 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AnyoneNet: Synchronized Speech and Talking Head Generation for Arbitrary Person
Aug 11, 2021
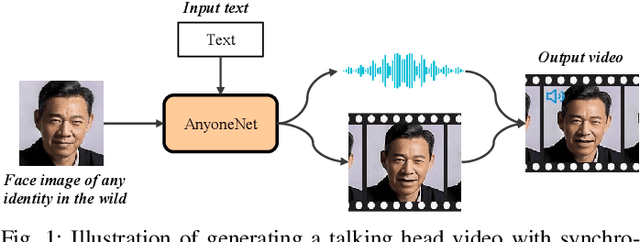
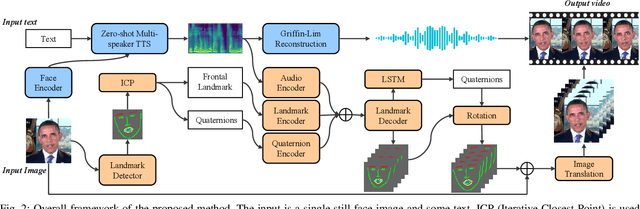
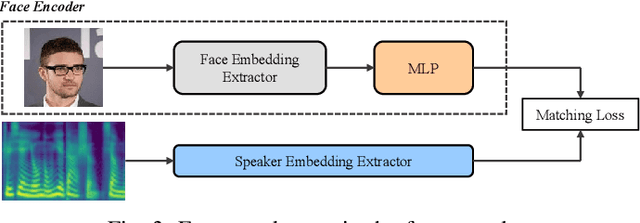
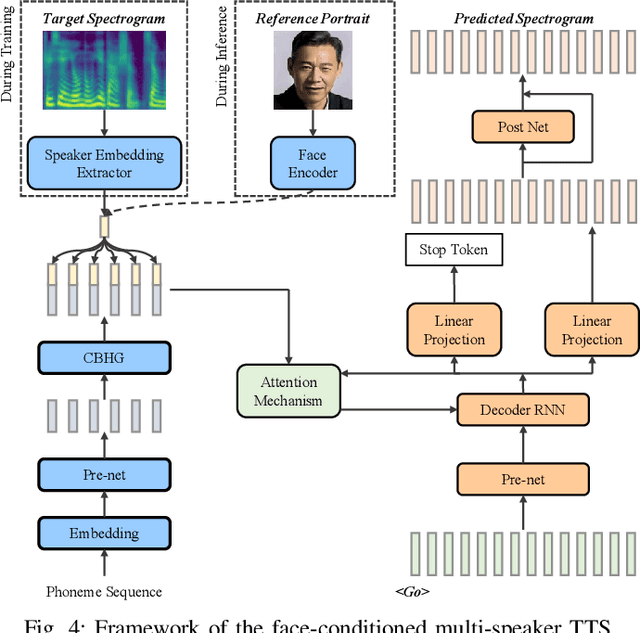
Automatically generating videos in which synthesized speech is synchronized with lip movements in a talking head has great potential in many human-computer interaction scenarios. In this paper, we present an automatic method to generate synchronized speech and talking-head videos on the basis of text and a single face image of an arbitrary person as input. In contrast to previous text-driven talking head generation methods, which can only synthesize the voice of a specific person, the proposed method is capable of synthesizing speech for any person that is inaccessible in the training stage. Specifically, the proposed method decomposes the generation of synchronized speech and talking head videos into two stages, i.e., a text-to-speech (TTS) stage and a speech-driven talking head generation stage. The proposed TTS module is a face-conditioned multi-speaker TTS model that gets the speaker identity information from face images instead of speech, which allows us to synthesize a personalized voice on the basis of the input face image. To generate the talking head videos from the face images, a facial landmark-based method that can predict both lip movements and head rotations is proposed. Extensive experiments demonstrate that the proposed method is able to generate synchronized speech and talking head videos for arbitrary persons and non-persons. Synthesized speech shows consistency with the given face regarding to the synthesized voice's timbre and one's appearance in the image, and the proposed landmark-based talking head method outperforms the state-of-the-art landmark-based method on generating natural talking head videos.