 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Direct Preference Optimization
May 20, 2026Preference-based reinforcement learning (RL) is a key paradigm for aligning policies with human judgments, yet its theoretical behavior in distributed settings where preference data are fragmented across heterogeneous users remains poorly understood. Direct Preference Optimization (DPO) avoids explicit reward modeling but lacks convergence guarantees under federated and decentralized training, where communication constraints and non-IID preferences fundamentally alter optimization dynamics. We provide the first convergence and time-complexity analysis of DPO in distributed environments. Modeling personalized offline RL with user-specific preference distributions, we characterize the induced global optimization landscape. For federated DPO, we derive convergence rates that quantify the impact of client drift, communication frequency, and preference heterogeneity; for decentralized DPO, we establish convergence over general communication graphs and show how spectral connectivity governs optimization speed and consensus. Empirically, we corroborate our theoretical insights on standard alignment benchmarks, demonstrating that our proposed methods not only enjoy strong theoretical guarantees but also deliver robust and scalable performance in practice. The code base is available here.
Lighting-aware Unified Model for Instance Segmentation
May 19, 2026Foundation models like the Segment Anything Model (SAM) demonstrate impressive zero-shot generalization but frequently degrade under diverse real-world illumination, particularly for instance segmentation. In this work, we address this limitation by developing \textit{Lighting Convolutional-Attention (\lca{})}, an adapter module that enhances segmentation robustness without fine-tuning the heavy backbone. \lca{} employs a dual-branch architecture to process RGB features alongside contrast maps, enabling physically motivated sensitivity to structural changes rather than illumination artifacts. We optimize \lca{} through a pairwise training strategy, introducing a targeted loss term that explicitly penalizes discrepancies between clean images and their corresponding illumination variants. To evaluate and support this architecture, we conduct a comprehensive empirical study across multiple existing benchmarks and present a novel Unity-based synthetic dataset specifically designed to accurately replicate complex real-world lighting conditions. Extensive experimental results demonstrate that our approach successfully bridges the domain gap, delivering superior lighting-robust segmentation.
COOPO: Cyclic Offline-Online Policy Optimization Algorithm
May 18, 2026Offline reinforcement learning struggles with distributional shift and constrained performance due to static dataset limitations, while online RL demands prohibitive environment interactions. The recent advent of hybrid offline-to-online methods bridges these domains but suffers from distribution drift during transitions and catastrophic forgetting of offline knowledge. We introduce COOPO (Cyclic Offline-Online Policy Optimization), a generalized framework that repeatedly cycles between constrained offline training and online fine-tuning. Each cycle first anchors the policy to the dataset via KL-regularized advantage-weighted offline updates to minimize distributional shift and then fine-tunes it online using any policy optimization for stable exploration. Crucially, periodically returning to offline training eliminates forgetting and drift while maximizing dataset reuse. The cyclic behavior also helps reduce the online environment interactions. Theoretically, COOPO achieves better online sample efficiency, surpassing pure online RL, with guaranteed monotonic improvement under standard coverage assumptions. Extensive D4RL benchmarks demonstrate COOPO reduces online interactions versus state-of-the-art hybrids while improving final returns, maintaining robustness across diverse offline algorithms and online optimizers. This looped synergy sets new efficiency and performance standards for adaptive RL.
TabQL: In-Context Q-Learning with Tabular Foundation Models
May 18, 2026We propose Tabular Q-Learning (TabQL), a reinforcement learning framework that replaces the conventional parametric Q-network in Deep Q-Learning (DQN) with a tabular foundation model endowed with in-context learning capabilities. The key idea is to represent Q-values through a sequence-to-sequence foundation model operating over a tabularized representation of state-action-Q-value tuples, enabling rapid adaptation from limited online interaction by conditioning on recent experience. TabQL departs from classical DQN by leveraging (i) zero- or few-shot Q-value inference via in-context updates, and (ii) a warm-up phase using standard DQN to bootstrap high-quality context. Particularly, to enhance the context quality, new transitions are generated by executing actions output by TabQL with predicted Q values from DQN. We formalize TabQL, analyze its convergence and sample complexity under mild assumptions, and show that TabQL interpolates between vanilla Q-learning and DQN with in-context learning. Our analysis demonstrates that TabQL achieves improved efficiency compared to DQN by amortizing Bellman updates through in-context learning. Extensive numerical experiments with several benchmarks showcase the effectiveness and efficacy of the proposed TabQL.
