 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoStruct: Bridging Evolutionary and Structural Priors for Antibody CDR Design via Protein Language Model Adaptation
May 20, 2026Equivariant graph neural network (GNN) methods for antibody complementarity-determining region (CDR) design achieve the highest sequence recovery but suffer from severe vocabulary collapse. The current best GNN methods over-predict very few amino acids, such as tyrosine and glycine, while ignoring functionally important residues. We trace this failure to GNN encoders learning amino acid distributions de novo from limited structural data, discarding substitution patterns encoded in evolutionary databases. To resolve this, we propose EvoStruct, which bridges a frozen protein language model (PLM) with 3D structural context from an E(3)-equivariant GNN via a cross-attention adapter. Unlike prior PLM-structure adapters for general protein design, EvoStruct targets the vocabulary collapse problem specific to CDR design through progressive PLM unfreezing and R-Drop consistency regularization. On the CHIMERA-Bench dataset, EvoStruct achieves the highest amino acid recovery and lowest perplexity among several antibody design methods, improving sequence recovery by 16% and reducing perplexity by 43% relative to the best GNN baselines, while recovering 2.3x greater amino acid diversity and the highest binding-pair correlation with ground truth.
ConTact: Contact-First Antibody CDR Design via Explicit Interface Reasoning
May 20, 2026Computational antibody CDR design methods condition on antigen structure to generate binding loops, yet existing architectures conflate two fundamentally distinct sub-problems: identifying which CDR positions will contact the antigen, and selecting amino acids at those positions. This conflation forces models to learn contact reasoning implicitly through uniform message passing, diluting antigen signal across all positions equally. We introduce ConTact, a contact-then-act architecture that explicitly decomposes CDR design into three cascaded stages: learning surface complementarity fingerprints, predicting CDR-antigen contacts, and injecting contact-gated antigen features into the sequence head. A distance-biased cross-attention module encodes geometric priors favoring spatial neighbors, while a contact-weighted cross-entropy loss concentrates gradient signal on binding-critical positions. On CHIMERA-Bench dataset, ConTact achieves the best structural quality (7% RMSD improvement over the next-best baseline), best epitope awareness (10% F1 score over GNN baselines), and competitive sequence recovery (AAR 0.38) among several CDR-H3 design baselines.
Cooperative Informative Sensing for Monitoring Dynamic Indoor Environments via Multi-Agent Reinforcement Learning
Apr 25, 2026Monitoring human activity in indoor environments is important for applications such as facility management, safety assessment, and space utilization analysis. While mobile robot teams offer the potential to actively improve observation quality, existing multi-robot monitoring and active perception approaches typically rely on coverage or visitation based objectives that are weakly aligned with the accuracy requirements of human-centric monitoring tasks. In this work, we formulate cooperative active observation as a decentralized control problem in which multiple robots adjust their motion to directly optimize monitoring accuracy under partial observability. We propose a learning-based framework for cooperative policies from decentralized observations using multi-agent reinforcement learning (MARL), supported by an architecture that handles variable numbers of humans and temporal dependencies. Simulation results across diverse indoor environments and monitoring tasks show that the proposed approach consistently outperforms classical coverage, persistent monitoring, and learning-free multi-robot baselines, while remaining robust to changes in the number of observed humans.
