 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reasoning Graph Networks for Kinship Verification: from Star-shaped to Hierarchical
Sep 06, 2021
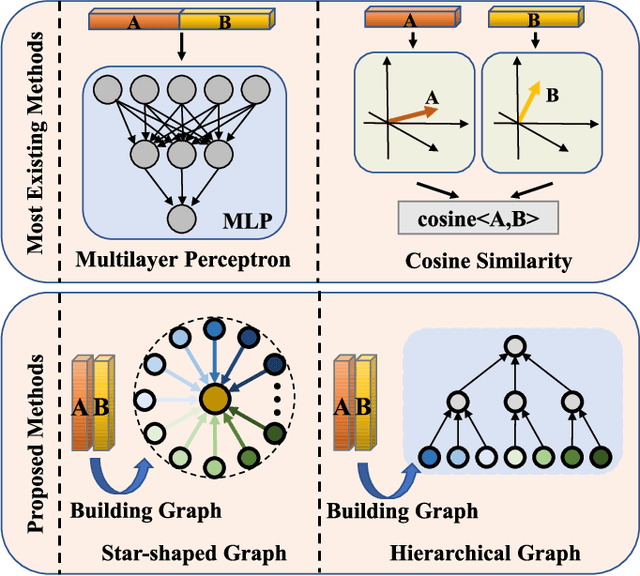
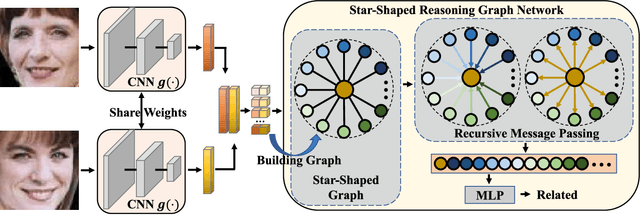

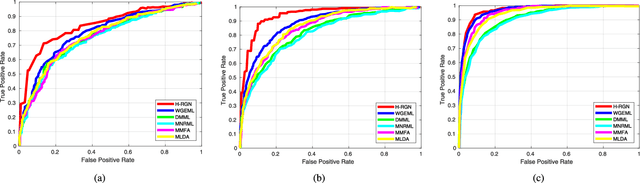
In this paper, we investigate the problem of facial kinship verification by learning hierarchical reasoning graph networks. Conventional methods usually focus on learning discriminative features for each facial image of a paired sample and neglect how to fuse the obtained two facial image features and reason about the relations between them. To address this, we propose a Star-shaped Reasoning Graph Network (S-RGN). Our S-RGN first constructs a star-shaped graph where each surrounding node encodes the information of comparisons in a feature dimension and the central node is employed as the bridge for the interaction of surrounding nodes. Then we perform relational reasoning on this star graph with iterative message passing. The proposed S-RGN uses only one central node to analyze and process information from all surrounding nodes, which limits its reasoning capacity. We further develop a Hierarchical Reasoning Graph Network (H-RGN) to exploit more powerful and flexible capacity. More specifically, our H-RGN introduces a set of latent reasoning nodes and constructs a hierarchical graph with them. Then bottom-up comparative information abstraction and top-down comprehensive signal propagation are iteratively performed on the hierarchical graph to update the node features. Extensive experimental results on four widely used kinship databases show that the proposed methods achieve very competitive results.
