 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SpecTNT: a Time-Frequency Transformer for Music Audio
Oct 18, 2021


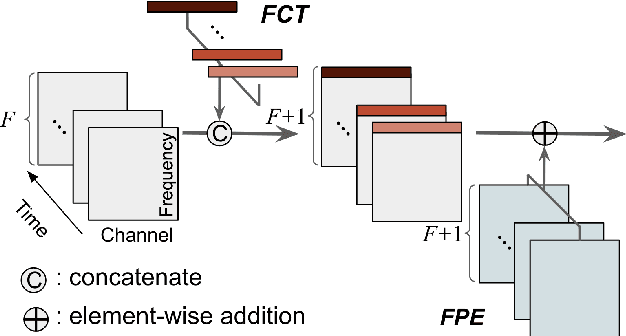
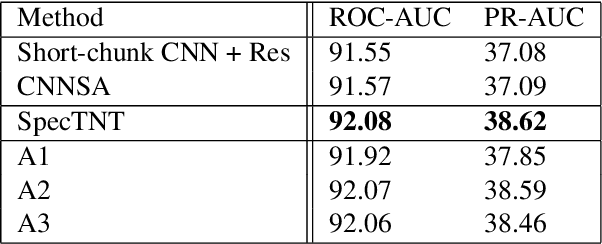
Transformers have drawn attention in the MIR field for their remarkable performance shown in natural language processing and computer vision. However, prior works in the audio processing domain mostly use Transformer as a temporal feature aggregator that acts similar to RNNs. In this paper, we propose SpecTNT, a Transformer-based architecture to model both spectral and temporal sequences of an input time-frequency representation. Specifically, we introduce a novel variant of the Transformer-in-Transformer (TNT) architecture. In each SpecTNT block, a spectral Transformer extracts frequency-related features into the frequency class token (FCT) for each frame. Later, the FCTs are linearly projected and added to the temporal embeddings (TEs), which aggregate useful information from the FCTs. Then, a temporal Transformer processes the TEs to exchange information across the time axis. By stacking the SpecTNT blocks, we build the SpecTNT model to learn the representation for music signals. In experiments, SpecTNT demonstrates state-of-the-art performance in music tagging and vocal melody extraction, and shows competitive performance for chord recognition. The effectiveness of SpecTNT and other design choices are further examined through ablation studies.
* 6 pages
A Survey on Legal Question Answering Systems
Oct 12, 2021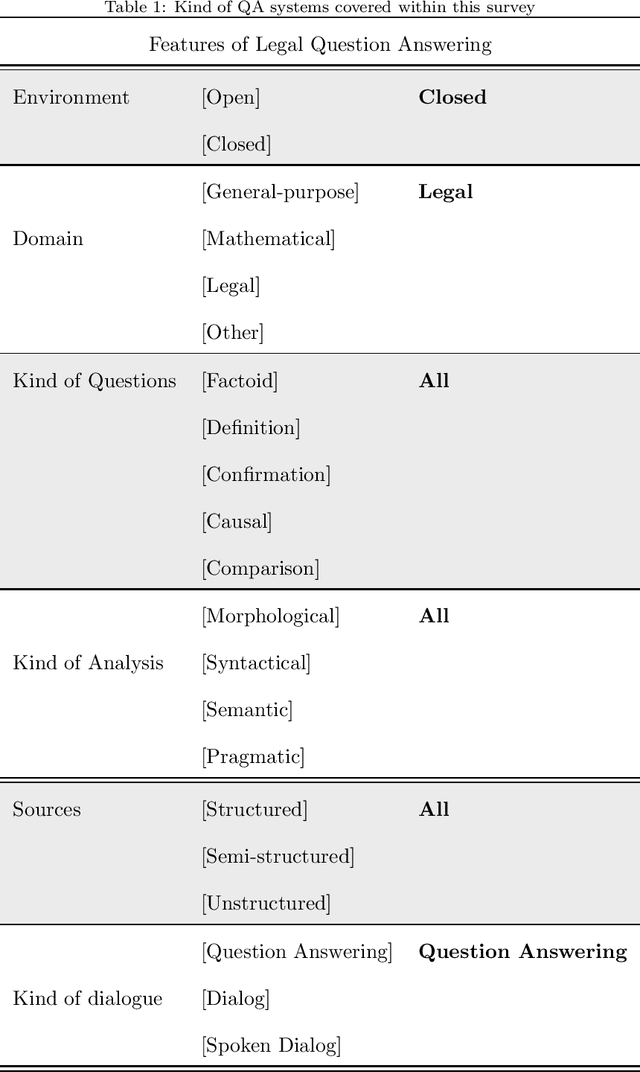
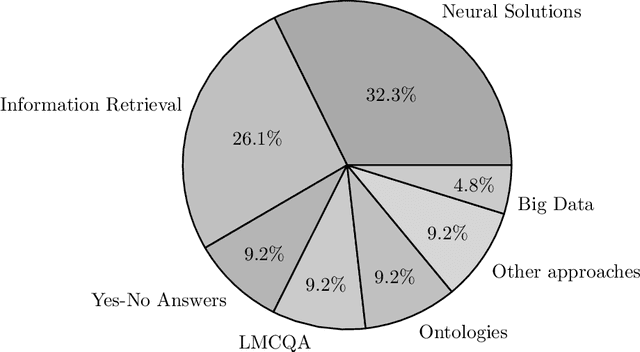