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 01, 2021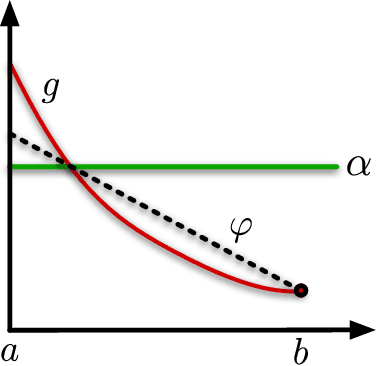
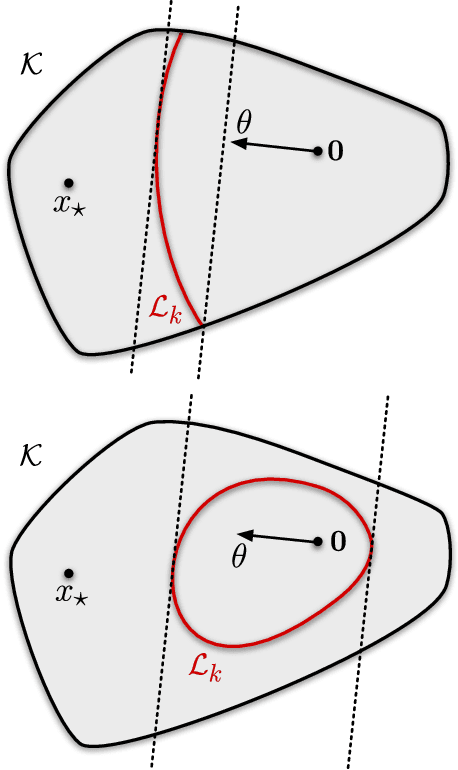
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f(x) = g(\langle x, \theta\rangle)$ for convex $g : \mathbb R \to \mathbb R$ and $\theta \in \mathbb R^d$. We provide a short information-theoretic proof that the minimax regret is at most $O(d\sqrt{n} \log(\operatorname{diam}\mathcal K))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set. Hence, this class of functions is at most logarithmically harder than the linear case.
Joint Vertebrae Identification and Localization in Spinal CT Images by Combining Short- and Long-Range Contextual Information
Dec 09, 2018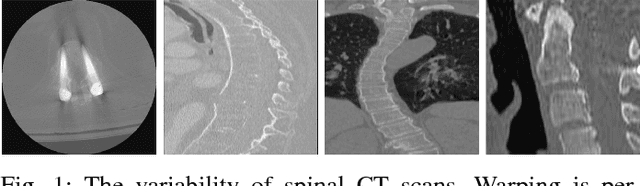
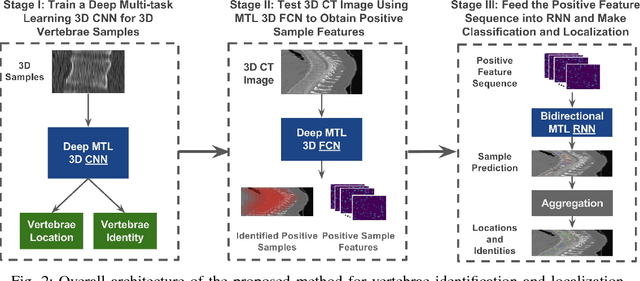
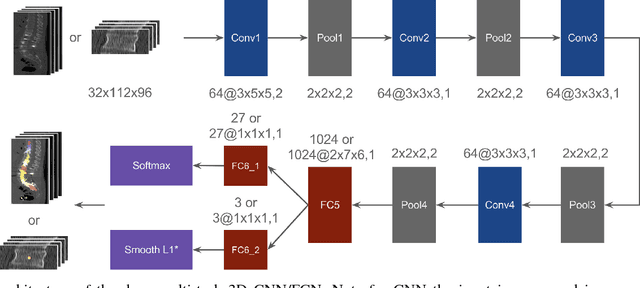
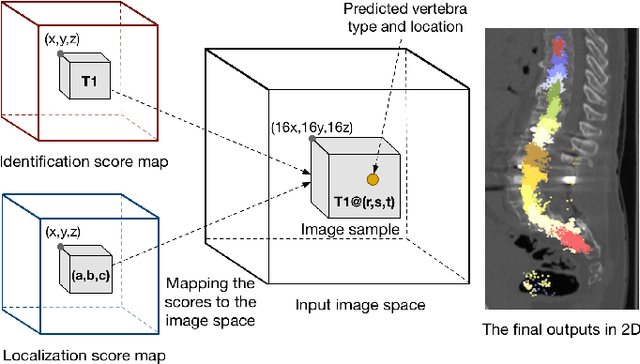
Automatic vertebrae identification and localization from arbitrary CT images is challenging. Vertebrae usually share similar morphological appearance. Because of pathology and the arbitrary field-of-view of CT scans, one can hardly rely on the existence of some anchor vertebrae or parametric methods to model the appearance and shape. To solve the problem, we argue that one should make use of the short-range contextual information, such as the presence of some nearby organs (if any), to roughly estimate the target vertebrae; due to the unique anatomic structure of the spine