 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore-on-Graph: Incentivizing Autonomous Exploration of Large Language Models on Knowledge Graphs with Path-refined Reward Modeling
Feb 25, 2026The reasoning process of Large Language Models (LLMs) is often plagued by hallucinations and missing facts in question-answering tasks. A promising solution is to ground LLMs' answers in verifiable knowledge sources, such as Knowledge Graphs (KGs). Prevailing KG-enhanced methods typically constrained LLM reasoning either by enforcing rules during generation or by imitating paths from a fixed set of demonstrations. However, they naturally confined the reasoning patterns of LLMs within the scope of prior experience or fine-tuning data, limiting their generalizability to out-of-distribution graph reasoning problems. To tackle this problem, in this paper, we propose Explore-on-Graph (EoG), a novel framework that encourages LLMs to autonomously explore a more diverse reasoning space on KGs. To incentivize exploration and discovery of novel reasoning paths, we propose to introduce reinforcement learning during training, whose reward is the correctness of the reasoning paths' final answers. To enhance the efficiency and meaningfulness of the exploration, we propose to incorporate path information as additional reward signals to refine the exploration process and reduce futile efforts. Extensive experiments on five KGQA benchmark datasets demonstrate that, to the best of our knowledge, our method achieves state-of-the-art performance, outperforming not only open-source but also even closed-source LLMs.
BPE: Behavioral Profiling Ensemble
Jan 15, 2026Ensemble learning is widely recognized as a pivotal strategy for pushing the boundaries of predictive performance. Traditional static ensemble methods, such as Stacking, typically assign weights by treating each base learner as a holistic entity, thereby overlooking the fact that individual models exhibit varying degrees of competence across different regions of the instance space. To address this limitation, Dynamic Ensemble Selection (DES) was introduced. However, both static and dynamic approaches predominantly rely on the divergence among different models as the basis for integration. This inter-model perspective neglects the intrinsic characteristics of the models themselves and necessitates a heavy reliance on validation sets for competence estimation. In this paper, we propose the Behavioral Profiling Ensemble (BPE) framework, which introduces a novel paradigm shift. Unlike traditional methods, BPE constructs a ``behavioral profile'' intrinsic to each model and derives integration weights based on the deviation between the model's response to a specific test instance and its established behavioral profile. Extensive experiments on both synthetic and real-world datasets demonstrate that the algorithm derived from the BPE framework achieves significant improvements over state-of-the-art ensemble baselines. These gains are evident not only in predictive accuracy but also in computational efficiency and storage resource utilization across various scenarios.
Accept-Reject Lasso
Aug 06, 2025



The Lasso method is known to exhibit instability in the presence of highly correlated features, often leading to an arbitrary selection of predictors. This issue manifests itself in two primary error types: the erroneous omission of features that lack a true substitutable relationship (falsely redundant features) and the inclusion of features with a true substitutable relationship (truly redundant features). Although most existing methods address only one of these challenges, we introduce the Accept-Reject Lasso (ARL), a novel approach that resolves this dilemma. ARL operationalizes an Accept-Reject framework through a fine-grained analysis of feature selection across data subsets. This framework is designed to partition the output of an ensemble method into beneficial and detrimental components through fine-grained analysis. The fundamental challenge for Lasso is that inter-variable correlation obscures the true sources of information. ARL tackles this by first using clustering to identify distinct subset structures within the data. It then analyzes Lasso's behavior across these subsets to differentiate between true and spurious correlations. For truly correlated features, which induce multicollinearity, ARL tends to select a single representative feature and reject the rest to ensure model stability. Conversely, for features linked by spurious correlations, which may vanish in certain subsets, ARL accepts those that Lasso might have incorrectly omitted. The distinct patterns arising from true versus spurious correlations create a divisible separation. By setting an appropriate threshold, our framework can effectively distinguish between these two phenomena, thereby maximizing the inclusion of informative variables while minimizing the introduction of detrimental ones. We illustrate the efficacy of the proposed method through extensive simulation and real-data experiments.
Relative Overfitting and Accept-Reject Framework
May 12, 2025



Currently, the scaling law of Large Language Models (LLMs) faces challenges and bottlenecks. This paper posits that noise effects, stemming from changes in the signal-to-noise ratio under diminishing marginal returns, are the root cause of these issues. To control this noise, we investigated the differences between models with performance advantages and disadvantages, introducing the concept of "relative overfitting." Based on their complementary strengths, we have proposed an application framework, Accept-Reject (AR). In Natural Language Processing (NLP), we use LLMs and Small Language Models (SLMs) as the medium for discussion. This framework enables SLMs to exert a universal positive influence on LLM decision outputs, rather than the intuitively expected negative influence. We validated our approach using self-built models based on mainstream architectures and pre-trained mainstream models across multiple datasets, including basic language modeling, long-context tasks, subject examination, and question-answering (QA) benchmarks. The results demonstrate that through our structure, compared to increasing the LLM's parameters, we can achieve better performance improvements with significantly lower parameter and computational costs in many scenarios. These improvements are universal, stable, and effective. Furthermore, we explore the potential of "relative overfitting" and the AR framework in other machine learning domains, such as computer vision (CV) and AI for science. We hope the proposed approach can help scale laws overcome existing bottlenecks.
Think Before You Act: A Two-Stage Framework for Mitigating Gender Bias Towards Vision-Language Tasks
May 27, 2024



