 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Range Image-based Pole Extractor for Long-term LiDAR Localization in Urban Environments
Aug 19, 2021
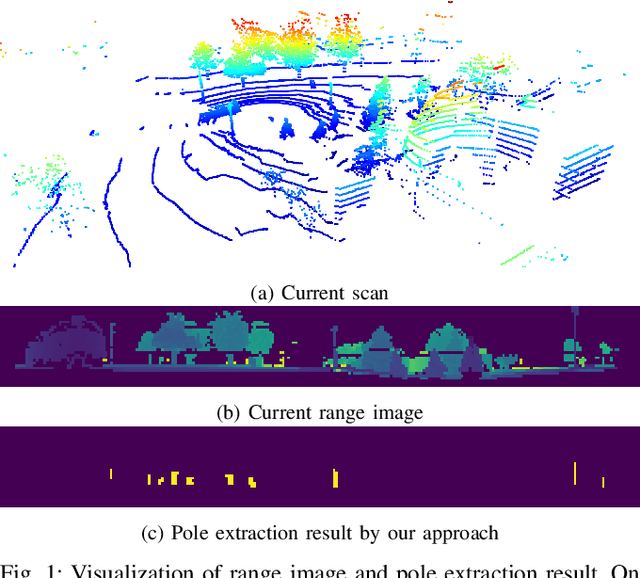
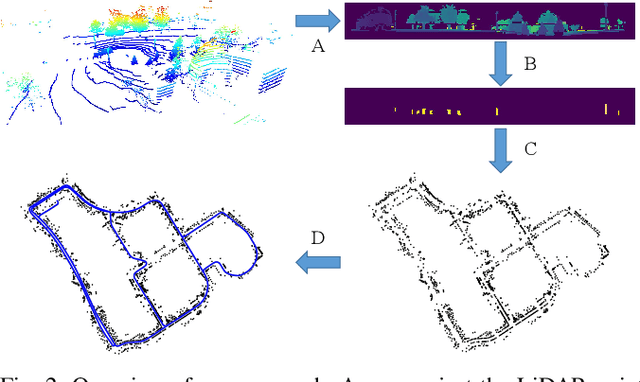
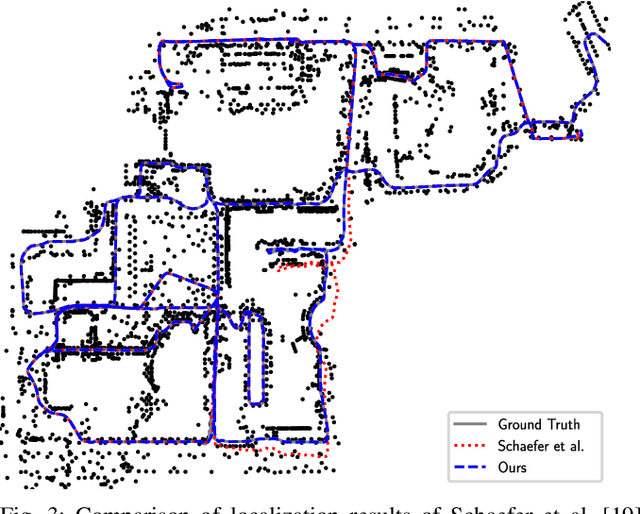
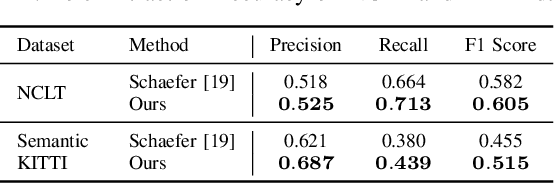
Reliable and accurate localization is crucial for mobile autonomous systems. Pole-like objects, such as traffic signs, poles, lamps, etc., are ideal landmarks for localization in urban environments due to their local distinctiveness and long-term stability. In this paper, we present a novel, accurate, and fast pole extraction approach that runs online and has little computational demands such that this information can be used for a localization system. Our method performs all computations directly on range images generated from 3D LiDAR scans, which avoids processing 3D point cloud explicitly and enables fast pole extraction for each scan. We test the proposed pole extraction and localization approach on different datasets with different LiDAR scanners, weather conditions, routes, and seasonal changes. The experimental results show that our approach outperforms other state-of-the-art approaches, while running online without a GPU. Besides, we release our pole dataset to the public for evaluating the performance of pole extractor, as well as the implementation of our approach.
