 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed Resource Allocation Optimization for User-Centric Cell-Free MIMO Networks
Oct 15, 2021
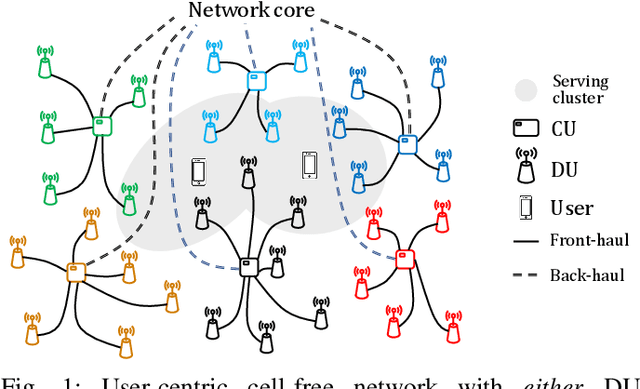
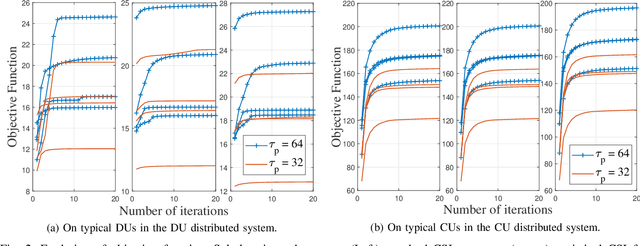
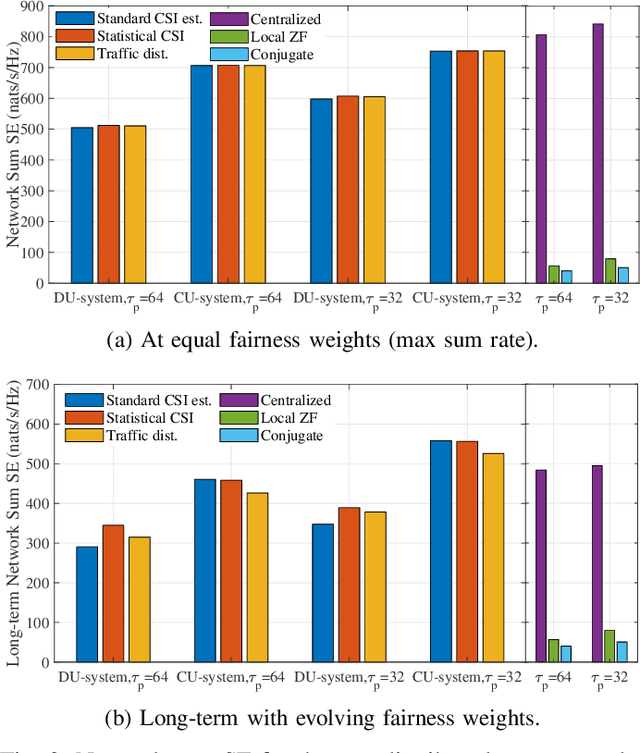
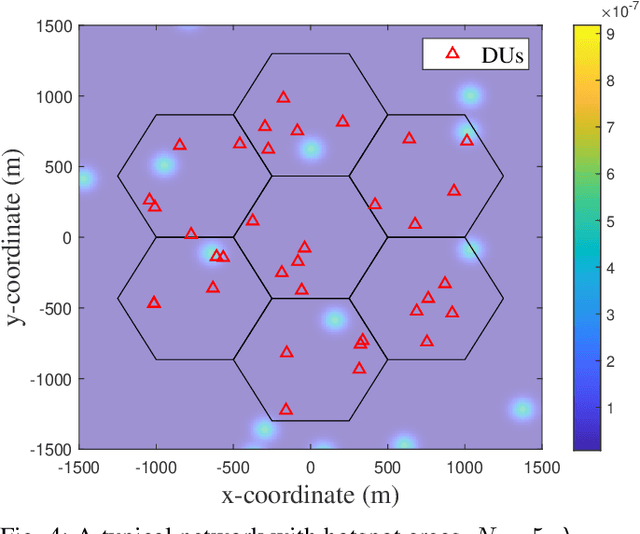
We develop two distributed downlink resource allocation algorithms for user-centric, cell-free, spatially-distributed, multiple-input multiple-output (MIMO) networks. In such networks, each user is served by a subset of nearby transmitters that we call distributed units or DUs. The operation of the DUs in a region is controlled by a central unit (CU). Our first scheme is implemented at the DUs, while the second is implemented at the CUs controlling these DUs. We define a hybrid quality of service metric that enables distributed optimization of system resources in a proportional fair manner. Specifically, each of our algorithms performs user scheduling, beamforming, and power control while accounting for channel estimation errors. Importantly, our algorithm does not require information exchange amongst DUs (CUs) for the DU-distributed (CU-distributed) system, while also smoothly converging. Our results show that our CU-distributed system provides 1.3- to 1.8-fold network throughput compared to the DU-distributed system, with minor increases in complexity and front-haul load - and substantial gains over benchmark schemes like local zero-forcing. We also analyze the trade-offs provided by the CU-distributed system, hence highlighting the significance of deploying multiple CUs in user-centric cell-free networks.
