 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiscale Wavelet Transfer Entropy with Application to Corticomuscular Coupling Analysis
Aug 09, 2021
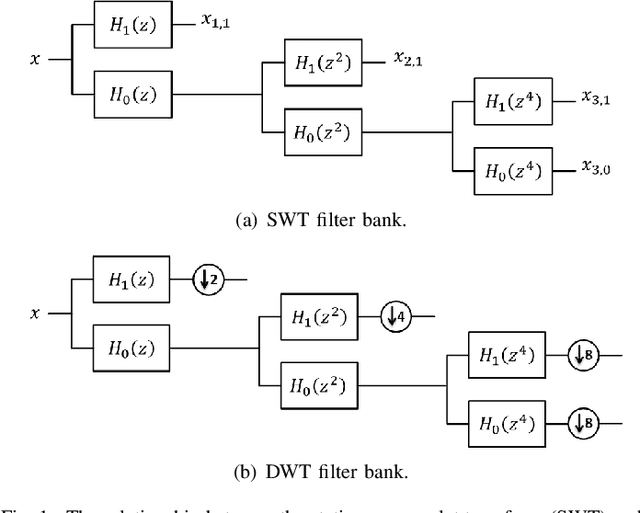
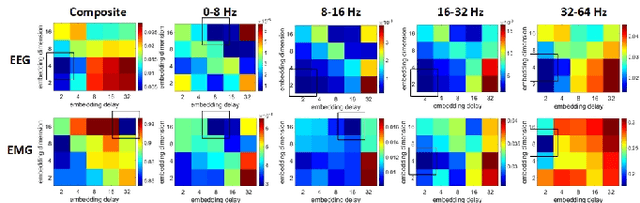
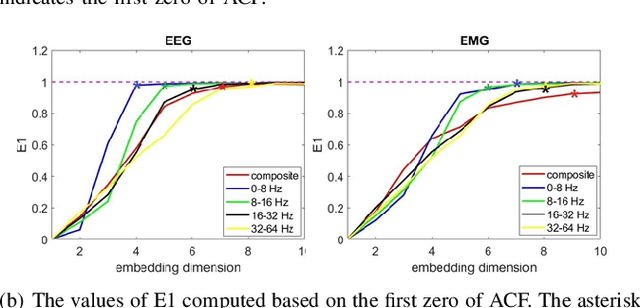
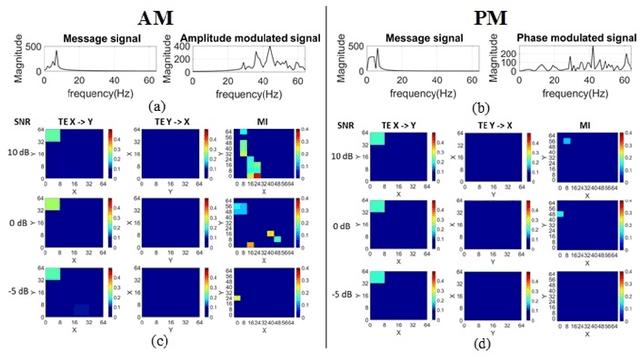
Objective: Functional coupling between the motor cortex and muscle activity is commonly detected and quantified by cortico-muscular coherence (CMC) or Granger causality (GC) analysis, which are applicable only to linear couplings and are not sufficiently sensitive: some healthy subjects show no significant CMC and GC, and yet have good motor skills. The objective of this work is to develop measures of functional cortico-muscular coupling that have improved sensitivity and are capable of detecting both linear and non-linear interactions. Methods: A multiscale wavelet transfer entropy (TE) methodology is proposed. The methodology relies on a dyadic stationary wavelet transform to decompose electroencephalogram (EEG) and electromyogram (EMG) signals into functional bands of neural oscillations. Then, it applies TE analysis based on a range of embedding delay vectors to detect and quantify intra- and cross-frequency band cortico-muscular coupling at different time scales. Results: Our experiments with neurophysiological signals substantiate the potential of the developed methodologies for detecting and quantifying information flow between EEG and EMG signals for subjects with and without significant CMC or GC, including non-linear cross-frequency interactions, and interactions across different temporal scales. The obtained results are in agreement with the underlying sensorimotor neurophysiology. Conclusion: These findings suggest that the concept of multiscale wavelet TE provides a comprehensive framework for analysing cortex-muscle interactions. Significance: The proposed methodologies will enable developing novel insights into movement control and neurophysiological processes more generally.