HoroPCA: Hyperbolic Dimensionality Reduction via Horospherical Projections
Jun 07, 2021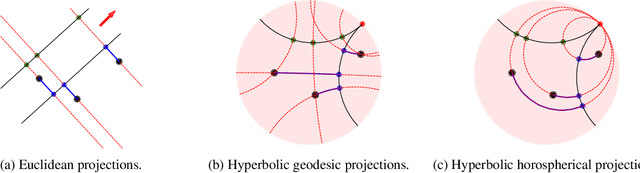
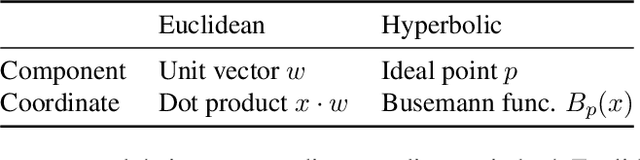
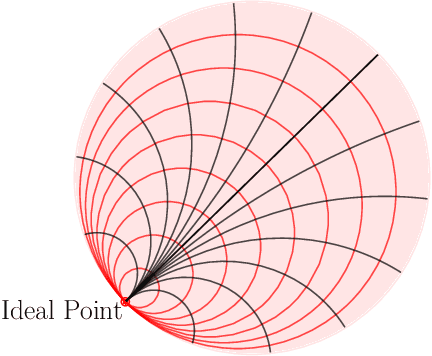
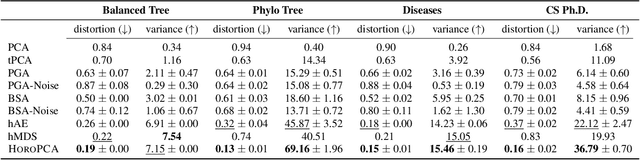
This paper studies Principal Component Analysis (PCA) for data lying in hyperbolic spaces. Given directions, PCA relies on: (1) a parameterization of subspaces spanned by these directions, (2) a method of projection onto subspaces that preserves information in these directions, and (3) an objective to optimize, namely the variance explained by projections. We generalize each of these concepts to the hyperbolic space and propose HoroPCA, a method for hyperbolic dimensionality reduction. By focusing on the core problem of extracting principal directions, HoroPCA theoretically better preserves information in the original data such as distances, compared to previous generalizations of PCA. Empirically, we validate that HoroPCA outperforms existing dimensionality reduction methods, significantly reducing error in distance preservation. As a data whitening method, it improves downstream classification by up to 3.9% compared to methods that don't use whitening. Finally, we show that HoroPCA can be used to visualize hyperbolic data in two dimensions.
Systems of bounded rational agents with information-theoretic constraints
Sep 16, 2018Specialization and hierarchical organization are important features of efficient collaboration in economical, artificial, and biological systems. Here, we investigate the hypothesis that both features can be explained by the fact that each entity of such a system is limited in a certain way. We propose an information-theoretic approach based on a Free Energy principle, in order to computationally analyze systems of bounded rational agents that deal with such limitations optimally. We find that specialization allows to focus on fewer tasks, thus leading to a more efficient execution, but in turn requires coordination in hierarchical structures of specialized experts and coordinating units. Our results suggest that hierarchical architectures of specialized units at lower levels that are coordinated by units at higher levels are optimal, given that each unit's information-processing capability is limited and conforms to constraints on complexity costs.