Optimal Auction Design for the Gradual Procurement of Strategic Service Provider Agents
Oct 25, 2021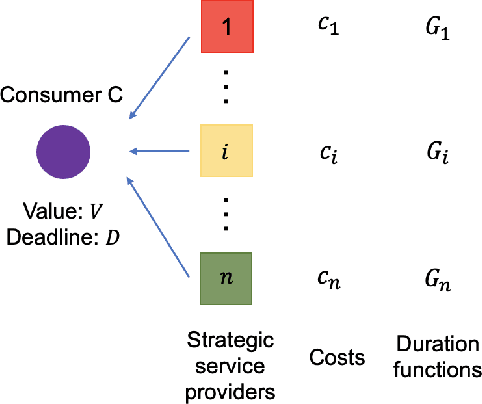
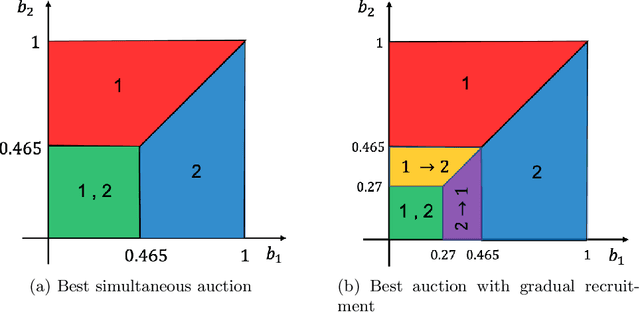
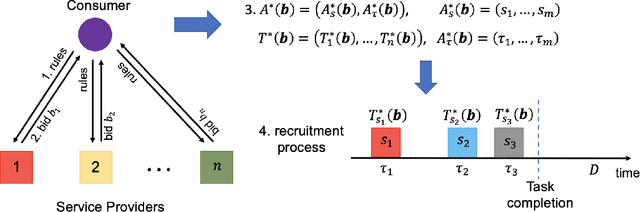
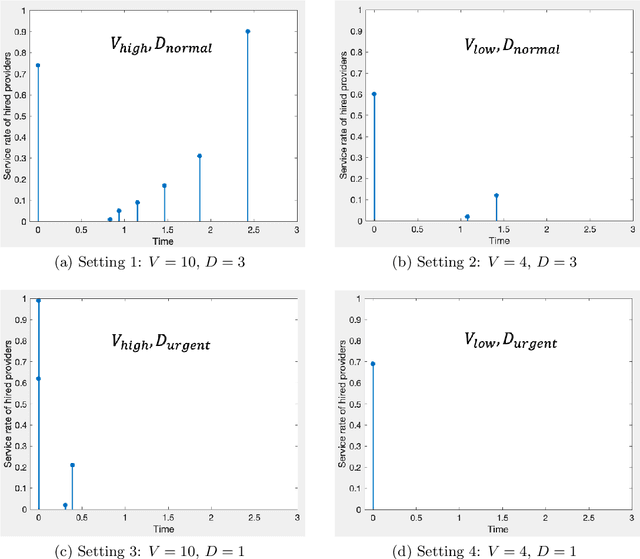
We consider an outsourcing problem where a software agent procures multiple services from providers with uncertain reliabilities to complete a computational task before a strict deadline. The service consumer requires a procurement strategy that achieves the optimal balance between success probability and invocation cost. However, the service providers are self-interested and may misrepresent their private cost information if it benefits them. For such settings, we design a novel procurement auction that provides the consumer with the highest possible revenue, while giving sufficient incentives to providers to tell the truth about their costs. This auction creates a contingent plan for gradual service procurement that suggests recruiting a new provider only when the success probability of the already hired providers drops below a time-dependent threshold. To make this auction incentive compatible, we propose a novel weighted threshold payment scheme which pays the minimum among all truthful mechanisms. Using the weighted payment scheme, we also design a low-complexity near-optimal auction that reduces the computational complexity of the optimal mechanism by 99% with only marginal performance loss (less than 1%). We demonstrate the effectiveness and strength of our proposed auctions through both game theoretical and numerical analysis. The experiment results confirm that the proposed auctions exhibit 59% improvement in performance over the current state-of-the-art, by increasing success probability up to 79% and reducing invocation cost by up to 11%.