column, vertebrae have fixed sequential order which provides the important long-range contextual information to further calibrate the results. We propose a robust and efficient vertebrae identification and localization system that can inherently learn to incorporate both the short-range and long-range contextual information in a supervised manner. To this end, we develop a multi-task 3D fully convolutional neural network (3D FCN) to effectively extract the short-range contextual information around the target vertebrae. For the long-range contextual information, we propose a multi-task bidirectional recurrent neural network (Bi-RNN) to encode the spatial and contextual information among the vertebrae of the visible spine column. We demonstrate the effectiveness of the proposed approach on a challenging dataset and the experimental results show that our approach outperforms the state-of-the-art methods by a significant margin.
Semantic Communications in Networked Systems
Mar 09, 2021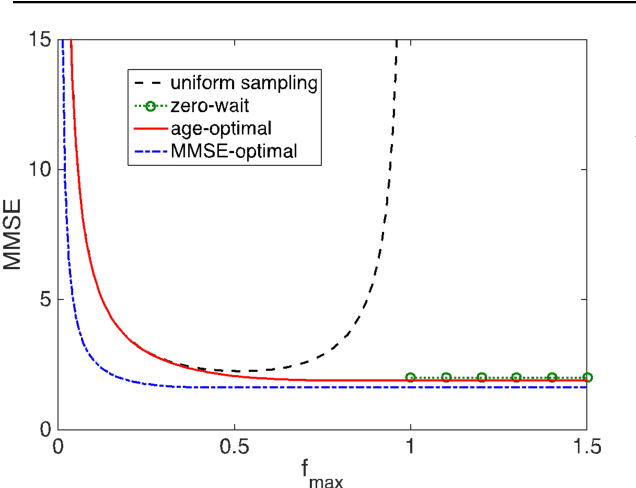
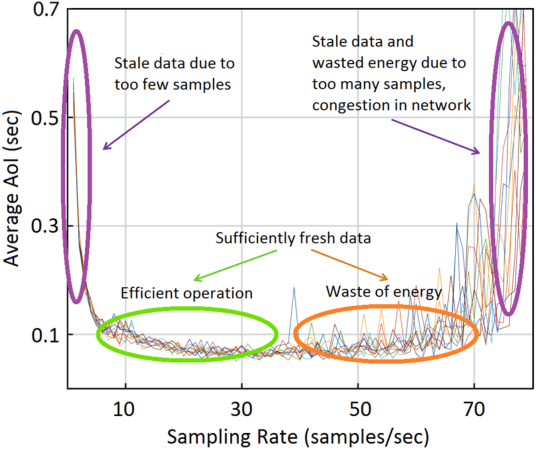
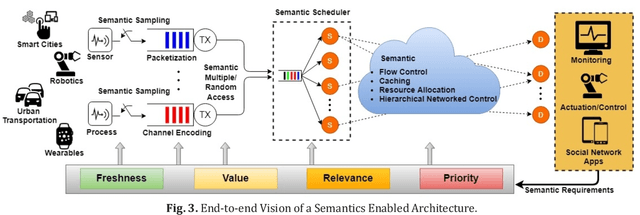
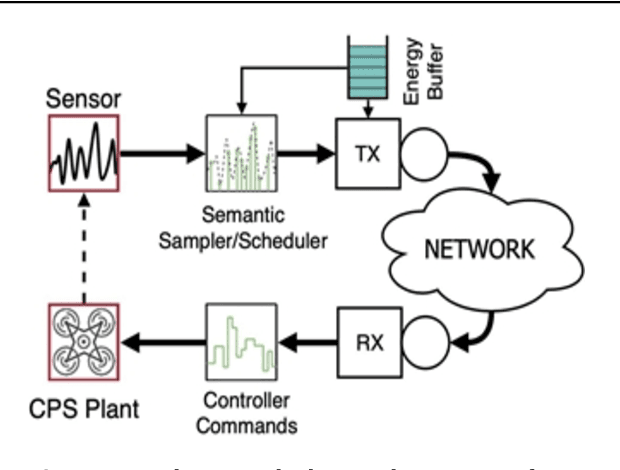
We present our vision for a departure from the established way of architecting and assessing communication networks, by incorporating the semantics of information for communications and control in networked systems. We define semantics of information, not as the meaning of the messages, but as their significance, possibly within a real time constraint, relative to the purpose of the data exchange. We argue that research efforts must focus on laying the theoretical foundations of a redesign of the entire process of information generation, transmission