 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coverless information hiding based on Generative Model
Feb 10, 2018
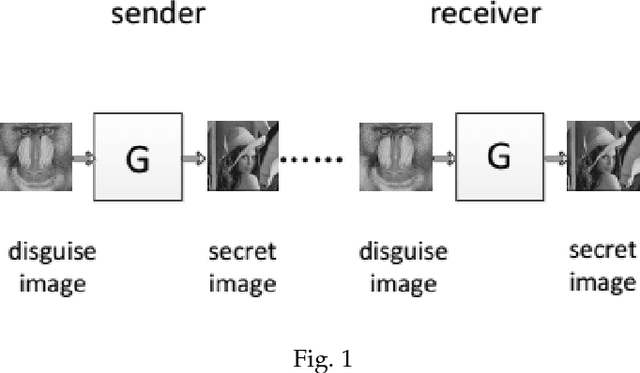
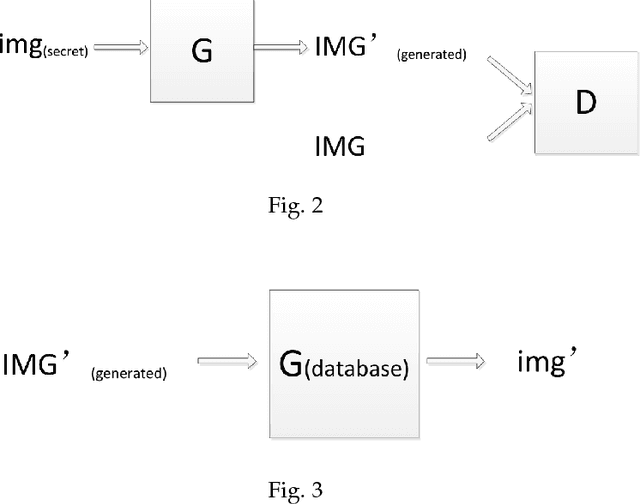
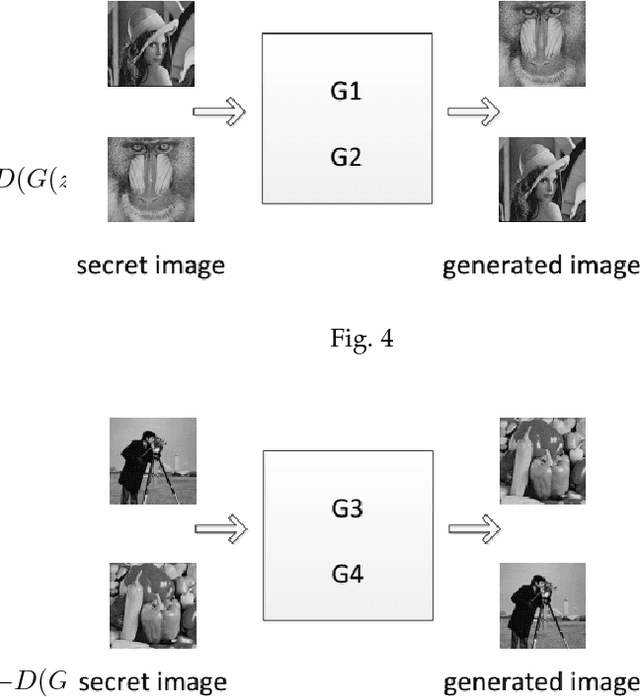
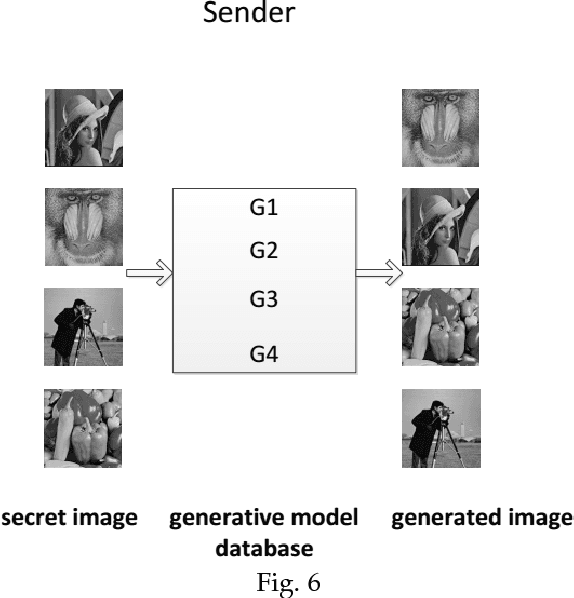
A new coverless image information hiding method based on generative model is proposed, we feed the secret image to the generative model database, and generate a meaning-normal and independent image different from the secret image, then, the generated image is transmitted to the receiver and is fed to the generative model database to generate another image visually the same as the secret image. So we only need to transmit the meaning-normal image which is not related to the secret image, and we can achieve the same effect as the transmission of the secret image. This is the first time to propose the coverless image information hiding method based on generative model, compared with the traditional image steganography, the transmitted image does not embed any information of the secret image in this method, therefore, can effectively resist steganalysis tools. Experimental results show that our method has high capacity, safety and reliability.