Target Adaptive Context Aggregation for Video Scene Graph Generation
Aug 18, 2021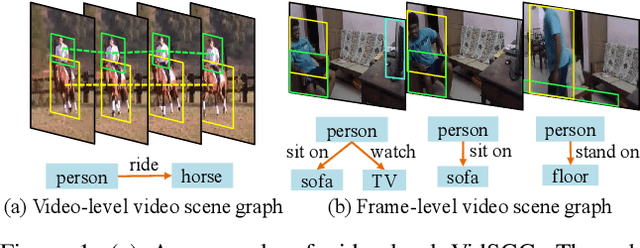

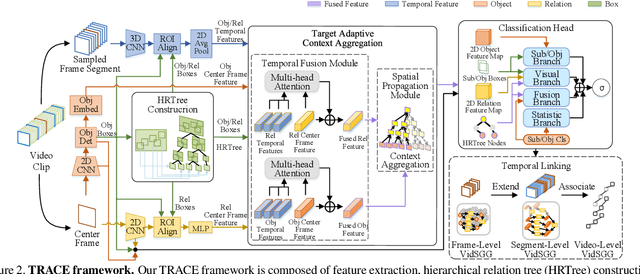
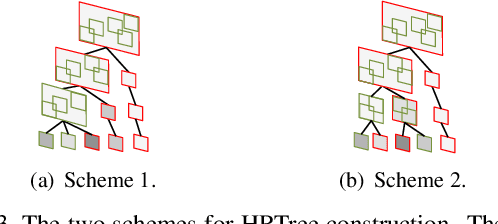
This paper deals with a challenging task of video scene graph generation (VidSGG), which could serve as a structured video representation for high-level understanding tasks. We present a new {\em detect-to-track} paradigm for this task by decoupling the context modeling for relation prediction from the complicated low-level entity tracking. Specifically, we design an efficient method for frame-level VidSGG, termed as {\em Target Adaptive Context Aggregation Network} (TRACE), with a focus on capturing spatio-temporal context information for relation recognition. Our TRACE framework streamlines the VidSGG pipeline with a modular design, and presents two unique blocks of Hierarchical Relation Tree (HRTree) construction and Target-adaptive Context Aggregation. More specific, our HRTree first provides an adpative structure for organizing possible relation candidates efficiently, and guides context aggregation module to effectively capture spatio-temporal structure information. Then, we obtain a contextualized feature representation for each relation candidate and build a classification head to recognize its relation category. Finally, we provide a simple temporal association strategy to track TRACE detected results to yield the video-level VidSGG. We perform experiments on two VidSGG benchmarks: ImageNet-VidVRD and Action Genome, and the results demonstrate that our TRACE achieves the state-of-the-art performance. The code and models are made available at \url{https://github.com/MCG-NJU/TRACE}.
