 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Slot-VPS: Object-centric Representation Learning for Video Panoptic Segmentation
Dec 16, 2021
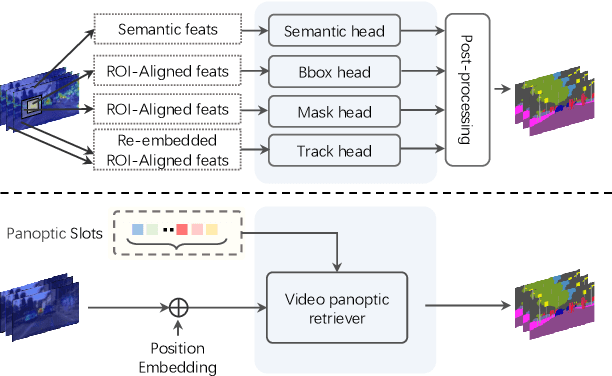
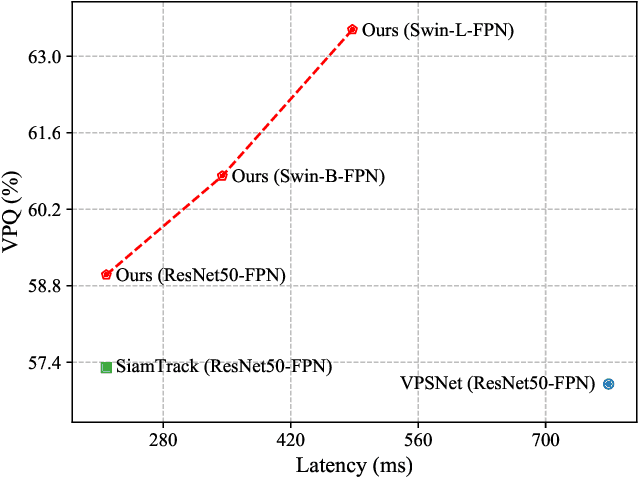
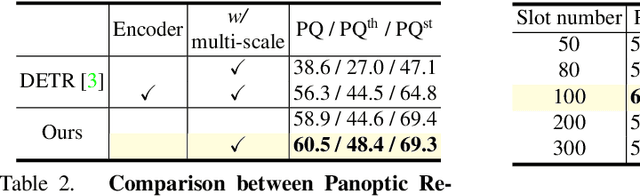
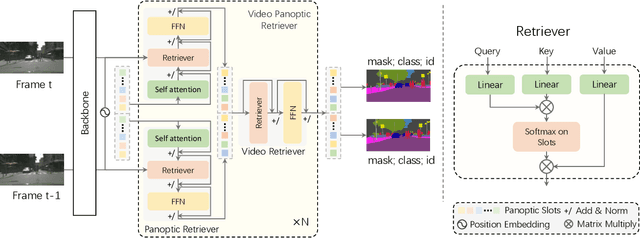
Video Panoptic Segmentation (VPS) aims at assigning a class label to each pixel, uniquely segmenting and identifying all object instances consistently across all frames. Classic solutions usually decompose the VPS task into several sub-tasks and utilize multiple surrogates (e.g. boxes and masks, centres and offsets) to represent objects. However, this divide-and-conquer strategy requires complex post-processing in both spatial and temporal domains and is vulnerable to failures from surrogate tasks. In this paper, inspired by object-centric learning which learns compact and robust object representations, we present Slot-VPS, the first end-to-end framework for this task. We encode all panoptic entities in a video, including both foreground instances and background semantics, with a unified representation called panoptic slots. The coherent spatio-temporal object's information is retrieved and encoded into the panoptic slots by the proposed Video Panoptic Retriever, enabling it to localize, segment, differentiate, and associate objects in a unified manner. Finally, the output panoptic slots can be directly converted into the class, mask, and object ID of panoptic objects in the video. We conduct extensive ablation studies and demonstrate the effectiveness of our approach on two benchmark datasets, Cityscapes-VPS (\textit{val} and test sets) and VIPER (\textit{val} set), achieving new state-of-the-art performance of 63.7, 63.3 and 56.2 VPQ, respectively.
