 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning A 3D-CNN and Transformer Prior for Hyperspectral Image Super-Resolution
Nov 27, 2021
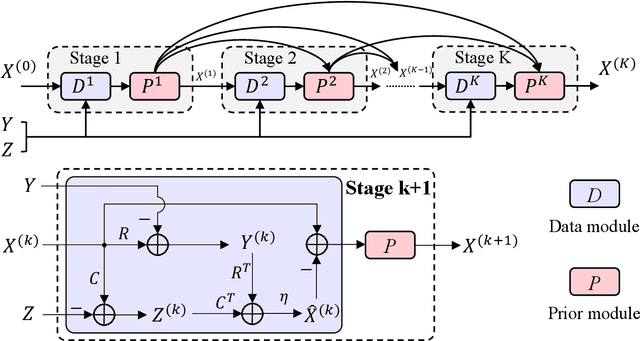
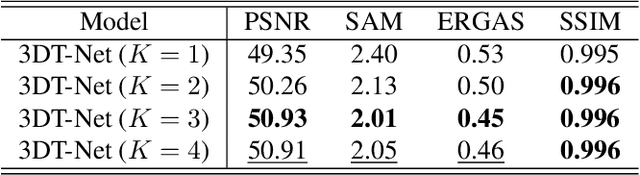
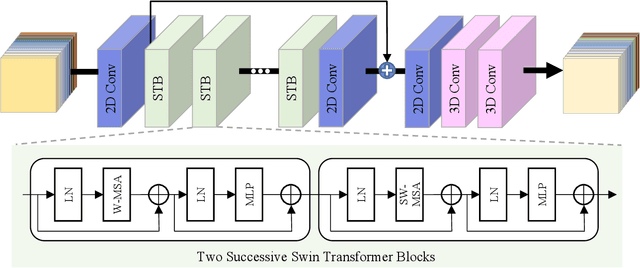
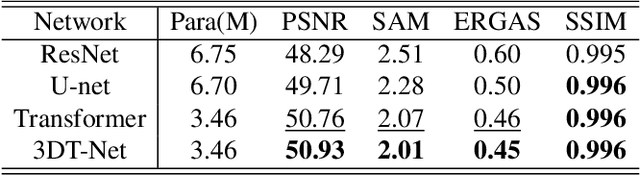
To solve the ill-posed problem of hyperspectral image super-resolution (HSISR), an usually method is to use the prior information of the hyperspectral images (HSIs) as a regularization term to constrain the objective function. Model-based methods using hand-crafted priors cannot fully characterize the properties of HSIs. Learning-based methods usually use a convolutional neural network (CNN) to learn the implicit priors of HSIs. However, the learning ability of CNN is limited, it only considers the spatial characteristics of the HSIs and ignores the spectral characteristics, and convolution is not effective for long-range dependency modeling. There is still a lot of room for improvement. In this paper, we propose a novel HSISR method that uses Transformer instead of CNN to learn the prior of HSIs. Specifically, we first use the proximal gradient algorithm to solve the HSISR model, and then use an unfolding network to simulate the iterative solution processes. The self-attention layer of Transformer makes it have the ability of spatial global interaction. In addition, we add 3D-CNN behind the Transformer layers to better explore the spatio-spectral correlation of HSIs. Both quantitative and visual results on two widely used HSI datasets and the real-world dataset demonstrate that the proposed method achieves a considerable gain compared to all the mainstream algorithms including the most competitive conventional methods and the recently proposed deep learning-based methods.