Edge Prior Augmented Networks for Motion Deblurring on Naturally Blurry Images
Sep 18, 2021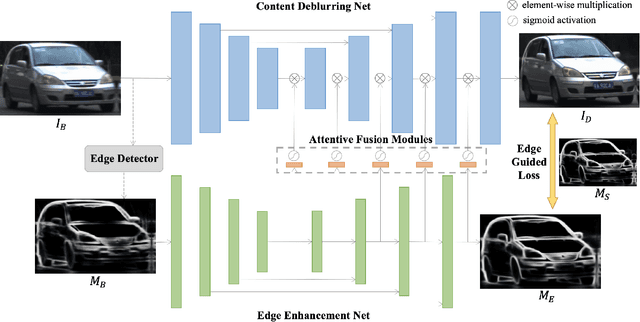



Motion deblurring has witnessed rapid development in recent years, and most of the recent methods address it by using deep learning techniques, with the help of different kinds of prior knowledge. Concerning that deblurring is essentially expected to improve the image sharpness, edge information can serve as an important prior. However, the edge has not yet been seriously taken into consideration in previous methods when designing deep models. To this end, we present a novel framework that incorporates edge prior knowledge into deep models, termed Edge Prior Augmented Networks (EPAN). EPAN has a content-based main branch and an edge-based auxiliary branch, which are constructed as a Content Deblurring Net (CDN) and an Edge Enhancement Net (EEN), respectively. EEN is designed to augment CDN in the deblurring process via an attentive fusion mechanism, where edge features are mapped as spatial masks to guide content features in a feature-based hierarchical manner. An edge-guided loss function is proposed to further regulate the optimization of EPAN by enforcing the focus on edge areas. Besides, we design a dual-camera-based image capturing setting to build a new dataset, Real Object Motion Blur (ROMB), with paired sharp and naturally blurry images of fast-moving cars, so as to better train motion deblurring models and benchmark the capability of motion deblurring algorithms in practice. Extensive experiments on the proposed ROMB and other existing datasets demonstrate that EPAN outperforms state-of-the-art approaches qualitatively and quantitatively.
Training Bi-Encoders for Word Sense Disambiguation
May 21, 2021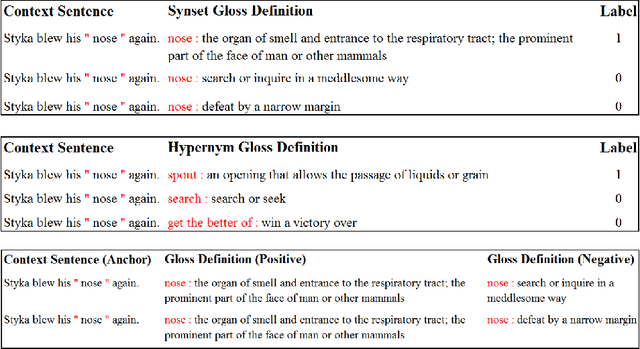
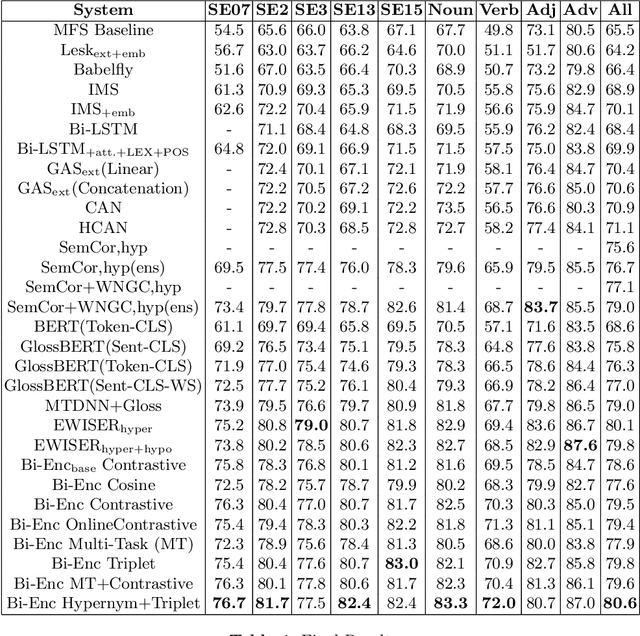
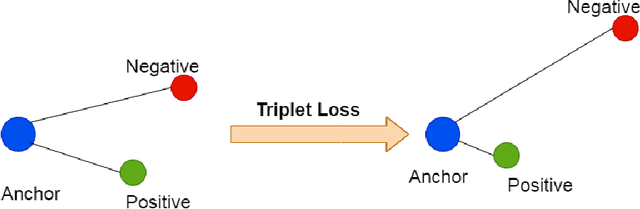
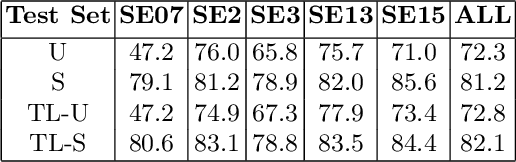
Modern transformer-based neural architectures yield impressive results in nearly every NLP task and Word Sense Disambiguation, the problem of discerning the correct sense of a word in a given context, is no exception. State-of-the-art approaches in WSD today leverage lexical information along with pre-trained embeddings from these models to achieve results comparable to human inter-annotator agreement on standard evaluation benchmarks. In the same vein, we experiment with several strategies to optimize bi-encoders for this specific task and propose alternative methods of presenting lexical information to our model. Through our multi-stage pre-training and fine-tuning pipeline we further the state of the art in Word Sense Disambiguation.
