance $\sigma_i^2$. Assume $\theta_1 > \theta_2 \geq \cdots \geq\theta_n$. We propose an adaptive algorithm which explores the gaps and variances of the rewards of the arms and makes future decisions based on the gathered information using a novel approach called \textit{grouped median elimination}. The proposed algorithm guarantees to output the best arm with probability $(1-\delta)$ and uses at most $O \left(\sum_{i = 1}^n \left(\frac{\sigma_i^2}{\Delta_i^2} + \frac{1}{\Delta_i}\right)(\ln \delta^{-1} + \ln \ln \Delta_i^{-1})\right)$ samples, where $\Delta_i$ ($i \geq 2$) denotes the reward gap between arm $i$ and the best arm and we define $\Delta_1 = \Delta_2$. This achieves a significant advantage over the variance-independent algorithms in some favorable scenarios and is the first result that removes the extra $\ln n$ factor on the best arm compared with the state-of-the-art. We further show that $\Omega \left( \sum_{i = 1}^n \left( \frac{\sigma_i^2}{\Delta_i^2} + \frac{1}{\Delta_i} \right) \ln \delta^{-1} \right)$ samples are necessary for an algorithm to achieve the same goal, thereby illustrating that our algorithm is optimal up to doubly logarithmic terms.