 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task-Sensitive Concept Drift Detector with Constraint Embedding
Aug 24, 2021
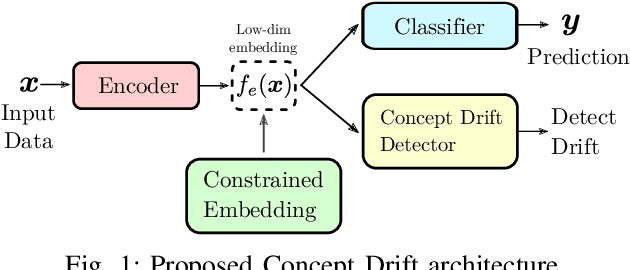
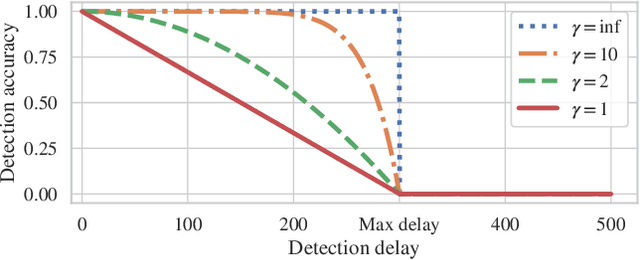
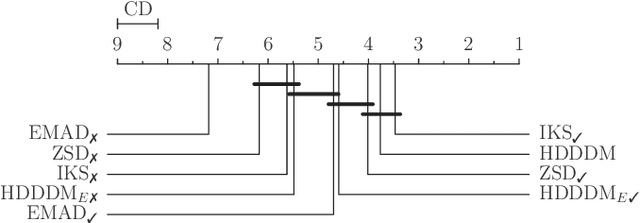
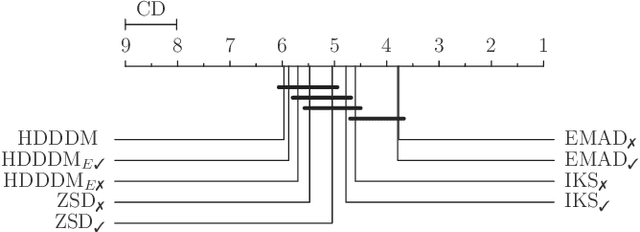
Detecting drifts in data is essential for machine learning applications, as changes in the statistics of processed data typically has a profound influence on the performance of trained models. Most of the available drift detection methods are either supervised and require access to the true labels during inference time, or they are completely unsupervised and aim for changes in distributions without taking label information into account. We propose a novel task-sensitive semi-supervised drift detection scheme, which utilizes label information while training the initial model, but takes into account that supervised label information is no longer available when using the model during inference. It utilizes a constrained low-dimensional embedding representation of the input data. This way, it is best suited for the classification task. It is able to detect real drift, where the drift affects the classification performance, while it properly ignores virtual drift, where the classification performance is not affected by the drift. In the proposed framework, the actual method to detect a change in the statistics of incoming data samples can be chosen freely. Experimental evaluation on nine benchmarks datasets, with different types of drift, demonstrates that the proposed framework can reliably detect drifts, and outperforms state-of-the-art unsupervised drift detection approaches.