Many legal professionals think that the explosion of information about local, regional, national, and international legislation makes their practice more costly, time-consuming, and even error-prone. The two main reasons for this are that most legislation is usually unstructured, and the tremendous amount and pace with which laws are released causes information overload in their daily tasks. In the case of the legal domain, the research community agrees that a system allowing to generate automatic responses to legal questions could substantially impact many practical implications in daily activities. The degree of usefulness is such that even a semi-automatic solution could significantly help to reduce the workload to be faced. This is mainly because a Question Answering system could be able to automatically process a massive amount of legal resources to answer a question or doubt in seconds, which means that it could save resources in the form of effort, money, and time to many professionals in the legal sector. In this work, we quantitatively and qualitatively survey the solutions that currently exist to meet this challenge.
Learners that Use Little Information
Feb 28, 2018We study learning algorithms that are restricted to using a small amount of information from their input sample. We introduce a category of learning algorithms we term $d$-bit information learners, which are algorithms whose output conveys at most $d$ bits of information of their input. A central theme in this work is that such algorithms generalize. We focus on the learning capacity of these algorithms, and prove sample complexity bounds with tight dependencies on the confidence and error parameters. We also observe connections with well studied notions such as sample compression schemes, Occam's razor, PAC-Bayes and differential privacy. We discuss an approach that allows us to prove upper bounds on the amount of information that algorithms reveal about their inputs, and also provide a lower bound by showing a simple concept class for which every (possibly randomized) empirical risk minimizer must reveal a lot of information. On the other hand, we show that in the distribution-dependent setting every VC class has empirical risk minimizers that do not reveal a lot of information.
