 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Inside Your Diffusion Model? A Score-Based Riemannian Metric to Explore the Data Manifold
May 19, 2025



Recent advances in diffusion models have demonstrated their remarkable ability to capture complex image distributions, but the geometric properties of the learned data manifold remain poorly understood. We address this gap by introducing a score-based Riemannian metric that leverages the Stein score function from diffusion models to characterize the intrinsic geometry of the data manifold without requiring explicit parameterization. Our approach defines a metric tensor in the ambient space that stretches distances perpendicular to the manifold while preserving them along tangential directions, effectively creating a geometry where geodesics naturally follow the manifold's contours. We develop efficient algorithms for computing these geodesics and demonstrate their utility for both interpolation between data points and extrapolation beyond the observed data distribution. Through experiments on synthetic data with known geometry, Rotated MNIST, and complex natural images via Stable Diffusion, we show that our score-based geodesics capture meaningful transformations that respect the underlying data distribution. Our method consistently outperforms baseline approaches on perceptual metrics (LPIPS) and distribution-level metrics (FID, KID), producing smoother, more realistic image transitions. These results reveal the implicit geometric structure learned by diffusion models and provide a principled way to navigate the manifold of natural images through the lens of Riemannian geometry.
Topological Data Analysis (TDA) Techniques Enhance Hand Pose Classification from ECoG Neural Recordings
Oct 09, 2021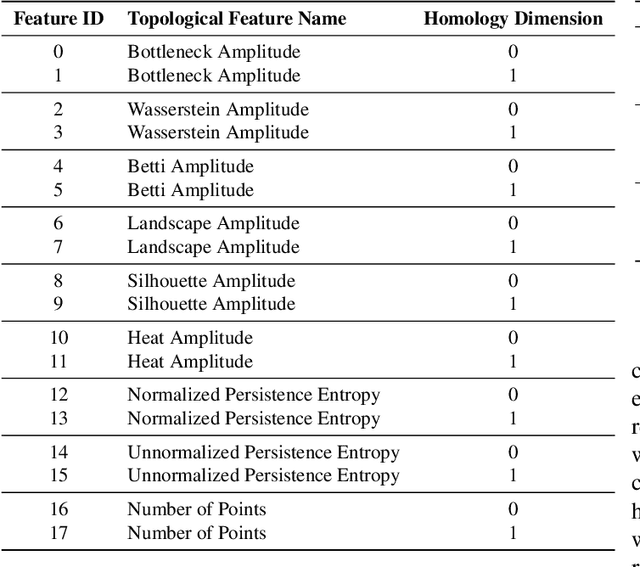
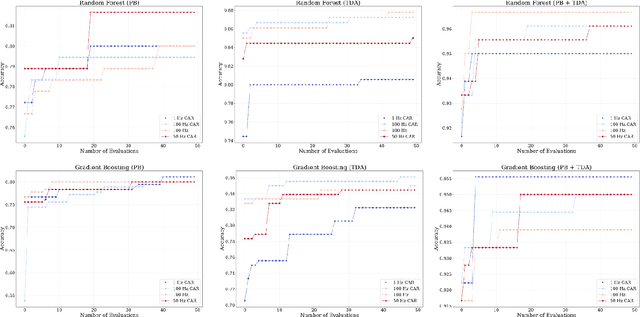
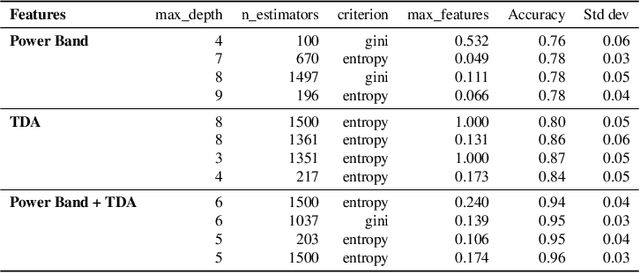
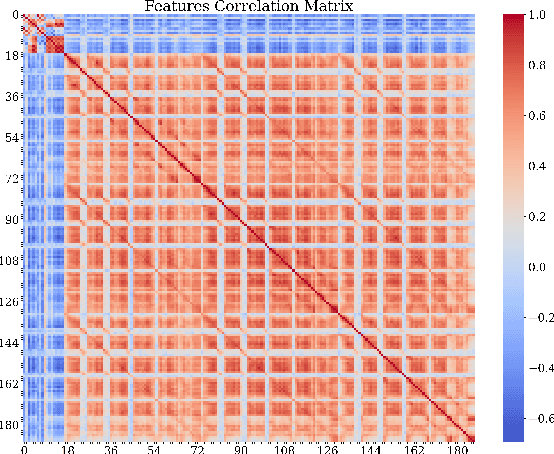
Electrocorticogram (ECoG) well characterizes hand movement intentions and gestures. In the present work we aim to investigate the possibility to enhance hand pose classification, in a Rock-Paper-Scissor - and Rest - task, by introducing topological descriptors of time series data. We hypothesized that an innovative approach based on topological data analysis can extract hidden information that are not detectable with standard Brain Computer Interface (BCI)techniques. To investigate this hypothesis, we integrate topological features together with power band features and feed them to several standard classifiers, e.g. Random Forest,Gradient Boosting. Model selection is thus completed after a meticulous phase of bayesian hyperparameter optimization. With our method, we observed robust results in terms of ac-curacy for a four-labels classification problem, with limited available data. Through feature importance investigation, we conclude that topological descriptors are able to extract useful discriminative information and provide novel insights.Since our data are restricted to single-patient recordings, generalization might be limited. Nevertheless, our method can be extended and applied to a wide range of neurophysiological recordings and it might be an intriguing point of departure for future studies.
