 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
WaveCorr: Correlation-savvy Deep Reinforcement Learning for Portfolio Management
Sep 14, 2021

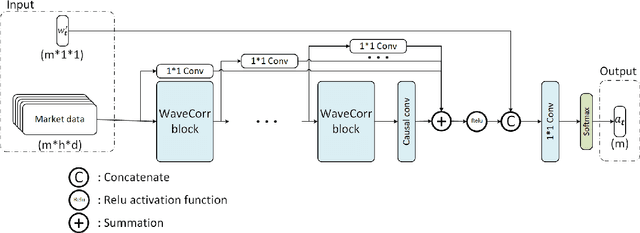
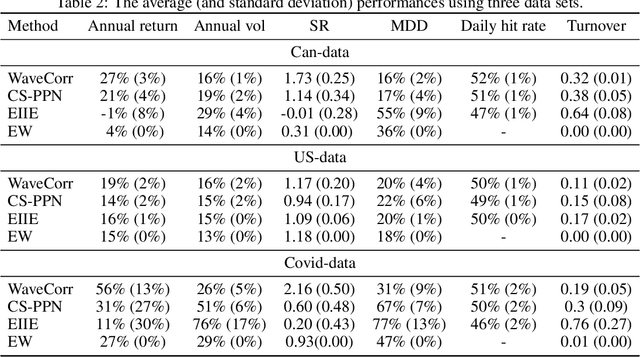
The problem of portfolio management represents an important and challenging class of dynamic decision making problems, where rebalancing decisions need to be made over time with the consideration of many factors such as investors preferences, trading environments, and market conditions. In this paper, we present a new portfolio policy network architecture for deep reinforcement learning (DRL)that can exploit more effectively cross-asset dependency information and achieve better performance than state-of-the-art architectures. In particular, we introduce a new property, referred to as \textit{asset permutation invariance}, for portfolio policy networks that exploit multi-asset time series data, and design the first portfolio policy network, named WaveCorr, that preserves this invariance property when treating asset correlation information. At the core of our design is an innovative permutation invariant correlation processing layer. An extensive set of experiments are conducted using data from both Canadian (TSX) and American stock markets (S&P 500), and WaveCorr consistently outperforms other architectures with an impressive 3%-25% absolute improvement in terms of average annual return, and up to more than 200% relative improvement in average Sharpe ratio. We also measured an improvement of a factor of up to 5 in the stability of performance under random choices of initial asset ordering and weights. The stability of the network has been found as particularly valuable by our industrial partner.
Signal power and energy-per-bit optimization problems in systems mMTC
Sep 29, 2021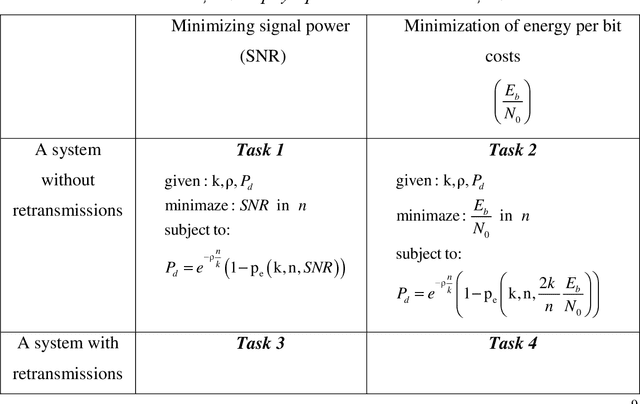
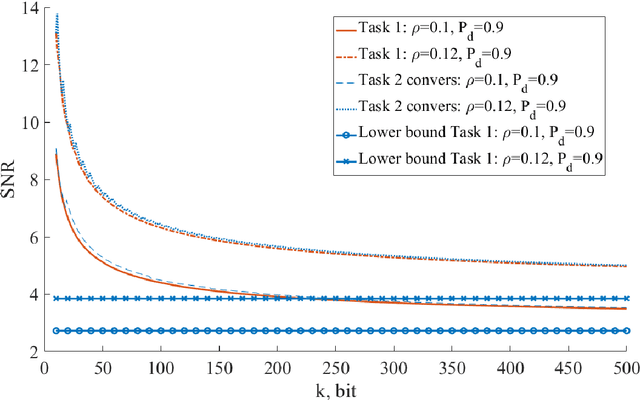

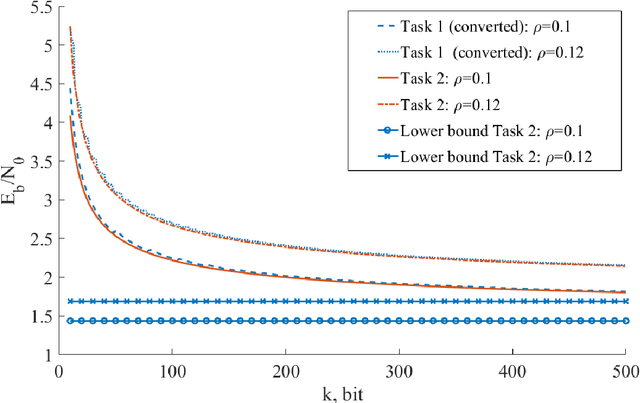