Sparse Joint Transmission for Cloud Radio Access Networks with Limited Fronthaul Capacity
Jul 29, 2021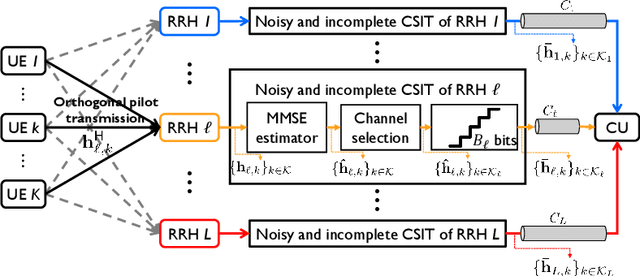
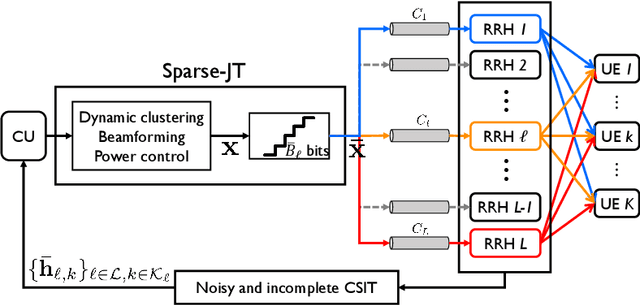
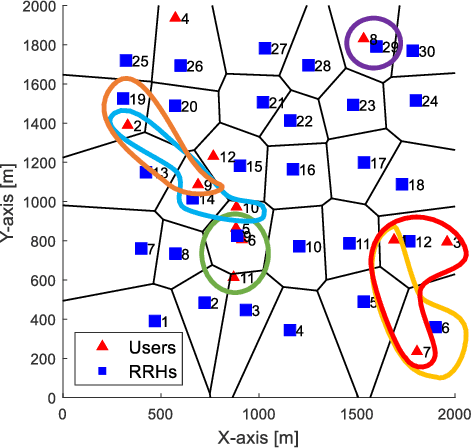
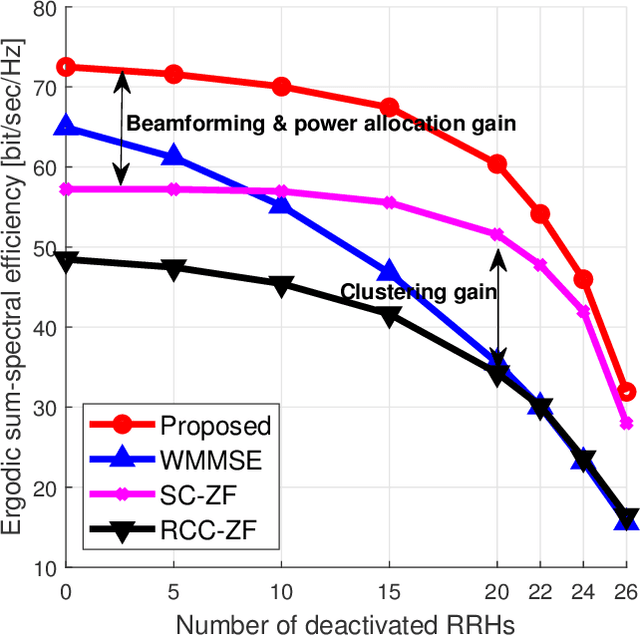
A cloud radio access network (C-RAN) is a promising cellular network, wherein densely deployed multi-antenna remote-radio-heads (RRHs) jointly serve many users using the same time-frequency resource. By extremely high signaling overheads for both channel state information (CSI) acquisition and data sharing at a baseband unit (BBU), finding a joint transmission strategy with a significantly reduced signaling overhead is indispensable to achieve the cooperation gain in practical C-RANs. In this paper, we present a novel sparse joint transmission (sparse-JT) method for C-RANs, where the number of transmit antennas per unit area is much larger than the active downlink user density. Considering the effects of noisy-and-incomplete CSI and the quantization errors in data sharing by a finite-rate fronthaul capacity, the key innovation of sparse-JT is to find a joint solution for cooperative RRH clusters, beamforming vectors, and power allocation to maximize a lower bound of the sum-spectral efficiency under the sparsity constraint of active RRHs. To find such a solution, we present a computationally efficient algorithm that guarantees to find a local-optimal solution for a relaxed sum-spectral efficiency maximization problem. By system-level simulations, we exhibit that sparse-JT provides significant gains in ergodic spectral efficiencies compared to existing joint transmissions.