Spatial Aggregation and Temporal Convolution Networks for Real-time Kriging
Sep 24, 2021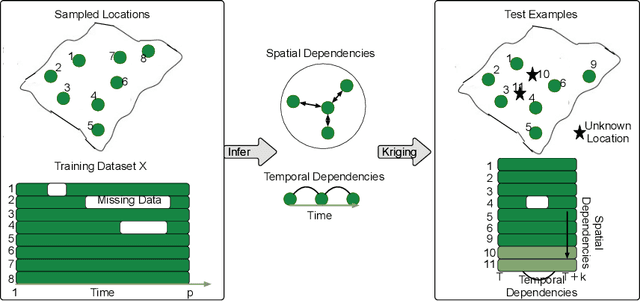

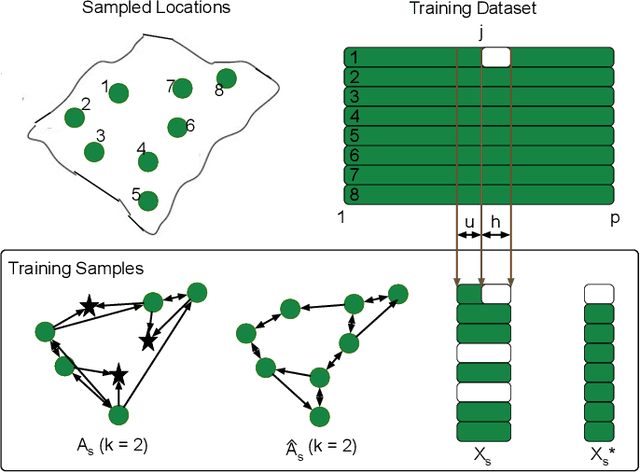
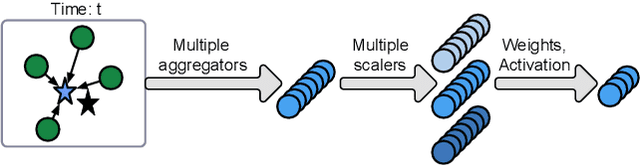
Spatiotemporal kriging is an important application in spatiotemporal data analysis, aiming to recover/interpolate signals for unsampled/unobserved locations based on observed signals. The principle challenge for spatiotemporal kriging is how to effectively model and leverage the spatiotemporal dependencies within the data. Recently, graph neural networks (GNNs) have shown great promise for spatiotemporal kriging tasks. However, standard GNNs often require a carefully designed adjacency matrix and specific aggregation functions, which are inflexible for general applications/problems. To address this issue, we present SATCN -- Spatial Aggregation and Temporal Convolution Networks -- a universal and flexible framework to perform spatiotemporal kriging for various spatiotemporal datasets without the need for model specification. Specifically, we propose a novel spatial aggregation network (SAN) inspired by Principal Neighborhood Aggregation, which uses multiple aggregation functions to help one node gather diverse information from its neighbors. To exclude information from unsampled nodes, a masking strategy that prevents the unsampled sensors from sending messages to their neighborhood is introduced to SAN. We capture temporal dependencies by the temporal convolutional networks, which allows our model to cope with data of diverse sizes. To make SATCN generalizable to unseen nodes and even unseen graph structures, we employ an inductive strategy to train SATCN. We conduct extensive experiments on three real-world spatiotemporal datasets, including traffic speed and climate recordings. Our results demonstrate the superiority of SATCN over traditional and GNN-based kriging models.