Attention Is Indeed All You Need: Semantically Attention-Guided Decoding for Data-to-Text NLG
Sep 15, 2021

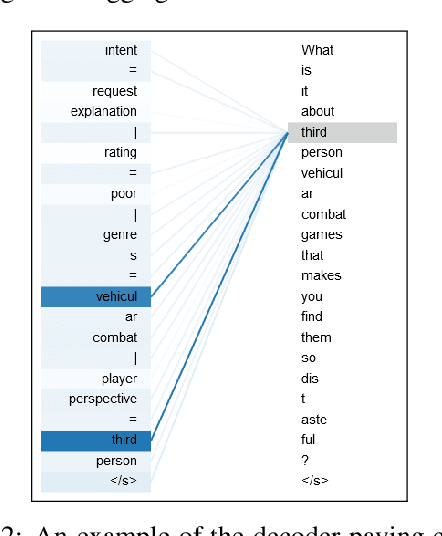
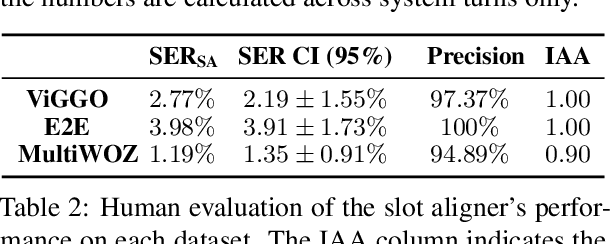
Ever since neural models were adopted in data-to-text language generation, they have invariably been reliant on extrinsic components to improve their semantic accuracy, because the models normally do not exhibit the ability to generate text that reliably mentions all of the information provided in the input. In this paper, we propose a novel decoding method that extracts interpretable information from encoder-decoder models' cross-attention, and uses it to infer which attributes are mentioned in the generated text, which is subsequently used to rescore beam hypotheses. Using this decoding method with T5 and BART, we show on three datasets its ability to dramatically reduce semantic errors in the generated outputs, while maintaining their state-of-the-art quality.
Information processing constraints in travel behaviour modelling: A generative learning approach
Jul 16, 2019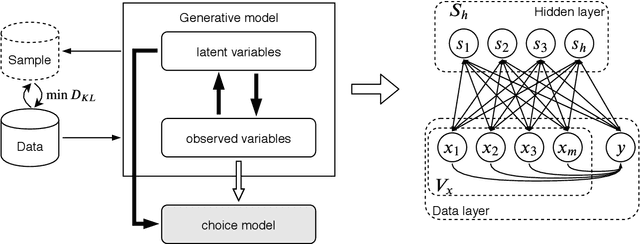
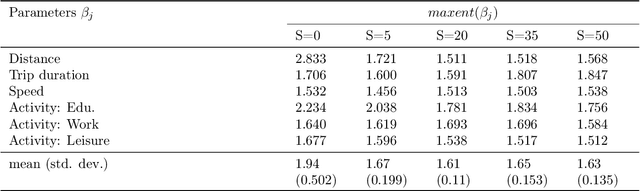
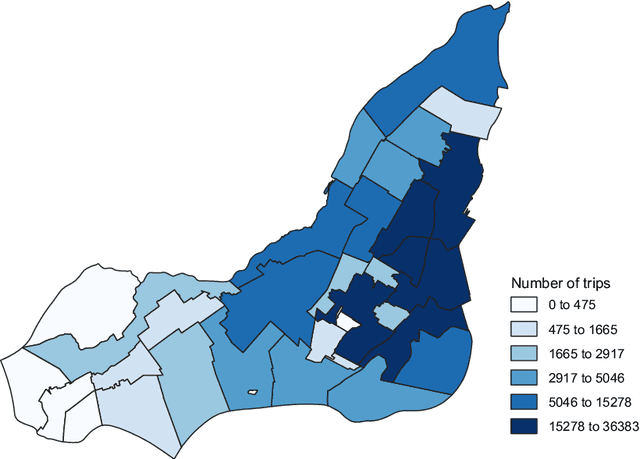
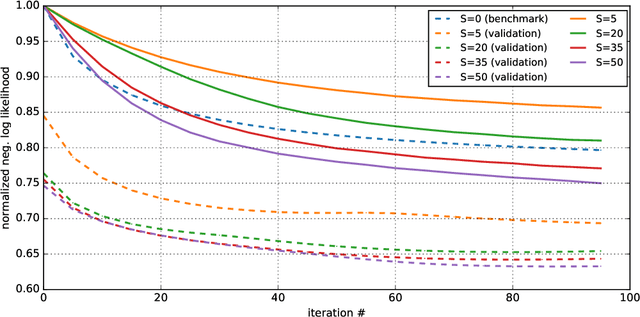
Travel decisions tend to exhibit sensitivity to uncertainty and information processing constraints. These behavioural conditions can be characterized by a generative learning process. We propose a data-driven generative model version of rational inattention theory to emulate these behavioural representations. We outline the methodology of the generative model and the associated learning process as well as provide an intuitive explanation of how this process captures the value of prior information in the choice utility specification. We demonstrate the effects of information heterogeneity on a travel choice, analyze the econometric interpretation, and explore the properties of our generative model. Our findings indicate a strong correlation with rational inattention behaviour theory, which suggest that individuals may ignore certain exogenous variables and rely on prior information for evaluating decisions under uncertainty. Finally, the principles demonstrated in this study can be formulated as a generalized entropy and utility based multinomial logit model.