DYPLODOC: Dynamic Plots for Document Classification
Jul 26, 2021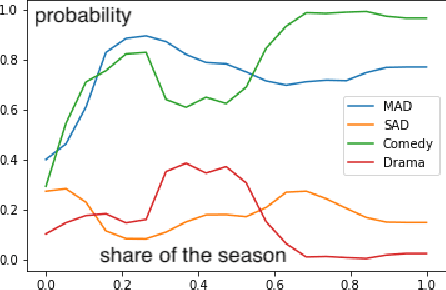
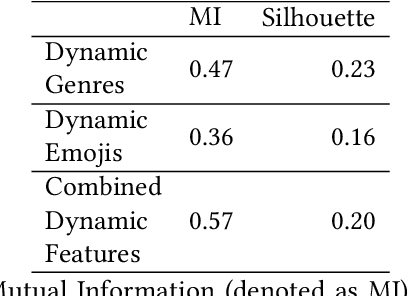
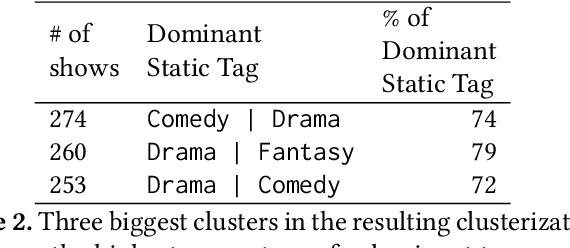

Narrative generation and analysis are still on the fringe of modern natural language processing yet are crucial in a variety of applications. This paper proposes a feature extraction method for plot dynamics. We present a dataset that consists of the plot descriptions for thirteen thousand TV shows alongside meta-information on their genres and dynamic plots extracted from them. We validate the proposed tool for plot dynamics extraction and discuss possible applications of this method to the tasks of narrative analysis and generation.
Generating MIMO Channels For 6G Virtual Worlds Using Ray-tracing Simulations
Jun 09, 2021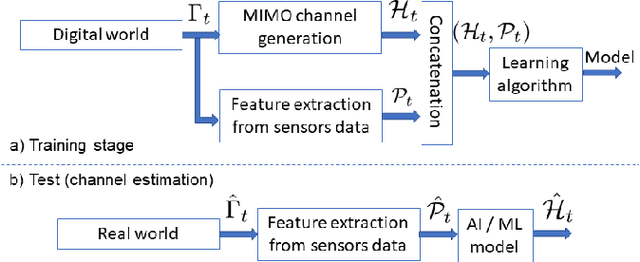

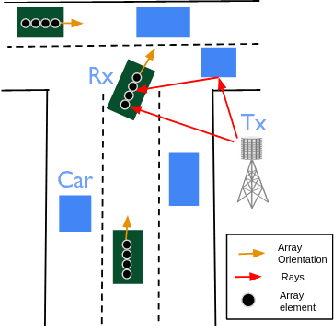
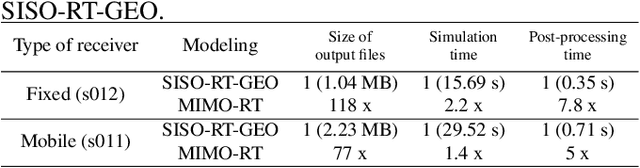
Some 6G use cases include augmented reality and high-fidelity holograms, with this information flowing through the network. Hence, it is expected that 6G systems can feed machine learning algorithms with such context information to optimize communication performance. This paper focuses on the simulation of 6G MIMO systems that rely on a 3-D representation of the environment as captured by cameras and eventually other sensors. We present new and improved Raymobtime datasets, which consist of paired MIMO channels and multimodal data. We also discuss tradeoffs between speed and accuracy when generating channels via ray-tracing. We finally provide results of beam selection and channel estimation to assess the impact of the improvements in the ray-tracing simulation methodology.