Latin writing styles analysis with Machine Learning: New approach to old questions
Sep 01, 2021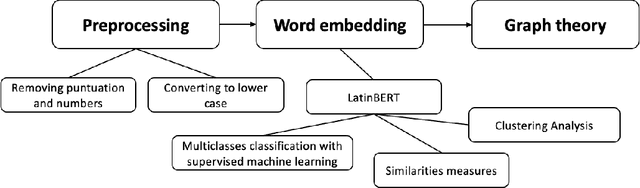
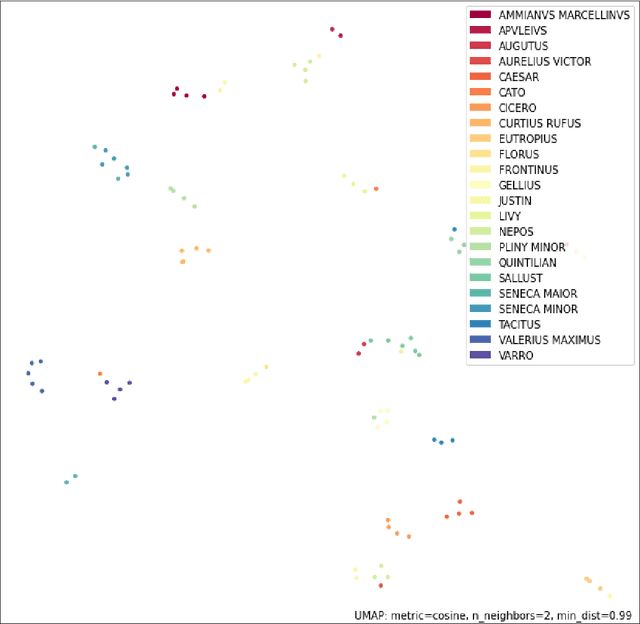
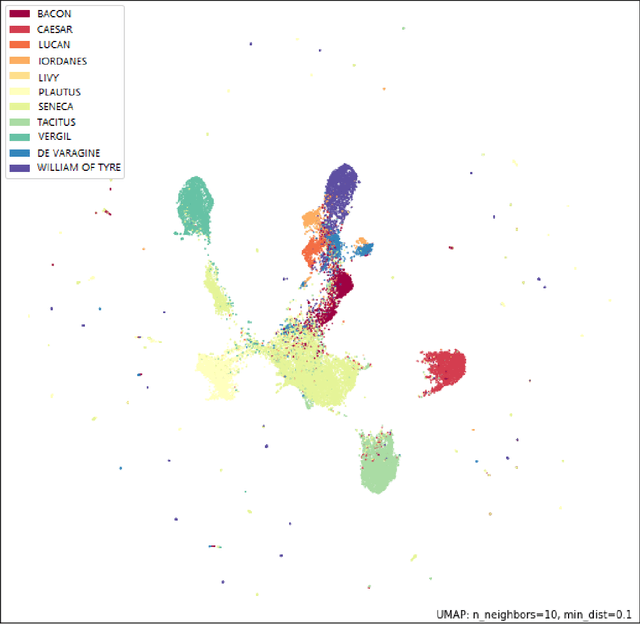
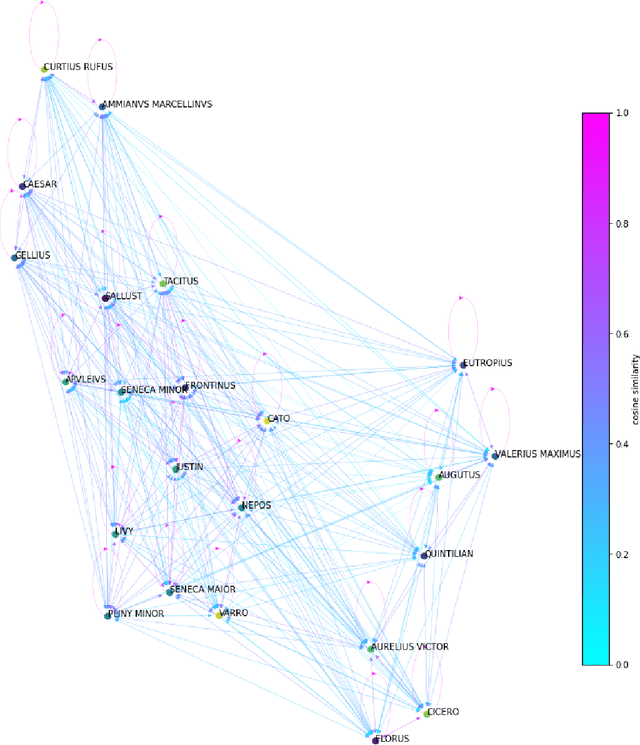
In the Middle Ages texts were learned by heart and spread using oral means of communication from generation to generation. Adaptation of the art of prose and poems allowed keeping particular descriptions and compositions characteristic for many literary genres. Taking into account such a specific construction of literature composed in Latin, we can search for and indicate the probability patterns of familiar sources of specific narrative texts. Consideration of Natural Language Processing tools allowed us the transformation of textual objects into numerical ones and then application of machine learning algorithms to extract information from the dataset. We carried out the task consisting of the practical use of those concepts and observation to create a tool for analyzing narrative texts basing on open-source databases. The tool focused on creating specific search tools resources which could enable us detailed searching throughout the text. The main objectives of the study take into account finding similarities between sentences and between documents. Next, we applied machine learning algorithms on chosen texts to calculate specific features of them (for instance authorship or centuries) and to recognize sources of anonymous texts with a certain percentage.