Feature-Level Fusion of Super-App and Telecommunication Alternative Data Sources for Credit Card Fraud Detection
Nov 05, 2021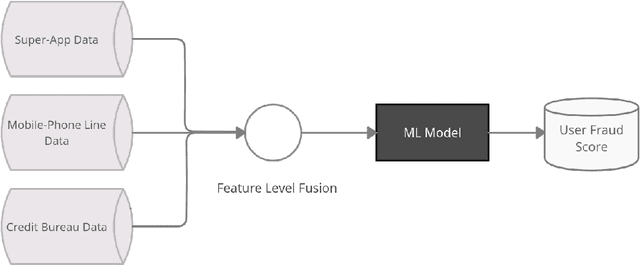
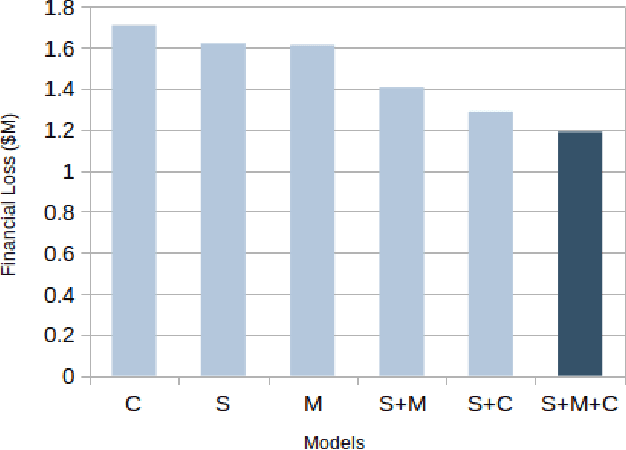
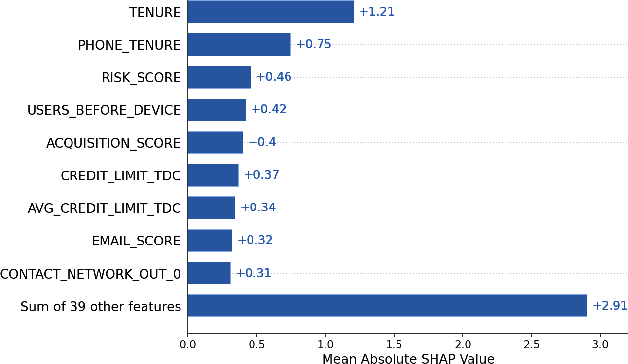

Identity theft is a major problem for credit lenders when there's not enough data to corroborate a customer's identity. Among super-apps large digital platforms that encompass many different services this problem is even more relevant; losing a client in one branch can often mean losing them in other services. In this paper, we review the effectiveness of a feature-level fusion of super-app customer information, mobile phone line data, and traditional credit risk variables for the early detection of identity theft credit card fraud. Through the proposed framework, we achieved better performance when using a model whose input is a fusion of alternative data and traditional credit bureau data, achieving a ROC AUC score of 0.81. We evaluate our approach over approximately 90,000 users from a credit lender's digital platform database. The evaluation was performed using not only traditional ML metrics but the financial costs as well.
Simple End-to-end Deep Learning Model for CDR-H3 Loop Structure Prediction
Nov 20, 2021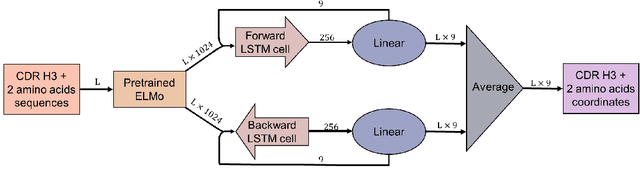
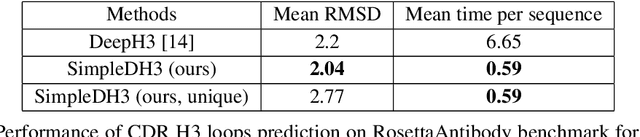
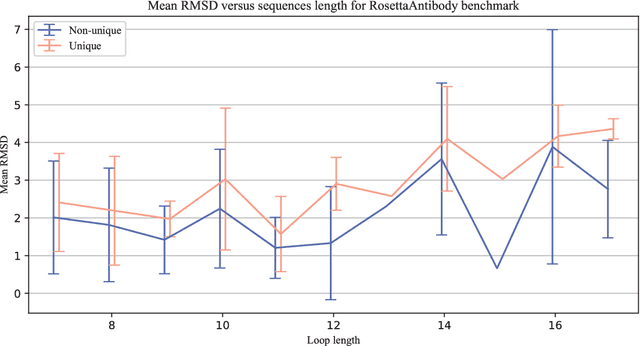
Predicting a structure of an antibody from its sequence is important since it allows for a better design process of synthetic antibodies that play a vital role in the health industry. Most of the structure of an antibody is conservative. The most variable and hard-to-predict part is the {\it third complementarity-determining region of the antibody heavy chain} (CDR H3). Lately, deep learning has been employed to solve the task of CDR H3 prediction. However, current state-of-the-art methods are not end-to-end, but rather they output inter-residue distances and orientations to the RosettaAntibody package that uses this additional information alongside statistical and physics-based methods to predict the 3D structure. This does not allow a fast screening process and, therefore, inhibits the development of targeted synthetic antibodies. In this work, we present an end-to-end model to predict CDR H3 loop structure, that performs on par with state-of-the-art methods in terms of accuracy but an order of magnitude faster. We also raise an issue with a commonly used RosettaAntibody benchmark that leads to data leaks, i.e., the presence of identical sequences in the train and test datasets.