and usage in unison by developing: advanced semantic metrics for communications and control systems; an optimal sampling theory combining signal sparsity and semantics, for real-time prediction, reconstruction and control under communication constraints and delays; semantic compressed sensing techniques for decision making and inference directly in the compressed domain; semantic-aware data generation, channel coding, feedback, multiple and random access schemes that reduce the volume of data and the energy consumption, increasing the number of supportable devices.
Jointly Learning Semantic Parser and Natural Language Generator via Dual Information Maximization
Jun 13, 2019Semantic parsing aims to transform natural language (NL) utterances into formal meaning representations (MRs), whereas an NL generator achieves the reverse: producing a NL description for some given MRs. Despite this intrinsic connection, the two tasks are often studied separately in prior work. In this paper, we model the duality of these two tasks via a joint learning framework, and demonstrate its effectiveness of boosting the performance on both tasks. Concretely, we propose a novel method of dual information maximization (DIM) to regularize the learning process, where DIM empirically maximizes the variational lower bounds of expected joint distributions of NL and MRs. We further extend DIM to a semi-supervision setup (SemiDIM), which leverages unlabeled data of both tasks. Experiments on three datasets of dialogue management and code generation (and summarization) show that performance on both semantic parsing and NL generation can be consistently improved by DIM, in both supervised and semi-supervised setups.