Log-based Anomaly Detection Without Log Parsing
Aug 04, 2021
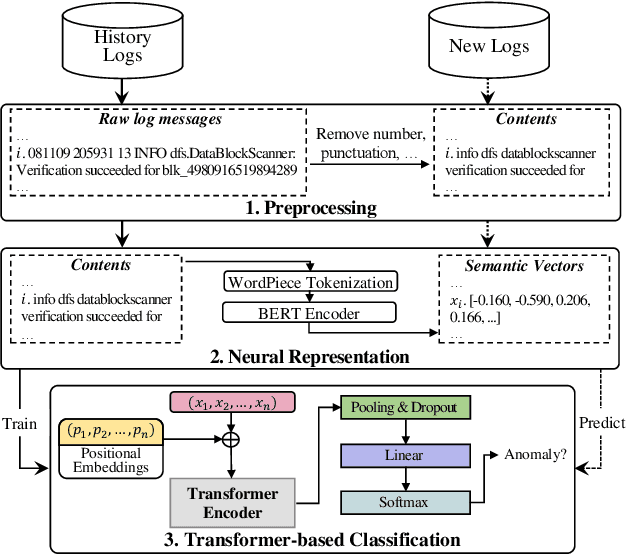
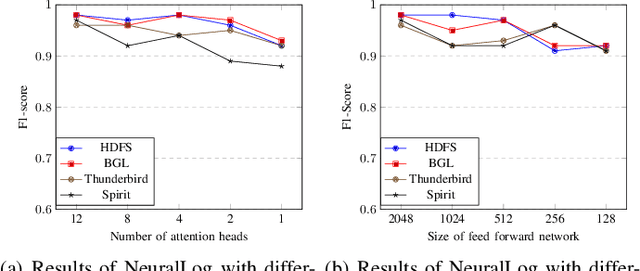
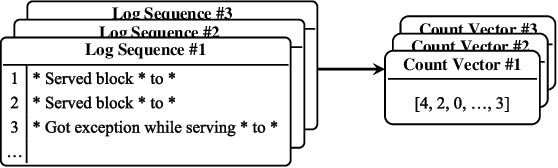
Software systems often record important runtime information in system logs for troubleshooting purposes. There have been many studies that use log data to construct machine learning models for detecting system anomalies. Through our empirical study, we find that existing log-based anomaly detection approaches are significantly affected by log parsing errors that are introduced by 1) OOV (out-of-vocabulary) words, and 2) semantic misunderstandings. The log parsing errors could cause the loss of important information for anomaly detection. To address the limitations of existing methods, we propose NeuralLog, a novel log-based anomaly detection approach that does not require log parsing. NeuralLog extracts the semantic meaning of raw log messages and represents them as semantic vectors. These representation vectors are then used to detect anomalies through a Transformer-based classification model, which can capture the contextual information from log sequences. Our experimental results show that the proposed approach can effectively understand the semantic meaning of log messages and achieve accurate anomaly detection results. Overall, NeuralLog achieves F1-scores greater than 0.95 on four public datasets, outperforming the existing approaches.