Currently, the issues of the operation of the Internet of Things technology are being actively studied. The operation of a large number of different self-powered sensors is within the framework of a massive machine-type communications scenario using random access methods. Topical issues in this type of communication are: reducing the transmission signal power and increasing the duration of the device by reducing the consumption energy per bit. Formulation and analysis of the tasks of minimizing transmission power and spent energy per bit in systems without retransmissions and with retransmissions to obtain achievability bounds. A model of the system is described, within which four problems of minimizing signal power and energy consumption for given parameters (the number of information bits, the spectral efficiency of the system, and the Packet Delivery Ratio) are formulated and described. The numerical results of solving these optimization problems are presented, which make it possible to obtain the achievability bounds for the considered characteristics in systems with and without losses. The lower bounds obtained by the Shannon formula are presented, assuming that the message length is not limited. The results obtained showed that solving the minimization problem with respect to one of the parameters (signal power or consumption energy per bit) does not minimize the second parameter. This difference is most significant for small information message lengths, which corresponds to IoT scenarios. The results obtained allow assessing the potential for minimizing transmission signal power and consumption energy per bit in random multiple access systems with massive machine-type communications scenarios. The presented problems were solved without taking into account the average delay of message transmission.
We've had this conversation before: A Novel Approach to Measuring Dialog Similarity
Oct 12, 2021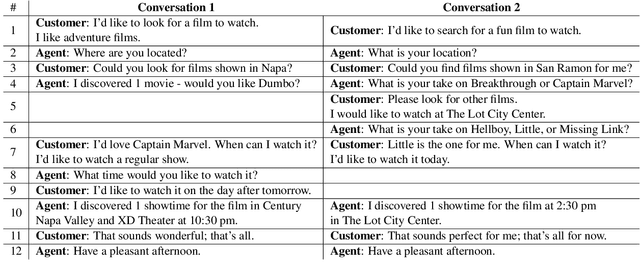
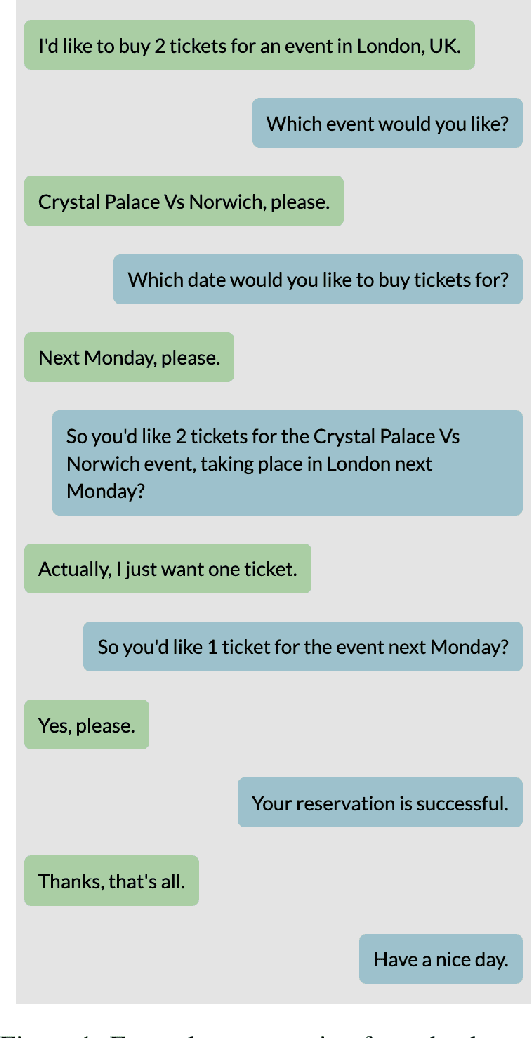
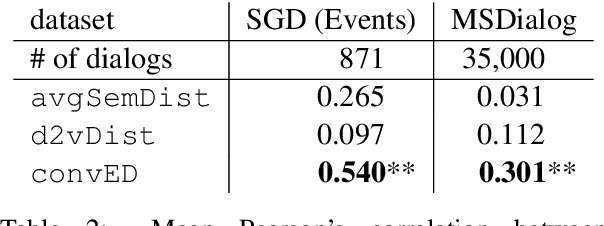
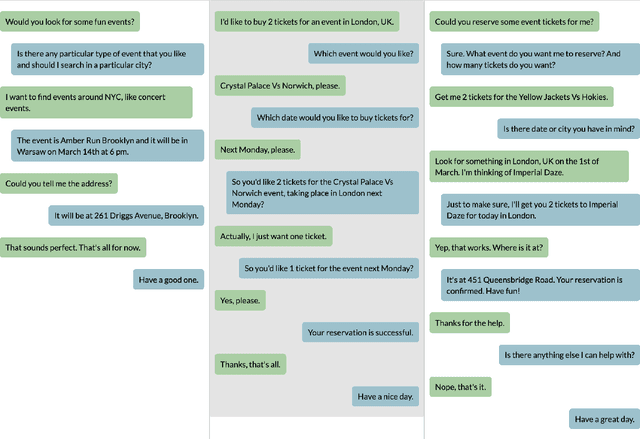