Lung Cancer Risk Estimation with Incomplete Data: A Joint Missing Imputation Perspective
Jul 25, 2021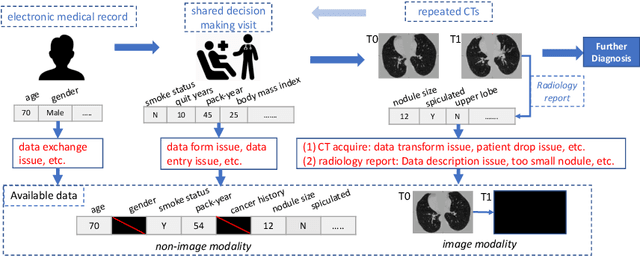
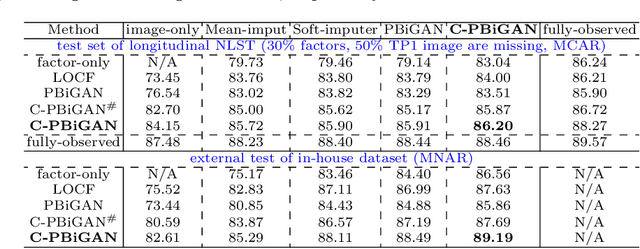
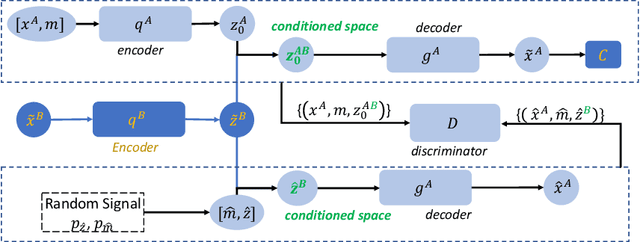
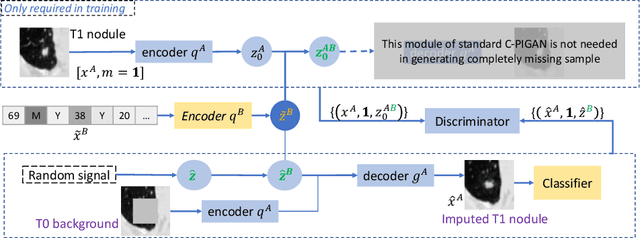
Data from multi-modality provide complementary information in clinical prediction, but missing data in clinical cohorts limits the number of subjects in multi-modal learning context. Multi-modal missing imputation is challenging with existing methods when 1) the missing data span across heterogeneous modalities (e.g., image vs. non-image); or 2) one modality is largely missing. In this paper, we address imputation of missing data by modeling the joint distribution of multi-modal data. Motivated by partial bidirectional generative adversarial net (PBiGAN), we propose a new Conditional PBiGAN (C-PBiGAN) method that imputes one modality combining the conditional knowledge from another modality. Specifically, C-PBiGAN introduces a conditional latent space in a missing imputation framework that jointly encodes the available multi-modal data, along with a class regularization loss on imputed data to recover discriminative information. To our knowledge, it is the first generative adversarial model that addresses multi-modal missing imputation by modeling the joint distribution of image and non-image data. We validate our model with both the national lung screening trial (NLST) dataset and an external clinical validation cohort. The proposed C-PBiGAN achieves significant improvements in lung cancer risk estimation compared with representative imputation methods (e.g., AUC values increase in both NLST (+2.9\%) and in-house dataset (+4.3\%) compared with PBiGAN, p$<$0.05).