SGEN: Single-cell Sequencing Graph Self-supervised Embedding Network
Oct 15, 2021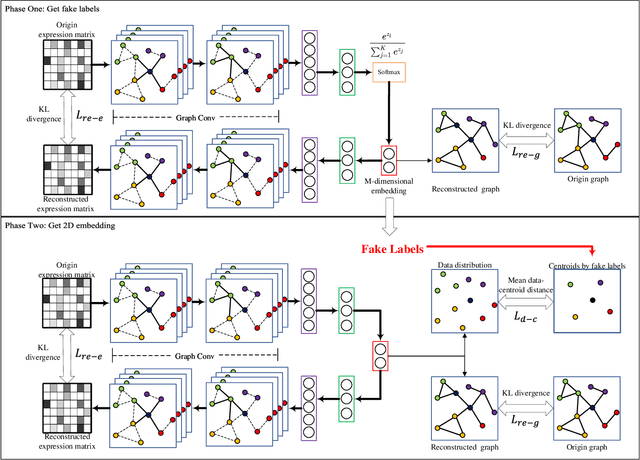
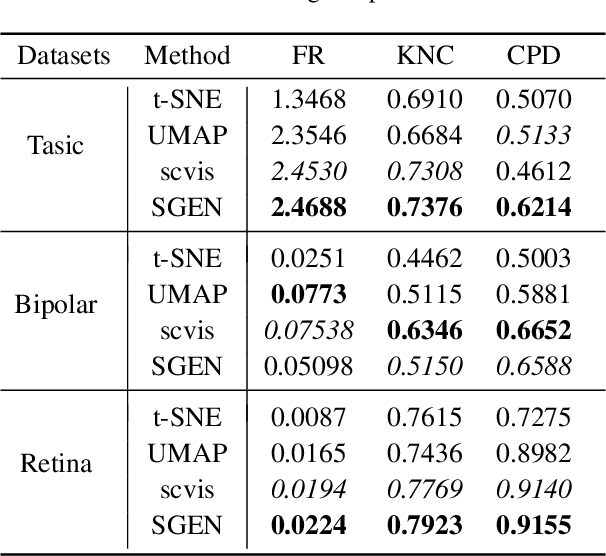
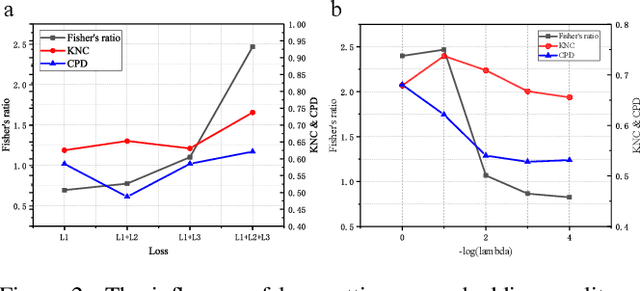
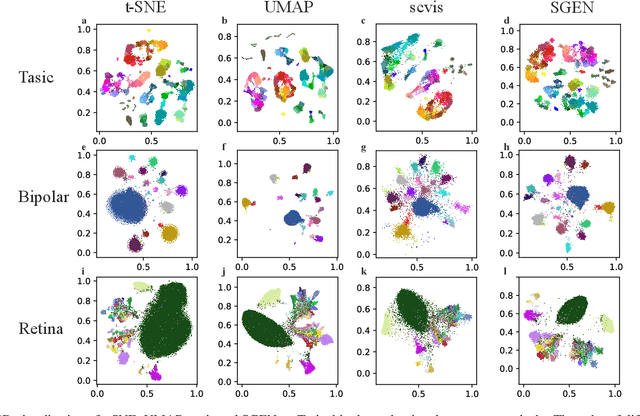
Single-cell sequencing has a significant role to explore biological processes such as embryonic development, cancer evolution, and cell differentiation. These biological properties can be presented by a two-dimensional scatter plot. However, single-cell sequencing data generally has very high dimensionality. Therefore, dimensionality reduction should be used to process the high dimensional sequencing data for 2D visualization and subsequent biological analysis. The traditional dimensionality reduction methods, which do not consider the structure characteristics of single-cell sequencing data, are difficult to reveal the data structure in the 2D representation. In this paper, we develop a 2D feature representation method based on graph convolutional networks (GCN) for the visualization of single-cell data, termed single-cell sequencing graph embedding networks (SGEN). This method constructs the graph by the similarity relationship between cells and adopts GCN to analyze the neighbor embedding information of samples, which makes the similar cell closer to each other on the 2D scatter plot. The results show SGEN achieves obvious 2D distribution and preserves the high-dimensional relationship of different cells. Meanwhile, similar cell clusters have spatial continuity rather than relying heavily on random initialization, which can reflect the trajectory of cell development in this scatter plot.