It's Easier to Translate out of English than into it: Measuring Neural Translation Difficulty by Cross-Mutual Information
May 05, 2020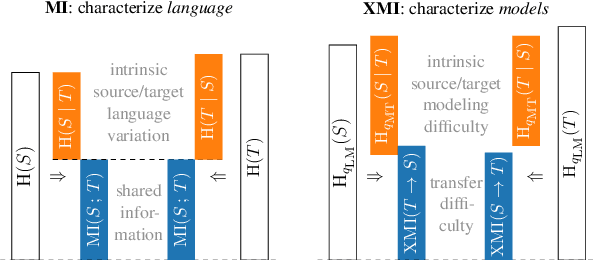
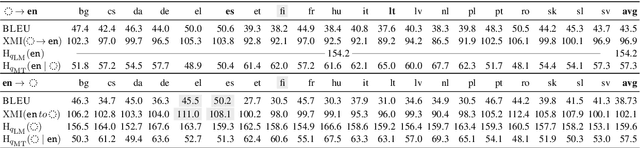
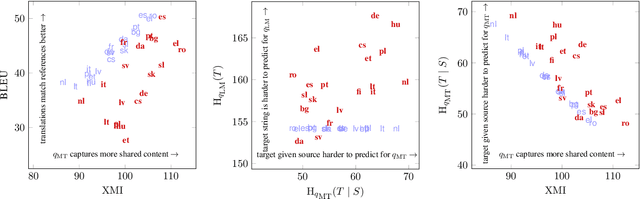
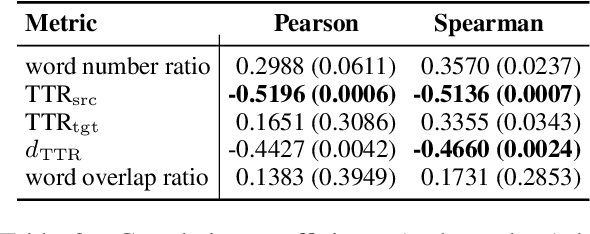
The performance of neural machine translation systems is commonly evaluated in terms of BLEU. However, due to its reliance on target language properties and generation, the BLEU metric does not allow an assessment of which translation directions are more difficult to model. In this paper, we propose cross-mutual information (XMI): an asymmetric information-theoretic metric of machine translation difficulty that exploits the probabilistic nature of most neural machine translation models. XMI allows us to better evaluate the difficulty of translating text into the target language while controlling for the difficulty of the target-side generation component independent of the translation task. We then present the first systematic and controlled study of cross-lingual translation difficulties using modern neural translation systems. Code for replicating our experiments is available online at https://github.com/e-bug/nmt-difficulty.
Combining Machine Learning with Physics: A Framework for Tracking and Sorting Multiple Dark Solitons
Nov 08, 2021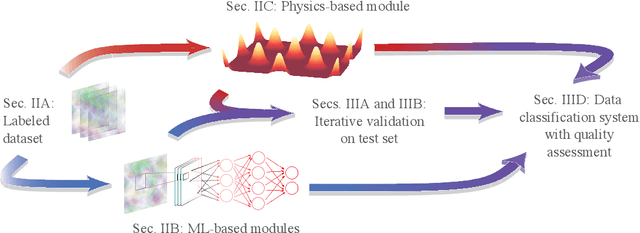
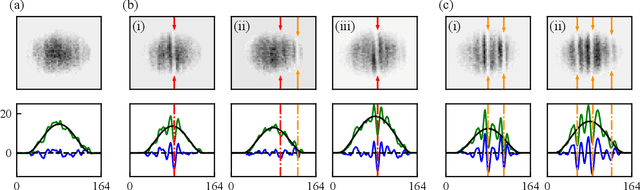
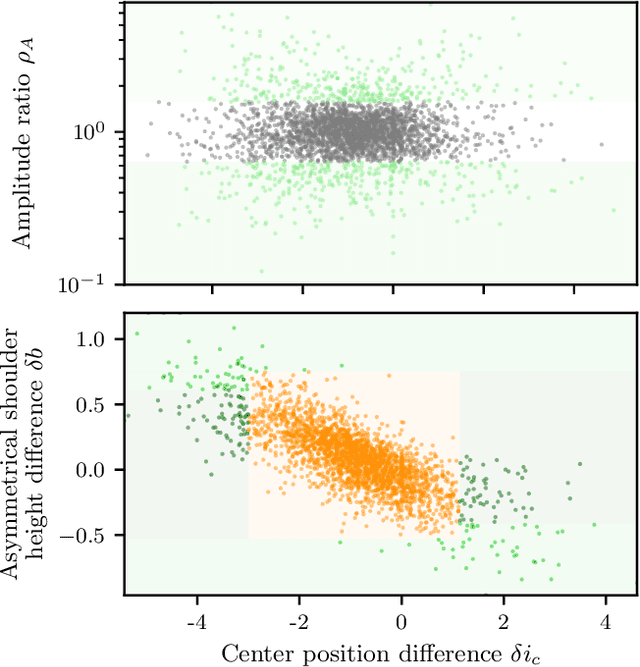