G-image Segmentation: Similarity-preserving Fuzzy C-Means with Spatial Information Constraint in Wavelet Space
Jun 20, 2020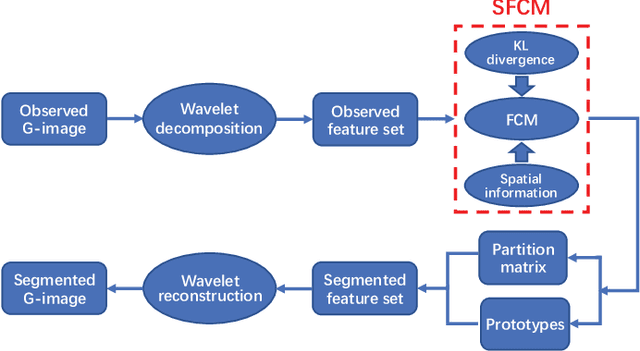
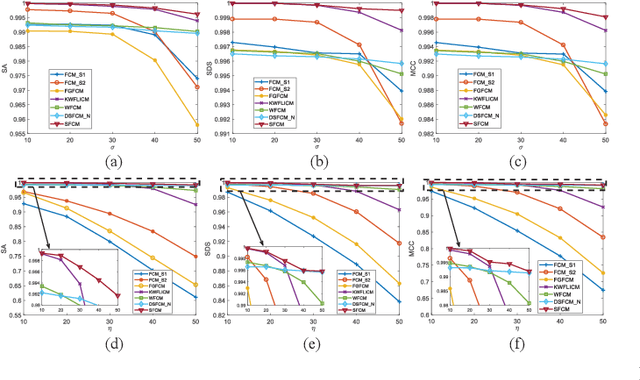
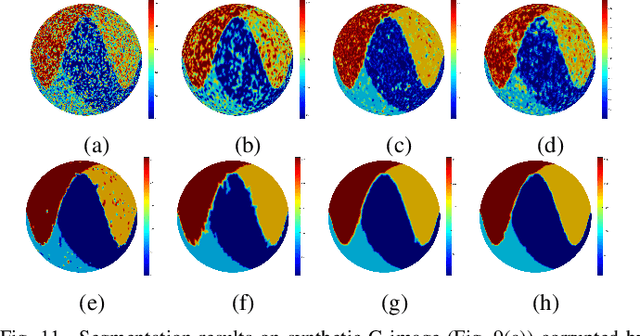
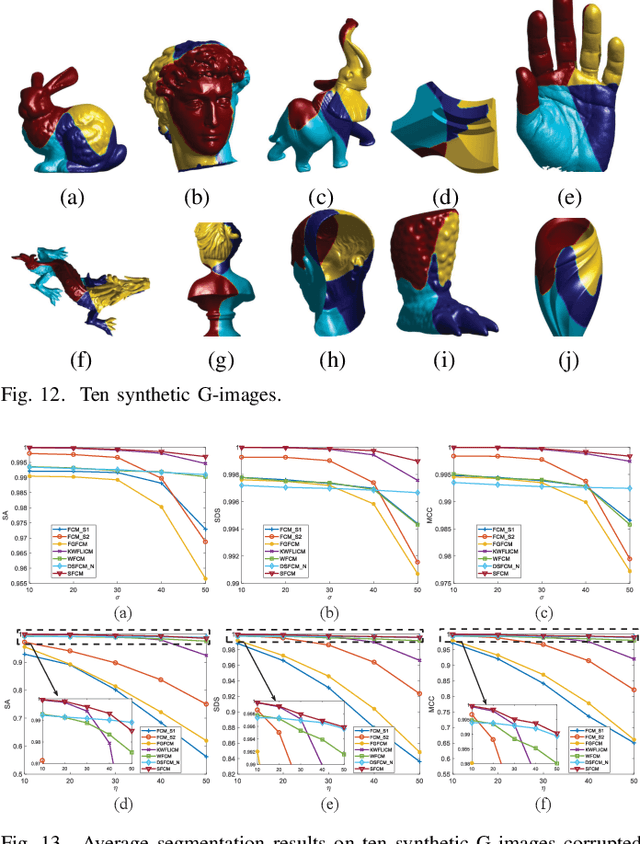
G-images refer to image data defined on irregular graph domains. This work elaborates a similarity-preserving Fuzzy C-Means (FCM) algorithm for G-image segmentation and aims to develop techniques and tools for segmenting G-images. To preserve the membership similarity between an arbitrary image pixel and its neighbors, a Kullback-Leibler divergence term on membership partition is introduced as a part of FCM. As a result, similarity-preserving FCM is developed by considering spatial information of image pixels for its robustness enhancement. Due to superior characteristics of a wavelet space, the proposed FCM is performed in this space rather than Euclidean one used in conventional FCM to secure its high robustness. Experiments on synthetic and real-world G-images demonstrate that it indeed achieves higher robustness and performance than the state-of-the-art FCM algorithms. Moreover, it requires less computation than most of them.