Align and Prompt: Video-and-Language Pre-training with Entity Prompts
Dec 23, 2021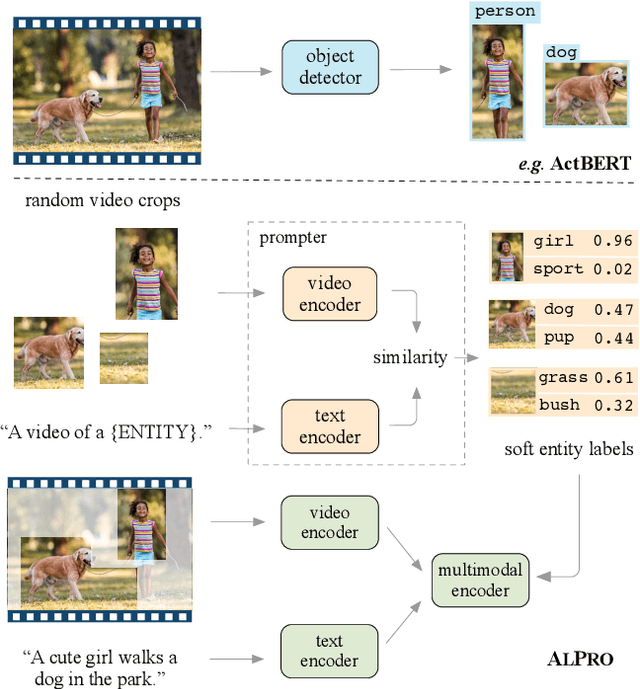
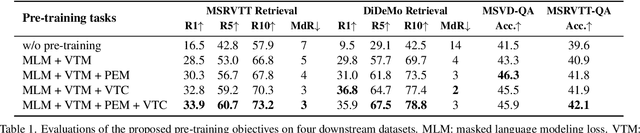
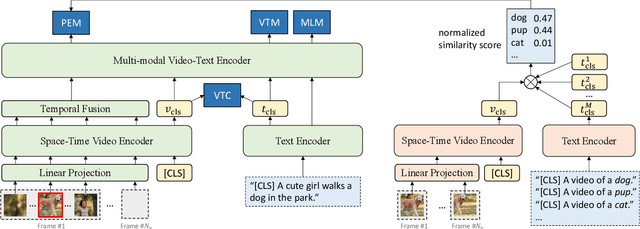
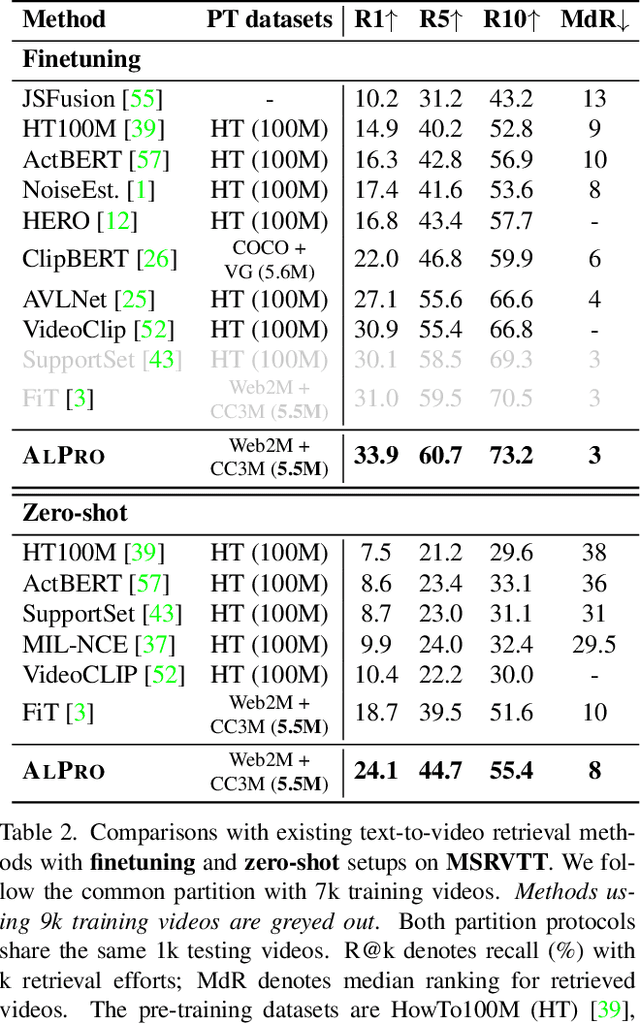
Video-and-language pre-training has shown promising improvements on various downstream tasks. Most previous methods capture cross-modal interactions with a transformer-based multimodal encoder, not fully addressing the misalignment between unimodal video and text features. Besides, learning fine-grained visual-language alignment usually requires off-the-shelf object detectors to provide object information, which is bottlenecked by the detector's limited vocabulary and expensive computation cost. We propose Align and Prompt: an efficient and effective video-and-language pre-training framework with better cross-modal alignment. First, we introduce a video-text contrastive (VTC) loss to align unimodal video-text features at the instance level, which eases the modeling of cross-modal interactions. Then, we propose a new visually-grounded pre-training task, prompting entity modeling (PEM), which aims to learn fine-grained region-entity alignment. To achieve this, we first introduce an entity prompter module, which is trained with VTC to produce the similarity between a video crop and text prompts instantiated with entity names. The PEM task then asks the model to predict the entity pseudo-labels (i.e~normalized similarity scores) for randomly-selected video crops. The resulting pre-trained model achieves state-of-the-art performance on both text-video retrieval and videoQA, outperforming prior work by a substantial margin. Our code and pre-trained models are available at https://github.com/salesforce/ALPRO.