In ultracold atom experiments, data often comes in the form of images which suffer information loss inherent in the techniques used to prepare and measure the system. This is particularly problematic when the processes of interest are complicated, such as interactions among excitations in Bose-Einstein condensates (BECs). In this paper, we describe a framework combining machine learning (ML) models with physics-based traditional analyses to identify and track multiple solitonic excitations in images of BECs. We use an ML-based object detector to locate the solitonic excitations and develop a physics-informed classifier to sort solitonic excitations into physically motivated sub-categories. Lastly, we introduce a quality metric quantifying the likelihood that a specific feature is a kink soliton. Our trained implementation of this framework -- SolDet -- is publicly available as an open-source python package. SolDet is broadly applicable to feature identification in cold atom images when trained on a suitable user-provided dataset.
Windowed Decoding for Delayed Bit-Interleaved Coded Modulation
Aug 15, 2021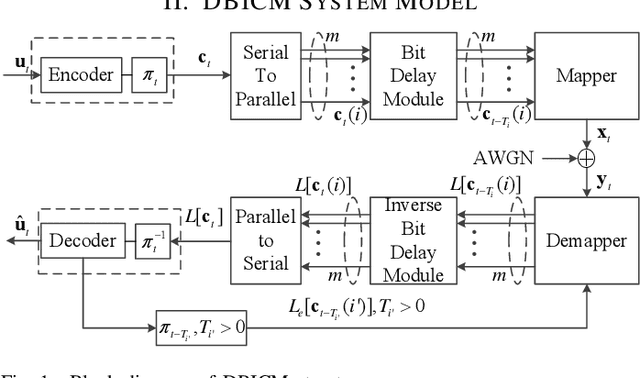
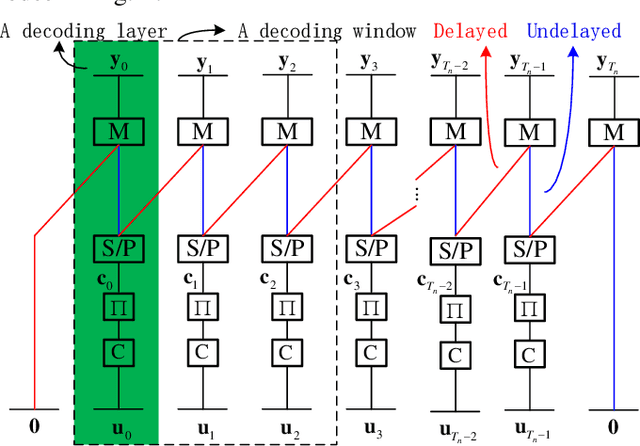

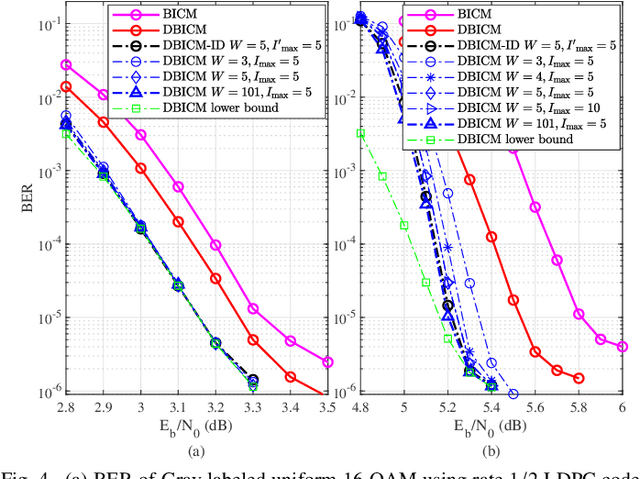
Delayed bit-interleaved coded modulation (DBICM) generalizes bit-interleaved coded modulation (BICM) by modulating differently delayed sub-blocks of codewords onto the same signals. DBICM improves transmission reliability over BICM due to its capability of detecting undelayed sub-blocks with the extrinsic information of the decoded delayed sub-blocks. In this work, we propose a novel windowed decoding algorithm for DBICM, which uses the extrinsic information of both the decoded delayed and undelayed sub-blocks, to improve the detection on all sub-blocks. Numerical results show that the proposed windowed decoding significantly outperforms the original decoding.