Simultaneous face detection and 360 degree headpose estimation
Nov 23, 2021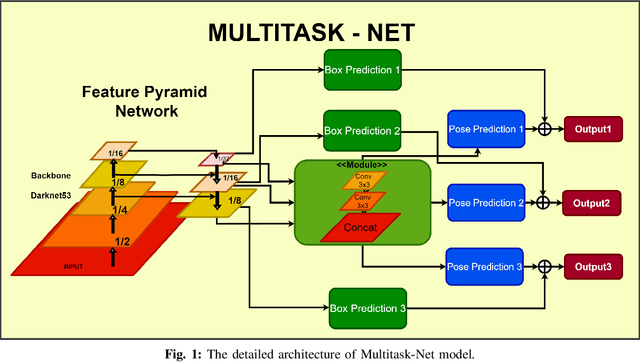
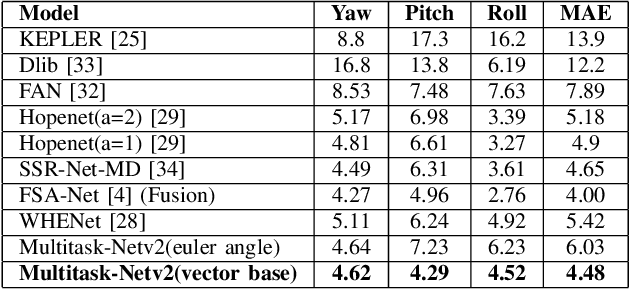
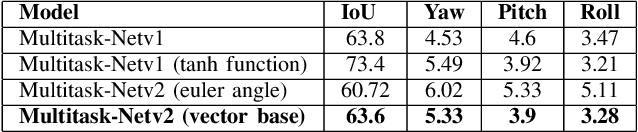
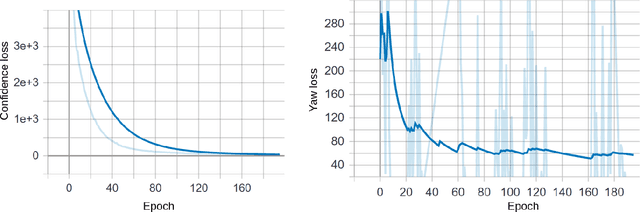
With many practical applications in human life, including manufacturing surveillance cameras, analyzing and processing customer behavior, many researchers are noticing face detection and head pose estimation on digital images. A large number of proposed deep learning models have state-of-the-art accuracy such as YOLO, SSD, MTCNN, solving the problem of face detection or HopeNet, FSA-Net, RankPose model used for head pose estimation problem. According to many state-of-the-art methods, the pipeline of this task consists of two parts, from face detection to head pose estimation. These two steps are completely independent and do not share information. This makes the model clear in setup but does not leverage most of the featured resources extracted in each model. In this paper, we proposed the Multitask-Net model with the motivation to leverage the features extracted from the face detection model, sharing them with the head pose estimation branch to improve accuracy. Also, with the variety of data, the Euler angle domain representing the face is large, our model can predict with results in the 360 Euler angle domain. Applying the multitask learning method, the Multitask-Net model can simultaneously predict the position and direction of the human head. To increase the ability to predict the head direction of the model, we change there presentation of the human face from the Euler angle to vectors of the Rotation matrix.