An information theoretic approach to the autoencoder
Jan 23, 2019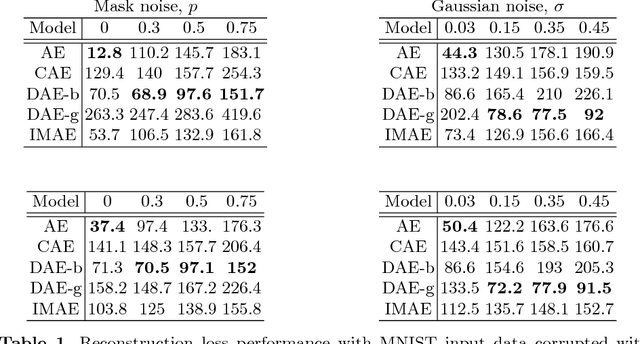
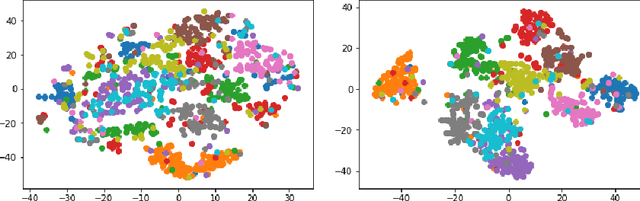

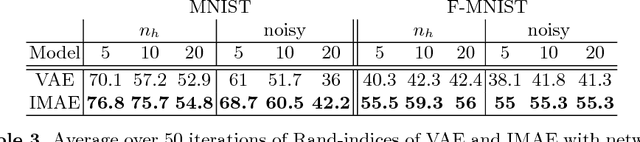
We present a variation of the Autoencoder (AE) that explicitly maximizes the mutual information between the input data and the hidden representation. The proposed model, the InfoMax Autoencoder (IMAE), by construction is able to learn a robust representation and good prototypes of the data. IMAE is compared both theoretically and then computationally with the state of the art models: the Denoising and Contractive Autoencoders in the one-hidden layer setting and the Variational Autoencoder in the multi-layer case. Computational experiments are performed with the MNIST and Fashion-MNIST datasets and demonstrate particularly the strong clusterization performance of IMAE.
Adversarial Examples Generation for Reducing Implicit Gender Bias in Pre-trained Models
Oct 03, 2021
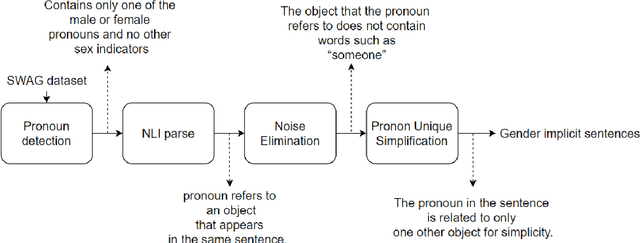

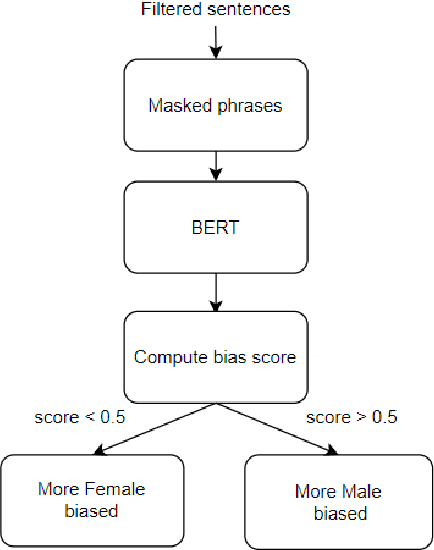
Over the last few years, Contextualized Pre-trained Neural Language Models, such as BERT, GPT, have shown significant gains in various NLP tasks. To enhance the robustness of existing pre-trained models, one way is adversarial examples generation and evaluation for conducting data augmentation or adversarial learning. In the meanwhile, gender bias embedded in the models seems to be a serious problem in practical applications. Many researches have covered the gender bias produced by word-level information(e.g. gender-stereotypical occupations), while few researchers have investigated the sentence-level cases and implicit cases. In this paper, we proposed a method to automatically generate implicit gender bias samples at sentence-level and a metric to measure gender bias. Samples generated by our method will be evaluated in terms of accuracy. The metric will be used to guide the generation of examples from Pre-trained models. Therefore, those examples could be used to impose attacks on Pre-trained Models. Finally, we discussed the evaluation efficacy of our generated examples on reducing gender bias for future research.
Regularized Learning in Banach Spaces
Sep 07, 2021This article presents a different way to study the theory of regularized learning for generalized data including representer theorems and convergence theorems. The generalized data are composed of linear functionals and real scalars to represent the discrete information of the local models. By the extension of the classical machine learning, the empirical risks are computed by the generalized data and the loss functions. According to the techniques of regularization, the global solutions are approximated by minimizing the regularized empirical risks over the Banach spaces. The Banach spaces are adaptively chosen to endow the generalized input data with compactness such that the existence and convergence of the approximate solutions are guaranteed by the weak* topology.