Grid Partitioned Attention: Efficient TransformerApproximation with Inductive Bias for High Resolution Detail Generation
Jul 08, 2021
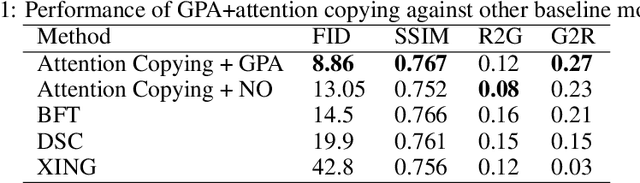

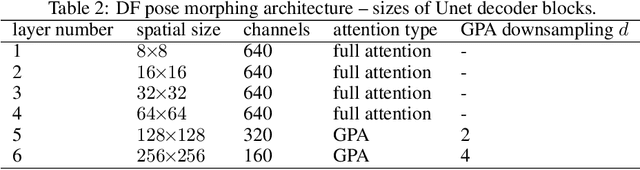
Attention is a general reasoning mechanism than can flexibly deal with image information, but its memory requirements had made it so far impractical for high resolution image generation. We present Grid Partitioned Attention (GPA), a new approximate attention algorithm that leverages a sparse inductive bias for higher computational and memory efficiency in image domains: queries attend only to few keys, spatially close queries attend to close keys due to correlations. Our paper introduces the new attention layer, analyzes its complexity and how the trade-off between memory usage and model power can be tuned by the hyper-parameters.We will show how such attention enables novel deep learning architectures with copying modules that are especially useful for conditional image generation tasks like pose morphing. Our contributions are (i) algorithm and code1of the novel GPA layer, (ii) a novel deep attention-copying architecture, and (iii) new state-of-the art experimental results in human pose morphing generation benchmarks.
IDOL-Net: An Interactive Dual-Domain Parallel Network for CT Metal Artifact Reduction
Apr 03, 2021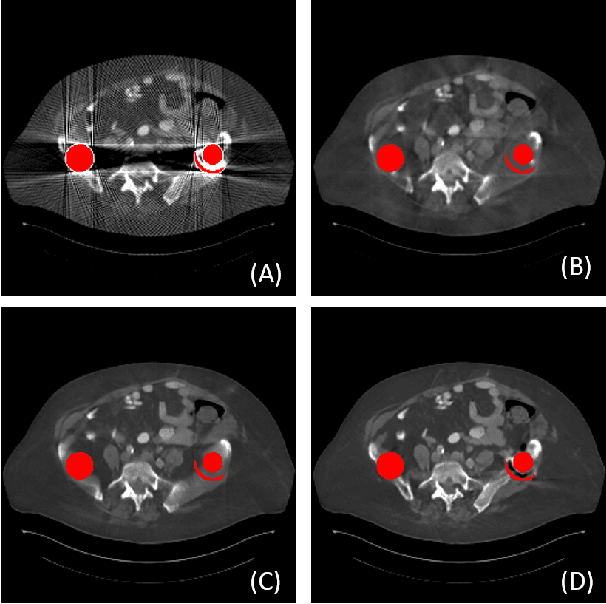
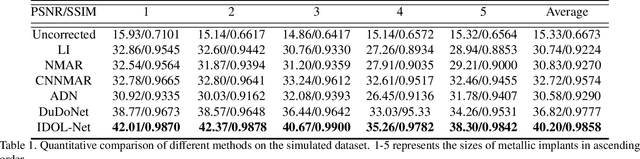
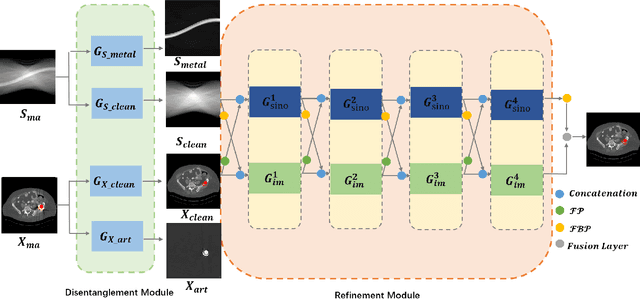

Due to the presence of metallic implants, the imaging quality of computed tomography (CT) would be heavily degraded. With the rapid development of deep learning, several network models have been proposed for metal artifact reduction (MAR). Since the dual-domain MAR methods can leverage the hybrid information from both sinogram and image domains, they have significantly improved the performance compared to single-domain methods. However,current dual-domain methods usually operate on both domains in a specific order, which implicitly imposes a certain priority prior into MAR and may ignore the latent information interaction between both domains. To address this problem, in this paper, we propose a novel interactive dualdomain parallel network for CT MAR, dubbed