Gender bias in vision-language models (VLMs) can reinforce harmful stereotypes and discrimination. In this paper, we focus on mitigating gender bias towards vision-language tasks. We identify object hallucination as the essence of gender bias in VLMs. Existing VLMs tend to focus on salient or familiar attributes in images but ignore contextualized nuances. Moreover, most VLMs rely on the co-occurrence between specific objects and gender attributes to infer the ignored features, ultimately resulting in gender bias. We propose GAMA, a task-agnostic generation framework to mitigate gender bias. GAMA consists of two stages: narrative generation and answer inference. During narrative generation, GAMA yields all-sided but gender-obfuscated narratives, which prevents premature concentration on localized image features, especially gender attributes. During answer inference, GAMA integrates the image, generated narrative, and a task-specific question prompt to infer answers for different vision-language tasks. This approach allows the model to rethink gender attributes and answers. We conduct extensive experiments on GAMA, demonstrating its debiasing and generalization ability.
PCRED: Zero-shot Relation Triplet Extraction with Potential Candidate Relation Selection and Entity Boundary Detection
Dec 13, 2022



Zero-shot relation triplet extraction (ZeroRTE) aims to extract relation triplets from unstructured texts under the zero-shot setting, where the relation sets at the training and testing stages are disjoint. Previous state-of-the-art method handles this challenging task by leveraging pretrained language models to generate data as additional training samples, which increases the training cost and severely constrains the model performance. To address the above issues, we propose a novel method named PCRED for ZeroRTE with Potential Candidate Relation Selection and Entity Boundary Detection. The remarkable characteristic of PCRED is that it does not rely on additional data and still achieves promising performance. The model adopts a relation-first paradigm, recognizing unseen relations through candidate relation selection. With this approach, the semantics of relations are naturally infused in the context. Entities are extracted based on the context and the semantics of relations subsequently. We evaluate our model on two ZeroRTE datasets. The experiment results show that our method consistently outperforms previous works. Our code will be available at https://anonymous.4open.science/r/PCRED.
Kadabra: Adapting Kademlia for the Decentralized Web
Oct 23, 2022