Intelligence, physics and information -- the tradeoff between accuracy and simplicity in machine learning
Jan 20, 2020How can we enable machines to make sense of the world, and become better at learning? To approach this goal, I believe viewing intelligence in terms of many integral aspects, and also a universal two-term tradeoff between task performance and complexity, provides two feasible perspectives. In this thesis, I address several key questions in some aspects of intelligence, and study the phase transitions in the two-term tradeoff, using strategies and tools from physics and information. Firstly, how can we make the learning models more flexible and efficient, so that agents can learn quickly with fewer examples? Inspired by how physicists model the world, we introduce a paradigm and an AI Physicist agent for simultaneously learning many small specialized models (theories) and the domain they are accurate, which can then be simplified, unified and stored, facilitating few-shot learning in a continual way. Secondly, for representation learning, when can we learn a good representation, and how does learning depend on the structure of the dataset? We approach this question by studying phase transitions when tuning the tradeoff hyperparameter. In the information bottleneck, we theoretically show that these phase transitions are predictable and reveal structure in the relationships between the data, the model, the learned representation and the loss landscape. Thirdly, how can agents discover causality from observations? We address part of this question by introducing an algorithm that combines prediction and minimizing information from the input, for exploratory causal discovery from observational time series. Fourthly, to make models more robust to label noise, we introduce Rank Pruning, a robust algorithm for classification with noisy labels. I believe that building on the work of my thesis we will be one step closer to enable more intelligent machines that can make sense of the world.
GMSRF-Net: An improved generalizability with global multi-scale residual fusion network for polyp segmentation
Nov 20, 2021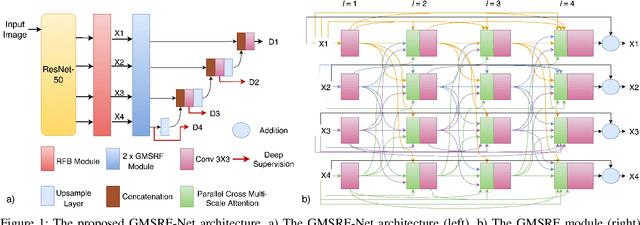
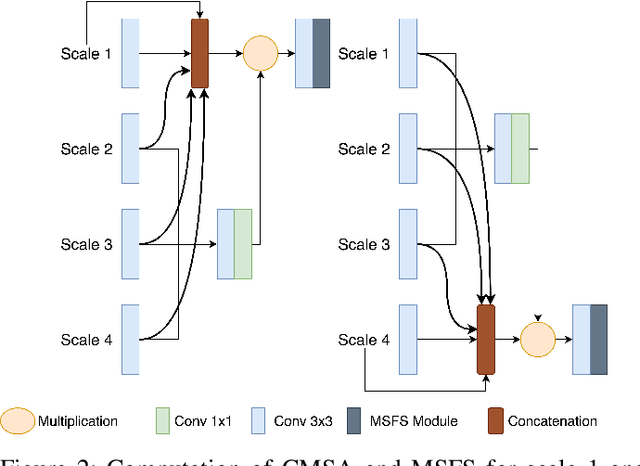
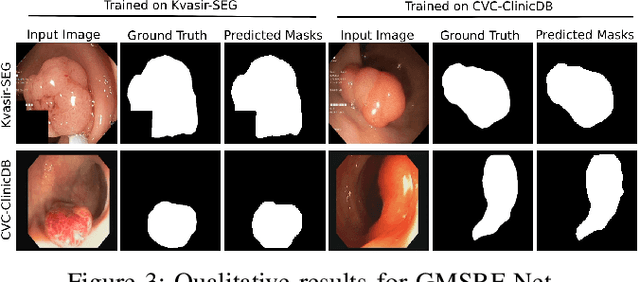
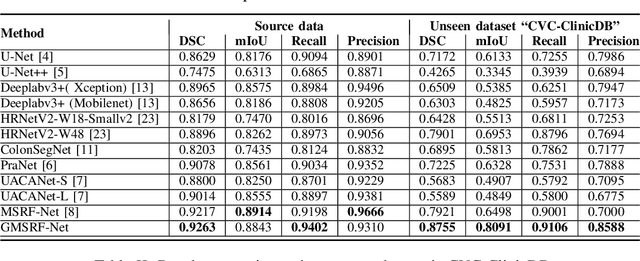
Colonoscopy is a gold standard procedure but is highly operator-dependent. Efforts have been made to automate the detection and segmentation of polyps, a precancerous precursor, to effectively minimize missed rate. Widely used computer-aided polyp segmentation systems actuated by encoder-decoder have achieved high performance in terms of accuracy. However, polyp segmentation datasets collected from varied centers can follow different imaging protocols leading to difference in data distribution. As a result, most methods suffer from performance