Controlling Wasserstein distances by Kernel norms with application to Compressive Statistical Learning
Dec 01, 2021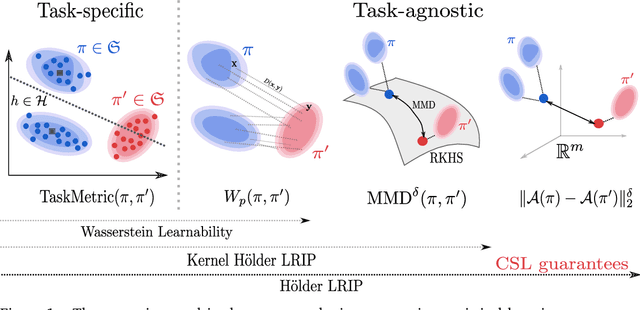
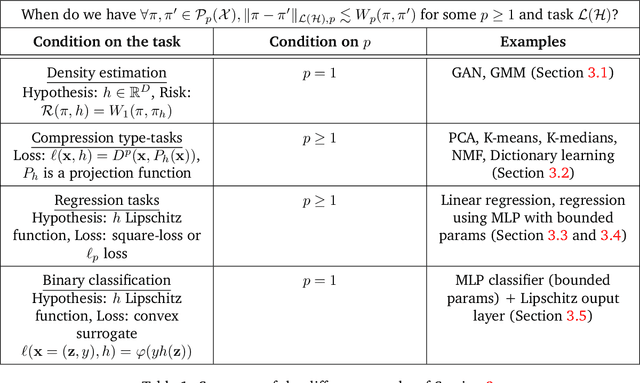
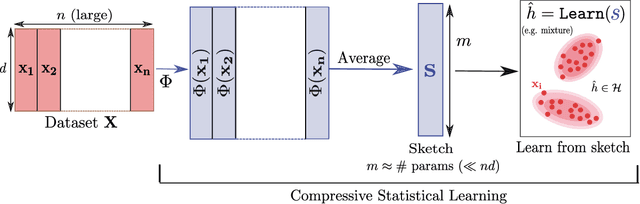

Comparing probability distributions is at the crux of many machine learning algorithms. Maximum Mean Discrepancies (MMD) and Optimal Transport distances (OT) are two classes of distances between probability measures that have attracted abundant attention in past years. This paper establishes some conditions under which the Wasserstein distance can be controlled by MMD norms. Our work is motivated by the compressive statistical learning (CSL) theory, a general framework for resource-efficient large scale learning in which the training data is summarized in a single vector (called sketch) that captures the information relevant to the considered learning task. Inspired by existing results in CSL, we introduce the H\"older Lower Restricted Isometric Property (H\"older LRIP) and show that this property comes with interesting guarantees for compressive statistical learning. Based on the relations between the MMD and the Wasserstein distance, we provide guarantees for compressive statistical learning by introducing and studying the concept of Wasserstein learnability of the learning task, that is when some task-specific metric between probability distributions can be bounded by a Wasserstein distance.