HYPERION: Hyperspectral Penetrating-type Ellipsoidal Reconstruction for Terahertz Blind Source Separation
Sep 30, 2021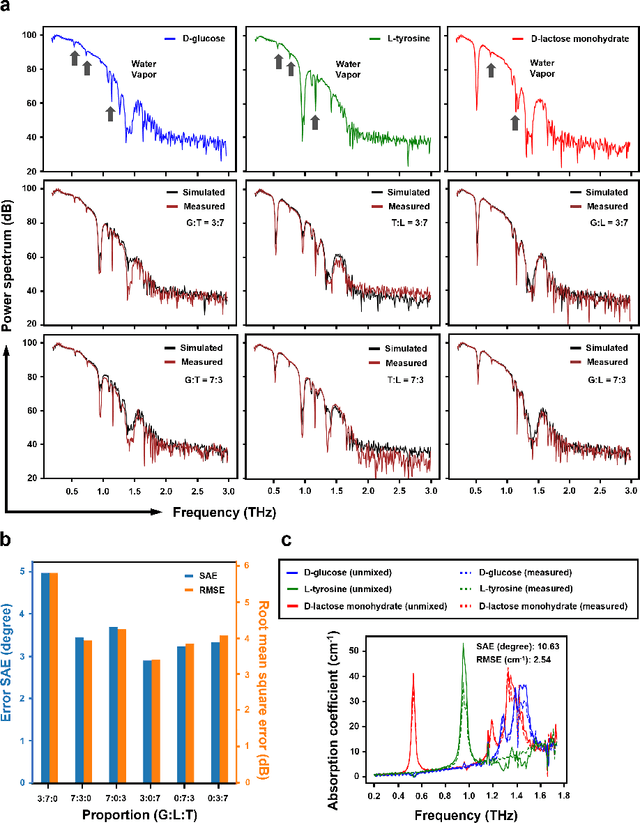
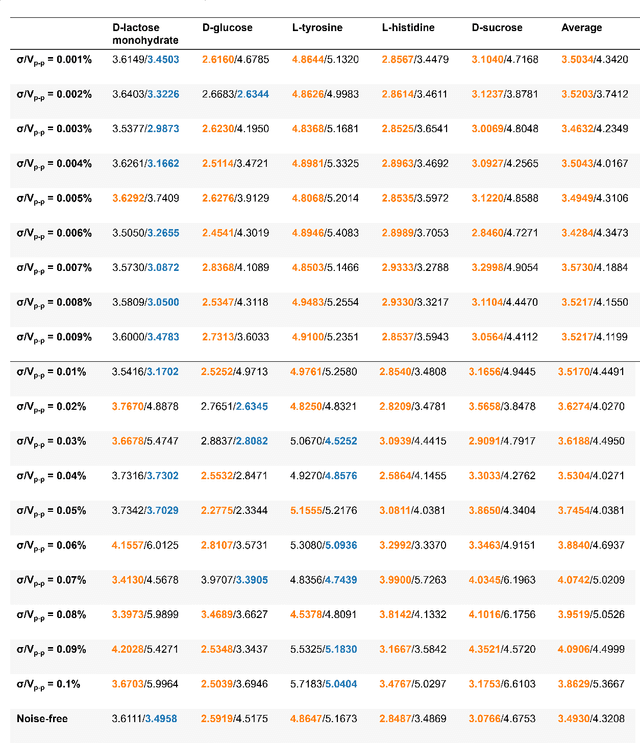
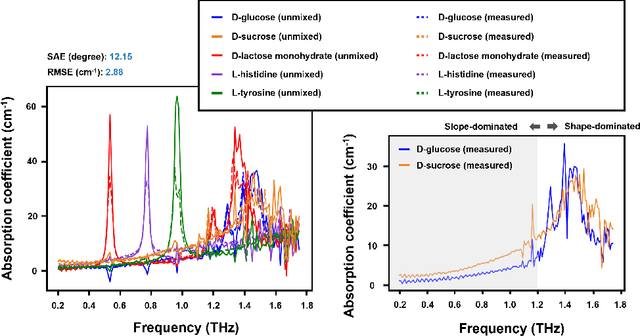

Terahertz (THz) technology has been a great candidate for applications, including pharmaceutic analysis, chemical identification, and remote sensing and imaging due to its non-invasive and non-destructive properties. Among those applications, penetrating-type hyperspectral THz signals, which provide crucial material information, normally involve a noisy, complex mixture system. Additionally, the measured THz signals could be ill-conditioned due to the overlap of the material absorption peak in the measured bands. To address those issues, we consider penetrating-type signal mixtures and aim to develop a blind hyperspectral unmixing (HU) method without requiring any information from a prebuilt database. The proposed HYperspectral Penetrating-type Ellipsoidal ReconstructION (HYPERION) algorithm is unsupervised, not relying on collecting extensive data or sophisticated model training. Instead, it is developed based on elegant ellipsoidal geometry under a very mild requirement on data purity, whose excellent efficacy is experimentally demonstrated.