An Application of Large Language Models to Coding Negotiation Transcripts
Jul 18, 2024



In recent years, Large Language Models (LLM) have demonstrated impressive capabilities in the field of natural language processing (NLP). This paper explores the application of LLMs in negotiation transcript analysis by the Vanderbilt AI Negotiation Lab. Starting in September 2022, we applied multiple strategies using LLMs from zero shot learning to fine tuning models to in-context learning). The final strategy we developed is explained, along with how to access and use the model. This study provides a sense of both the opportunities and roadblocks for the implementation of LLMs in real life applications and offers a model for how LLMs can be applied to coding in other fields.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Image Compression with Recurrent Neural Network and Generalized Divisive Normalization
Sep 05, 2021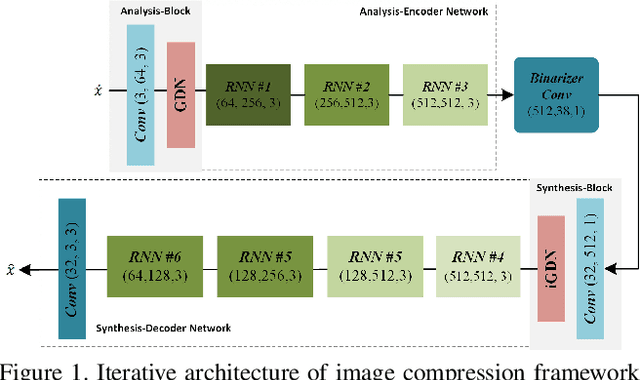
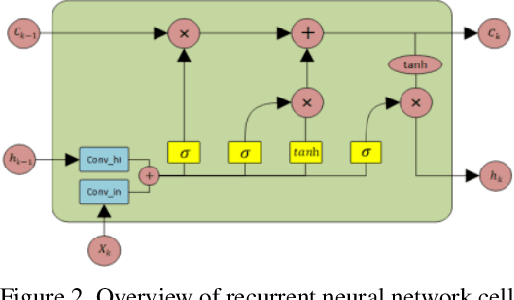
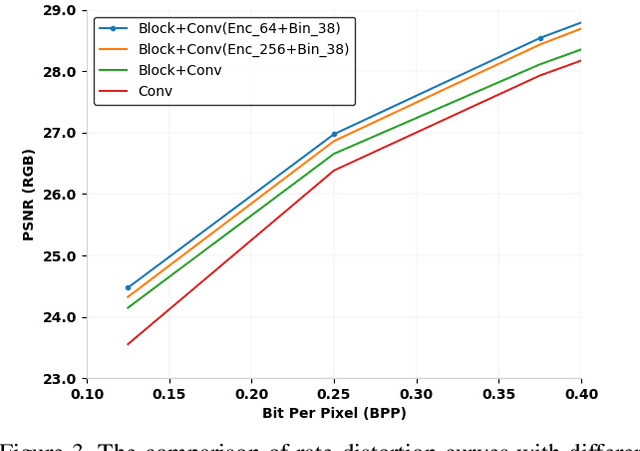
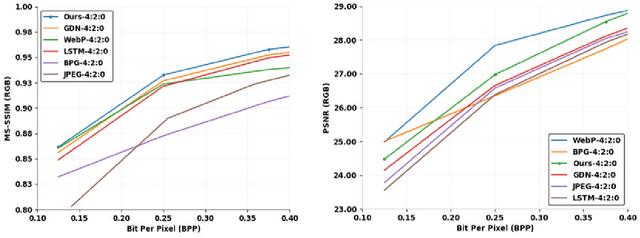
Image compression is a method to remove spatial redundancy between adjacent pixels and reconstruct a high-quality image. In the past few years, deep learning has gained huge attention from the research community and produced promising image reconstruction results. Therefore, recent methods focused on developing deeper and more complex networks, which significantly increased network complexity. In this paper, two effective novel blocks are developed: analysis and synthesis block that employs the convolution layer and Generalized Divisive Normalization (GDN) in the variable-rate encoder and decoder side. Our network utilizes a pixel RNN approach for quantization. Furthermore, to improve the whole network, we encode a residual image using LSTM cells to reduce unnecessary information. Experimental results demonstrated that the proposed variable-rate framework with novel blocks outperforms existing methods and standard image codecs, such as George's ~\cite{002} and JPEG in terms of image similarity. The project page along with code and models are available at https://khawar512.github.io/cvpr/
Informative Path Planning and Mapping with Multiple UAVs in Wind Fields
Oct 05, 2016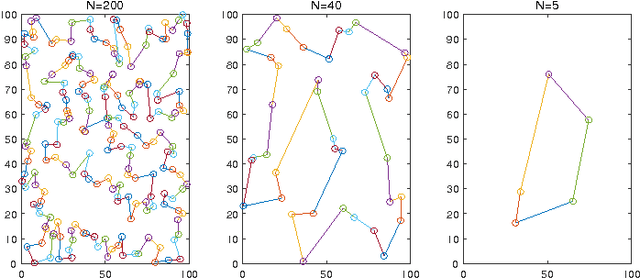
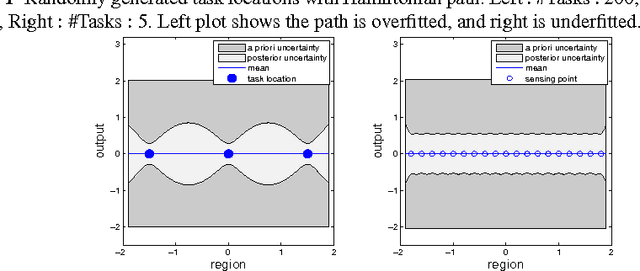
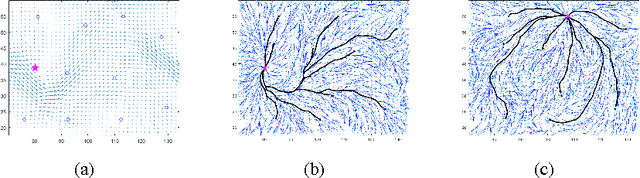
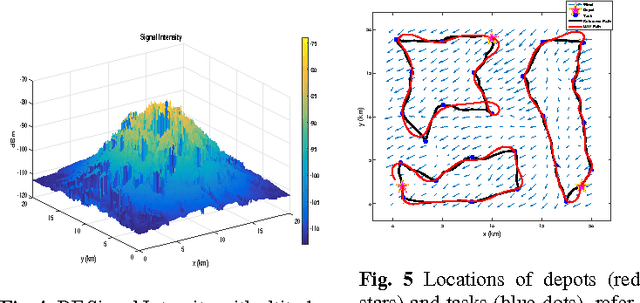
Informative path planning (IPP) is used to design paths for robotic sensor platforms to extract the best/maximum possible information about a quantity of interest while operating under a set of constraints, such as the dynamic feasibility of vehicles. The key challenges of IPP are the strong coupling in multiple layers of decisions: the selection of locations to visit, the allocation of sensor platforms to those locations; and the processing of the gathered information along the paths. This paper presents a systematic procedure for IPP and environmental mapping using multiple UAV sensor platforms. It (a) selects the best locations to observe, (b) calculates the cost and finds the best paths for each UAV, and (c) estimates the measurement value within a given region using the Gaussian process (GP) regression framework. An illustrative example of RF intensity field mapping is presented to demonstrate the validity and applicability of the proposed approach.