Constructing Flow Graphs from Procedural Cybersecurity Texts
May 29, 2021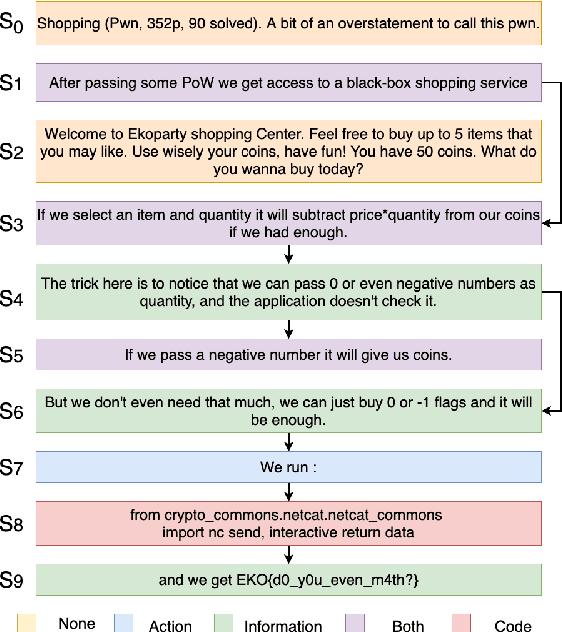
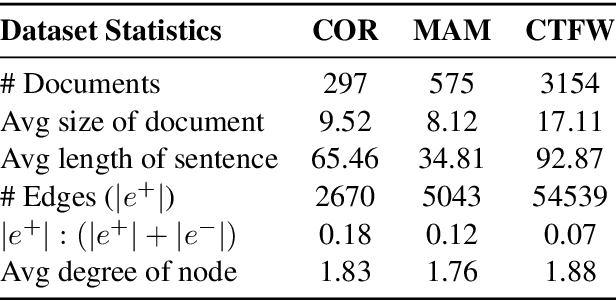
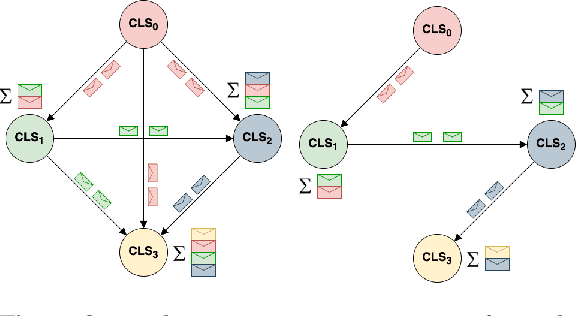
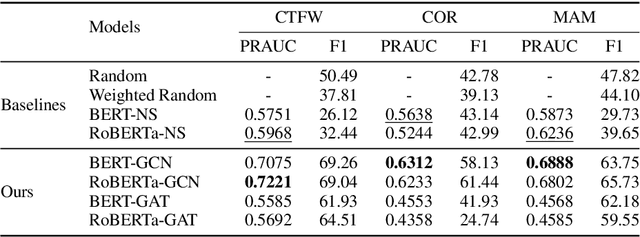
Following procedural texts written in natural languages is challenging. We must read the whole text to identify the relevant information or identify the instruction flows to complete a task, which is prone to failures. If such texts are structured, we can readily visualize instruction-flows, reason or infer a particular step, or even build automated systems to help novice agents achieve a goal. However, this structure recovery task is a challenge because of such texts' diverse nature. This paper proposes to identify relevant information from such texts and generate information flows between sentences. We built a large annotated procedural text dataset (CTFW) in the cybersecurity domain (3154 documents). This dataset contains valuable instructions regarding software vulnerability analysis experiences. We performed extensive experiments on CTFW with our LM-GNN model variants in multiple settings. To show the generalizability of both this task and our method, we also experimented with procedural texts from two other domains (Maintenance Manual and Cooking), which are substantially different from cybersecurity. Our experiments show that Graph Convolution Network with BERT sentence embeddings outperforms BERT in all three domains
