 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Variational InfoMax Learning Objective
Mar 07, 2020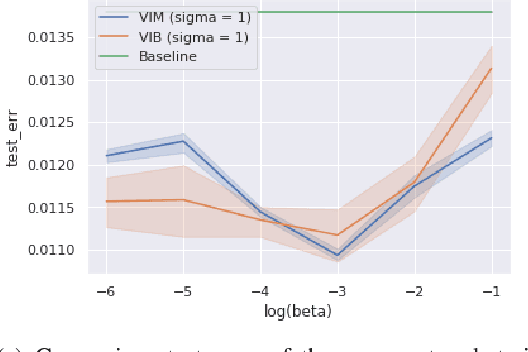
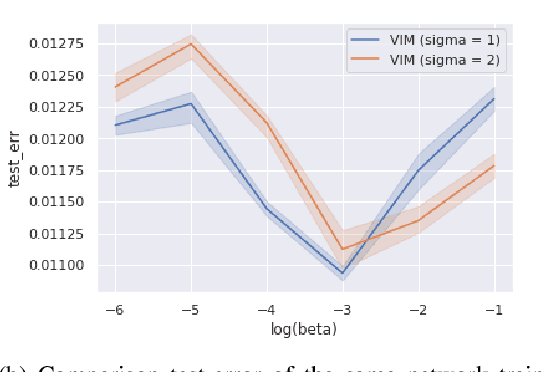

Bayesian Inference and Information Bottleneck are the two most popular objectives for neural networks, but they can be optimised only via a variational lower bound: the Variational Information Bottleneck (VIB). In this manuscript we show that the two objectives are actually equivalent to the InfoMax: maximise the information between the data and the labels. The InfoMax representation of the two objectives is not relevant only per se, since it helps to understand the role of the network capacity, but also because it allows us to derive a variational objective, the Variational InfoMax (VIM), that maximises them directly without resorting to any lower bound. The theoretical improvement of VIM over VIB is highlighted by the computational experiments, where the model trained by VIM improves the VIB model in three different tasks: accuracy, robustness to noise and representation quality.
The variational infomax autoencoder
May 25, 2019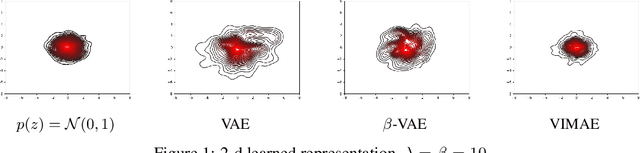
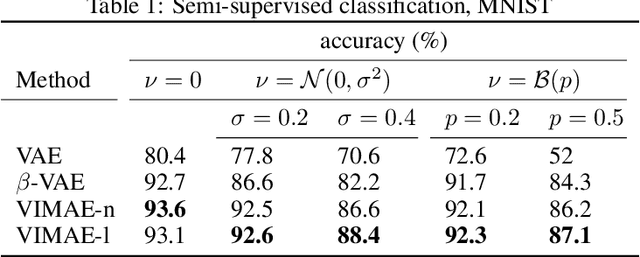


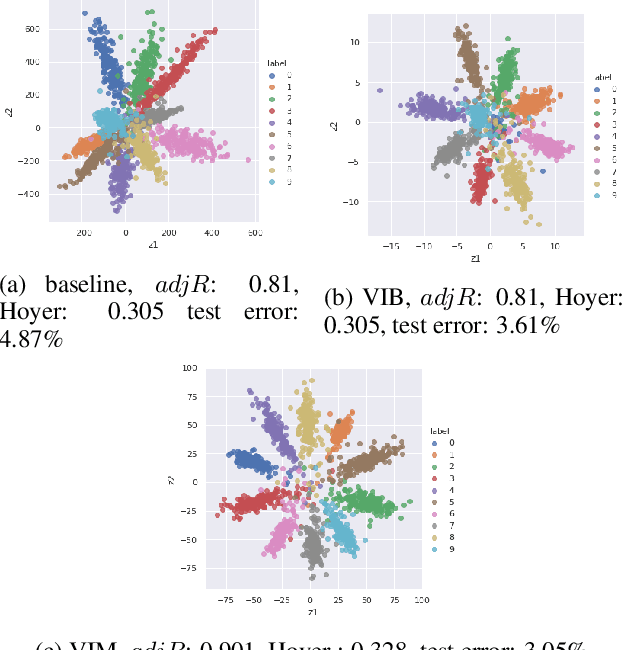
We propose the Variational InfoMax AutoEncoder (VIMAE), a method to train a generative model, maximizing the variational lower bound of the mutual information between the visible data and the hidden representation, maintaining bounded the capacity of the network. In the paper we investigate the capacity role in a neural network and deduce that a small capacity network tends to learn a more robust and disentangled representation than an high capacity one. Such observations are confirmed by the computational experiments.
An information theoretic approach to the autoencoder
Jan 23, 2019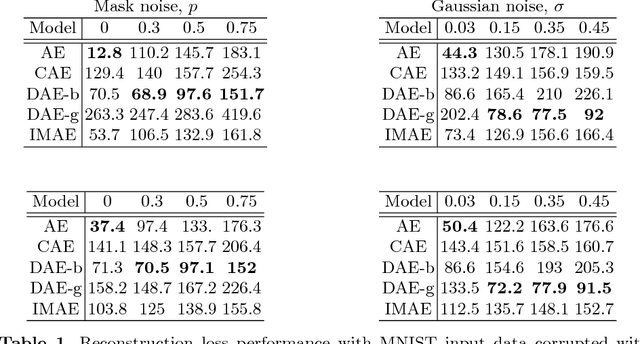
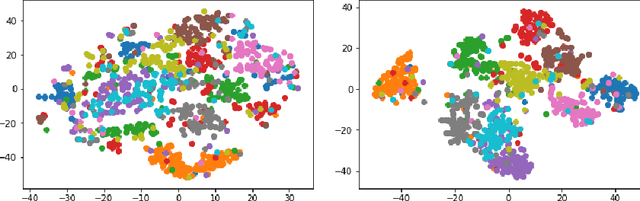

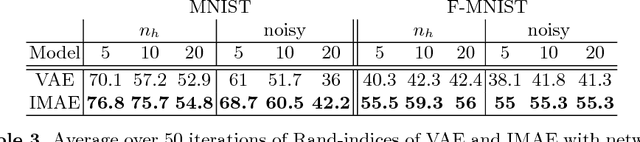
We present a variation of the Autoencoder (AE) that explicitly maximizes the mutual information between the input data and the hidden representation. The proposed model, the InfoMax Autoencoder (IMAE), by construction is able to learn a robust representation and good prototypes of the data. IMAE is compared both theoretically and then computationally with the state of the art models: the Denoising and Contractive Autoencoders in the one-hidden layer setting and the Variational Autoencoder in the multi-layer case. Computational experiments are performed with the MNIST and Fashion-MNIST datasets and demonstrate particularly the strong clusterization performance of IMAE.