as IDOLNet. Different from existing dual-domain methods, the proposed IDOL-Net is composed of two modules. The disentanglement module is utilized to generate high-quality prior sinogram and image as the complementary inputs. The follow-up refinement module consists of two parallel and interactive branches that simultaneously operate on image and sinogram domain, fully exploiting the latent information interaction between both domains. The simulated and clinical results demonstrate that the proposed IDOL-Net outperforms several state-of-the-art models in both qualitative and quantitative aspects.
Boosting Crowd Counting with Transformers
May 23, 2021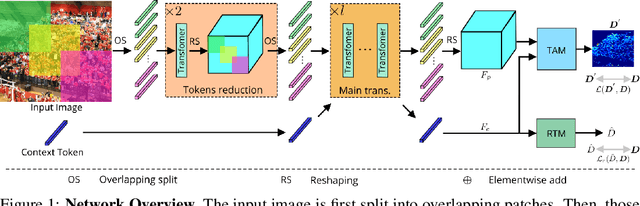
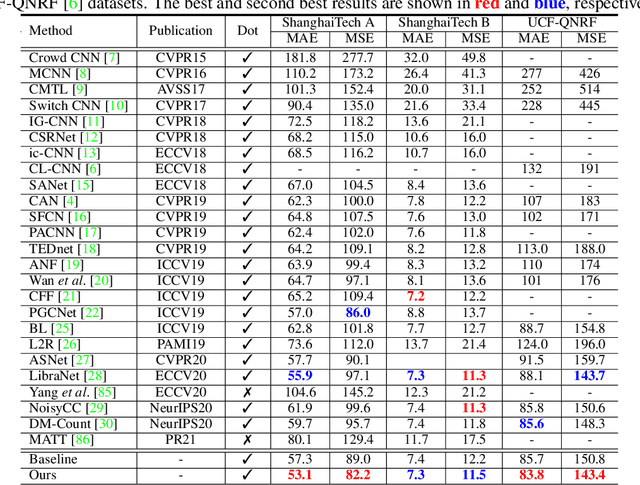
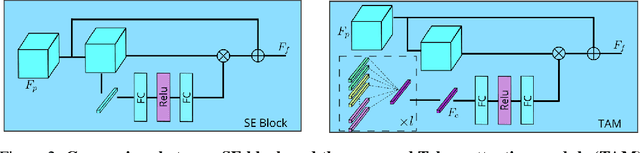
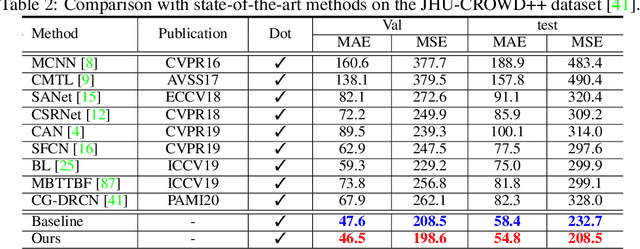
Significant progress on the crowd counting problem has been achieved by integrating larger context into convolutional neural networks (CNNs). This indicates that global scene context is essential, despite the seemingly bottom-up nature of the problem. This may be explained by the fact that context knowledge can adapt and improve local feature extraction to a given scene. In this paper, we therefore investigate the role of global context for crowd counting. Specifically, a pure transformer is used to extract features with global information from overlapping image patches. Inspired by classification, we add a context token to the input sequence, to facilitate information exchange with tokens corresponding to image patches throughout transformer layers. Due to the fact that transformers do not explicitly model the tried-and-true channel-wise interactions, we propose a token-attention module (TAM) to recalibrate encoded features through channel-wise attention informed by the context token. Beyond that, it is adopted to predict the total person count of the image through regression-token module (RTM). Extensive experiments demonstrate that our method achieves state-of-the-art performance on various datasets, including ShanghaiTech, UCF-QNRF, JHU-CROWD++ and NWPU. On the large-scale JHU-CROWD++ dataset, our method improves over the previous best results by 26.9% and 29.9% in terms of MAE and MSE, respectively.