Metric Map Merging using RFID Tags & Topological Information
Nov 17, 2017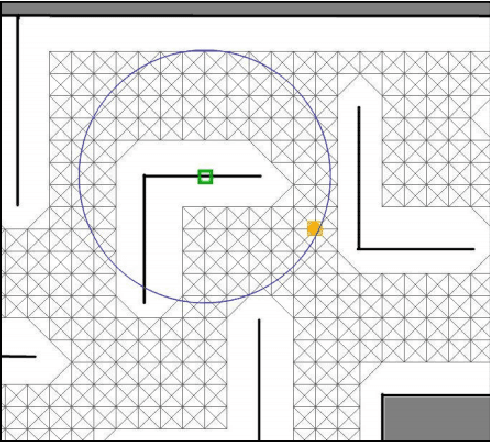
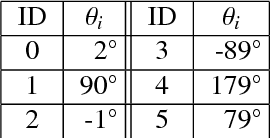
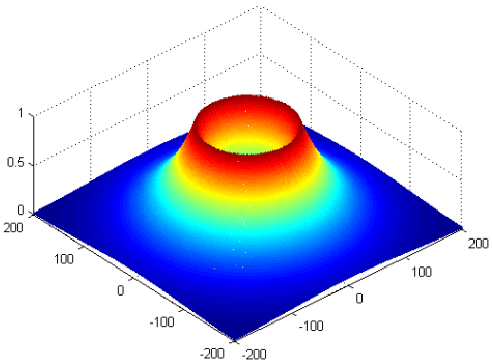
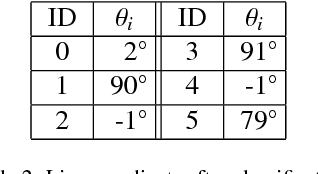
A map merging component is crucial for the proper functionality of a multi-robot system performing exploration, since it provides the means to integrate and distribute the most important information carried by the agents: the explored-covered space and its exact (depending on the SLAM accuracy) morphology. Map merging is a prerequisite for an intelligent multi-robot team aiming to deploy a smart exploration technique. In the current work, a metric map merging approach based on environmental information is proposed, in conjunction with spatially scattered RFID tags localization. This approach is divided into the following parts: the maps approximate rotation calculation via the obstacles poses and localized RFID tags, the translation employing the best localized common RFID tag and finally the transformation refinement using an ICP algorithm.
Recommending best course of treatment based on similarities of prognostic markers
Jul 19, 2021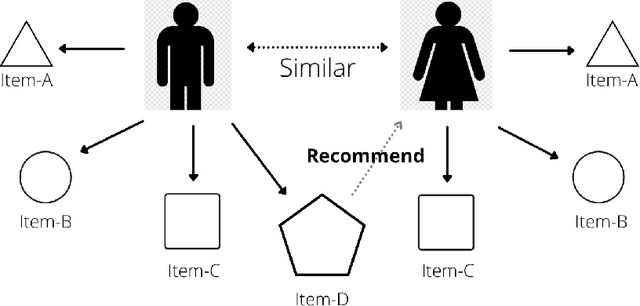
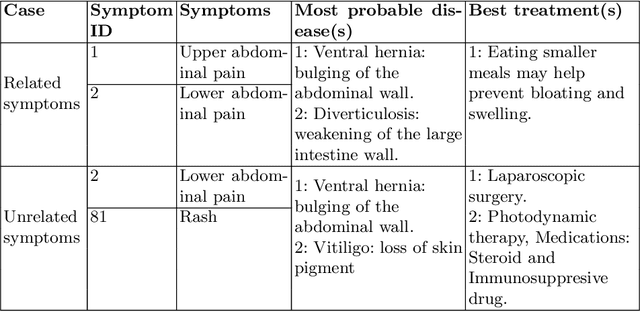
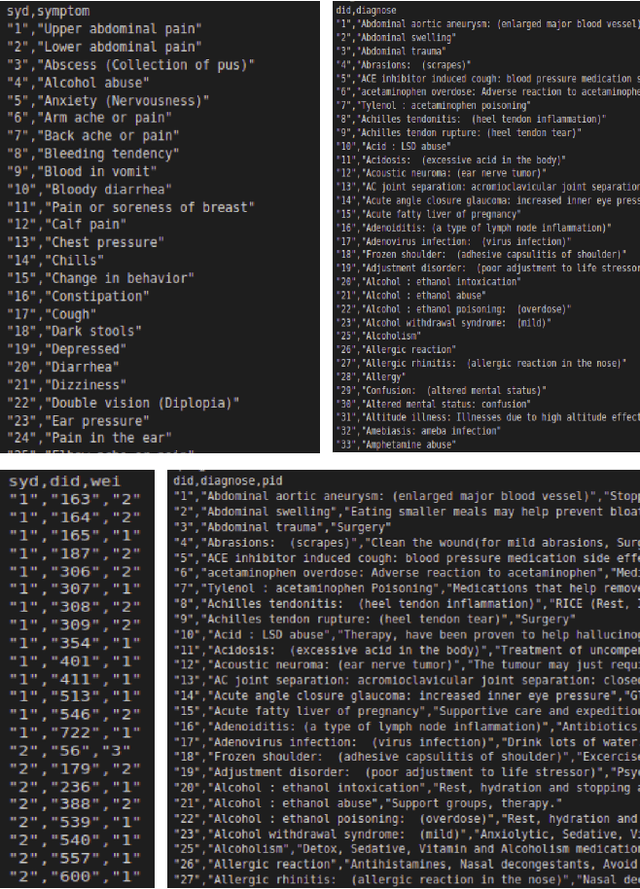