Dialog is a core building block of human natural language interactions. It contains multi-party utterances used to convey information from one party to another in a dynamic and evolving manner. The ability to compare dialogs is beneficial in many real world use cases, such as conversation analytics for contact center calls and virtual agent design. We propose a novel adaptation of the edit distance metric to the scenario of dialog similarity. Our approach takes into account various conversation aspects such as utterance semantics, conversation flow, and the participants. We evaluate this new approach and compare it to existing document similarity measures on two publicly available datasets. The results demonstrate that our method outperforms the other approaches in capturing dialog flow, and is better aligned with the human perception of conversation similarity.
Medical Instrument Segmentation in 3D US by Hybrid Constrained Semi-Supervised Learning
Jul 30, 2021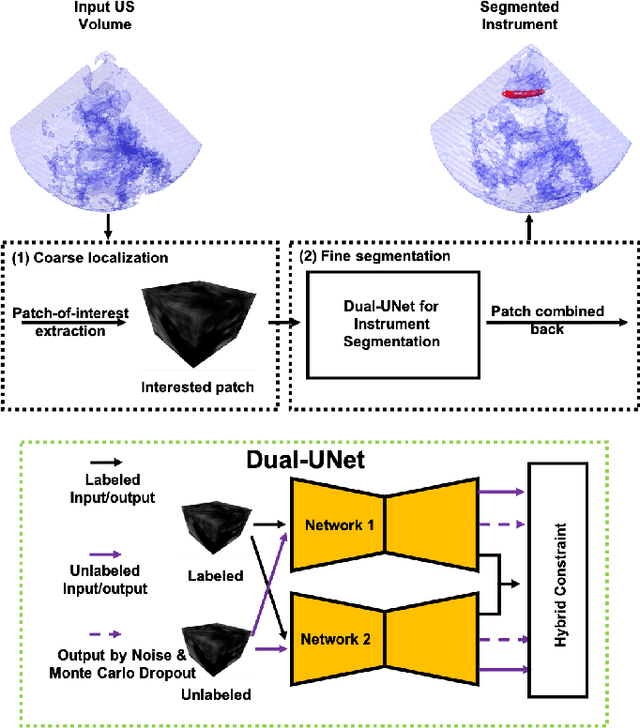

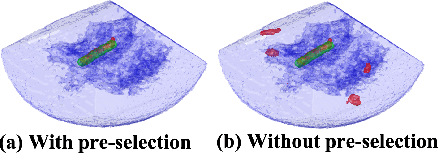
Medical instrument segmentation in 3D ultrasound is essential for image-guided intervention. However, to train a successful deep neural network for instrument segmentation, a large number of labeled images are required, which is expensive and time-consuming to obtain. In this article, we propose a semi-supervised learning (SSL) framework for instrument segmentation in 3D US, which requires much less annotation effort than the existing methods. To achieve the SSL learning, a Dual-UNet is proposed to segment the instrument. The Dual-UNet leverages unlabeled data using a novel hybrid loss function, consisting of uncertainty and contextual constraints. Specifically, the uncertainty constraints leverage the uncertainty estimation of the predictions of the UNet, and therefore improve the unlabeled information for SSL training. In addition, contextual constraints exploit the contextual information of the training images, which are used as the complementary information for voxel-wise uncertainty estimation. Extensive experiments on multiple ex-vivo and in-vivo datasets show that our proposed method achieves Dice score of about 68.6%-69.1% and the inference time of about 1 sec. per volume. These results are better than the state-of-the-art SSL methods and the inference time is comparable to the supervised approaches.