Intra-Inter Subject Self-supervised Learning for Multivariate Cardiac Signals
Sep 18, 2021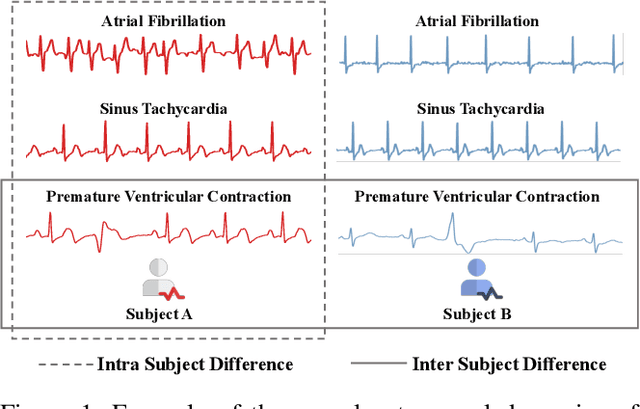

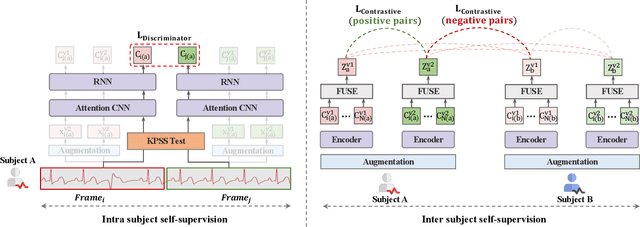
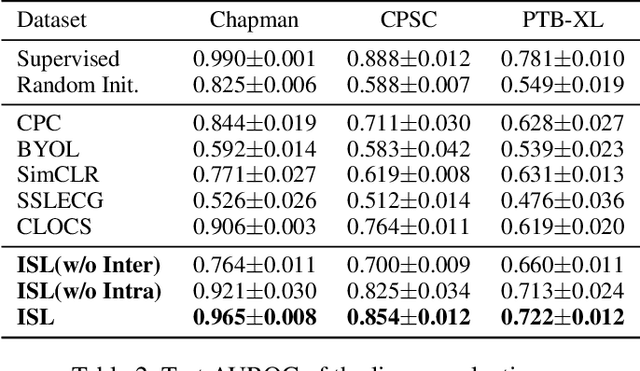
Learning information-rich and generalizable representations effectively from unlabeled multivariate cardiac signals to identify abnormal heart rhythms (cardiac arrhythmias) is valuable in real-world clinical settings but often challenging due to its complex temporal dynamics. Cardiac arrhythmias can vary significantly in temporal patterns even for the same patient ($i.e.$, intra subject difference). Meanwhile, the same type of cardiac arrhythmia can show different temporal patterns among different patients due to different cardiac structures ($i.e.$, inter subject difference). In this paper, we address the challenges by proposing an Intra-inter Subject self-supervised Learning (ISL) model that is customized for multivariate cardiac signals. Our proposed ISL model integrates medical knowledge into self-supervision to effectively learn from intra-inter subject differences. In intra subject self-supervision, ISL model first extracts heartbeat-level features from each subject using a channel-wise attentional CNN-RNN encoder. Then a stationarity test module is employed to capture the temporal dependencies between heartbeats. In inter subject self-supervision, we design a set of data augmentations according to the clinical characteristics of cardiac signals and perform contrastive learning among subjects to learn distinctive representations for various types of patients. Extensive experiments on three real-world datasets were conducted. In a semi-supervised transfer learning scenario, our pre-trained ISL model leads about 10% improvement over supervised training when only 1% labeled data is available, suggesting strong generalizability and robustness of the model.