What do Large Language Models Learn about Scripts?
Dec 27, 2021

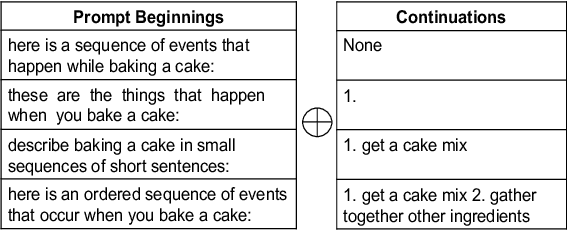
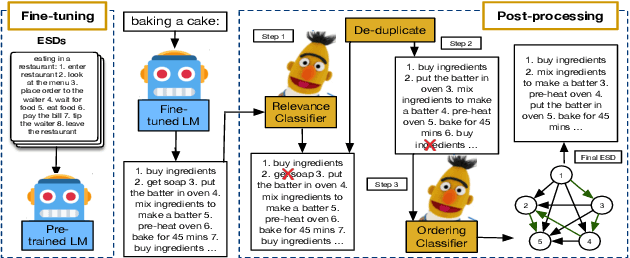
Script Knowledge (Schank and Abelson, 1975) has long been recognized as crucial for language understanding as it can help in filling in unstated information in a narrative. However, such knowledge is expensive to produce manually and difficult to induce from text due to reporting bias (Gordon and Van Durme, 2013). In this work, we are interested in the scientific question of whether explicit script knowledge is present and accessible through pre-trained generative language models (LMs). To this end, we introduce the task of generating full event sequence descriptions (ESDs) given a scenario in the form of natural language prompts. In zero-shot probing experiments, we find that generative LMs produce poor ESDs with mostly omitted, irrelevant, repeated or misordered events. To address this, we propose a pipeline-based script induction framework (SIF) which can generate good quality ESDs for unseen scenarios (e.g., bake a cake). SIF is a two-staged framework that fine-tunes LM on a small set of ESD examples in the first stage. In the second stage, ESD generated for an unseen scenario is post-processed using RoBERTa-based models to filter irrelevant events, remove repetitions, and reorder the temporally misordered events. Through automatic and manual evaluations, we demonstrate that SIF yields substantial improvements ($1$-$3$ BLUE points) over a fine-tuned LM. However, manual analysis shows that there is great room for improvement, offering a new research direction for inducing script knowledge.
An Investigation of the Effectiveness of Phase for Audio Classification
Oct 06, 2021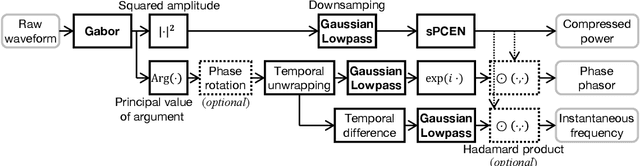

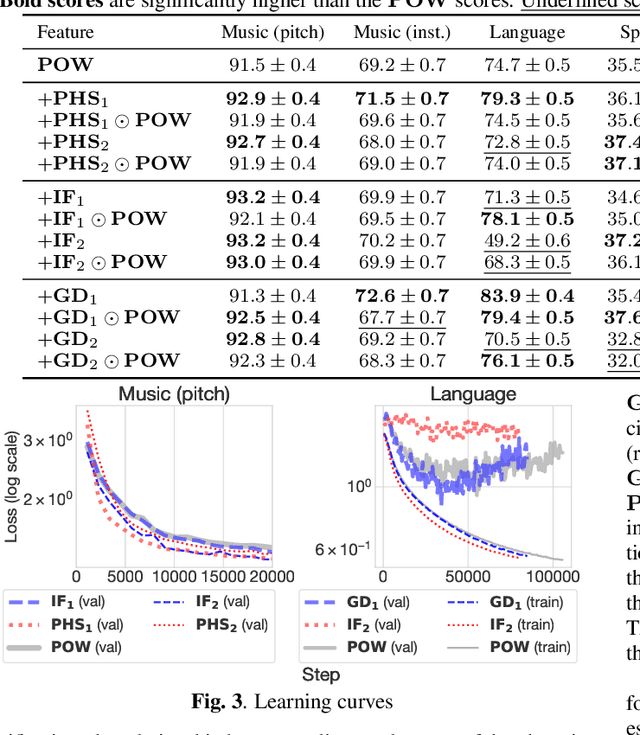
While log-amplitude mel-spectrogram has widely been used as the feature representation for processing speech based on deep learning, the effectiveness of another aspect of speech spectrum, i.e., phase information, was shown recently for tasks such as speech enhancement and source separation. In this study, we extensively investigated the effectiveness of including phase information of signals for eight audio classification tasks. We constructed a learnable front-end that can compute the phase and its derivatives based on a time-frequency representation with mel-like frequency axis. As a result, experimental results showed significant performance improvement for musical pitch detection, musical instrument detection, language identification, speaker identification, and birdsong detection. On the other hand, overfitting to the recording condition was observed for some tasks when the instantaneous frequency was used. The results implied that the relationship between the phase values of adjacent elements is more important than the phase itself in audio classification.