Determining the Credibility of Science Communication
May 30, 2021

Most work on scholarly document processing assumes that the information processed is trustworthy and factually correct. However, this is not always the case. There are two core challenges, which should be addressed: 1) ensuring that scientific publications are credible -- e.g. that claims are not made without supporting evidence, and that all relevant supporting evidence is provided; and 2) that scientific findings are not misrepresented, distorted or outright misreported when communicated by journalists or the general public. I will present some first steps towards addressing these problems and outline remaining challenges.
Did the Cat Drink the Coffee? Challenging Transformers with Generalized Event Knowledge
Jul 22, 2021
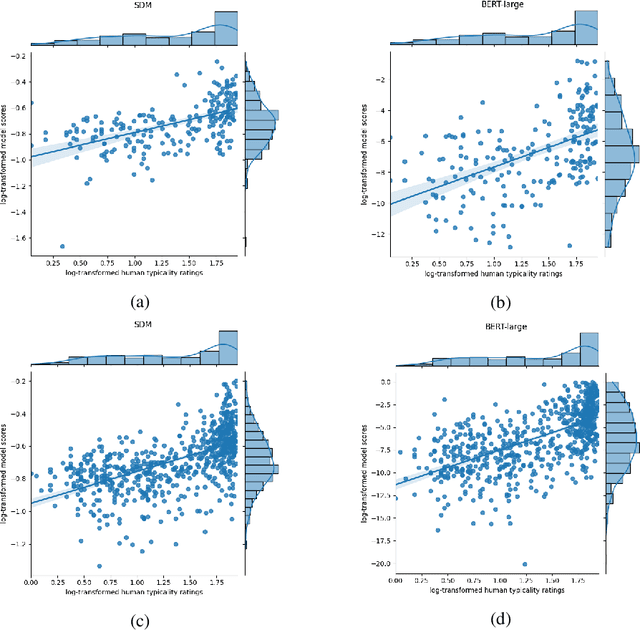

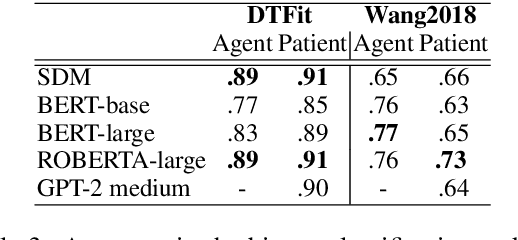
Prior research has explored the ability of computational models to predict a word semantic fit with a given predicate. While much work has been devoted to modeling the typicality relation between verbs and arguments in isolation, in this paper we take a broader perspective by assessing whether and to what extent computational approaches have access to the information about the typicality of entire events and situations described in language (Generalized Event Knowledge). Given the recent success of Transformers Language Models (TLMs), we decided to test them on a benchmark for the \textit{dynamic estimation of thematic fit}. The evaluation of these models was performed in comparison with SDM, a framework specifically designed to integrate events in sentence meaning representations, and we conducted a detailed error analysis to investigate which factors affect their behavior. Our results show that TLMs can reach performances that are comparable to those achieved by SDM. However, additional analysis consistently suggests that TLMs do not capture important aspects of event knowledge, and their predictions often depend on surface linguistic features, such as frequent words, collocations and syntactic patterns, thereby showing sub-optimal generalization abilities.