Image Compression with Recurrent Neural Network and Generalized Divisive Normalization
Sep 05, 2021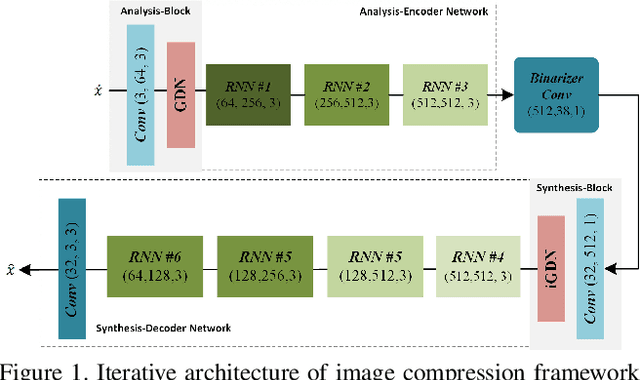
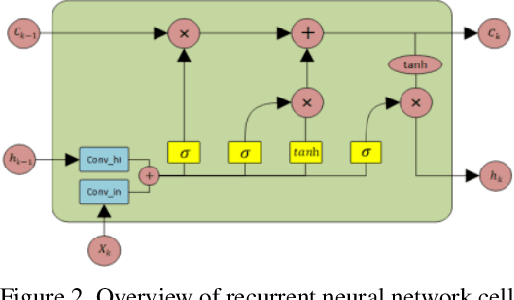
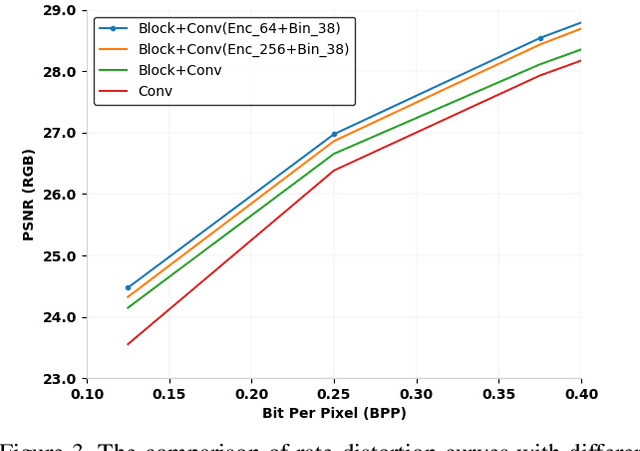
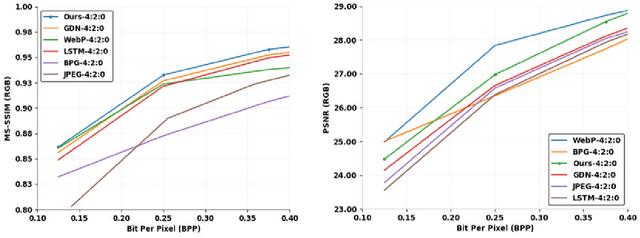
Image compression is a method to remove spatial redundancy between adjacent pixels and reconstruct a high-quality image. In the past few years, deep learning has gained huge attention from the research community and produced promising image reconstruction results. Therefore, recent methods focused on developing deeper and more complex networks, which significantly increased network complexity. In this paper, two effective novel blocks are developed: analysis and synthesis block that employs the convolution layer and Generalized Divisive Normalization (GDN) in the variable-rate encoder and decoder side. Our network utilizes a pixel RNN approach for quantization. Furthermore, to improve the whole network, we encode a residual image using LSTM cells to reduce unnecessary information. Experimental results demonstrated that the proposed variable-rate framework with novel blocks outperforms existing methods and standard image codecs, such as George's ~\cite{002} and JPEG in terms of image similarity. The project page along with code and models are available at https://khawar512.github.io/cvpr/