* Accepted by IEEE Transactions on Image Processing (TIP)
A Volumetric Transformer for Accurate 3D Tumor Segmentation
Nov 26, 2021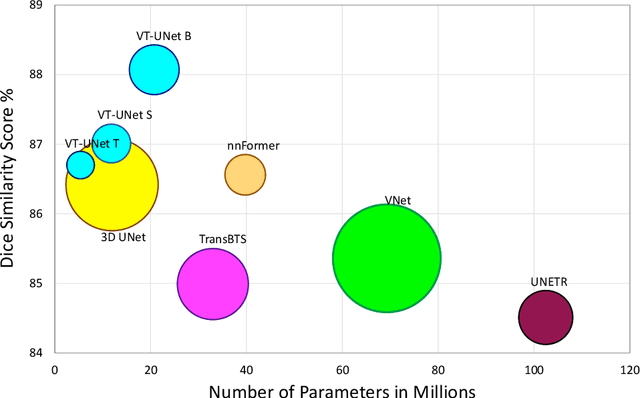
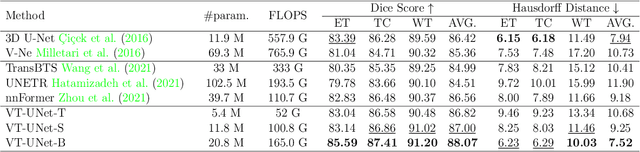
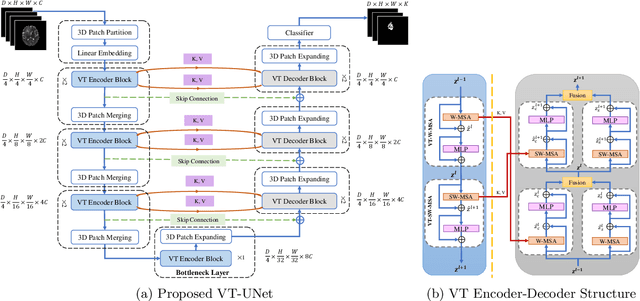
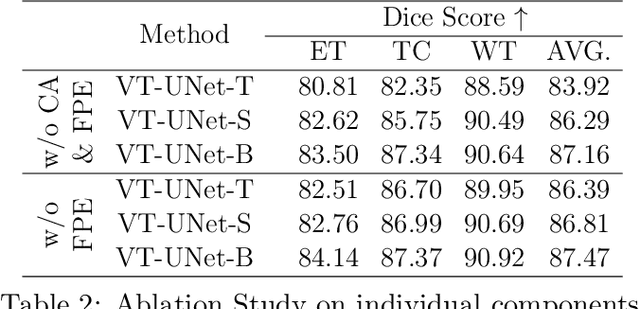
This paper presents a Transformer architecture for volumetric medical image segmentation. Designing a computationally efficient Transformer architecture for volumetric segmentation is a challenging task. It requires keeping a complex balance in encoding local and global spatial cues, and preserving information along all axes of the volumetric data. The proposed volumetric Transformer has a U-shaped encoder-decoder design that processes the input voxels in their entirety. Our encoder has two consecutive self-attention layers to simultaneously encode local and global cues, and our decoder has novel parallel shifted window based self and cross attention blocks to capture fine details for boundary refinement by subsuming Fourier position encoding. Our proposed design choices result in a computationally efficient architecture, which demonstrates promising results on Brain Tumor Segmentation (BraTS) 2021, and Medical Segmentation Decathlon (Pancreas and Liver) datasets for tumor segmentation. We further show that the representations learned by our model transfer better across-datasets and are robust against data corruptions. \href{https://github.com/himashi92/VT-UNet}{Our code implementation is publicly available}.