LexiSafe: Offline Safe Reinforcement Learning with Lexicographic Safety-Reward Hierarchy
Feb 19, 2026Offline safe reinforcement learning (RL) is increasingly important for cyber-physical systems (CPS), where safety violations during training are unacceptable and only pre-collected data are available. Existing offline safe RL methods typically balance reward-safety tradeoffs through constraint relaxation or joint optimization, but they often lack structural mechanisms to prevent safety drift. We propose LexiSafe, a lexicographic offline RL framework designed to preserve safety-aligned behavior. We first develop LexiSafe-SC, a single-cost formulation for standard offline safe RL, and derive safety-violation and performance-suboptimality bounds that together yield sample-complexity guarantees. We then extend the framework to hierarchical safety requirements with LexiSafe-MC, which supports multiple safety costs and admits its own sample-complexity analysis. Empirically, LexiSafe demonstrates reduced safety violations and improved task performance compared to constrained offline baselines. By unifying lexicographic prioritization with structural bias, LexiSafe offers a practical and theoretically grounded approach for safety-critical CPS decision-making.
Balancing Utility and Privacy: Dynamically Private SGD with Random Projection
Sep 11, 2025Stochastic optimization is a pivotal enabler in modern machine learning, producing effective models for various tasks. However, several existing works have shown that model parameters and gradient information are susceptible to privacy leakage. Although Differentially Private SGD (DPSGD) addresses privacy concerns, its static noise mechanism impacts the error bounds for model performance. Additionally, with the exponential increase in model parameters, efficient learning of these models using stochastic optimizers has become more challenging. To address these concerns, we introduce the Dynamically Differentially Private Projected SGD (D2P2-SGD) optimizer. In D2P2-SGD, we combine two important ideas: (i) dynamic differential privacy (DDP) with automatic gradient clipping and (ii) random projection with SGD, allowing dynamic adjustment of the tradeoff between utility and privacy of the model. It exhibits provably sub-linear convergence rates across different objective functions, matching the best available rate. The theoretical analysis further suggests that DDP leads to better utility at the cost of privacy, while random projection enables more efficient model learning. Extensive experiments across diverse datasets show that D2P2-SGD remarkably enhances accuracy while maintaining privacy. Our code is available here.
Data-driven Kinematic Modeling in Soft Robots: System Identification and Uncertainty Quantification
Jul 10, 2025

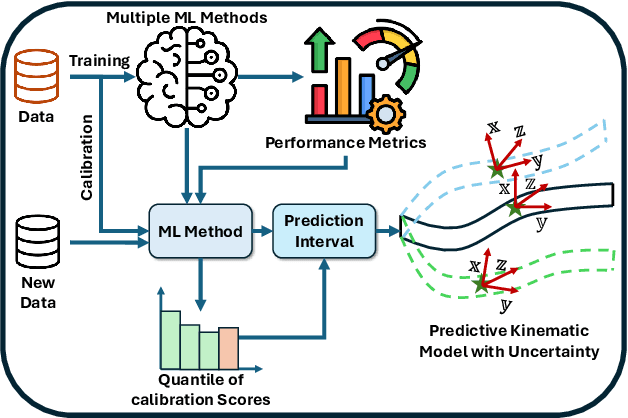

Precise kinematic modeling is critical in calibration and controller design for soft robots, yet remains a challenging issue due to their highly nonlinear and complex behaviors. To tackle the issue, numerous data-driven machine learning approaches have been proposed for modeling nonlinear dynamics. However, these models suffer from prediction uncertainty that can negatively affect modeling accuracy, and uncertainty quantification for kinematic modeling in soft robots is underexplored. In this work, using limited simulation and real-world data, we first investigate multiple linear and nonlinear machine learning models commonly used for kinematic modeling of soft robots. The results reveal that nonlinear ensemble methods exhibit the most robust generalization performance. We then develop a conformal kinematic modeling framework for soft robots by utilizing split conformal prediction to quantify predictive position uncertainty, ensuring distribution-free prediction intervals with a theoretical guarantee.