Assisted Learning for Organizations with Limited Data
Sep 21, 2021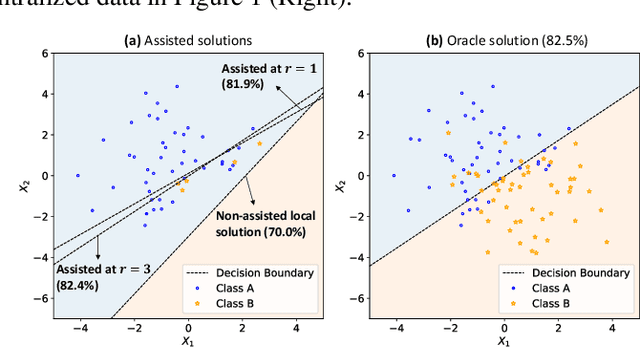
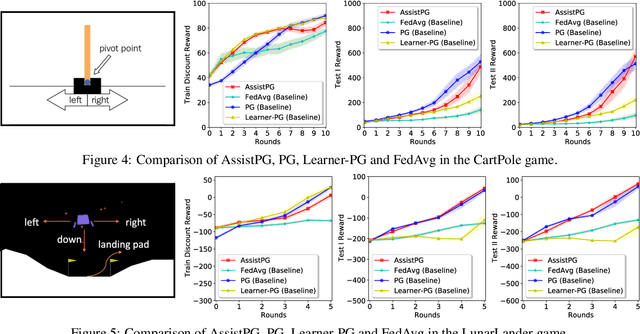
We develop an assisted learning framework for assisting organization-level learners to improve their learning performance with limited and imbalanced data. In particular, learners at the organization level usually have sufficient computation resource, but are subject to stringent collaboration policy and information privacy. Their limited imbalanced data often cause biased inference and sub-optimal decision-making. In our assisted learning framework, an organizational learner purchases assistance service from a service provider and aims to enhance its model performance within a few assistance rounds. We develop effective stochastic training algorithms for assisted deep learning and assisted reinforcement learning. Different from existing distributed algorithms that need to frequently transmit gradients or models, our framework allows the learner to only occasionally share information with the service provider, and still achieve a near-oracle model as if all the data were centralized.
Multistep traffic speed prediction: A deep learning based approach using latent space mapping considering spatio-temporal dependencies
Nov 03, 2021
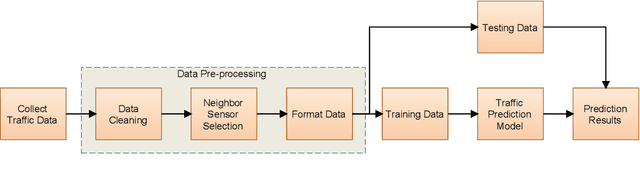
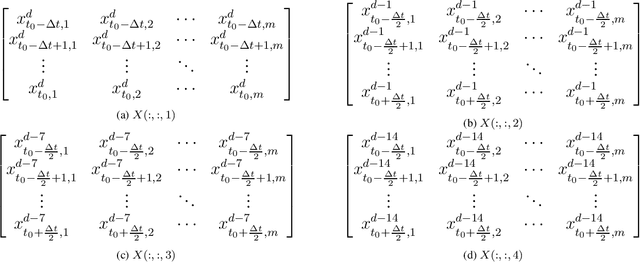
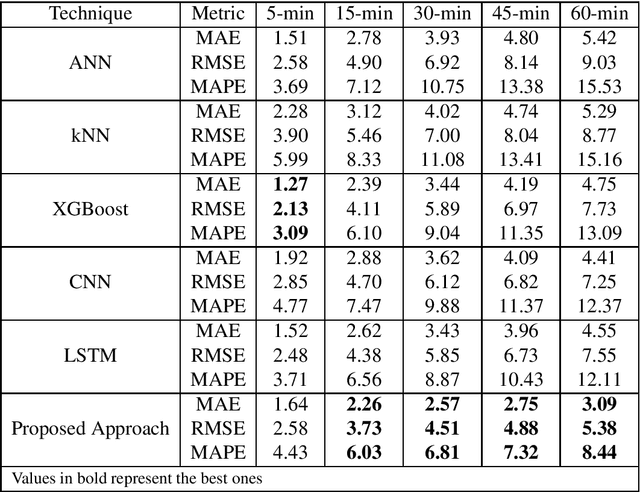
Traffic management in a city has become a major problem due to the increasing number of vehicles on roads. Intelligent Transportation System (ITS) can help the city traffic managers to tackle the problem by providing accurate traffic forecasts. For this, ITS requires a reliable traffic prediction algorithm that can provide accurate traffic prediction at multiple time steps based on past and current traffic data. In recent years, a number of different methods for traffic prediction have been proposed which have proved their effectiveness in terms of accuracy. However, most of these methods have either considered spatial information or temporal information only and overlooked the effect of other. In this paper, to address the above problem a deep learning based approach has been developed using both the spatial and temporal dependencies. To consider