Pretrained Cost Model for Distributed Constraint Optimization Problems
Dec 15, 2021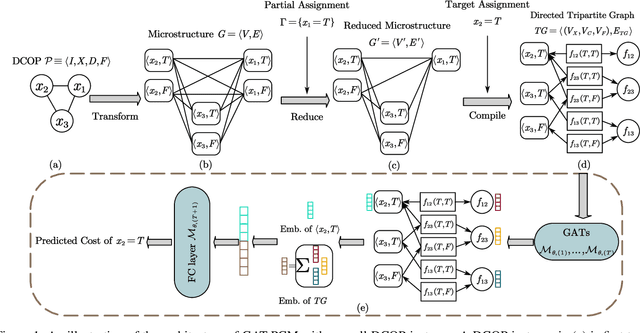
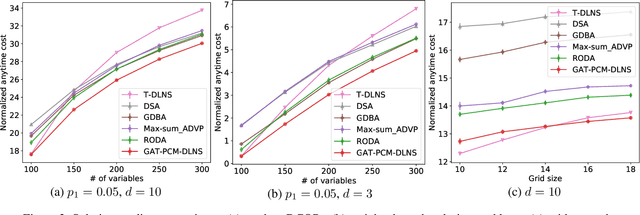
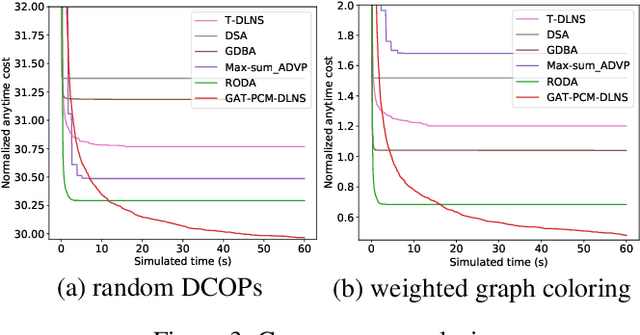
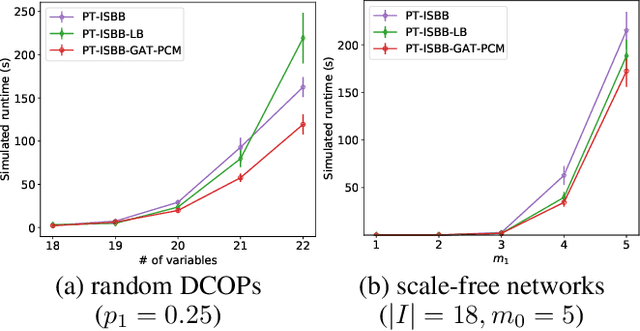
Distributed Constraint Optimization Problems (DCOPs) are an important subclass of combinatorial optimization problems, where information and controls are distributed among multiple autonomous agents. Previously, Machine Learning (ML) has been largely applied to solve combinatorial optimization problems by learning effective heuristics. However, existing ML-based heuristic methods are often not generalizable to different search algorithms. Most importantly, these methods usually require full knowledge about the problems to be solved, which are not suitable for distributed settings where centralization is not realistic due to geographical limitations or privacy concerns. To address the generality issue, we propose a novel directed acyclic graph representation schema for DCOPs and leverage the Graph Attention Networks (GATs) to embed graph representations. Our model, GAT-PCM, is then pretrained with optimally labelled data in an offline manner, so as to construct effective heuristics to boost a broad range of DCOP algorithms where evaluating the quality of a partial assignment is critical, such as local search or backtracking search. Furthermore, to enable decentralized model inference, we propose a distributed embedding schema of GAT-PCM where each agent exchanges only embedded vectors, and show its soundness and complexity. Finally, we demonstrate the effectiveness of our model by combining it with a local search or a backtracking search algorithm. Extensive empirical evaluations indicate that the GAT-PCM-boosted algorithms significantly outperform the state-of-the-art methods in various benchmarks. The pretrained model is available at https://github.com/dyc941126/GAT-PCM.
