 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Multi-LLM Inference: Characterization and Analysis of LLM Routing and Hierarchical Techniques
Jun 06, 2025Recent progress in Language Models (LMs) has dramatically advanced the field of natural language processing (NLP), excelling at tasks like text generation, summarization, and question answering. However, their inference remains computationally expensive and energy intensive, especially in settings with limited hardware, power, or bandwidth. This makes it difficult to deploy LMs in mobile, edge, or cost sensitive environments. To address these challenges, recent approaches have introduced multi LLM intelligent model selection strategies that dynamically allocate computational resources based on query complexity -- using lightweight models for simpler queries and escalating to larger models only when necessary. This survey explores two complementary strategies for efficient LLM inference: (i) routing, which selects the most suitable model based on the query, and (ii) cascading or hierarchical inference (HI), which escalates queries through a sequence of models until a confident response is found. Both approaches aim to reduce computation by using lightweight models for simpler tasks while offloading only when needed. We provide a comparative analysis of these techniques across key performance metrics, discuss benchmarking efforts, and outline open challenges. Finally, we outline future research directions to enable faster response times, adaptive model selection based on task complexity, and scalable deployment across heterogeneous environments, making LLM based systems more efficient and accessible for real world applications.
AI and Vision based Autonomous Navigation of Nano-Drones in Partially-Known Environments
May 08, 2025The miniaturisation of sensors and processors, the advancements in connected edge intelligence, and the exponential interest in Artificial Intelligence are boosting the affirmation of autonomous nano-size drones in the Internet of Robotic Things ecosystem. However, achieving safe autonomous navigation and high-level tasks such as exploration and surveillance with these tiny platforms is extremely challenging due to their limited resources. This work focuses on enabling the safe and autonomous flight of a pocket-size, 30-gram platform called Crazyflie 2.1 in a partially known environment. We propose a novel AI-aided, vision-based reactive planning method for obstacle avoidance under the ambit of Integrated Sensing, Computing and Communication paradigm. We deal with the constraints of the nano-drone by splitting the navigation task into two parts: a deep learning-based object detector runs on the edge (external hardware) while the planning algorithm is executed onboard. The results show the ability to command the drone at $\sim8$ frames-per-second and a model performance reaching a COCO mean-average-precision of $60.8$. Field experiments demonstrate the feasibility of the solution with the drone flying at a top speed of $1$ m/s while steering away from an obstacle placed in an unknown position and reaching the target destination. The outcome highlights the compatibility of the communication delay and the model performance with the requirements of the real-time navigation task. We provide a feasible alternative to a fully onboard implementation that can be extended to autonomous exploration with nano-drones.
Quality of Control based Resource Dimensioning for Collaborative Edge Robotics
Nov 11, 2024



With the increasing focus on flexible automation, which emphasizes systems capable of adapting to varied tasks and conditions, exploring future deployments of cloud and edge-based network infrastructures in robotic systems becomes crucial. This work, examines how wireless solutions could support the shift from rigid, wired setups toward more adaptive, flexible automation in industrial environments. We provide a quality of control (QoC) based abstraction for robotic workloads, parameterized on loop latency and reliability, and jointly optimize system performance. The setup involves collaborative robots working on distributed tasks, underscoring how wireless communication can enable more dynamic coordination in flexible automation systems. We use our abstraction to optimally maximize the QoC ensuring efficient operation even under varying network conditions. Additionally, our solution allocates the communication resources in time slots, optimizing the balance between communication and control costs. Our simulation results highlight that minimizing the delay in the system may not always ensure the best QoC but can lead to substantial gains in QoC if delays are sometimes relaxed, allowing more packets to be delivered reliably.
Predictability of Performance in Communication Networks Under Markovian Dynamics
Aug 26, 2024



With the emergence of time-critical applications in modern communication networks, there is a growing demand for proactive network adaptation and quality of service (QoS) prediction. However, a fundamental question remains largely unexplored: how can we quantify and achieve more predictable communication systems in terms of performance? To address this gap, this paper introduces a theoretical framework for defining and analyzing predictability in communication systems, with a focus on the impact of observations for performance forecasting. We establish a mathematical definition of predictability based on the total variation distance between forecast and marginal performance distributions. A system is deemed unpredictable when the forecast distribution, providing the most comprehensive characterization of future states using all accessible information, is indistinguishable from the marginal distribution, which depicts the system's behavior without any observational input. This framework is applied to multi-hop systems under Markovian conditions, with a detailed analysis of Geo/Geo/1 queuing models in both single-hop and multi-hop scenarios. We derive exact and approximate expressions for predictability in these systems, as well as upper bounds based on spectral analysis of the underlying Markov chains. Our results have implications for the design of efficient monitoring and prediction mechanisms in future communication networks aiming to provide deterministic services.
ExPECA: An Experimental Platform for Trustworthy Edge Computing Applications
Nov 02, 2023