Covert Beamforming Design for Intelligent Reflecting Surface Assisted IoT Networks
Sep 01, 2021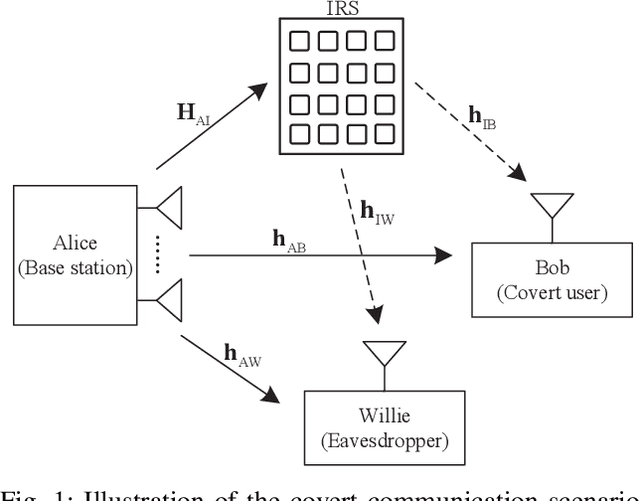
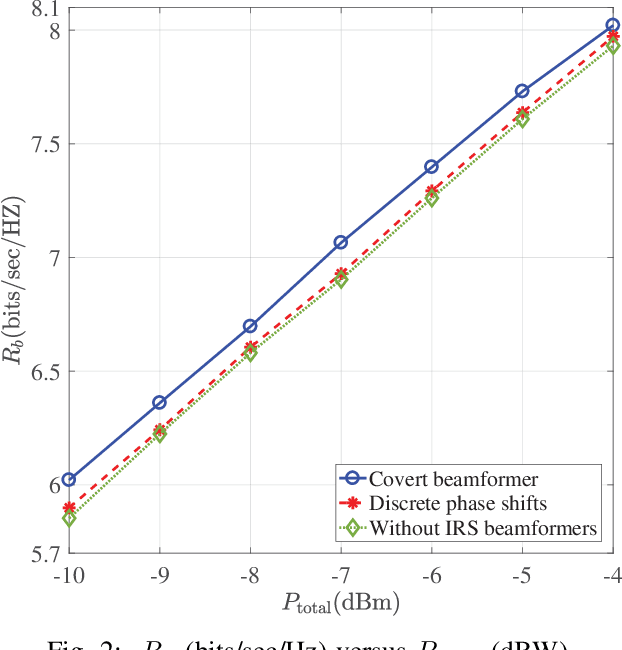
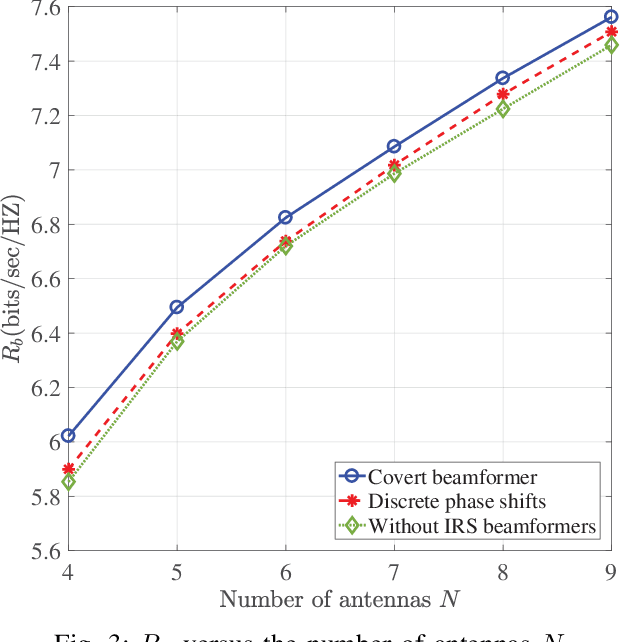
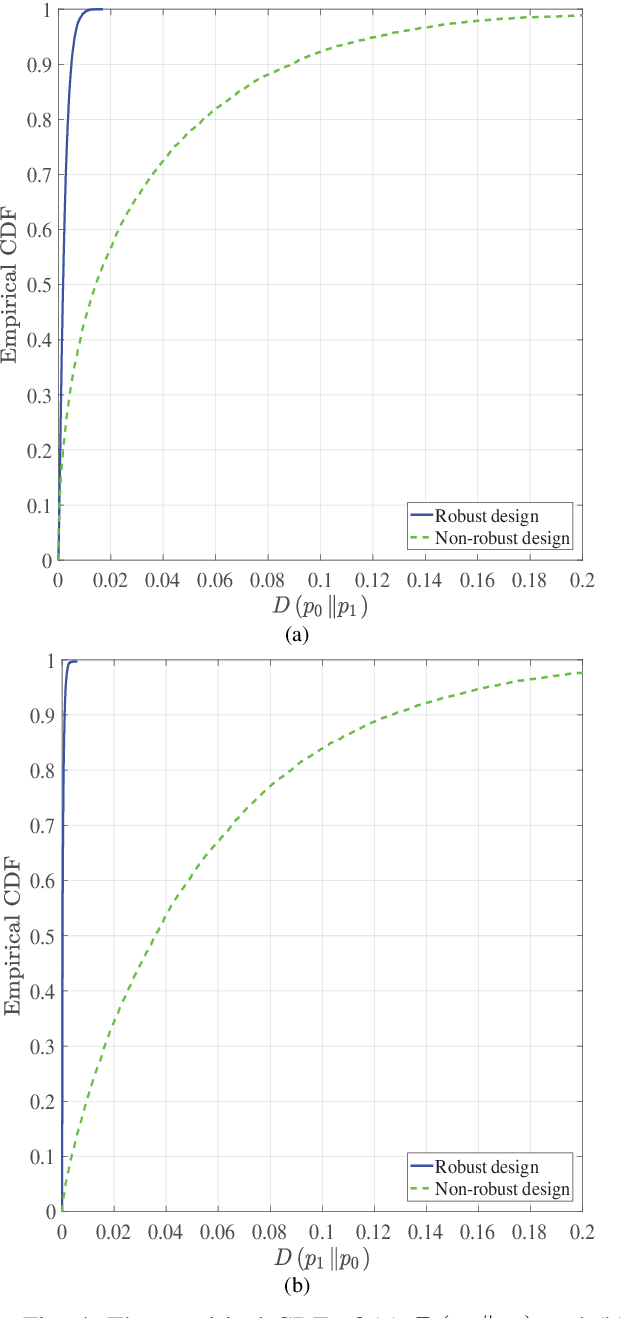
In this paper, we consider covert beamforming design for intelligent reflecting surface (IRS) assisted Internet of Things (IoT) networks, where Alice utilizes IRS to covertly transmit a message to Bob without being recognized by Willie. We investigate the joint beamformer design of Alice and IRS to maximize the covert rate of Bob when the knowledge about Willie's channel state information (WCSI) is perfect and imperfect at Alice, respectively. For the former case, we develop a covert beamformer under the perfect covert constraint by applying semidefinite relaxation. For the later case, the optimal decision threshold of Willie is derived, and we analyze the false alarm and the missed detection probabilities. Furthermore, we utilize the property of Kullback-Leibler divergence to develop the robust beamformer based on a relaxation, S-Lemma and alternate iteration approach. Finally, the numerical experiments evaluate the performance of the proposed covert beamformer design and robust beamformer design.