DeCAF: Decentralized Consensus-And-Factorization for Low-Rank Adaptation of Foundation Models
May 27, 2025Low-Rank Adaptation (LoRA) has emerged as one of the most effective, computationally tractable fine-tuning approaches for training Vision-Language Models (VLMs) and Large Language Models (LLMs). LoRA accomplishes this by freezing the pre-trained model weights and injecting trainable low-rank matrices, allowing for efficient learning of these foundation models even on edge devices. However, LoRA in decentralized settings still remains under explored, particularly for the theoretical underpinnings due to the lack of smoothness guarantee and model consensus interference (defined formally below). This work improves the convergence rate of decentralized LoRA (DLoRA) to match the rate of decentralized SGD by ensuring gradient smoothness. We also introduce DeCAF, a novel algorithm integrating DLoRA with truncated singular value decomposition (TSVD)-based matrix factorization to resolve consensus interference. Theoretical analysis shows TSVD's approximation error is bounded and consensus differences between DLoRA and DeCAF vanish as rank increases, yielding DeCAF's matching convergence rate. Extensive experiments across vision/language tasks demonstrate our algorithms outperform local training and rivals federated learning under both IID and non-IID data distributions.
Bidirectional Linear Recurrent Models for Sequence-Level Multisource Fusion
Apr 11, 2025Sequence modeling is a critical yet challenging task with wide-ranging applications, especially in time series forecasting for domains like weather prediction, temperature monitoring, and energy load forecasting. Transformers, with their attention mechanism, have emerged as state-of-the-art due to their efficient parallel training, but they suffer from quadratic time complexity, limiting their scalability for long sequences. In contrast, recurrent neural networks (RNNs) offer linear time complexity, spurring renewed interest in linear RNNs for more computationally efficient sequence modeling. In this work, we introduce BLUR (Bidirectional Linear Unit for Recurrent network), which uses forward and backward linear recurrent units (LRUs) to capture both past and future dependencies with high computational efficiency. BLUR maintains the linear time complexity of traditional RNNs, while enabling fast parallel training through LRUs. Furthermore, it offers provably stable training and strong approximation capabilities, making it highly effective for modeling long-term dependencies. Extensive experiments on sequential image and time series datasets reveal that BLUR not only surpasses transformers and traditional RNNs in accuracy but also significantly reduces computational costs, making it particularly suitable for real-world forecasting tasks. Our code is available here.
FUSE: First-Order and Second-Order Unified SynthEsis in Stochastic Optimization
Mar 06, 2025Stochastic optimization methods have actively been playing a critical role in modern machine learning algorithms to deliver decent performance. While numerous works have proposed and developed diverse approaches, first-order and second-order methods are in entirely different situations. The former is significantly pivotal and dominating in emerging deep learning but only leads convergence to a stationary point. However, second-order methods are less popular due to their computational intensity in large-dimensional problems. This paper presents a novel method that leverages both the first-order and second-order methods in a unified algorithmic framework, termed FUSE, from which a practical version (PV) is derived accordingly. FUSE-PV stands as a simple yet efficient optimization method involving a switch-over between first and second orders. Additionally, we develop different criteria that determine when to switch. FUSE-PV has provably shown a smaller computational complexity than SGD and Adam. To validate our proposed scheme, we present an ablation study on several simple test functions and show a comparison with baselines for benchmark datasets.