Semantics-aware Attention Improves Neural Machine Translation
Oct 13, 2021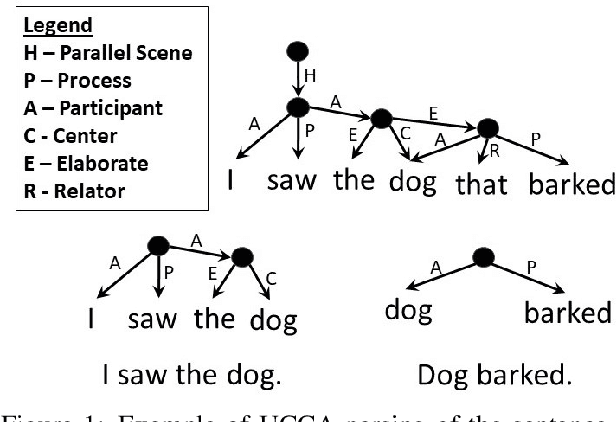
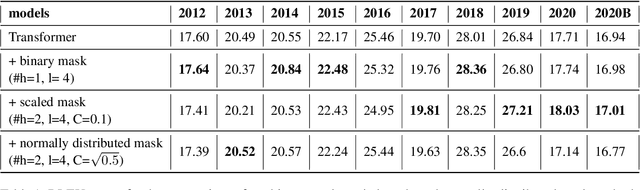
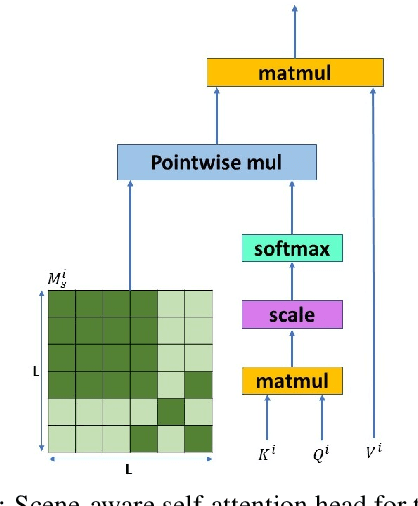

The integration of syntactic structures into Transformer machine translation has shown positive results, but to our knowledge, no work has attempted to do so with semantic structures. In this work we propose two novel parameter-free methods for injecting semantic information into Transformers, both rely on semantics-aware masking of (some of) the attention heads. One such method operates on the encoder, through a Scene-Aware Self-Attention (SASA) head. Another on the decoder, through a Scene-Aware Cross-Attention (SACrA) head. We show a consistent improvement over the vanilla Transformer and syntax-aware models for four language pairs. We further show an additional gain when using both semantic and syntactic structures in some language pairs.
Mixture-of-Variational-Experts for Continual Learning
Oct 25, 2021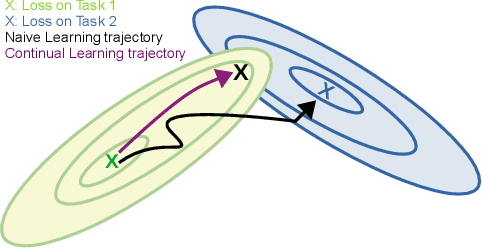
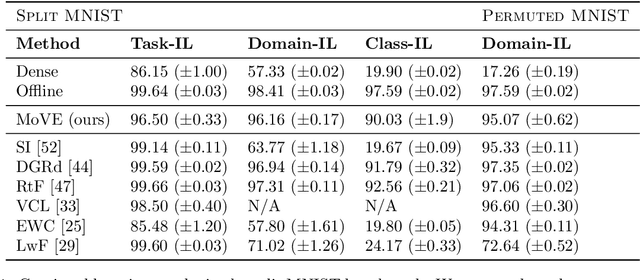
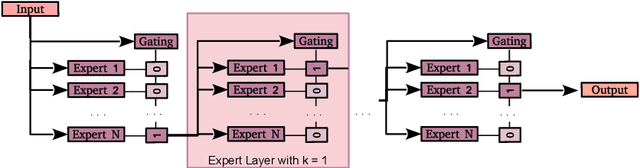
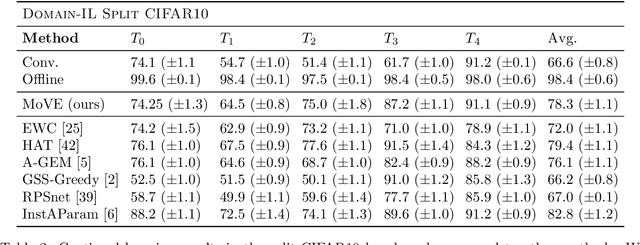
One significant shortcoming of machine learning is the poor ability of models to solve new problems quicker and without forgetting acquired knowledge. To better understand this issue, continual learning has emerged to systematically investigate learning protocols where the model sequentially observes samples generated by a series of tasks. First, we propose an optimality principle that facilitates a trade-off between learning and forgetting. We derive this principle from an information-theoretic formulation of bounded rationality and show its connections to other continual learning methods. Second, based on this principle, we propose a neural network layer for continual learning, called Mixture-of-Variational-Experts (MoVE), that alleviates forgetting while enabling the beneficial transfer of knowledge to new tasks. Our experiments on variants of the MNIST and CIFAR10 datasets demonstrate the competitive performance of MoVE layers when compared to state-of-the-art approaches.