Hyperspectral Pansharpening Based on Improved Deep Image Prior and Residual Reconstruction
Jul 06, 2021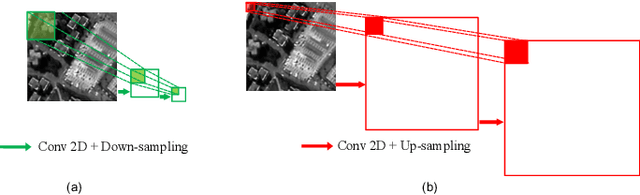


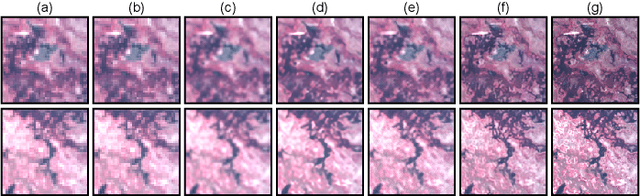
Hyperspectral pansharpening aims to synthesize a low-resolution hyperspectral image (LR-HSI) with a registered panchromatic image (PAN) to generate an enhanced HSI with high spectral and spatial resolution. Recently proposed HS pansharpening methods have obtained remarkable results using deep convolutional networks (ConvNets), which typically consist of three steps: (1) up-sampling the LR-HSI, (2) predicting the residual image via a ConvNet, and (3) obtaining the final fused HSI by adding the outputs from first and second steps. Recent methods have leveraged Deep Image Prior (DIP) to up-sample the LR-HSI due to its excellent ability to preserve both spatial and spectral information, without learning from large data sets. However, we observed that the quality of up-sampled HSIs can be further improved by introducing an additional spatial-domain constraint to the conventional spectral-domain energy function. We define our spatial-domain constraint as the $L_1$ distance between the predicted PAN image and the actual PAN image. To estimate the PAN image of the up-sampled HSI, we also propose a learnable spectral response function (SRF). Moreover, we noticed that the residual image between the up-sampled HSI and the reference HSI mainly consists of edge information and very fine structures. In order to accurately estimate fine information, we propose a novel over-complete network, called HyperKite, which focuses on learning high-level features by constraining the receptive from increasing in the deep layers. We perform experiments on three HSI datasets to demonstrate the superiority of our DIP-HyperKite over the state-of-the-art pansharpening methods. The deployment codes, pre-trained models, and final fusion outputs of our DIP-HyperKite and the methods used for the comparisons will be publicly made available at https://github.com/wgcban/DIP-HyperKite.git.