Representation Learning for Heterogeneous Information Networks via Embedding Events
Jan 29, 2019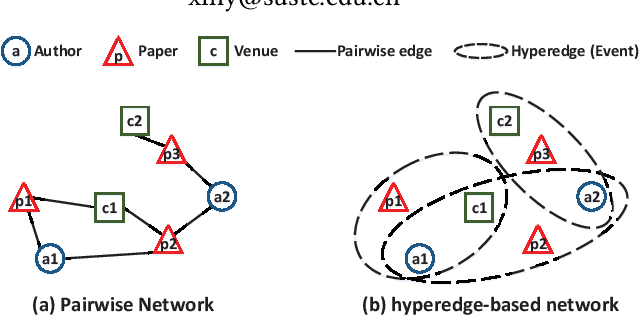

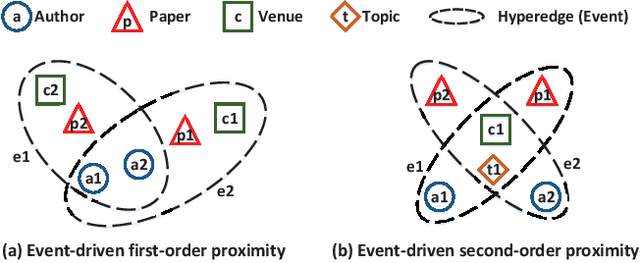
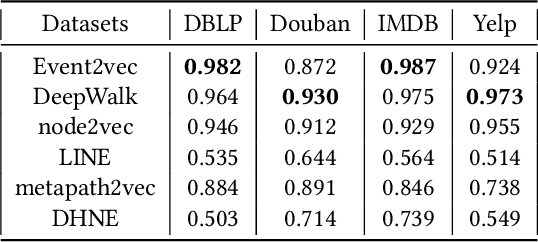
Network representation learning (NRL) has been widely used to help analyze large-scale networks through mapping original networks into a low-dimensional vector space. However, existing NRL methods ignore the impact of properties of relations on the object relevance in heterogeneous information networks (HINs). To tackle this issue, this paper proposes a new NRL framework, called Event2vec, for HINs to consider both quantities and properties of relations during the representation learning process. Specifically, an event (i.e., a complete semantic unit) is used to represent the relation among multiple objects, and both event-driven first-order and second-order proximities are defined to measure the object relevance according to the quantities and properties of relations. We theoretically prove how event-driven proximities can be preserved in the embedding space by Event2vec, which utilizes event embeddings to facilitate learning the object embeddings. Experimental studies demonstrate the advantages of Event2vec over state-of-the-art algorithms on four real-world datasets and three network analysis tasks (including network reconstruction, link prediction, and node classification).
Information Recovery in Shuffled Graphs via Graph Matching
Sep 27, 2017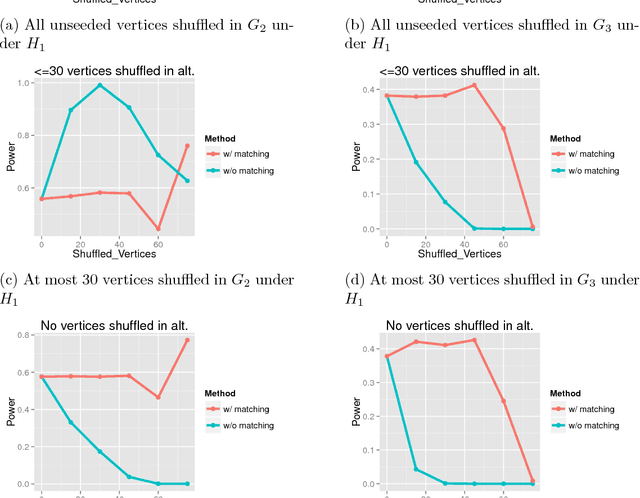
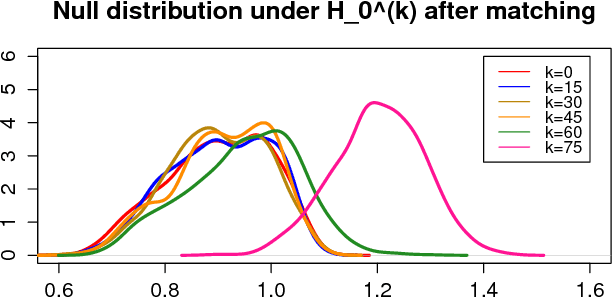
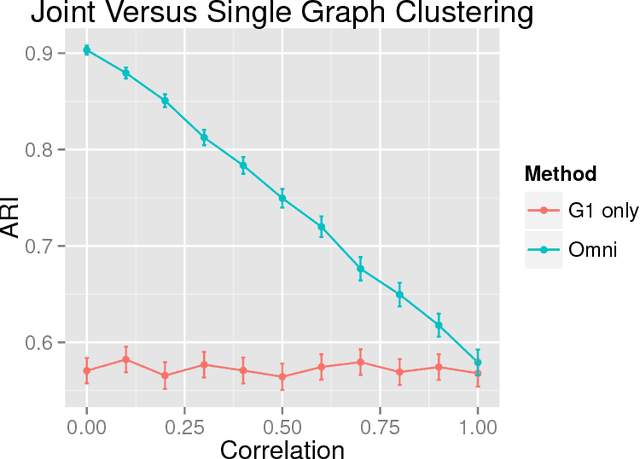
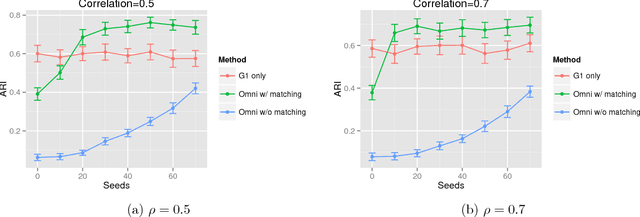