Grant-Free Random Access in Massive MIMO for Static Low-Power IoT Nodes
Oct 15, 2021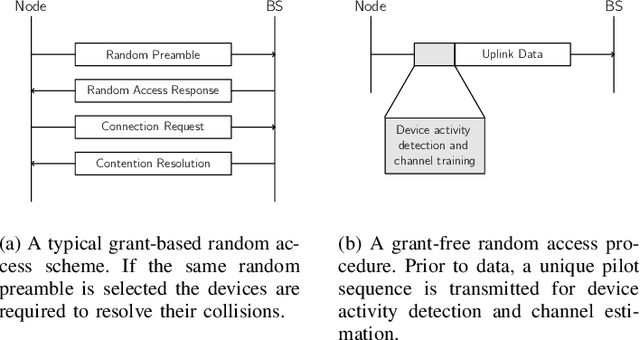
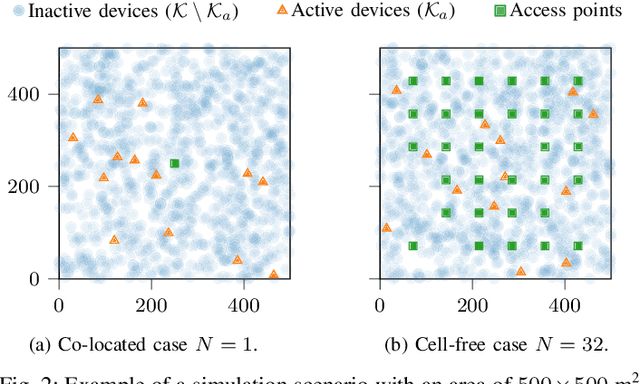
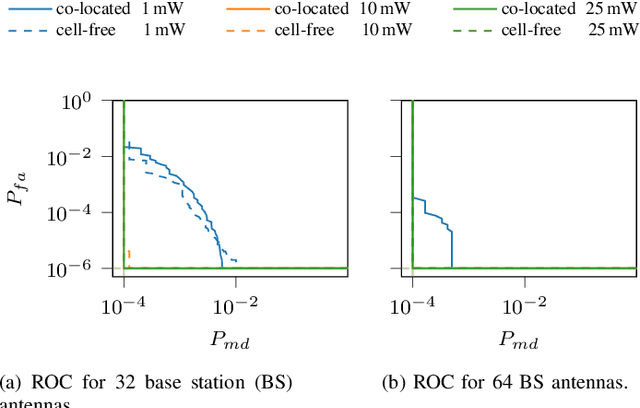
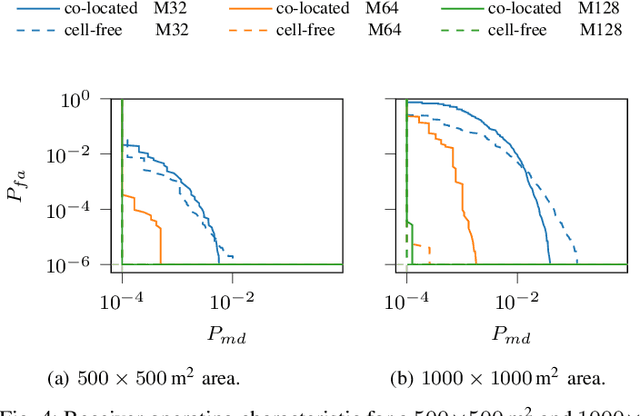
Massive MIMO is a promising technology to enable a massive number of Internet of Things nodes to transmit short and sporadic data bursts at low power. In conventional cellular networks, devices use a grant-based random access scheme to initiate communications. This scheme relies on a limited set of orthogonal preambles, which simplify signal processing operations at network access points. However, it is not well suited for Internet of Things (IoT) devices due to: (i) the large protocol overhead, and (ii) the high probability of collision. In contrast to the grant-based scheme, a grant-free approach uses user-specific preambles and has a small overhead, at the expense of more complexity at access points. In this work, a grant-free method is proposed, applicable for both co-located and cell-free deployments. The method has a closed form solution, which results in a significantly low complexity with respect to the state-of-the art. The algorithm exploits the static nature of IoT devices through the use of prior channel state information. With a power budget of 1 mW, 64 antennas are sufficient to support 1000 nodes with 200 simultaneous access requests with a probability of false alarm and miss detection below 10-6 and 10-4, respectively.