Semantic Compositional Learning for Low-shot Scene Graph Generation
Aug 19, 2021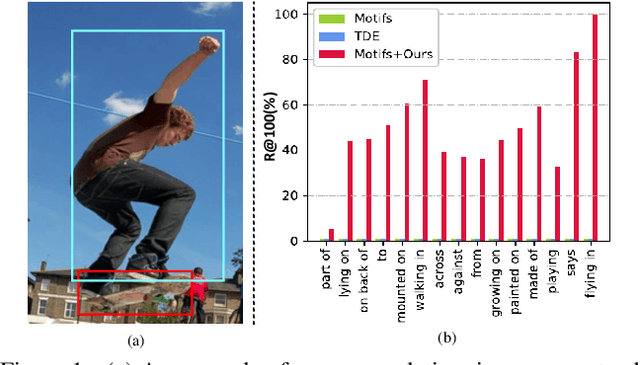
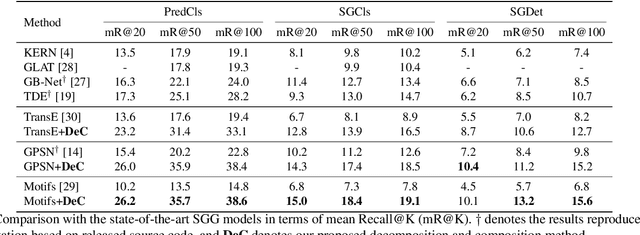
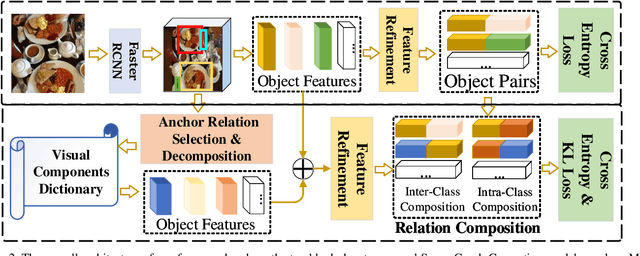
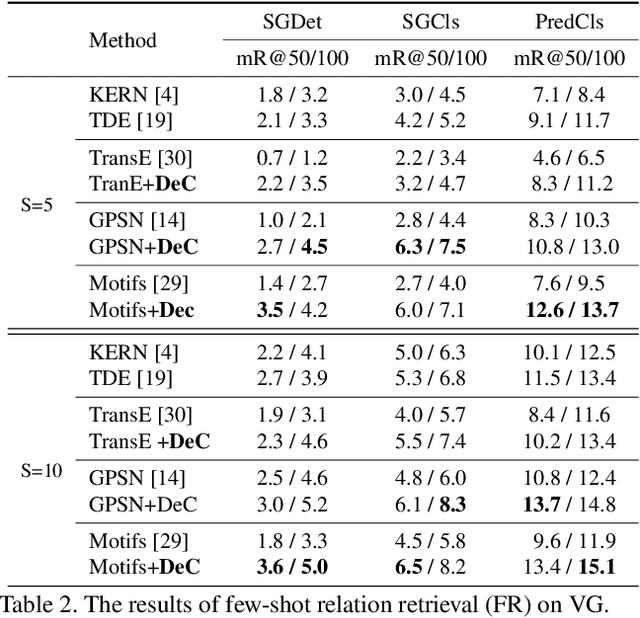
Scene graphs provide valuable information to many downstream tasks. Many scene graph generation (SGG) models solely use the limited annotated relation triples for training, leading to their underperformance on low-shot (few and zero) scenarios, especially on the rare predicates. To address this problem, we propose a novel semantic compositional learning strategy that makes it possible to construct additional, realistic relation triples with objects from different images. Specifically, our strategy decomposes a relation triple by identifying and removing the unessential component and composes a new relation triple by fusing with a semantically or visually similar object from a visual components dictionary, whilst ensuring the realisticity of the newly composed triple. Notably, our strategy is generic and can be combined with existing SGG models to significantly improve their performance. We performed a comprehensive evaluation on the benchmark dataset Visual Genome. For three recent SGG models, adding our strategy improves their performance by close to 50\%, and all of them substantially exceed the current state-of-the-art.