Fast Uncertainty Quantification for Active Graph SLAM
Oct 04, 2021
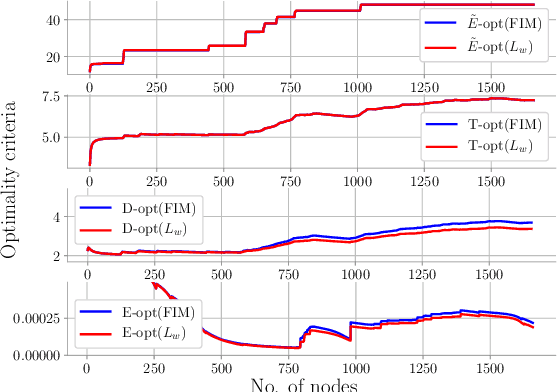
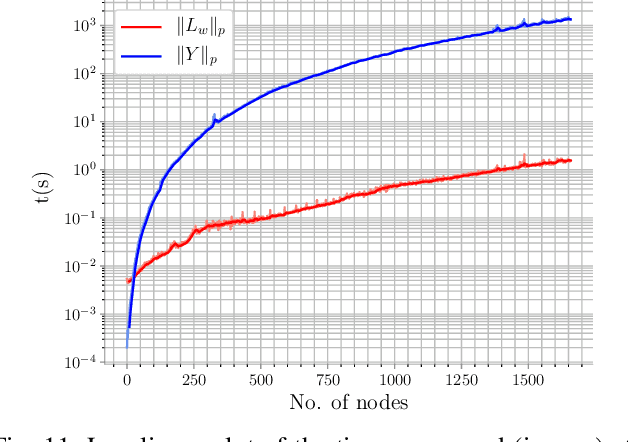
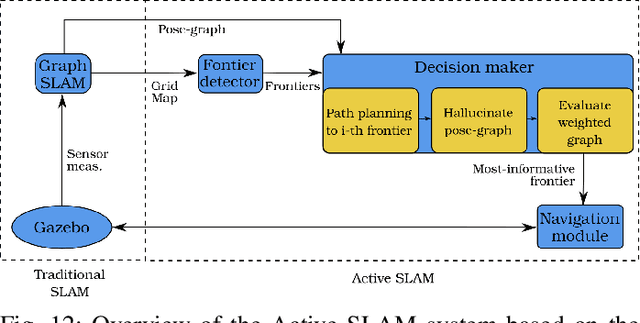
Quantifying uncertainty is a key stage in autonomous robotic exploration, since it allows to identify the most informative actions to execute. However, dealing with full Fisher Information matrices (FIM) is computationally heavy and may become intractable for online systems. In this work, we study the paradigm of Active graph SLAM formulated over $\textit{SE(n)}$, and propose a general relationship between the full FIM and the Laplacian matrix of the underlying pose-graph. Therefore, the optimal set of actions can be estimated by maximizing optimality criteria of the weighted Laplacian instead of that of the FIM. Experimental validation proves our method leads to equivalent results in a fraction of the time traditional methods require. Based on the former, we present an online Active graph SLAM system capable of selecting D-optimal actions and that outperforms other state-of-the-art methods that rely on slower computations. Also, we propose the use of such indices as stopping criterion, making our system capable of autonomously determining when the exploration strategy is no longer adding information to the graph SLAM algorithm and it should be either changed or terminated.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos
Dec 15, 2021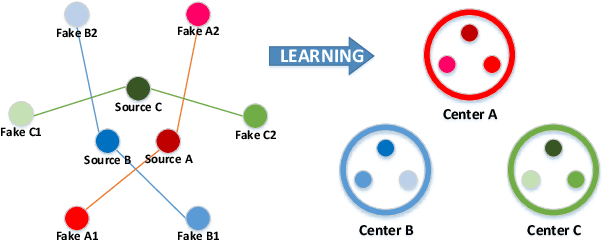
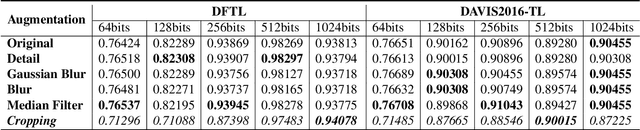
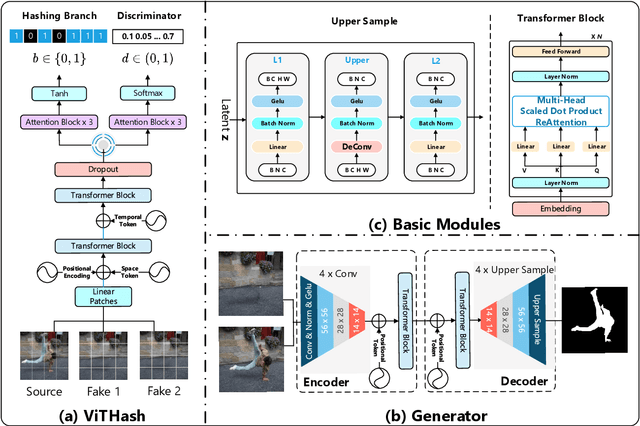

Conventional fake video detection methods outputs a possibility value or a suspected mask of tampering images. However, such unexplainable results cannot be used as convincing evidence. So it is better to trace the sources of fake videos. The traditional hashing methods are used to retrieve semantic-similar images, which can't discriminate the nuances of the image. Specifically, the sources tracing compared with traditional video retrieval. It is a challenge to find the real one from similar source videos. We designed a novel loss Hash Triplet Loss to solve the problem that the videos of people are very similar: the same scene with different angles, similar scenes with the same person. We propose Vision Transformer based models named Video Tracing and Tampering Localization (VTL). In the first stage, we train the hash centers by ViTHash (VTL-T). Then, a fake video is inputted to ViTHash, which outputs a hash code. The hash code is used to retrieve the source video from hash centers. In the second stage, the source video and fake video are inputted to generator (VTL-L). Then, the suspect regions are masked to provide auxiliary information. Moreover, we constructed two datasets: DFTL and DAVIS2016-TL. Experiments on DFTL clearly show the superiority of our framework in sources tracing of similar videos. In particular, the VTL also achieved comparable performance with state-of-the-art methods on DAVIS2016-TL. Our source code and datasets have been released on GitHub: \url{https://github.com/lajlksdf/vtl}.