The Impact of Positional Encodings on Multilingual Compression
Sep 11, 2021
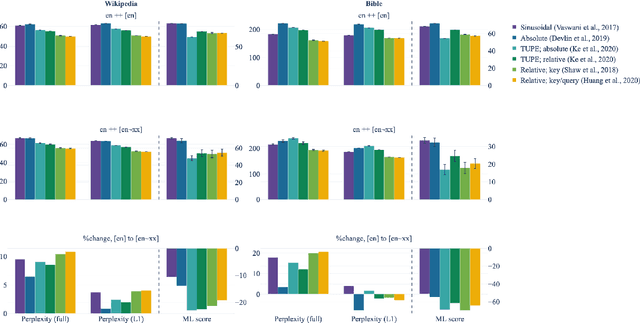

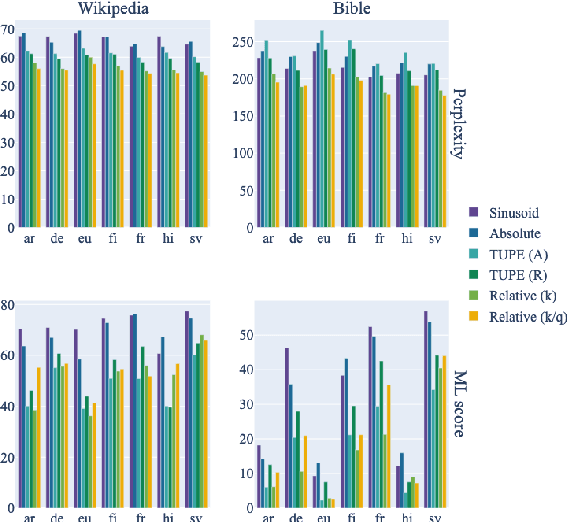
In order to preserve word-order information in a non-autoregressive setting, transformer architectures tend to include positional knowledge, by (for instance) adding positional encodings to token embeddings. Several modifications have been proposed over the sinusoidal positional encodings used in the original transformer architecture; these include, for instance, separating position encodings and token embeddings, or directly modifying attention weights based on the distance between word pairs. We first show that surprisingly, while these modifications tend to improve monolingual language models, none of them result in better multilingual language models. We then answer why that is: Sinusoidal encodings were explicitly designed to facilitate compositionality by allowing linear projections over arbitrary time steps. Higher variances in multilingual training distributions requires higher compression, in which case, compositionality becomes indispensable. Learned absolute positional encodings (e.g., in mBERT) tend to approximate sinusoidal embeddings in multilingual settings, but more complex positional encoding architectures lack the inductive bias to effectively learn compositionality and cross-lingual alignment. In other words, while sinusoidal positional encodings were originally designed for monolingual applications, they are particularly useful in multilingual language models.
Natural brain-information interfaces: Recommending information by relevance inferred from human brain signals
Jul 12, 2016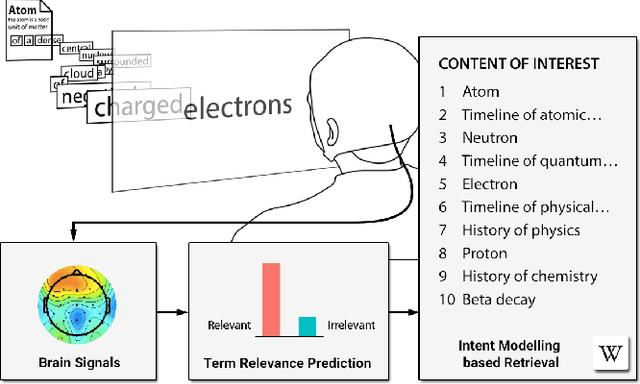
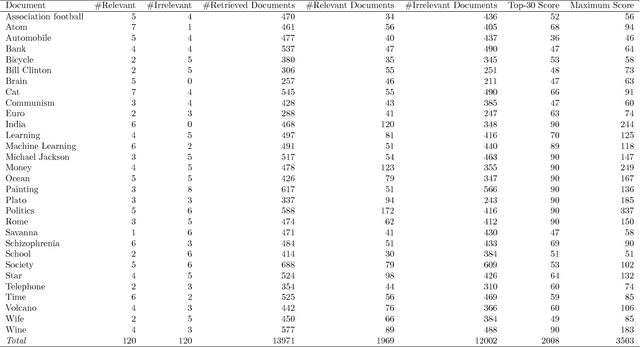

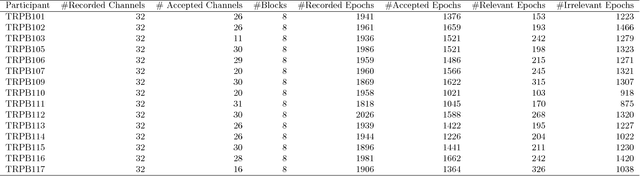
Finding relevant information from large document collections such as the World Wide Web is a common task in our daily lives. Estimation of a user's interest or search intention is necessary to recommend and retrieve relevant information from these collections. We introduce a brain-information interface used for recommending information by relevance inferred directly from brain signals. In experiments, participants were asked to read Wikipedia documents about a selection of topics while their EEG was recorded. Based on the prediction of word relevance, the individual's search intent was modeled and successfully used for retrieving new, relevant documents from the whole English Wikipedia corpus. The results show that the users' interests towards digital content can be modeled from the brain signals evoked by reading. The introduced brain-relevance paradigm enables the recommendation of information without any explicit user interaction, and may be applied across diverse information-intensive applications.