While many multiple graph inference methodologies operate under the implicit assumption that an explicit vertex correspondence is known across the vertex sets of the graphs, in practice these correspondences may only be partially or errorfully known. Herein, we provide an information theoretic foundation for understanding the practical impact that errorfully observed vertex correspondences can have on subsequent inference, and the capacity of graph matching methods to recover the lost vertex alignment and inferential performance. Working in the correlated stochastic blockmodel setting, we establish a duality between the loss of mutual information due to an errorfully observed vertex correspondence and the ability of graph matching algorithms to recover the true correspondence across graphs. In the process, we establish a phase transition for graph matchability in terms of the correlation across graphs, and we conjecture the analogous phase transition for the relative information loss due to shuffling vertex labels. We demonstrate the practical effect that graph shuffling---and matching---can have on subsequent inference, with examples from two sample graph hypothesis testing and joint spectral graph clustering.
Deep learning for surrogate modelling of 2D mantle convection
Aug 23, 2021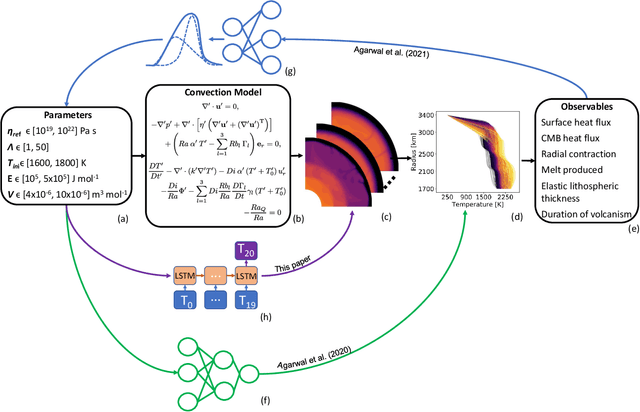
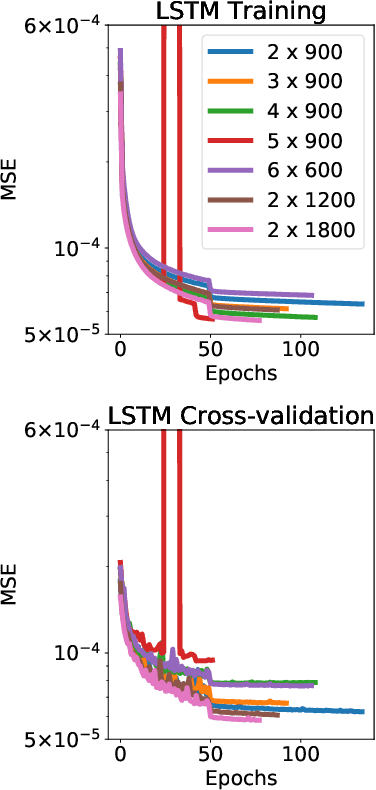
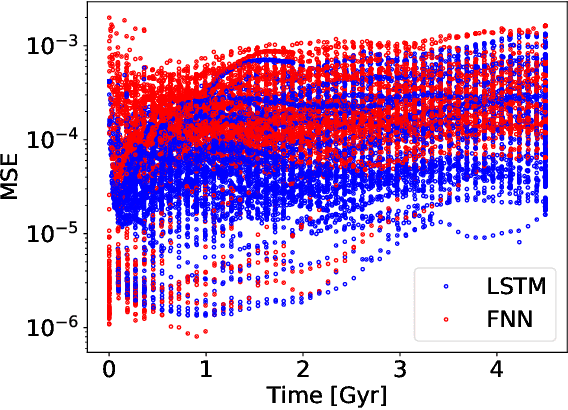
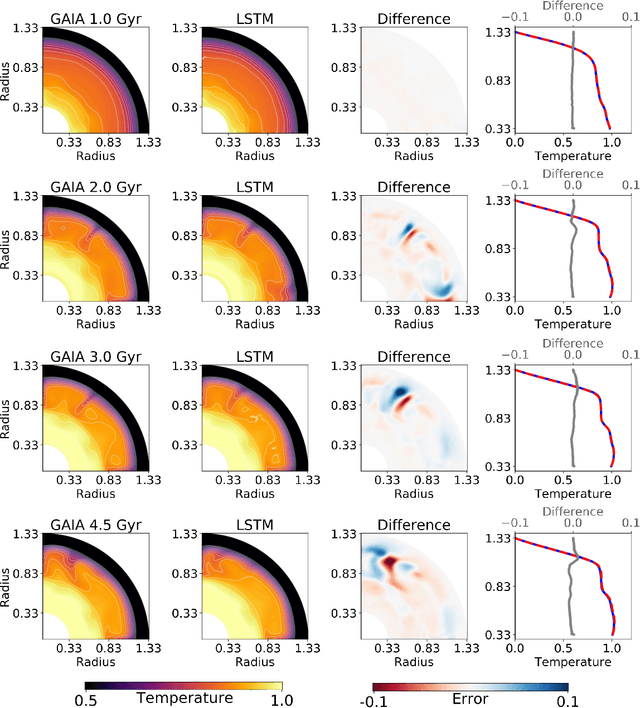