drop and require re-training for each specific dataset. We address this generalizability issue by proposing a global multi-scale residual fusion network (GMSRF-Net). Our proposed network maintains high-resolution representations while performing multi-scale fusion operations for all resolution scales. To further leverage scale information, we design cross multi-scale attention (CMSA) and multi-scale feature selection (MSFS) modules within the GMSRF-Net. The repeated fusion operations gated by CMSA and MSFS demonstrate improved generalizability of the network. Experiments conducted on two different polyp segmentation datasets show that our proposed GMSRF-Net outperforms the previous top-performing state-of-the-art method by 8.34% and 10.31% on unseen CVC-ClinicDB and unseen Kvasir-SEG, in terms of dice coefficient.
Forecasting sales with Bayesian networks: a case study of a supermarket product in the presence of promotions
Dec 16, 2021

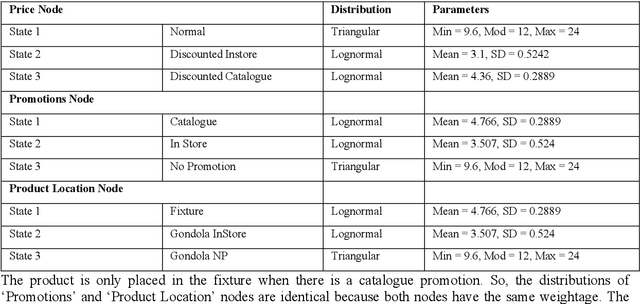
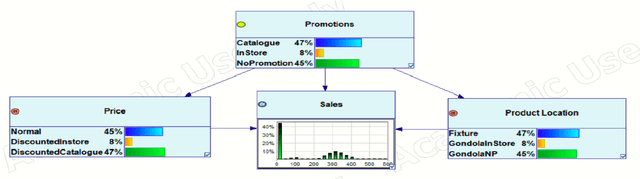
Sales forecasting is the prerequisite for a lot of managerial decisions such as production planning, material resource planning and budgeting in the supply chain. Promotions are one of the most important business strategies that are often used to boost sales. While promotions are attractive for generating demand, it is often difficult to forecast demand in their presence. In the past few decades, several quantitative models have been developed to forecast sales including statistical and machine learning models. However, these methods may not be adequate to account for all the internal and external factors that may impact sales. As a result, qualitative models have been adopted along with quantitative methods as consulting experts has been proven to improve forecast accuracy by providing contextual information. Such models are being used extensively to account for factors that can lead to a rapid change in sales, such as during promotions. In this paper, we aim to use Bayesian Networks to forecast promotional sales where a combination of factors such as price, type of promotions, and product location impacts sales. We choose to develop a BN model because BN models essentially have the capability to combine various qualitative and quantitative factors with causal forms, making it an attractive tool for sales forecasting during promotions. This can be used to adjust a company's promotional strategy in the context of this case study. We gather sales data for a particular product from a retailer that sells products in Australia. We develop a Bayesian Network for this product and validate our results by empirical analysis. This paper confirms that BNs can be effectively used to forecast sales, especially during promotions. In the end, we provide some research avenues for using BNs in forecasting sales.