Information-Propogation-Enhanced Neural Machine Translation by Relation Model
May 25, 2018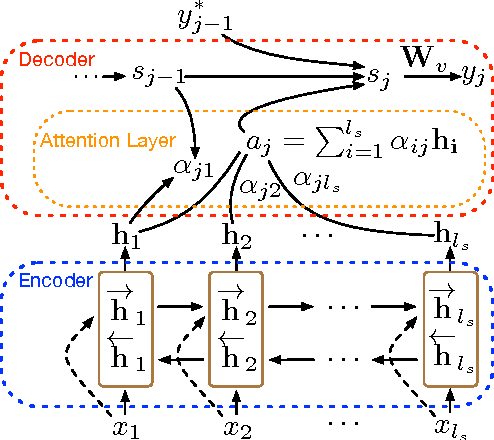
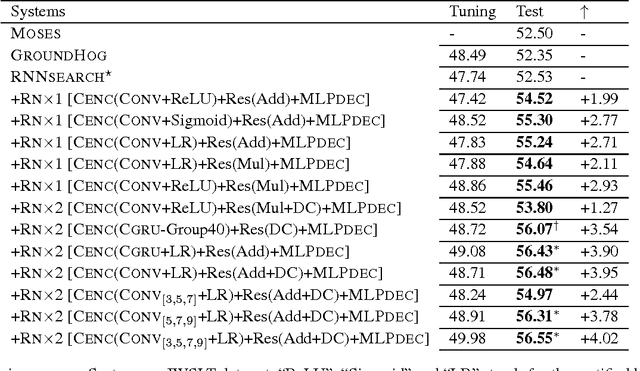
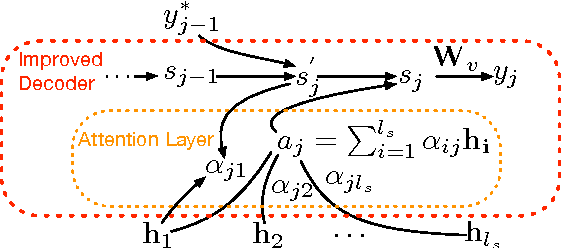
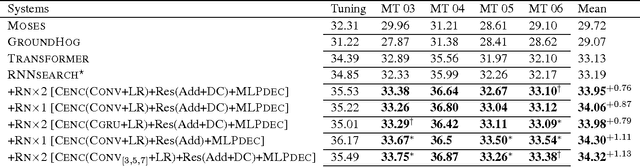
Even though sequence-to-sequence neural machine translation (NMT) model have achieved state-of-art performance in the recent fewer years, but it is widely concerned that the recurrent neural network (RNN) units are very hard to capture the long-distance state information, which means RNN can hardly find the feature with long term dependency as the sequence becomes longer. Similarly, convolutional neural network (CNN) is introduced into NMT for speeding recently, however, CNN focus on capturing the local feature of the sequence; To relieve this issue, we incorporate a relation network into the standard encoder-decoder framework to enhance information-propogation in neural network, ensuring that the information of the source sentence can flow into the decoder adequately. Experiments show that proposed framework outperforms the statistical MT model and the state-of-art NMT model significantly on two data sets with different scales.
Performance of UAV assisted Multiuser Terrestrial-Satellite Communication System over Mixed FSO/RF Channels
Sep 13, 2021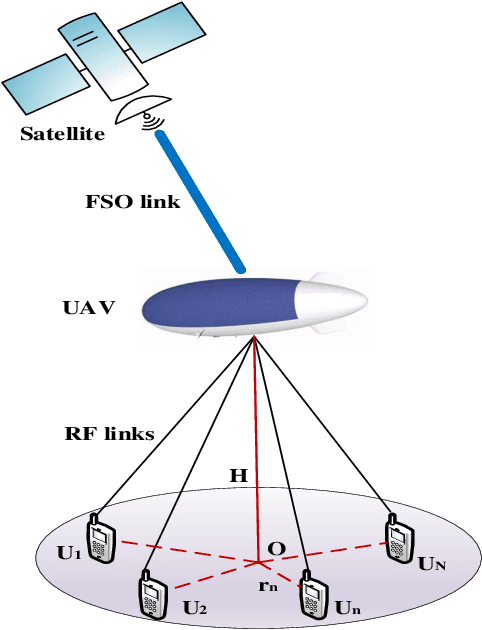
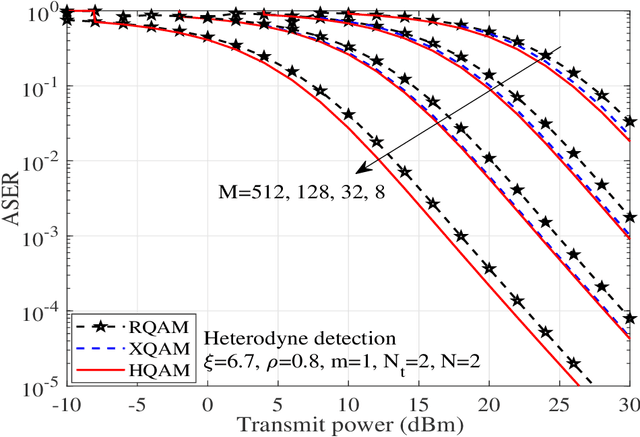
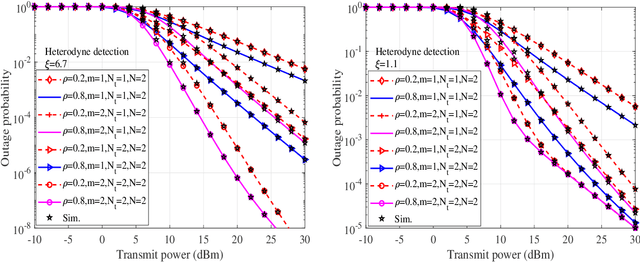
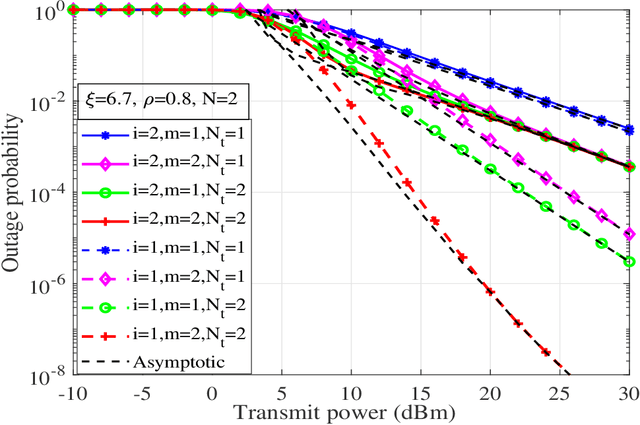
In this work, performance of a multi-antenna multiuser unmanned aerial vehicle (UAV) assisted terrestrial-satellite communication system over mixed free space optics (FSO)/ radio frequency (RF) channels is analyzed. Downlink transmission from the satellite to the UAV is completed through FSO link which follows Gamma-Gamma distribution with pointing error impairments. Both the heterodyne detection and intensity modulation direct detection techniques are considered at the FSO receiver. To avail the antenna diversity, multiple transmit antennas are considered at the UAV. Selective decode-and-forward scheme is assumed at the UAV and opportunistic user scheduling is performed while considering the practical constraints of outdated channel state information (CSI) during the user selection and transmission phase. The RF links are assumed to follow Nakagami-m distribution due to its versatile nature. In this context, for the performance analysis, analytical expressions of outage probability, asymptotic outage probability, ergodic capacity, effective capacity, and generalized average symbol-error-rate expressions of various quadrature amplitude modulation (QAM) schemes such as hexagonal-QAM, cross-QAM, and rectangular QAM are derived. A comparison of various modulation schemes is presented. Further, the impact of pointing error, number of antennas, delay constraint, fading severity, and imperfect CSI are highlighted on the system performance. Finally, all the analytical results are verified through the Monte-Carlo simulations.