Blockchains have become the catalyst for a growing movement to create a more decentralized Internet. A fundamental operation of applications in a decentralized Internet is data storage and retrieval. As today's blockchains are limited in their storage functionalities, in recent years a number of peer-to-peer data storage networks have emerged based on the Kademlia distributed hash table protocol. However, existing Kademlia implementations are not efficient enough to support fast data storage and retrieval operations necessary for (decentralized) Web applications. In this paper, we present Kadabra, a decentralized protocol for computing the routing table entries in Kademlia to accelerate lookups. Kadabra is motivated by the multi-armed bandit problem, and can automatically adapt to heterogeneity and dynamism in the network. Experimental results show Kadabra achieving between 15-50% lower lookup latencies compared to state-of-the-art baselines.
Covert Beamforming Design for Intelligent Reflecting Surface Assisted IoT Networks
Sep 01, 2021
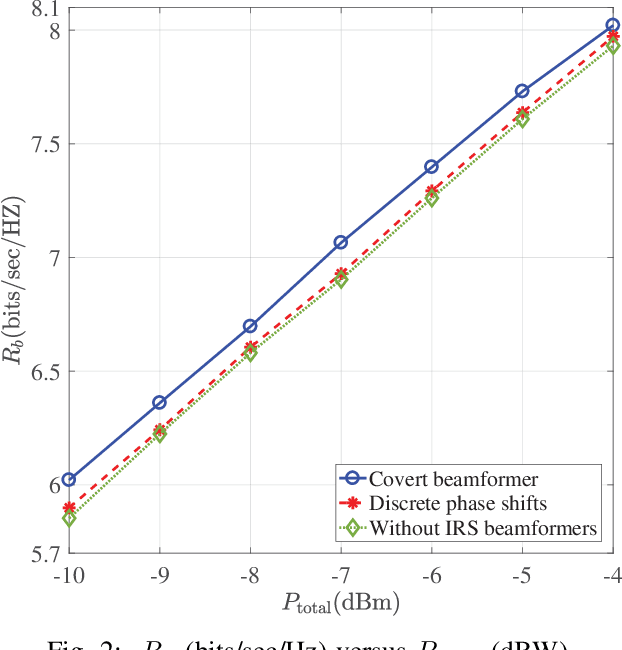
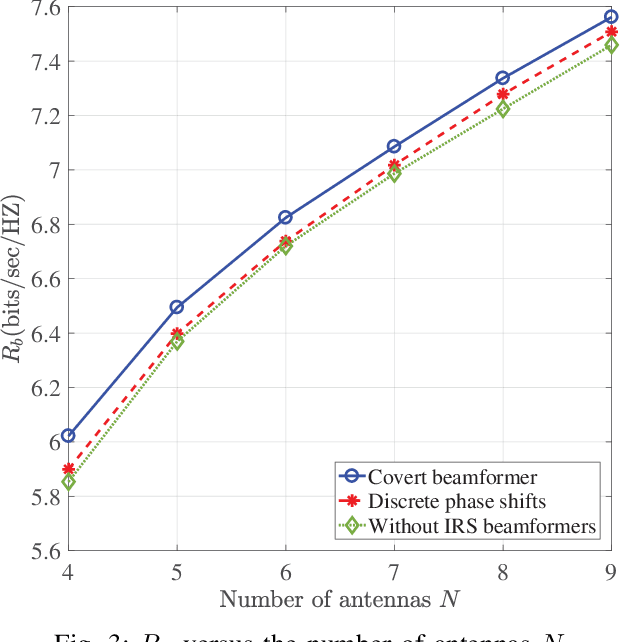
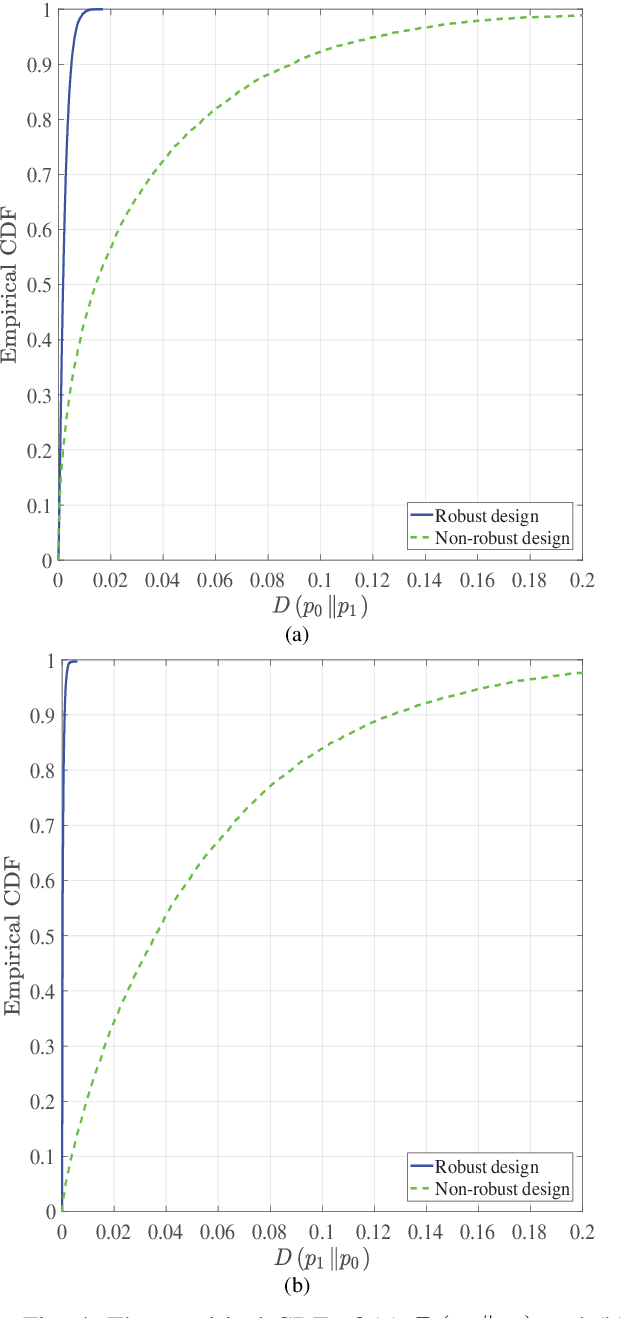
In this paper, we consider covert beamforming design for intelligent reflecting surface (IRS) assisted Internet of Things (IoT) networks, where Alice utilizes IRS to covertly transmit a message to Bob without being recognized by Willie. We investigate the joint beamformer design of Alice and IRS to maximize the covert rate of Bob when the knowledge about Willie's channel state information (WCSI) is perfect and imperfect at Alice, respectively. For the former case, we develop a covert beamformer under the perfect covert constraint by applying semidefinite relaxation. For the later case, the optimal decision threshold of Willie is derived, and we analyze the false alarm and the missed detection probabilities. Furthermore, we utilize the property of Kullback-Leibler divergence to develop the robust beamformer based on a relaxation, S-Lemma and alternate iteration approach. Finally, the numerical experiments evaluate the performance of the proposed covert beamformer design and robust beamformer design.