spatio-temporal dependencies, nearby road sensors at a particular instant are selected based on the attributes like traffic similarity and distance. Two pre-trained deep auto-encoders were cross-connected using the concept of latent space mapping and the resultant model was trained using the traffic data from the selected nearby sensors as input. The proposed deep learning based approach was trained using the real-world traffic data collected from loop detector sensors installed on different highways of Los Angeles and Bay Area. The traffic data is freely available from the web portal of the California Department of Transportation Performance Measurement System (PeMS). The effectiveness of the proposed approach was verified by comparing it with a number of machine/deep learning approaches. It has been found that the proposed approach provides accurate traffic prediction results even for 60-min ahead prediction with least error than other techniques.
Deep Measurement Updates for Bayes Filters
Dec 01, 2021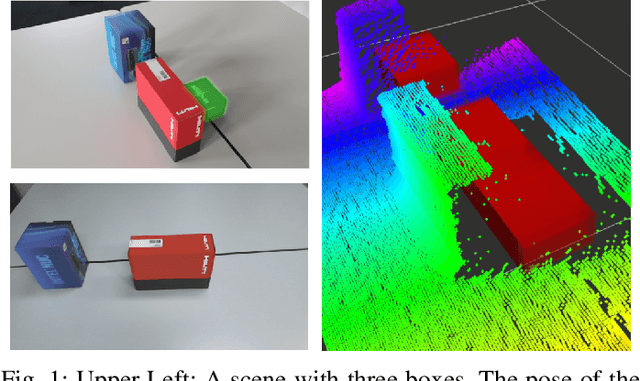
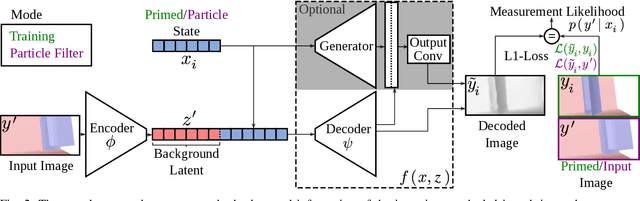
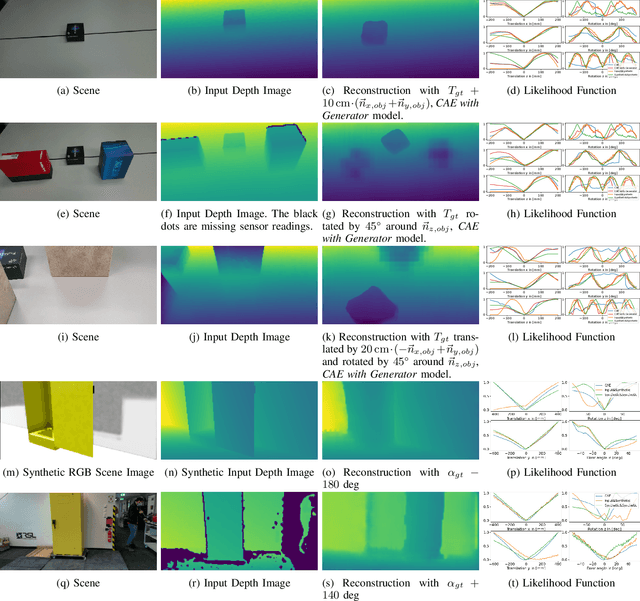

Measurement update rules for Bayes filters often contain hand-crafted heuristics to compute observation probabilities for high-dimensional sensor data, like images. In this work, we propose the novel approach Deep Measurement Update (DMU) as a general update rule for a wide range of systems. DMU has a conditional encoder-decoder neural network structure to process depth images as raw inputs. Even though the network is trained only on synthetic data, the model shows good performance at evaluation time on real-world data. With our proposed training scheme primed data training , we demonstrate how the DMU models can be trained efficiently to be sensitive to condition variables without having to rely on a stochastic information bottleneck. We validate the proposed methods in multiple scenarios of increasing complexity, beginning with the pose estimation of a single object to the joint estimation of the pose and the internal state of an articulated system. Moreover, we provide a benchmark against Articulated Signed Distance Functions(A-SDF) on the RBO dataset as a baseline comparison for articulation state estimation.