Fusion Detection via Distance-Decay IoU and weighted Dempster-Shafer Evidence Theory
Dec 06, 2021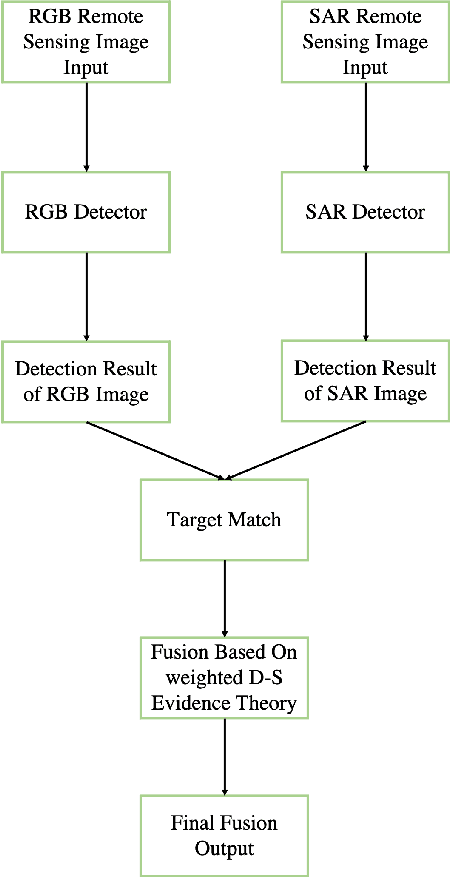

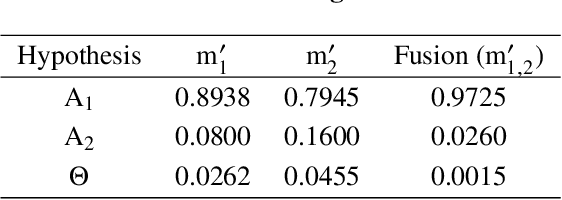
In recent years, increasing attentions are paid on object detection in remote sensing imagery. However, traditional optical detection is highly susceptible to illumination and weather anomaly. It is a challenge to effectively utilize the cross-modality information from multi-source remote sensing images, especially from optical and synthetic aperture radar images, to achieve all-day and all-weather detection with high accuracy and speed. Towards this end, a fast multi-source fusion detection framework is proposed in current paper. A novel distance-decay intersection over union is employed to encode the shape properties of the targets with scale invariance. Therefore, the same target in multi-source images can be paired accurately. Furthermore, the weighted Dempster-Shafer evidence theory is utilized to combine the optical and synthetic aperture radar detection, which overcomes the drawback in feature-level fusion that requires a large amount of paired data. In addition, the paired optical and synthetic aperture radar images for container ship Ever Given which ran aground in the Suez Canal are taken to demonstrate our fusion algorithm. To test the effectiveness of the proposed method, on self-built data set, the average precision of the proposed fusion detection framework outperform the optical detection by 20.13%.