Self-Conditioned Probabilistic Learning of Video Rescaling
Jul 24, 2021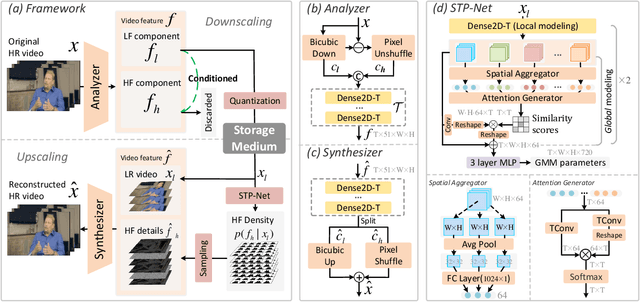
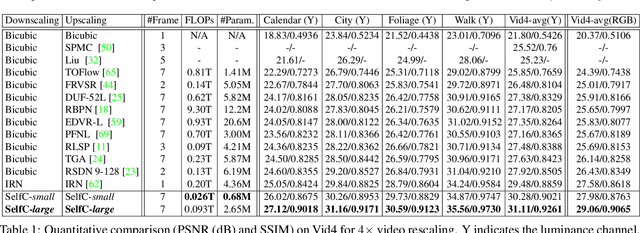
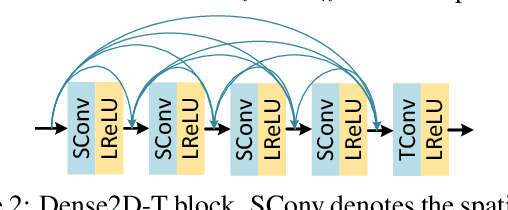

Bicubic downscaling is a prevalent technique used to reduce the video storage burden or to accelerate the downstream processing speed. However, the inverse upscaling step is non-trivial, and the downscaled video may also deteriorate the performance of downstream tasks. In this paper, we propose a self-conditioned probabilistic framework for video rescaling to learn the paired downscaling and upscaling procedures simultaneously. During the training, we decrease the entropy of the information lost in the downscaling by maximizing its probability conditioned on the strong spatial-temporal prior information within the downscaled video. After optimization, the downscaled video by our framework preserves more meaningful information, which is beneficial for both the upscaling step and the downstream tasks, e.g., video action recognition task. We further extend the framework to a lossy video compression system, in which a gradient estimator for non-differential industrial lossy codecs is proposed for the end-to-end training of the whole system. Extensive experimental results demonstrate the superiority of our approach on video rescaling, video compression, and efficient action recognition tasks.