Session-based Recommendation with Heterogeneous Graph Neural Network
Aug 12, 2021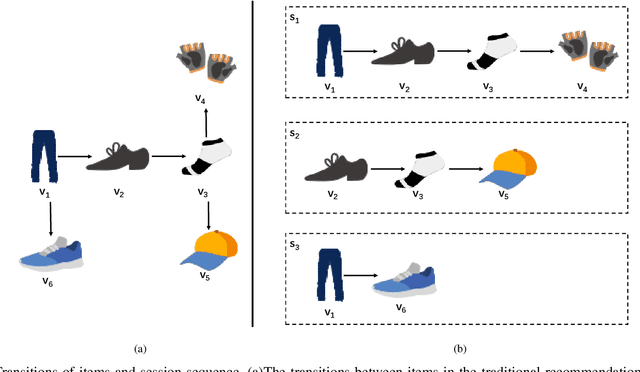
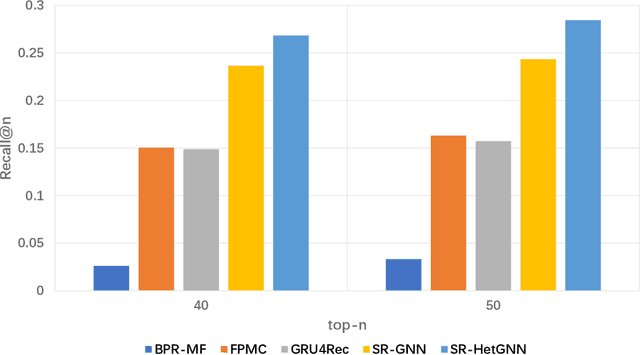
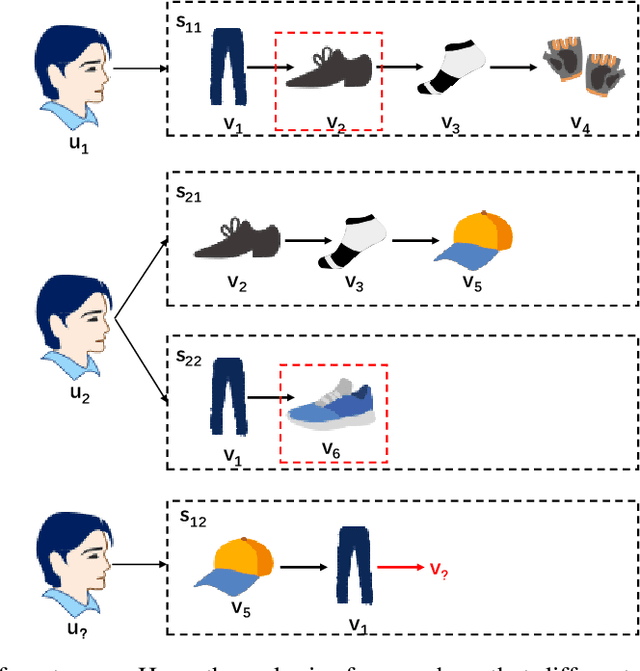
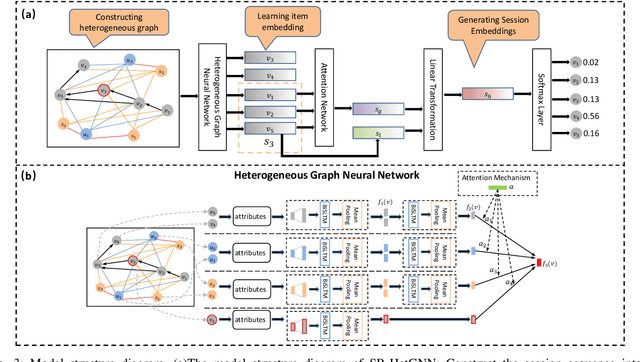
The purpose of the Session-Based Recommendation System is to predict the user's next click according to the previous session sequence. The current studies generally learn user preferences according to the transitions of items in the user's session sequence. However, other effective information in the session sequence, such as user profiles, are largely ignored which may lead to the model unable to learn the user's specific preferences. In this paper, we propose a heterogeneous graph neural network-based session recommendation method, named SR-HetGNN, which can learn session embeddings by heterogeneous graph neural network (HetGNN), and capture the specific preferences of anonymous users. Specifically, SR-HetGNN first constructs heterogeneous graphs containing various types of nodes according to the session sequence, which can capture the dependencies among items, users, and sessions. Second, HetGNN captures the complex transitions between items and learns the item embeddings containing user information. Finally, to consider the influence of users' long and short-term preferences, local and global session embeddings are combined with the attentional network to obtain the final session embedding. SR-HetGNN is shown to be superior to the existing state-of-the-art session-based recommendation methods through extensive experiments over two real large datasets Diginetica and Tmall.