U-shaped Transformer with Frequency-Band Aware Attention for Speech Enhancement
Dec 11, 2021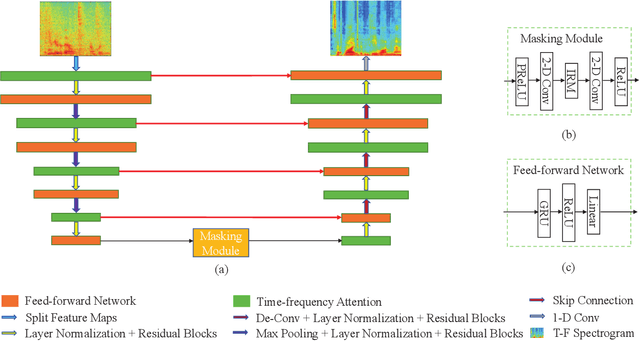
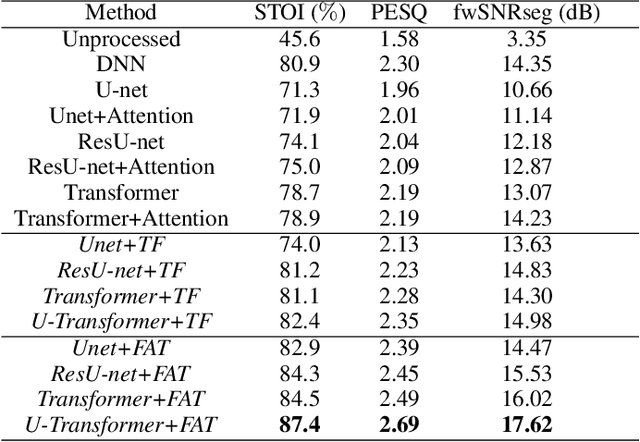
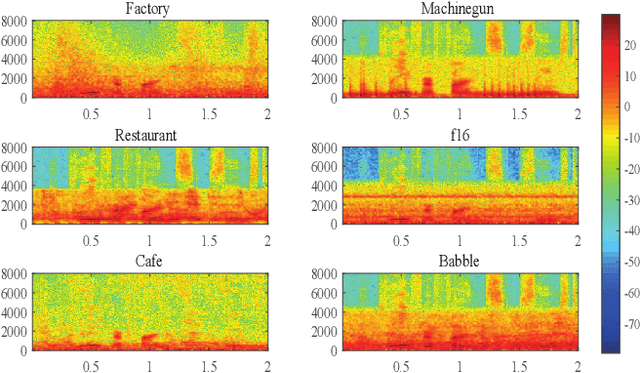
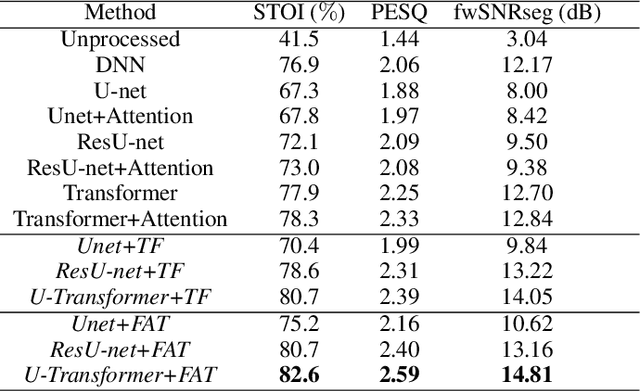
The state-of-the-art speech enhancement has limited performance in speech estimation accuracy. Recently, in deep learning, the Transformer shows the potential to exploit the long-range dependency in speech by self-attention. Therefore, it is introduced in speech enhancement to improve the speech estimation accuracy from a noise mixture. However, to address the computational cost issue in Transformer with self-attention, the axial attention is the option i.e., to split a 2D attention into two 1D attentions. Inspired by the axial attention, in the proposed method we calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps. Moreover, different from the axial attention, the proposed method provides two parallel multi-head attentions for time- and frequency-axis. Furthermore, it is proven in the literature that the lower frequency-band in speech, generally, contains more desired information than the higher frequency-band, in a noise mixture. Therefore, the frequency-band aware attention is proposed i.e., high frequency-band attention (HFA), and low frequency-band attention (LFA). The U-shaped Transformer is also first time introduced in the proposed method to further improve the speech estimation accuracy. The extensive evaluations over four public datasets, confirm the efficacy of the proposed method.