Traditionally, 1D models based on scaling laws have been used to parameterized convective heat transfer rocks in the interior of terrestrial planets like Earth, Mars, Mercury and Venus to tackle the computational bottleneck of high-fidelity forward runs in 2D or 3D. However, these are limited in the amount of physics they can model (e.g. depth dependent material properties) and predict only mean quantities such as the mean mantle temperature. We recently showed that feedforward neural networks (FNN) trained using a large number of 2D simulations can overcome this limitation and reliably predict the evolution of entire 1D laterally-averaged temperature profile in time for complex models [Agarwal et al. 2020]. We now extend that approach to predict the full 2D temperature field, which contains more information in the form of convection structures such as hot plumes and cold downwellings. Using a dataset of 10,525 two-dimensional simulations of the thermal evolution of the mantle of a Mars-like planet, we show that deep learning techniques can produce reliable parameterized surrogates (i.e. surrogates that predict state variables such as temperature based only on parameters) of the underlying partial differential equations. We first use convolutional autoencoders to compress the temperature fields by a factor of 142 and then use FNN and long-short term memory networks (LSTM) to predict the compressed fields. On average, the FNN predictions are 99.30% and the LSTM predictions are 99.22% accurate with respect to unseen simulations. Proper orthogonal decomposition (POD) of the LSTM and FNN predictions shows that despite a lower mean absolute relative accuracy, LSTMs capture the flow dynamics better than FNNs. When summed, the POD coefficients from FNN predictions and from LSTM predictions amount to 96.51% and 97.66% relative to the coefficients of the original simulations, respectively.