 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid Partitioned Attention: Efficient TransformerApproximation with Inductive Bias for High Resolution Detail Generation
Jul 08, 2021
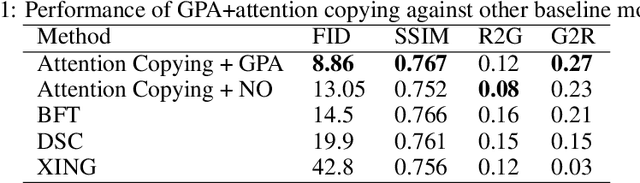

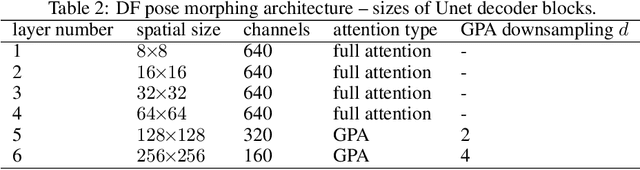
Attention is a general reasoning mechanism than can flexibly deal with image information, but its memory requirements had made it so far impractical for high resolution image generation. We present Grid Partitioned Attention (GPA), a new approximate attention algorithm that leverages a sparse inductive bias for higher computational and memory efficiency in image domains: queries attend only to few keys, spatially close queries attend to close keys due to correlations. Our paper introduces the new attention layer, analyzes its complexity and how the trade-off between memory usage and model power can be tuned by the hyper-parameters.We will show how such attention enables novel deep learning architectures with copying modules that are especially useful for conditional image generation tasks like pose morphing. Our contributions are (i) algorithm and code1of the novel GPA layer, (ii) a novel deep attention-copying architecture, and (iii) new state-of-the art experimental results in human pose morphing generation benchmarks.
An LSTM-Based Dynamic Customer Model for Fashion Recommendation
Aug 24, 2017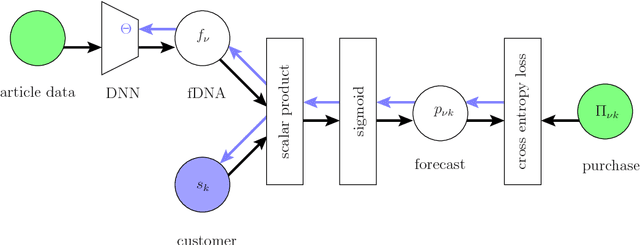
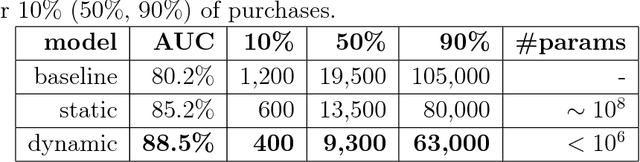
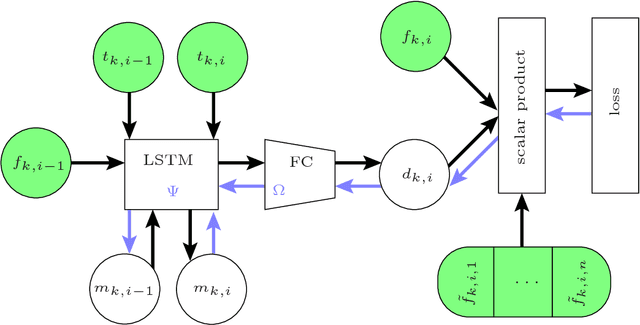
Online fashion sales present a challenging use case for personalized recommendation: Stores offer a huge variety of items in multiple sizes. Small stocks, high return rates, seasonality, and changing trends cause continuous turnover of articles for sale on all time scales. Customers tend to shop rarely, but often buy multiple items at once. We report on backtest experiments with sales data of 100k frequent shoppers at Zalando, Europe's leading online fashion platform. To model changing customer and store environments, our recommendation method employs a pair of neural networks: To overcome the cold start problem, a feedforward network generates article embeddings in "fashion space," which serve as input to a recurrent neural network that predicts a style vector in this space for each client, based on their past purchase sequence. We compare our results with a static collaborative filtering approach, and a popularity ranking baseline.
Fashion DNA: Merging Content and Sales Data for Recommendation and Article Mapping
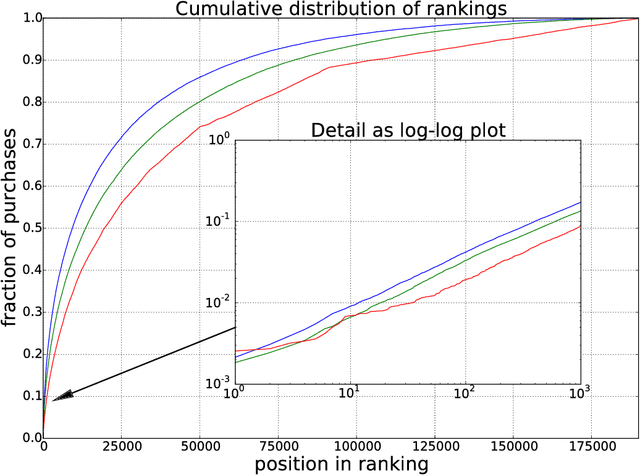
Sep 08, 2016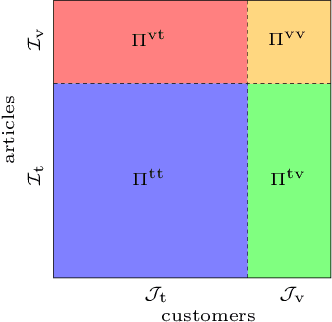
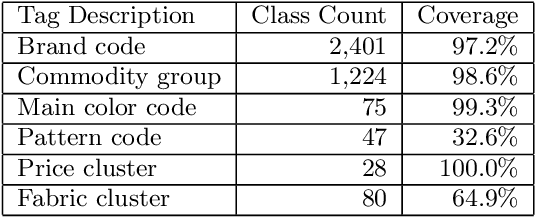
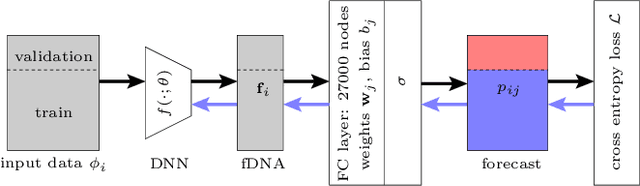

We present a method to determine Fashion DNA, coordinate vectors locating fashion items in an abstract space. Our approach is based on a deep neural network architecture that ingests curated article information such as tags and images, and is trained to predict sales for a large set of frequent customers. In the process, a dual space of customer style preferences naturally arises. Interpretation of the metric of these spaces is straightforward: The product of Fashion DNA and customer style vectors yields the forecast purchase likelihood for the customer-item pair, while the angle between Fashion DNA vectors is a measure of item similarity. Importantly, our models are able to generate unbiased purchase probabilities for fashion items based solely on article information, even in absence of sales data, thus circumventing the "cold-start problem" of collaborative recommendation approaches. Likewise, it generalizes easily and reliably to customers outside the training set. We experiment with Fashion DNA models based on visual and/or tag item data, evaluate their recommendation power, and discuss the resulting article similarities.