Unsupervised Domain Adaptation for Semantic Image Segmentation: a Comprehensive Survey
Dec 06, 2021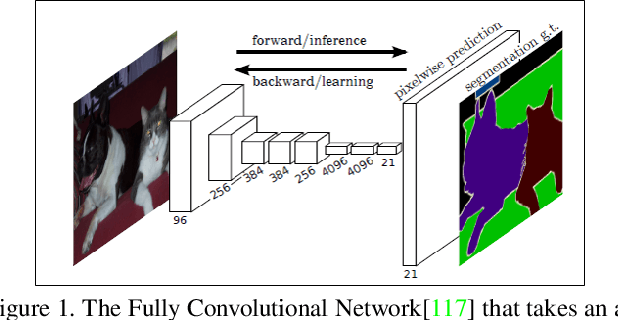
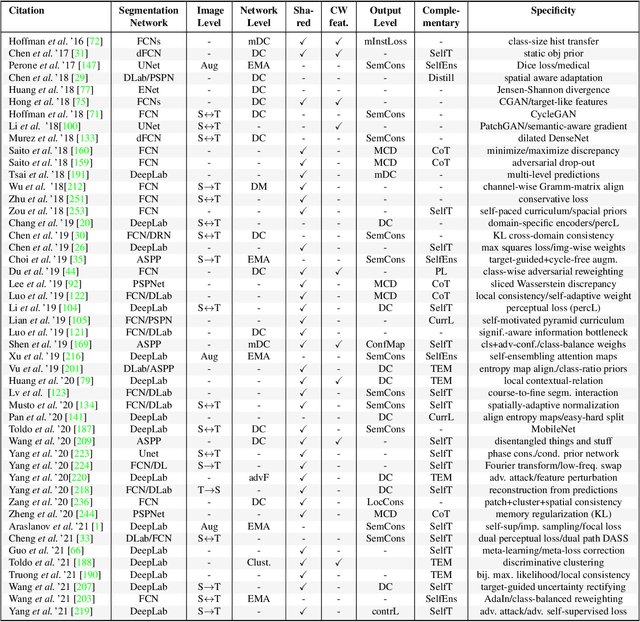
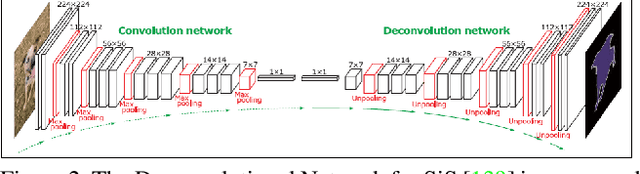
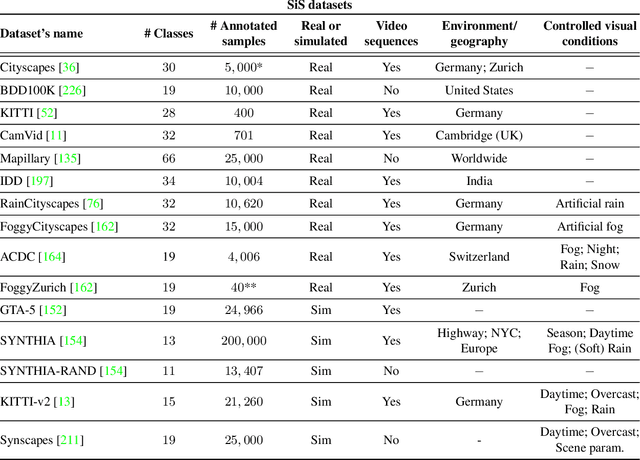
Semantic segmentation plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. Yet, the state-of-the-art models rely on large amount of annotated samples, which are more expensive to obtain than in tasks such as image classification. Since unlabelled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation reached a broad success within the semantic segmentation community. This survey is an effort to summarize five years of this incredibly rapidly growing field, which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. We present the most important semantic segmentation methods; we provide a comprehensive survey on domain adaptation techniques for semantic segmentation; we unveil newer trends such as multi-domain learning, domain generalization, test-time adaptation or source-free domain adaptation; we conclude this survey by describing datasets and benchmarks most widely used in semantic segmentation research. We hope that this survey will provide researchers across academia and industry with a comprehensive reference guide and will help them in fostering new research directions in the field.