With the advancement in the technology sector spanning over every field, a huge influx of information is inevitable. Among all the opportunities that the advancements in the technology have brought, one of them is to propose efficient solutions for data retrieval. This means that from an enormous pile of data, the retrieval methods should allow the users to fetch the relevant and recent data over time. In the field of entertainment and e-commerce, recommender systems have been functioning to provide the aforementioned. Employing the same systems in the medical domain could definitely prove to be useful in variety of ways. Following this context, the goal of this paper is to propose collaborative filtering based recommender system in the healthcare sector to recommend remedies based on the symptoms experienced by the patients. Furthermore, a new dataset is developed consisting of remedies concerning various diseases to address the limited availability of the data. The proposed recommender system accepts the prognostic markers of a patient as the input and generates the best remedy course. With several experimental trials, the proposed model achieved promising results in recommending the possible remedy for given prognostic markers.
Graph Decoupling Attention Markov Networks for Semi-supervised Graph Node Classification
Apr 28, 2021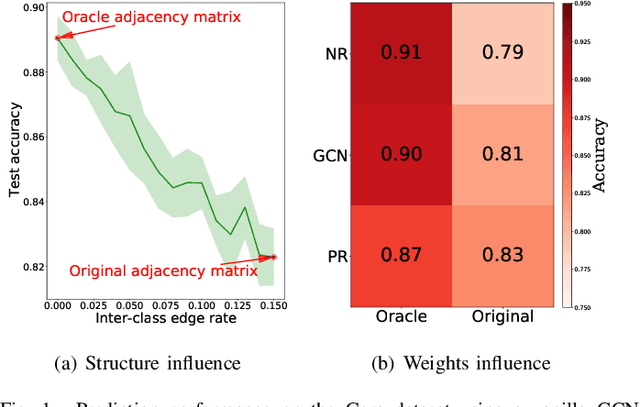
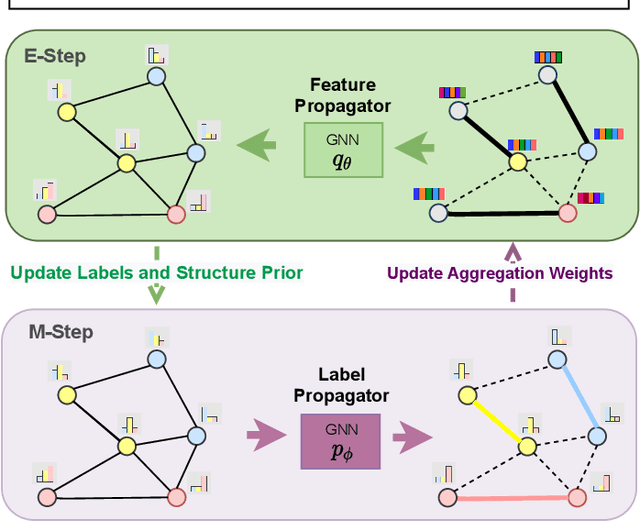
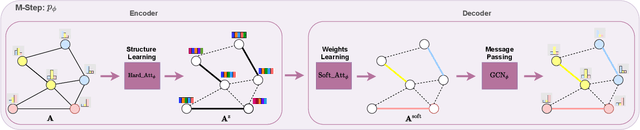
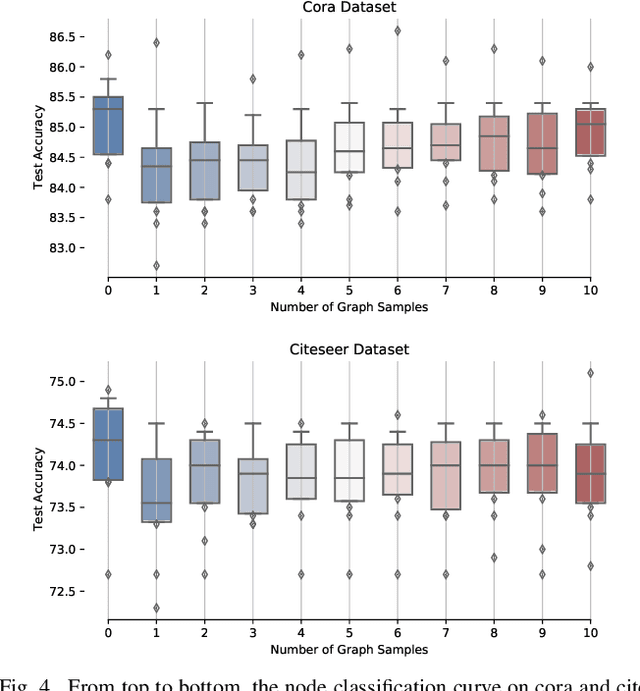
Graph neural networks (GNN) have been ubiquitous in graph learning tasks such as node classification. Most of GNN methods update the node embedding iteratively by aggregating its neighbors' information. However, they often suffer from negative disturbance, due to edges connecting nodes with different labels. One approach to alleviate this negative disturbance is to use attention, but current attention always considers feature similarity and suffers from the lack of supervision. In this paper, we consider the label dependency of graph nodes and propose a decoupling attention mechanism to learn both hard and soft attention. The hard attention is learned on labels for a refined graph structure with fewer inter-class edges. Its purpose is to reduce the aggregation's negative disturbance. The soft attention is learned on features maximizing the information gain by message passing over better graph structures. Moreover, the learned attention guides the label propagation and the feature propagation. Extensive experiments are performed on five well-known benchmark graph datasets to verify the effectiveness of the proposed method.