Gamifying optimization: a Wasserstein distance-based analysis of human search
Dec 12, 2021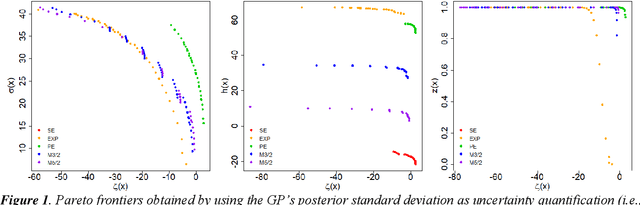
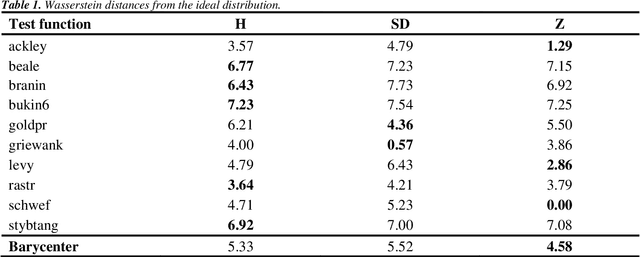
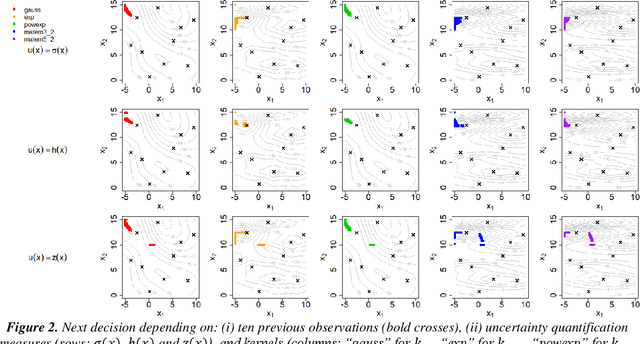
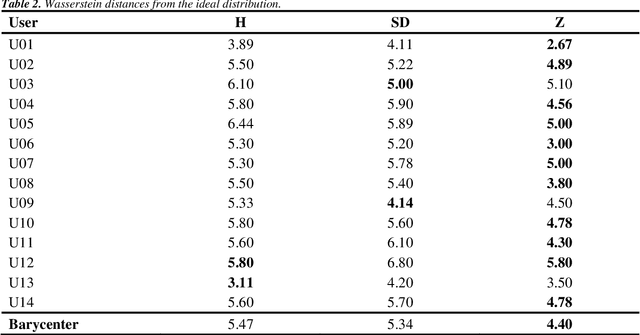
The main objective of this paper is to outline a theoretical framework to characterise humans' decision-making strategies under uncertainty, in particular active learning in a black-box optimization task and trading-off between information gathering (exploration) and reward seeking (exploitation). Humans' decisions making according to these two objectives can be modelled in terms of Pareto rationality. If a decision set contains a Pareto efficient strategy, a rational decision maker should always select the dominant strategy over its dominated alternatives. A distance from the Pareto frontier determines whether a choice is Pareto rational. To collect data about humans' strategies we have used a gaming application that shows the game field, with previous decisions and observations, as well as the score obtained. The key element in this paper is the representation of behavioural patterns of human learners as a discrete probability distribution. This maps the problem of the characterization of humans' behaviour into a space whose elements are probability distributions structured by a distance between histograms, namely the Wasserstein distance (WST). The distributional analysis gives new insights about human search strategies and their deviations from Pareto rationality. Since the uncertainty is one of the two objectives defining the Pareto frontier, the analysis has been performed for three different uncertainty quantification measures to identify which better explains the Pareto compliant behavioural patterns. Beside the analysis of individual patterns WST has also enabled a global analysis computing the barycenters and WST k-means clustering. A further analysis has been performed by a decision tree to relate non-Paretian behaviour, characterized by exasperated exploitation, to the dynamics of the evolution of the reward seeking process.