This paper presents ExPECA, an edge computing and wireless communication research testbed designed to tackle two pressing challenges: comprehensive end-to-end experimentation and high levels of experimental reproducibility. Leveraging OpenStack-based Chameleon Infrastructure (CHI) framework for its proven flexibility and ease of operation, ExPECA is located in a unique, isolated underground facility, providing a highly controlled setting for wireless experiments. The testbed is engineered to facilitate integrated studies of both communication and computation, offering a diverse array of Software-Defined Radios (SDR) and Commercial Off-The-Shelf (COTS) wireless and wired links, as well as containerized computational environments. We exemplify the experimental possibilities of the testbed using OpenRTiST, a latency-sensitive, bandwidth-intensive application, and analyze its performance. Lastly, we highlight an array of research domains and experimental setups that stand to gain from ExPECA's features, including closed-loop applications and time-sensitive networking.
Data-Driven Latency Probability Prediction for Wireless Networks: Focusing on Tail Probabilities
Jul 20, 2023



With the emergence of new application areas, such as cyber-physical systems and human-in-the-loop applications, there is a need to guarantee a certain level of end-to-end network latency with extremely high reliability, e.g., 99.999%. While mechanisms specified under IEEE 802.1as time-sensitive networking (TSN) can be used to achieve these requirements for switched Ethernet networks, implementing TSN mechanisms in wireless networks is challenging due to their stochastic nature. To conform the wireless link to a reliability level of 99.999%, the behavior of extremely rare outliers in the latency probability distribution, or the tail of the distribution, must be analyzed and controlled. This work proposes predicting the tail of the latency distribution using state-of-the-art data-driven approaches, such as mixture density networks (MDN) and extreme value mixture models, to estimate the likelihood of rare latencies conditioned on the network parameters, which can be used to make more informed decisions in wireless transmission. Actual latency measurements of IEEE 802.11g (WiFi), commercial private and a software-defined 5G network are used to benchmark the proposed approaches and evaluate their sensitivities concerning the tail probabilities.
Semantically Optimized End-to-End Learning for Positional Telemetry in Vehicular Scenarios
May 05, 2023



End-to-end learning for wireless communications has recently attracted much interest in the community, owing to the emergence of deep learning-based architectures for the physical layer. Neural network-based autoencoders have been proposed as potential replacements of traditional model-based transmitter and receiver structures. Such a replacement primarily provides an unprecedented level of flexibility, allowing to tune such emerging physical layer network stacks in many different directions. The semantic relevance of the transmitted messages is one of those directions. In this paper, we leverage a specific semantic relationship between the occurrence of a message (the source), and the channel statistics. Such a scenario could be illustrated for instance, in vehicular communications where the distance is to be conveyed between a leader and a follower. We study two autoencoder approaches where these special circumstances are exploited. We then evaluate our autoencoders, showing through the simulations that the semantic optimization can achieve significant improvements in the BLER and RMSE for vehicular communications leading to considerably reduced risks and needs for message re-transmissions.
The Case for Hierarchical Deep Learning Inference at the Network Edge
Apr 23, 2023



Resource-constrained Edge Devices (EDs), e.g., IoT sensors and microcontroller units, are expected to make intelligent decisions using Deep Learning (DL) inference at the edge of the network. Toward this end, there is a significant research effort in developing tinyML models - Deep Learning (DL) models with reduced computation and memory storage requirements - that can be embedded on these devices. However, tinyML models have lower inference accuracy. On a different front, DNN partitioning and inference offloading techniques were studied for distributed DL inference between EDs and Edge Servers (ESs). In this paper, we explore Hierarchical Inference (HI), a novel approach proposed by Vishnu et al. 2023, arXiv:2304.00891v1 , for performing distributed DL inference at the edge. Under HI, for each data sample, an ED first uses a local algorithm (e.g., a tinyML model) for inference. Depending on the application, if the inference provided by the local algorithm is incorrect or further assistance is required from large DL models on edge or cloud, only then the ED offloads the data sample. At the outset, HI seems infeasible as the ED, in general, cannot know if the local inference is sufficient or not. Nevertheless, we present the feasibility of implementing HI for machine fault detection and image classification applications. We demonstrate its benefits using quantitative analysis and argue that using HI will result in low latency, bandwidth savings, and energy savings in edge AI systems.
Online Algorithms for Hierarchical Inference in Deep Learning applications at the Edge
Apr 03, 2023