Spatio-Temporal Interaction Graph Parsing Networks for Human-Object Interaction Recognition
Aug 19, 2021
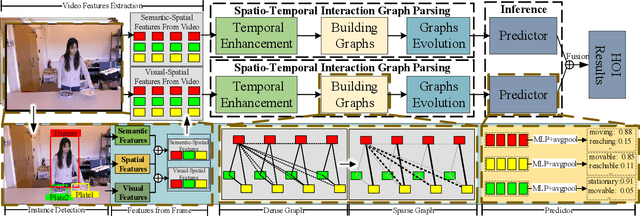
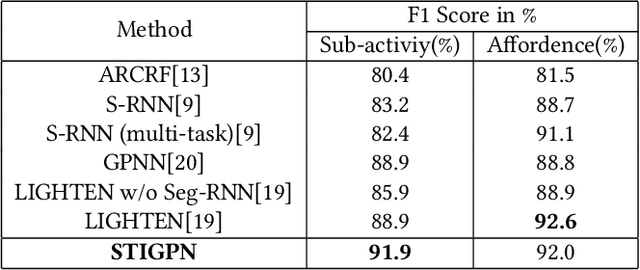
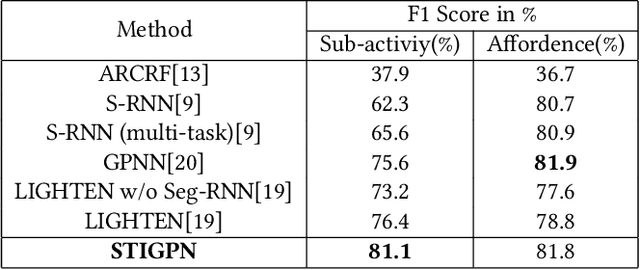
For a given video-based Human-Object Interaction scene, modeling the spatio-temporal relationship between humans and objects are the important cue to understand the contextual information presented in the video. With the effective spatio-temporal relationship modeling, it is possible not only to uncover contextual information in each frame but also to directly capture inter-time dependencies. It is more critical to capture the position changes of human and objects over the spatio-temporal dimension when their appearance features may not show up significant changes over time. The full use of appearance features, the spatial location and the semantic information are also the key to improve the video-based Human-Object Interaction recognition performance. In this paper, Spatio-Temporal Interaction Graph Parsing Networks (STIGPN) are constructed, which encode the videos with a graph composed of human and object nodes. These nodes are connected by two types of relations: (i) spatial relations modeling the interactions between human and the interacted objects within each frame. (ii) inter-time relations capturing the long range dependencies between human and the interacted objects across frame. With the graph, STIGPN learn spatio-temporal features directly from the whole video-based Human-Object Interaction scenes. Multi-modal features and a multi-stream fusion strategy are used to enhance the reasoning capability of STIGPN. Two Human-Object Interaction video datasets, including CAD-120 and Something-Else, are used to evaluate the proposed architectures, and the state-of-the-art performance demonstrates the superiority of STIGPN.
Convolutional generative adversarial imputation networks for spatio-temporal missing data in storm surge simulations