Information Theoretic Structure Learning with Confidence
Sep 13, 2016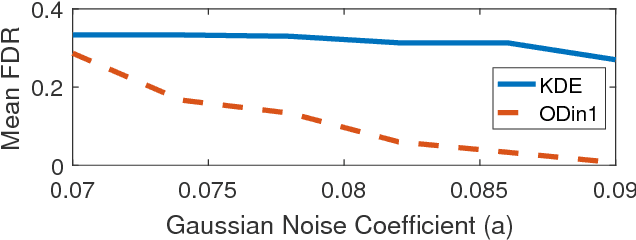
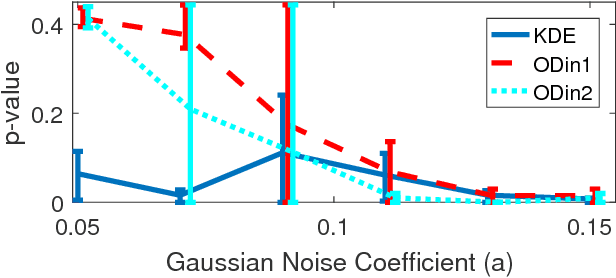
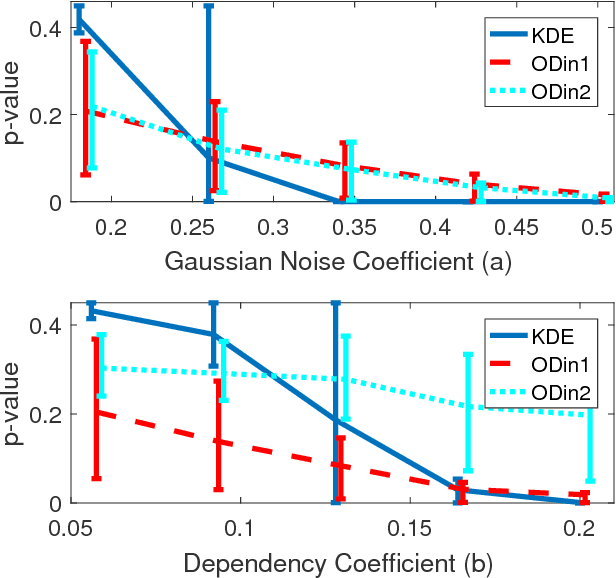
Information theoretic measures (e.g. the Kullback Liebler divergence and Shannon mutual information) have been used for exploring possibly nonlinear multivariate dependencies in high dimension. If these dependencies are assumed to follow a Markov factor graph model, this exploration process is called structure discovery. For discrete-valued samples, estimates of the information divergence over the parametric class of multinomial models lead to structure discovery methods whose mean squared error achieves parametric convergence rates as the sample size grows. However, a naive application of this method to continuous nonparametric multivariate models converges much more slowly. In this paper we introduce a new method for nonparametric structure discovery that uses weighted ensemble divergence estimators that achieve parametric convergence rates and obey an asymptotic central limit theorem that facilitates hypothesis testing and other types of statistical validation.
* 10 pages, 3 figures
Video Crowd Localization with Multi-focus Gaussian Neighbor Attention and a Large-Scale Benchmark
Jul 19, 2021
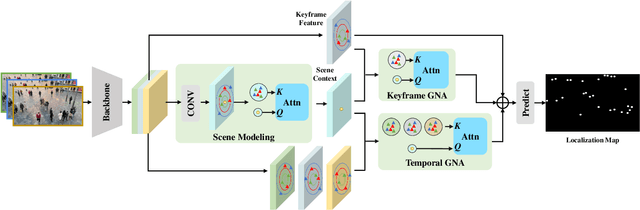

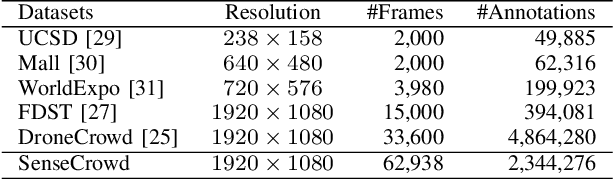
Video crowd localization is a crucial yet challenging task, which aims to estimate exact locations of human heads in the given crowded videos. To model spatial-temporal dependencies of human mobility, we propose a multi-focus Gaussian neighbor attention (GNA), which can effectively exploit long-range correspondences while maintaining the spatial topological structure of the input videos. In particular, our GNA can also capture the scale variation of human heads well using the equipped multi-focus mechanism. Based on the multi-focus GNA, we develop a unified neural network called GNANet to accurately locate head centers in video clips by fully aggregating spatial-temporal information via a scene modeling module and a context cross-attention module. Moreover, to facilitate future researches in this field, we introduce a large-scale crowded video benchmark named SenseCrowd, which consists of 60K+ frames captured in various surveillance scenarios and 2M+ head annotations. Finally, we conduct extensive experiments on three datasets including our SenseCrowd, and the experiment results show that the proposed method is capable to achieve state-of-the-art performance for both video crowd localization and counting. The code and the dataset will be released.