Latin writing styles analysis with Machine Learning: New approach to old questions
Sep 01, 2021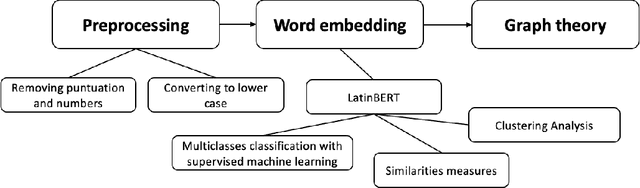
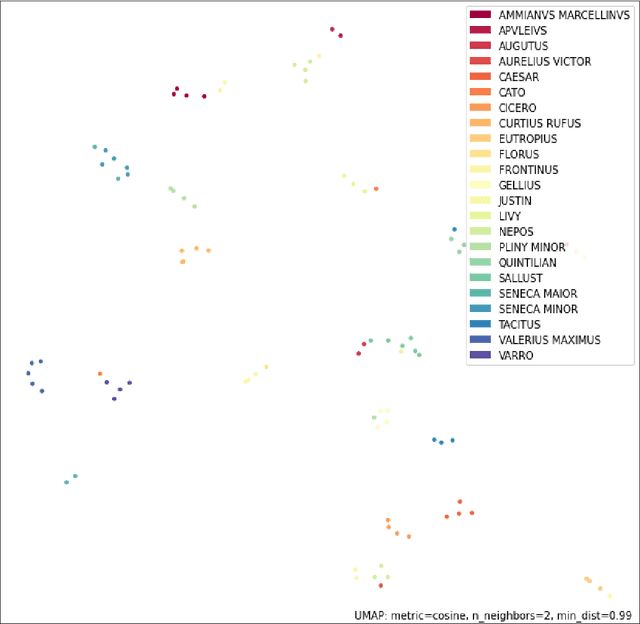
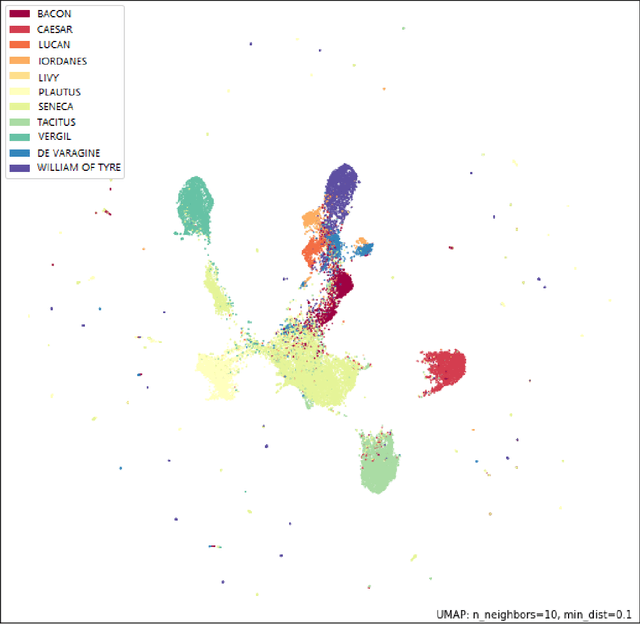
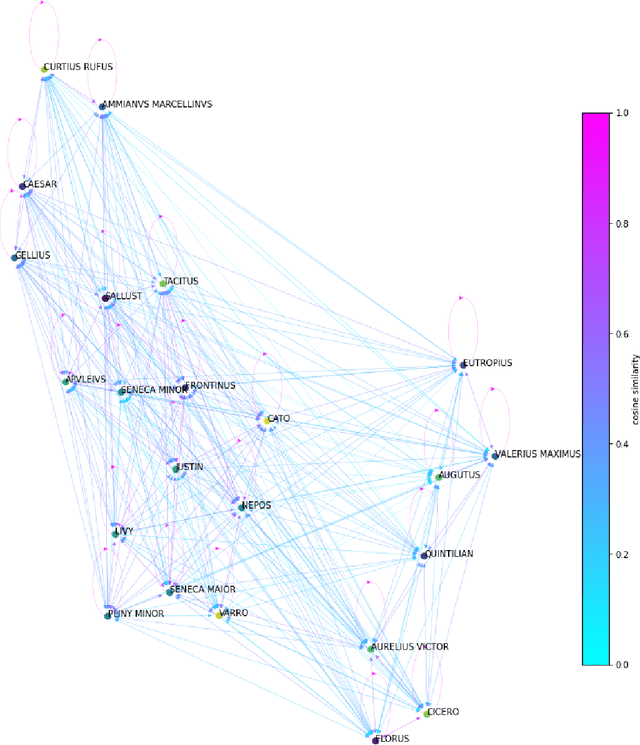
In the Middle Ages texts were learned by heart and spread using oral means of communication from generation to generation. Adaptation of the art of prose and poems allowed keeping particular descriptions and compositions characteristic for many literary genres. Taking into account such a specific construction of literature composed in Latin, we can search for and indicate the probability patterns of familiar sources of specific narrative texts. Consideration of Natural Language Processing tools allowed us the transformation of textual objects into numerical ones and then application of machine learning algorithms to extract information from the dataset. We carried out the task consisting of the practical use of those concepts and observation to create a tool for analyzing narrative texts basing on open-source databases. The tool focused on creating specific search tools resources which could enable us detailed searching throughout the text. The main objectives of the study take into account finding similarities between sentences and between documents. Next, we applied machine learning algorithms on chosen texts to calculate specific features of them (for instance authorship or centuries) and to recognize sources of anonymous texts with a certain percentage.