Nov 26, 2021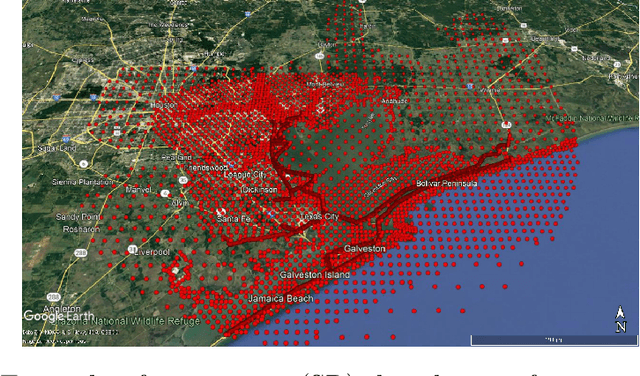
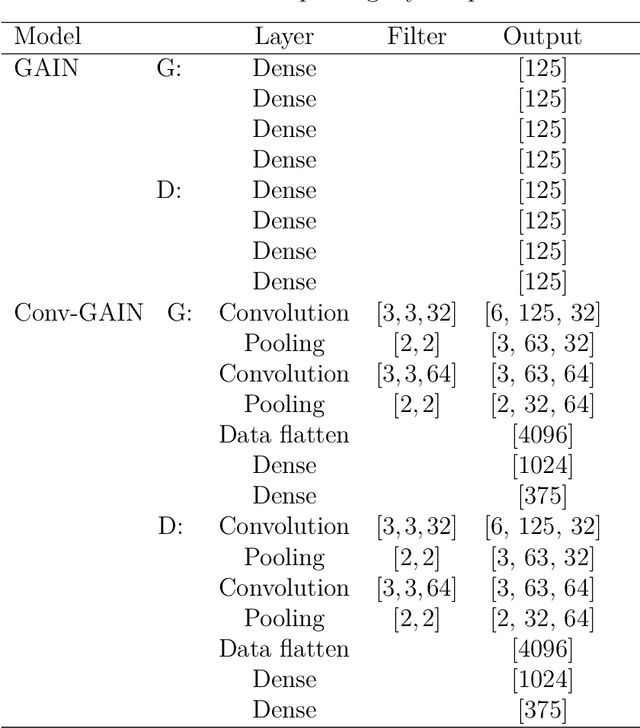
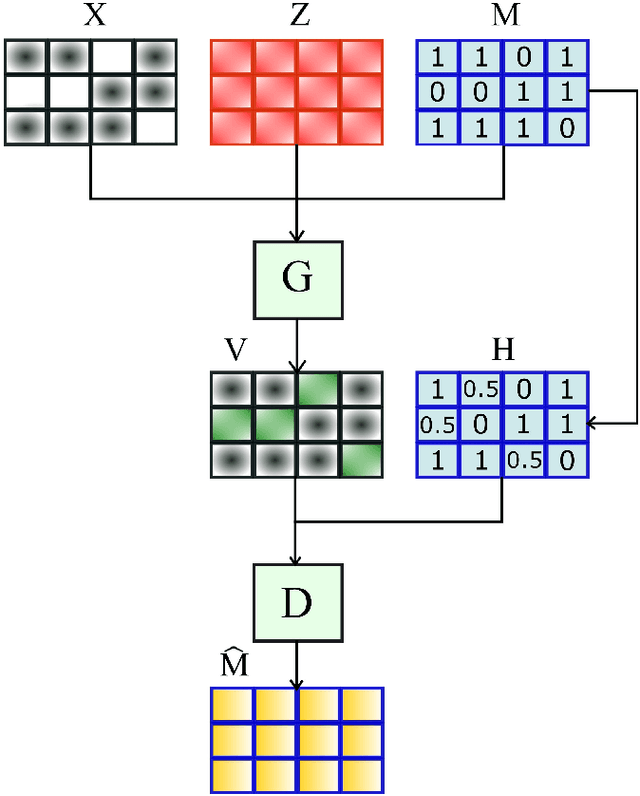

Imputation of missing data is a task that plays a vital role in a number of engineering and science applications. Often such missing data arise in experimental observations from limitations of sensors or post-processing transformation errors. Other times they arise from numerical and algorithmic constraints in computer simulations. One such instance and the application emphasis of this paper are numerical simulations of storm surge. The simulation data corresponds to time-series surge predictions over a number of save points within the geographic domain of interest, creating a spatio-temporal imputation problem where the surge points are heavily correlated spatially and temporally, and the missing values regions are structurally distributed at random. Very recently, machine learning techniques such as neural network methods have been developed and employed for missing data imputation tasks. Generative Adversarial Nets (GANs) and GAN-based techniques have particularly attracted attention as unsupervised machine learning methods. In this study, the Generative Adversarial Imputation Nets (GAIN) performance is improved by applying convolutional neural networks instead of fully connected layers to better capture the correlation of data and promote learning from the adjacent surge points. Another adjustment to the method needed specifically for the studied data is to consider the coordinates of the points as additional features to provide the model more information through the convolutional layers. We name our proposed method as Convolutional Generative Adversarial Imputation Nets (Conv-GAIN). The proposed method's performance by considering the improvements and adaptations required for the storm surge data is assessed and compared to the original GAIN and a few other techniques. The results show that Conv-GAIN has better performance than the alternative methods on the studied data.