Delineating Knowledge Domains in the Scientific Literature Using Visual Information
Aug 12, 2019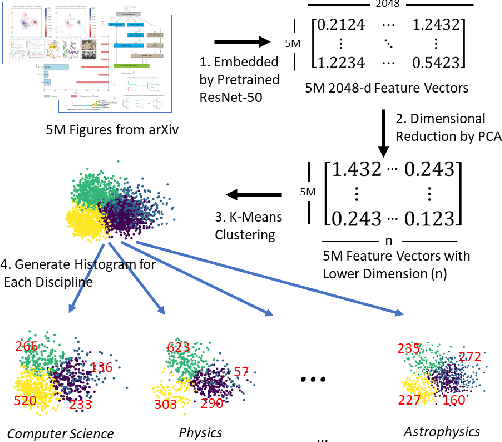
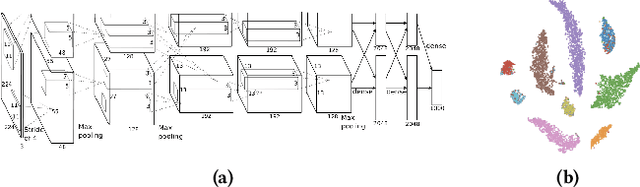
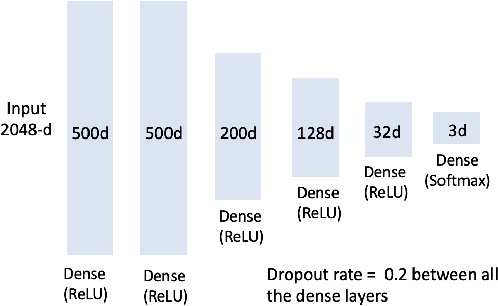
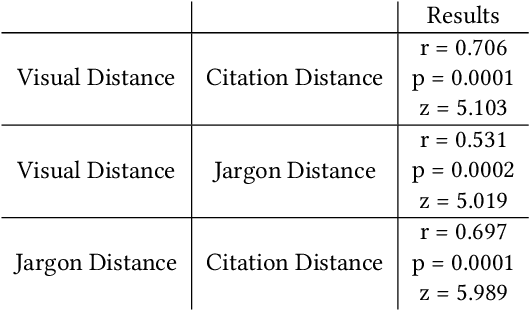
Figures are an important channel for scientific communication, used to express complex ideas, models and data in ways that words cannot. However, this visual information is mostly ignored in analyses of the scientific literature. In this paper, we demonstrate the utility of using scientific figures as markers of knowledge domains in science, which can be used for classification, recommender systems, and studies of scientific information exchange. We encode sets of images into a visual signature, then use distances between these signatures to understand how patterns of visual communication compare with patterns of jargon and citation structures. We find that figures can be as effective for differentiating communities of practice as text or citation patterns. We then consider where these metrics disagree to understand how different disciplines use visualization to express ideas. Finally, we further consider how specific figure types propagate through the literature, suggesting a new mechanism for understanding the flow of ideas apart from conventional channels of text and citations. Our ultimate aim is to better leverage these information-dense objects to improve scientific communication across disciplinary boundaries.