Keyword Extraction for Improved Document Retrieval in Conversational Search
Sep 22, 2021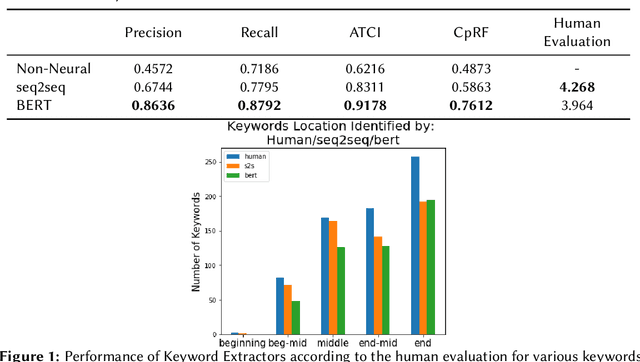
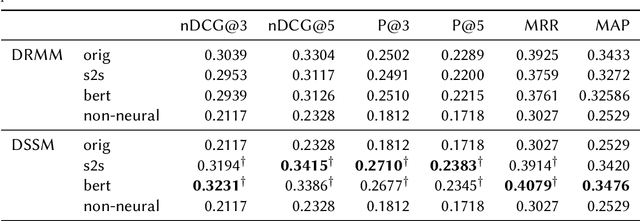
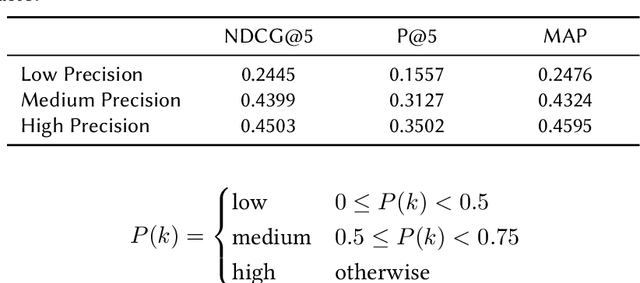
Recent research has shown that mixed-initiative conversational search, based on the interaction between users and computers to clarify and improve a query, provides enormous advantages. Nonetheless, incorporating additional information provided by the user from the conversation poses some challenges. In fact, further interactions could confuse the system as a user might use words irrelevant to the information need but crucial for correct sentence construction in the context of multi-turn conversations. To this aim, in this paper, we have collected two conversational keyword extraction datasets and propose an end-to-end document retrieval pipeline incorporating them. Furthermore, we study the performance of two neural keyword extraction models, namely, BERT and sequence to sequence, in terms of extraction accuracy and human annotation. Finally, we study the effect of keyword extraction on the end-to-end neural IR performance and show that our approach beats state-of-the-art IR models. We make the two datasets publicly available to foster research in this area.
DANets: Deep Abstract Networks for Tabular Data Classification and Regression
Dec 06, 2021
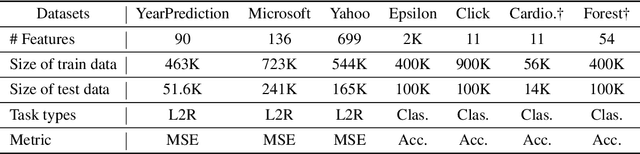
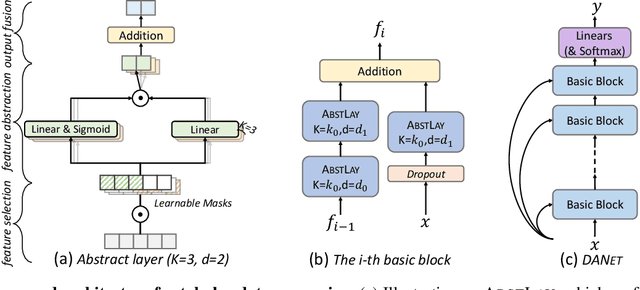
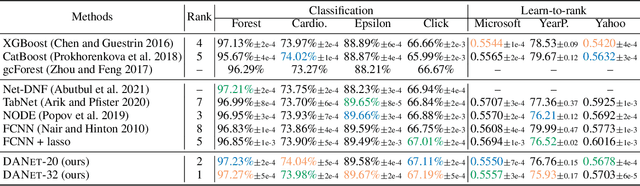
Tabular data are ubiquitous in real world applications. Although many commonly-used neural components (e.g., convolution) and extensible neural networks (e.g., ResNet) have been developed by the machine learning community, few of them were effective for tabular data and few designs were adequately tailored for tabular data structures. In this paper, we propose a novel and flexible neural component for tabular data, called Abstract Layer (AbstLay), which learns to explicitly group correlative input features and generate higher-level features for semantics