GraSSNet: Graph Soft Sensing Neural Networks
Nov 12, 2021
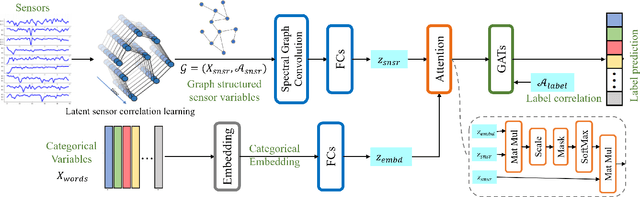
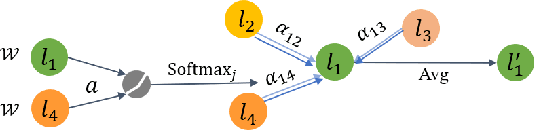
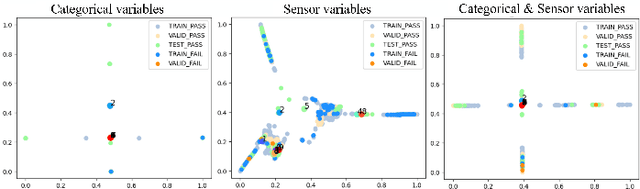
In the era of big data, data-driven based classification has become an essential method in smart manufacturing to guide production and optimize inspection. The industrial data obtained in practice is usually time-series data collected by soft sensors, which are highly nonlinear, nonstationary, imbalanced, and noisy. Most existing soft-sensing machine learning models focus on capturing either intra-series temporal dependencies or pre-defined inter-series correlations, while ignoring the correlation between labels as each instance is associated with multiple labels simultaneously. In this paper, we propose a novel graph based soft-sensing neural network (GraSSNet) for multivariate time-series classification of noisy and highly-imbalanced soft-sensing data. The proposed GraSSNet is able to 1) capture the inter-series and intra-series dependencies jointly in the spectral domain; 2) exploit the label correlations by superimposing label graph that built from statistical co-occurrence information; 3) learn features with attention mechanism from both textual and numerical domain; and 4) leverage unlabeled data and mitigate data imbalance by semi-supervised learning. Comparative studies with other commonly used classifiers are carried out on Seagate soft sensing data, and the experimental results validate the competitive performance of our proposed method.