Training Feedback Spiking Neural Networks by Implicit Differentiation on the Equilibrium State
Sep 29, 2021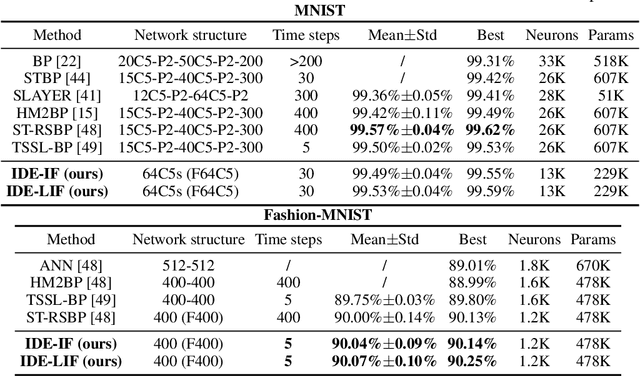
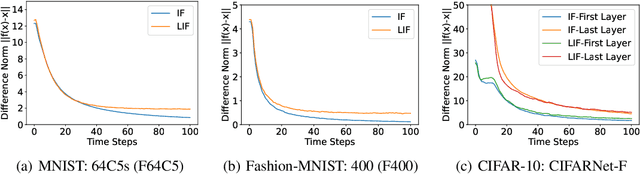
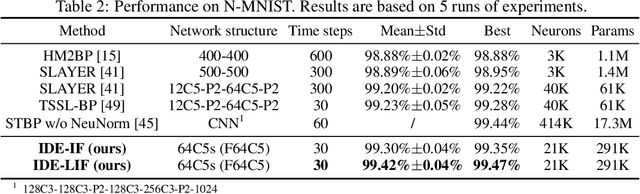
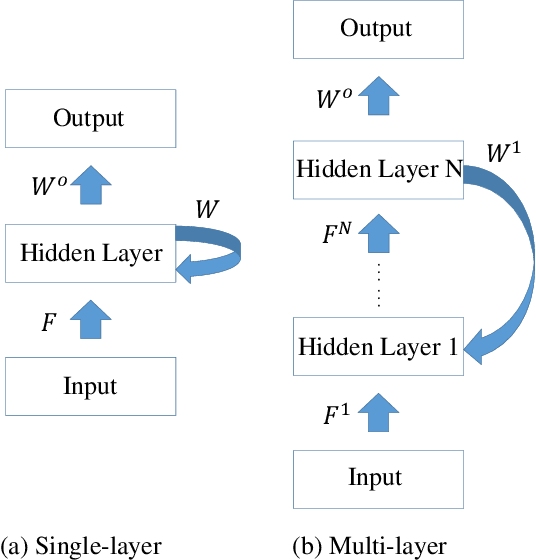
Spiking neural networks (SNNs) are brain-inspired models that enable energy-efficient implementation on neuromorphic hardware. However, the supervised training of SNNs remains a hard problem due to the discontinuity of the spiking neuron model. Most existing methods imitate the backpropagation framework and feedforward architectures for artificial neural networks, and use surrogate derivatives or compute gradients with respect to the spiking time to deal with the problem. These approaches either accumulate approximation errors or only propagate information limitedly through existing spikes, and usually require information propagation along time steps with large memory costs and biological implausibility. In this work, we consider feedback spiking neural networks, which are more brain-like, and propose a novel training method that does not rely on the exact reverse of the forward computation. First, we show that the average firing rates of SNNs with feedback connections would gradually evolve to an equilibrium state along time, which follows a fixed-point equation. Then by viewing the forward computation of feedback SNNs as a black-box solver for this equation, and leveraging the implicit differentiation on the equation, we can compute the gradient for parameters without considering the exact forward procedure. In this way, the forward and backward procedures are decoupled and therefore the problem of non-differentiable spiking functions is avoided. We also briefly discuss the biological plausibility of implicit differentiation, which only requires computing another equilibrium. Extensive experiments on MNIST, Fashion-MNIST, N-MNIST, CIFAR-10, and CIFAR-100 demonstrate the superior performance of our method for feedback models with fewer neurons and parameters in a small number of time steps. Our code is avaiable at https://github.com/pkuxmq/IDE-FSNN.