Predicting infections in the Covid-19 pandemic -- lessons learned
Dec 02, 2021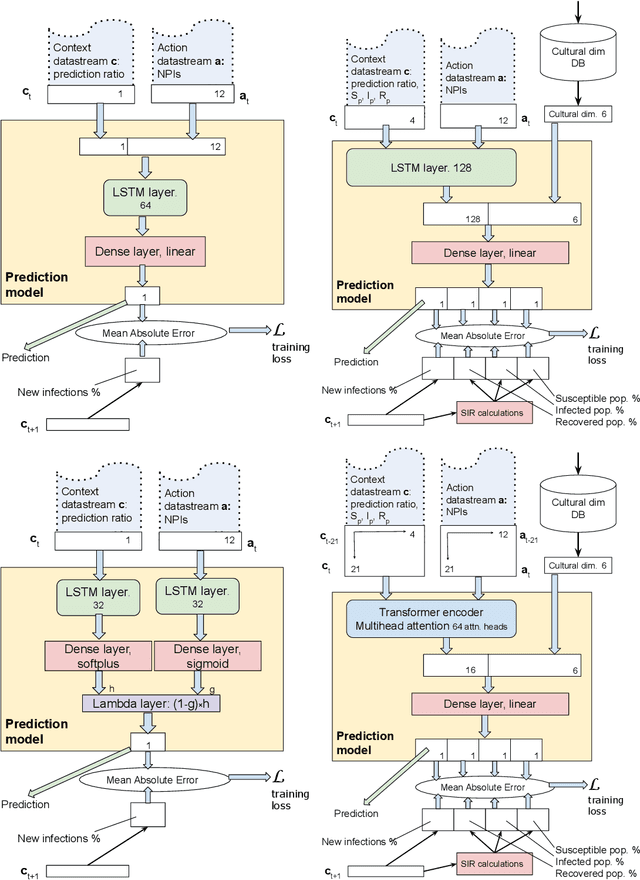
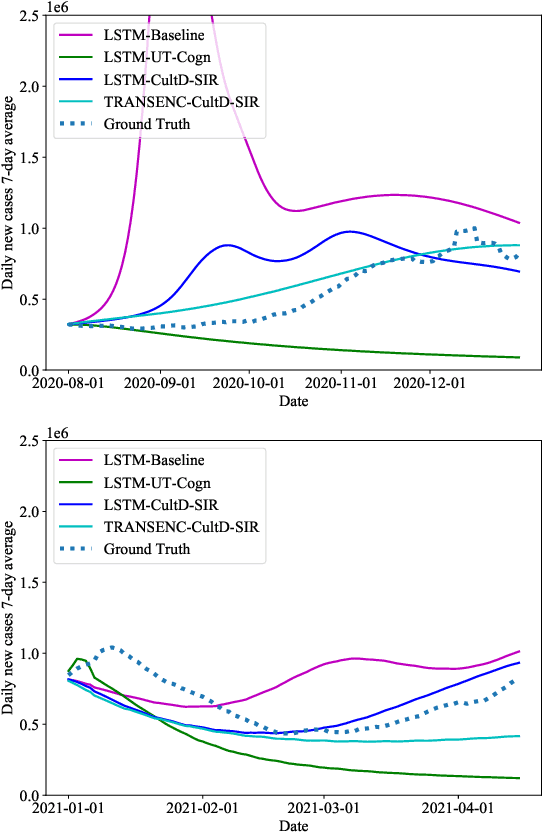

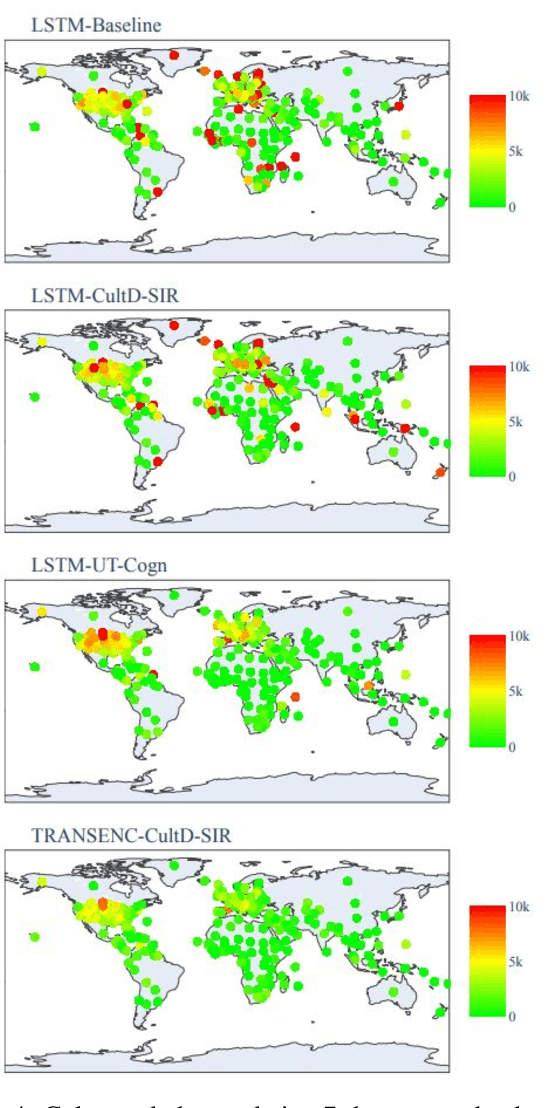
Throughout the Covid-19 pandemic, a significant amount of effort had been put into developing techniques that predict the number of infections under various assumptions about the public policy and non-pharmaceutical interventions. While both the available data and the sophistication of the AI models and available computing power exceed what was available in previous years, the overall success of prediction approaches was very limited. In this paper, we start from prediction algorithms proposed for XPrize Pandemic Response Challenge and consider several directions