Learning to Control using Image Feedback
Oct 28, 2021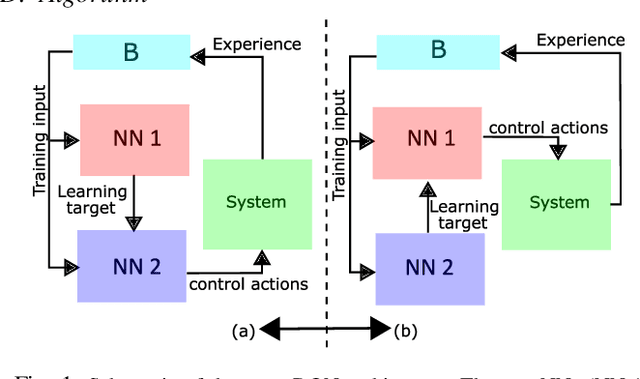
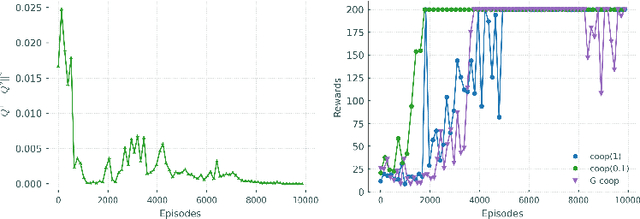
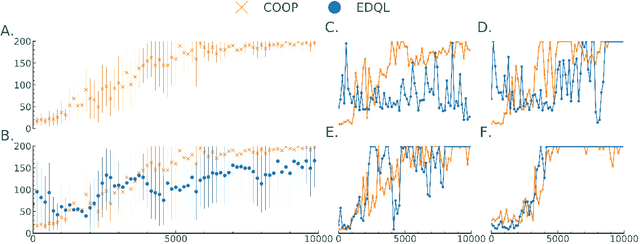
Learning to control complex systems using non-traditional feedback, e.g., in the form of snapshot images, is an important task encountered in diverse domains such as robotics, neuroscience, and biology (cellular systems). In this paper, we present a two neural-network (NN)-based feedback control framework to design control policies for systems that generate feedback in the form of images. In particular, we develop a deep $Q$-network (DQN)-driven learning control strategy to synthesize a sequence of control inputs from snapshot images that encode the information pertaining to the current state and control action of the system. Further, to train the networks we employ a direct error-driven learning (EDL) approach that utilizes a set of linear transformations of the NN training error to update the NN weights in each layer. We verify the efficacy of the proposed control strategy using numerical examples.
High-order joint embedding for multi-level link prediction
Nov 07, 2021
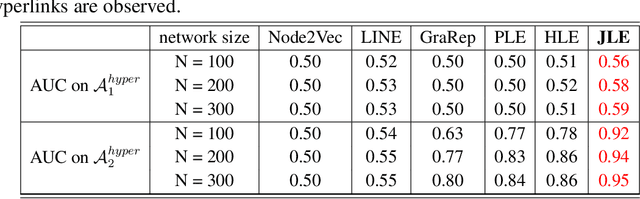
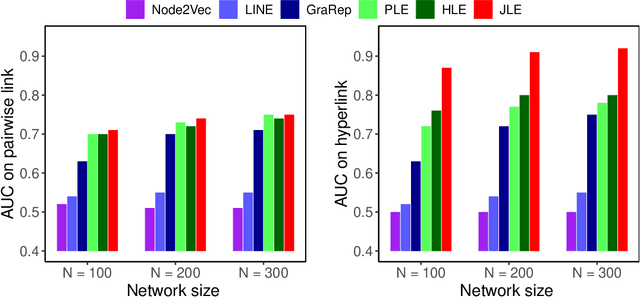
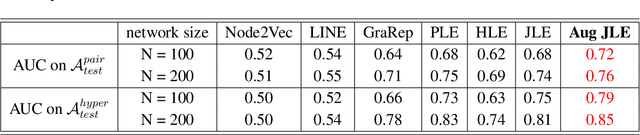
Link prediction infers potential links from observed networks, and is one of the essential problems in network analyses. In contrast to traditional graph representation modeling which only predicts two-way pairwise relations, we propose a novel tensor-based joint network embedding approach on simultaneously encoding pairwise links and hyperlinks onto a latent space, which captures the dependency between pairwise and multi-way links in inferring potential unobserved hyperlinks. The major advantage of the proposed embedding procedure is that it incorporates both the pairwise relationships and subgroup-wise structure among nodes to capture richer network information. In addition, the proposed method introduces a hierarchical dependency among links to infer potential hyperlinks, and leads to better link prediction. In theory we establish the estimation consistency for the proposed embedding approach, and provide a faster convergence rate compared to link prediction utilizing pairwise links or hyperlinks only. Numerical studies on both simulation settings and Facebook ego-networks indicate that the proposed method improves both hyperlink and pairwise link prediction accuracy compared to existing link prediction algorithms.