TimeTraveler: Reinforcement Learning for Temporal Knowledge Graph Forecasting
Sep 09, 2021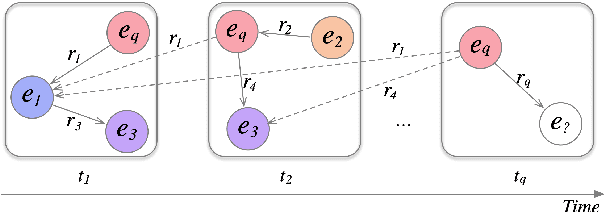
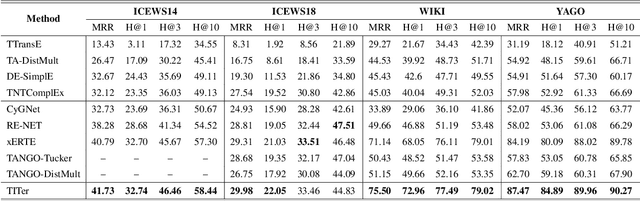


Temporal knowledge graph (TKG) reasoning is a crucial task that has gained increasing research interest in recent years. Most existing methods focus on reasoning at past timestamps to complete the missing facts, and there are only a few works of reasoning on known TKGs to forecast future facts. Compared with the completion task, the forecasting task is more difficult that faces two main challenges: (1) how to effectively model the time information to handle future timestamps? (2) how to make inductive inference to handle previously unseen entities that emerge over time? To address these challenges, we propose the first reinforcement learning method for forecasting. Specifically, the agent travels on historical knowledge graph snapshots to search for the answer. Our method defines a relative time encoding function to capture the timespan information, and we design a novel time-shaped reward based on Dirichlet distribution to guide the model learning. Furthermore, we propose a novel representation method for unseen entities to improve the inductive inference ability of the model. We evaluate our method for this link prediction task at future timestamps. Extensive experiments on four benchmark datasets demonstrate substantial performance improvement meanwhile with higher explainability, less calculation, and fewer parameters when compared with existing state-of-the-art methods.
Multimodal Breast Lesion Classification Using Cross-Attention Deep Networks
Aug 21, 2021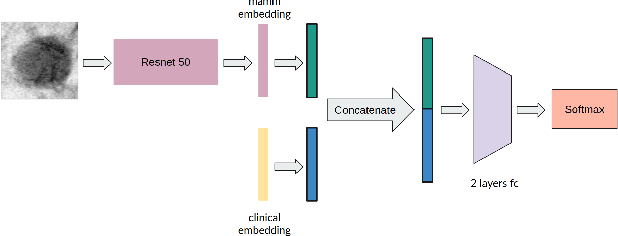
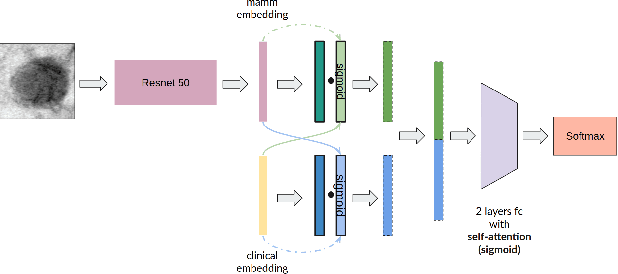
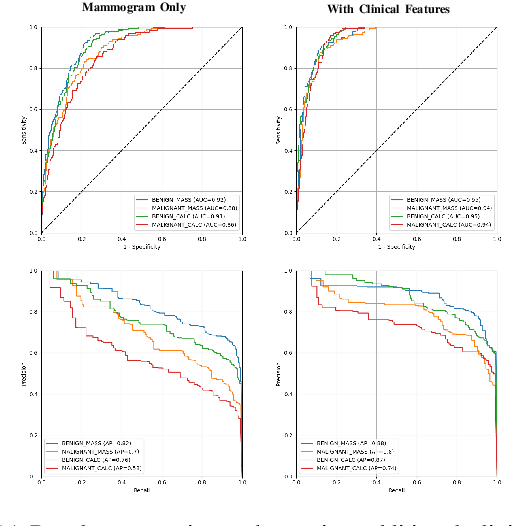

Accurate breast lesion risk estimation can significantly reduce unnecessary biopsies and help doctors decide optimal treatment plans. Most existing computer-aided systems rely solely on mammogram features to classify breast lesions. While this approach is convenient, it does not fully exploit useful information in clinical reports to achieve the optimal performance. Would clinical features significantly improve breast lesion classification compared to using mammograms alone? How to handle missing clinical information caused by variation in medical practice? What is the best way to combine mammograms and clinical features? There is a compelling need for a systematic study to address these fundamental questions. This paper investigates several multimodal deep networks based on feature concatenation, cross-attention, and co-attention to combine mammograms and categorical clinical variables. We show that the proposed architectures significantly increase the lesion classification performance (average area under ROC curves from 0.89 to 0.94). We also evaluate the model when clinical variables are missing.