abstraction. Also, we design a structure re-parameterization method to compress AbstLay, thus reducing the computational complexity by a clear margin in the reference phase. A special basic block is built using AbstLays, and we construct a family of Deep Abstract Networks (DANets) for tabular data classification and regression by stacking such blocks. In DANets, a special shortcut path is introduced to fetch information from raw tabular features, assisting feature interactions across different levels. Comprehensive experiments on seven real-world tabular datasets show that our AbstLay and DANets are effective for tabular data classification and regression, and the computational complexity is superior to competitive methods. Besides, we evaluate the performance gains of DANet as it goes deep, verifying the extendibility of our method. Our code is available at https://github.com/WhatAShot/DANet.
You Only Need End-to-End Training for Long-Tailed Recognition
Dec 15, 2021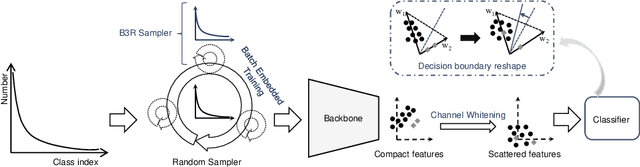
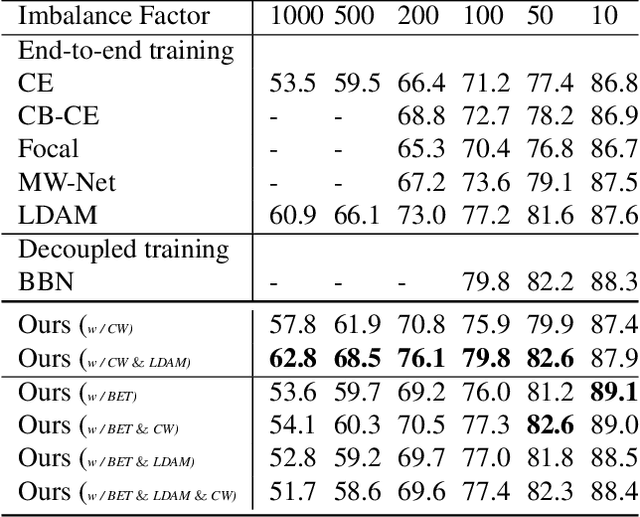
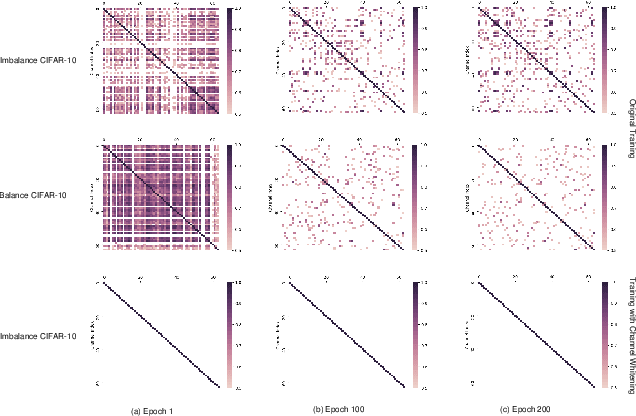
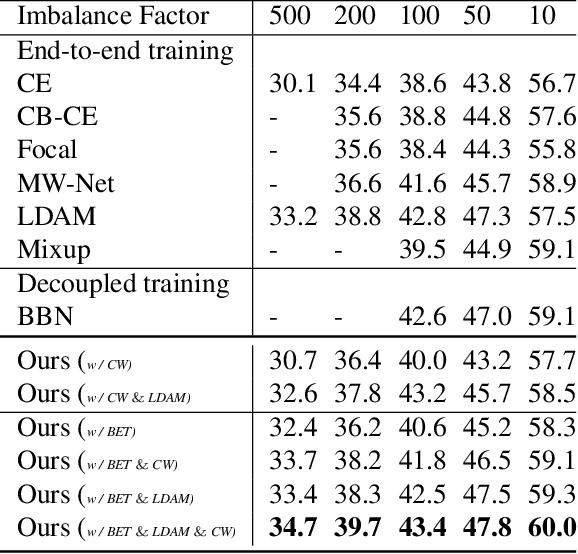
The generalization gap on the long-tailed data sets is largely owing to most categories only occupying a few training samples. Decoupled training achieves better performance by training backbone and classifier separately. What causes the poorer performance of end-to-end model training (e.g., logits margin-based methods)? In this work, we identify a key factor that affects the learning of the classifier: the channel-correlated features with low entropy before inputting into the classifier. From the perspective of information theory, we analyze why cross-entropy loss tends to produce highly correlated features on the imbalanced data. In addition, we theoretically analyze and prove its impacts on the gradients of classifier weights, the condition number of Hessian, and logits margin-based approach. Therefore, we firstly propose to use Channel Whitening to decorrelate ("scatter") the classifier's inputs for decoupling