Thermal Image Super-Resolution Using Second-Order Channel Attention with Varying Receptive Fields
Jul 30, 2021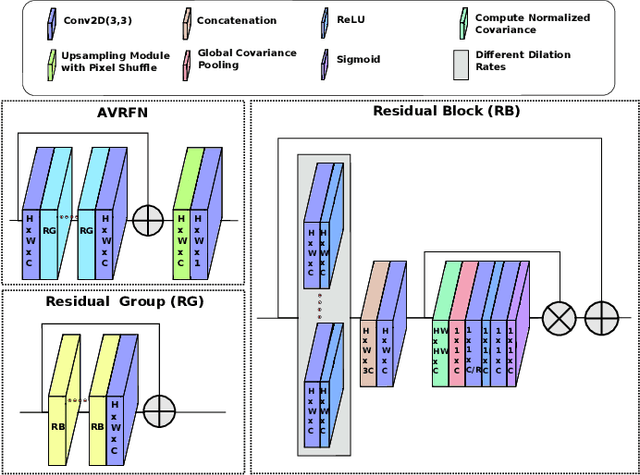
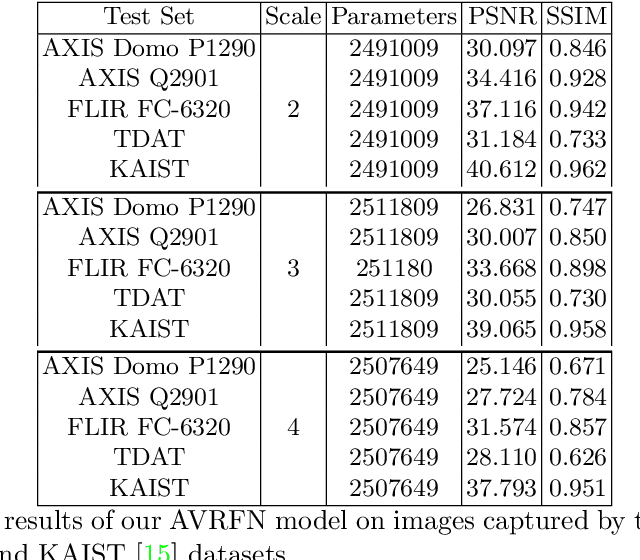
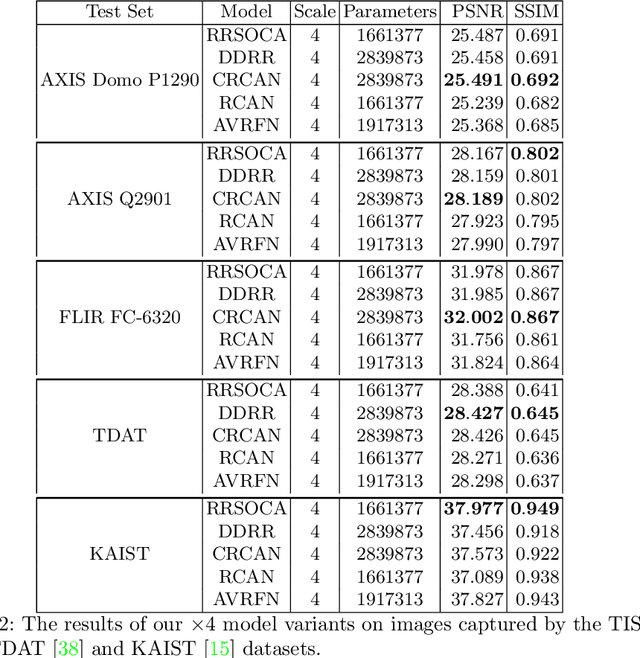

Thermal images model the long-infrared range of the electromagnetic spectrum and provide meaningful information even when there is no visible illumination. Yet, unlike imagery that represents radiation from the visible continuum, infrared images are inherently low-resolution due to hardware constraints. The restoration of thermal images is critical for applications that involve safety, search and rescue, and military operations. In this paper, we introduce a system to efficiently reconstruct thermal images. Specifically, we explore how to effectively attend to contrasting receptive fields (RFs) where increasing the RFs of a network can be computationally expensive. For this purpose, we introduce a deep attention to varying receptive fields network (AVRFN). We supply a gated convolutional layer with higher-order information extracted from disparate RFs, whereby an RF is parameterized by a dilation rate. In this way, the dilation rate can be tuned to use fewer parameters thus increasing the efficacy of AVRFN. Our experimental results show an improvement over the state of the art when compared against competing thermal image super-resolution methods.