We consider a resource-constrained Edge Device (ED) embedded with a small-size ML model (S-ML) for a generic classification application, and an Edge Server (ES) that hosts a large-size ML model (L-ML). Since the inference accuracy of S-ML is lower than that of the L-ML, offloading all the data samples to the ES results in high inference accuracy, but it defeats the purpose of embedding S-ML on the ED and deprives the benefits of reduced latency, bandwidth savings, and energy efficiency of doing local inference. To get the best out of both worlds, i.e., the benefits of doing inference on the ED and the benefits of doing inference on ES, we explore the idea of Hierarchical Inference (HI), wherein S-ML inference is only accepted when it is correct, otherwise the data sample is offloaded for L-ML inference. However, the ideal implementation of HI is infeasible as the correctness of the S-ML inference is not known to the ED. We thus propose an online meta-learning framework to predict the correctness of the S-ML inference. The resulting online learning problem turns out to be a Prediction with Expert Advice (PEA) problem with continuous expert space. We consider the full feedback scenario, where the ED receives feedback on the correctness of the S-ML once it accepts the inference, and the no-local feedback scenario, where the ED does not receive the ground truth for the classification, and propose the HIL-F and HIL-N algorithms and prove a regret bound that is sublinear with the number of data samples. We evaluate and benchmark the performance of the proposed algorithms for image classification applications using four datasets, namely, Imagenette, Imagewoof, MNIST, and CIFAR-10.
NeuroRAN: Rethinking Virtualization for AI-native Radio Access Networks in 6G
Apr 16, 2021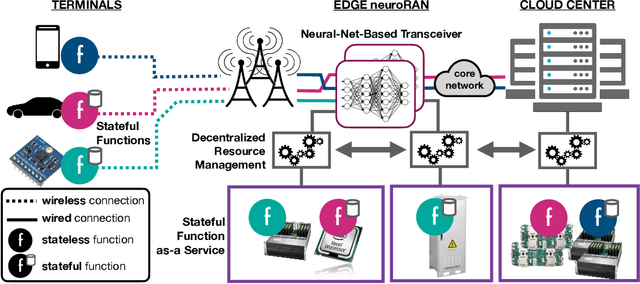
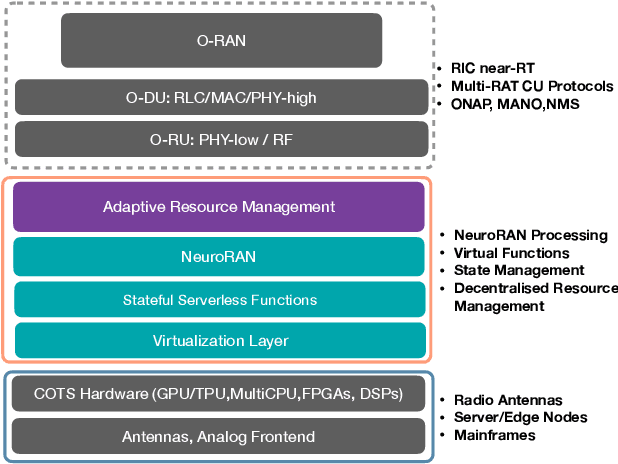
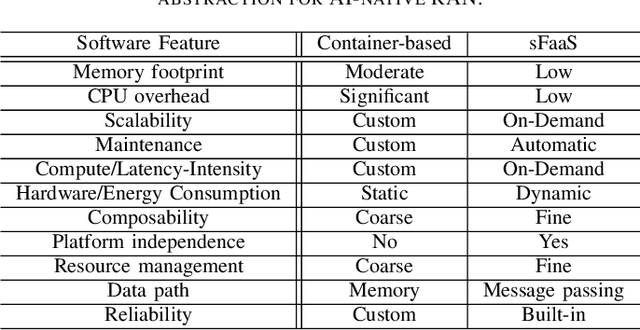
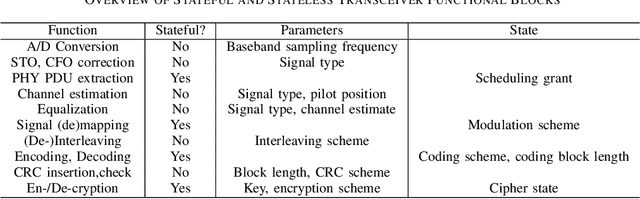
Network softwarization has revolutionized the architecture of cellular wireless networks. State-of-the-art container based virtual radio access networks (vRAN) provide enormous flexibility and reduced life cycle management costs, but they also come with prohibitive energy consumption. We argue that for future AI-native wireless networks to be flexible and energy efficient, there is a need for a new abstraction in network softwarization that caters for neural network type of workloads and allows a large degree of service composability. In this paper we present the NeuroRAN architecture, which leverages stateful function as a user facing execution model, and is complemented with virtualized resources and decentralized resource management. We show that neural network based implementations of common transceiver functional blocks fit the proposed architecture, and we discuss key research challenges related to compilation and code generation, resource management, reliability and security.