the weight update and reshaping the skewed decision boundary, which achieves satisfactory results combined with logits margin-based method. However, when the number of minor classes are large, batch imbalance and more participation in training cause over-fitting of the major classes. We also propose two novel modules, Block-based Relatively Balanced Batch Sampler (B3RS) and Batch Embedded Training (BET) to solve the above problems, which makes the end-to-end training achieve even better performance than decoupled training. Experimental results on the long-tailed classification benchmarks, CIFAR-LT and ImageNet-LT, demonstrate the effectiveness of our method.
Technological Approaches to Detecting Online Disinformation and Manipulation
Aug 26, 2021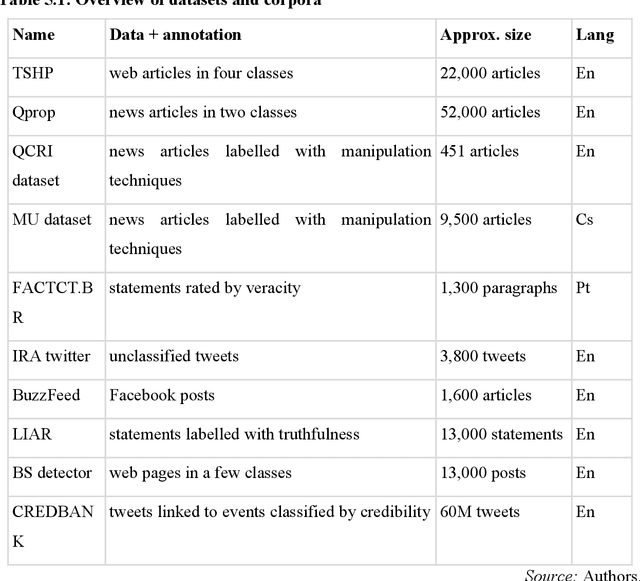
The move of propaganda and disinformation to the online environment is possible thanks to the fact that within the last decade, digital information channels radically increased in popularity as a news source. The main advantage of such media lies in the speed of information creation and dissemination. This, on the other hand, inevitably adds pressure, accelerating editorial work, fact-checking, and the scrutiny of source credibility. In this chapter, an overview of computer-supported approaches to detecting disinformation and manipulative techniques based on several criteria is presented. We concentrate on the technical aspects of automatic methods which support fact-checking, topic identification, text style analysis, or message filtering on social media channels. Most of the techniques employ artificial intelligence and machine learning with feature extraction combining available information resources. The following text firstly specifies the tasks related to computer detection of manipulation and disinformation spreading. The second section presents concrete methods of solving the tasks of the analysis, and the third sections enlists current verification and benchmarking datasets published and used in this area for evaluation and comparison.