that might allow their improvement. Then, we investigate their performance over medium-term predictions extending over several months. We find that augmenting the algorithms with additional information about the culture of the modeled region, incorporating traditional compartmental models and up-to-date deep learning architectures can improve the performance for short term predictions, the accuracy of medium-term predictions is still very low and a significant amount of future research is needed to make such models a reliable component of a public policy toolbox.
Applying Surface Normal Information in Drivable Area and Road Anomaly Detection for Ground Mobile Robots
Aug 26, 2020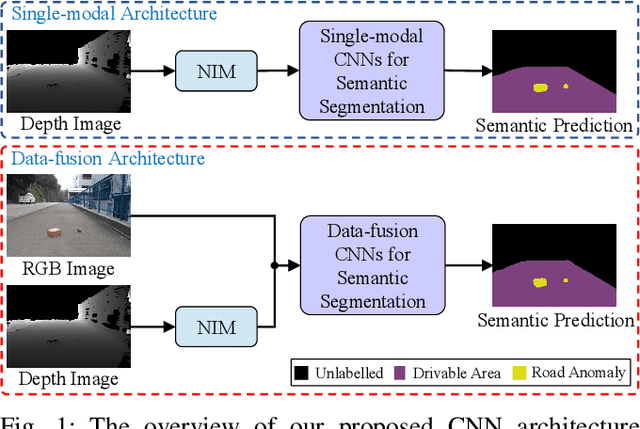
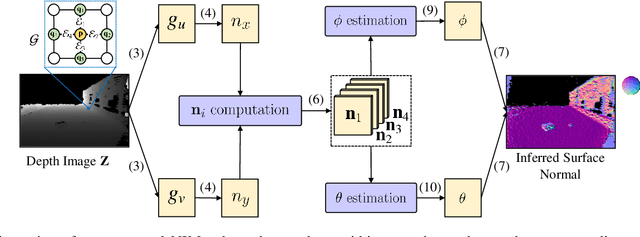
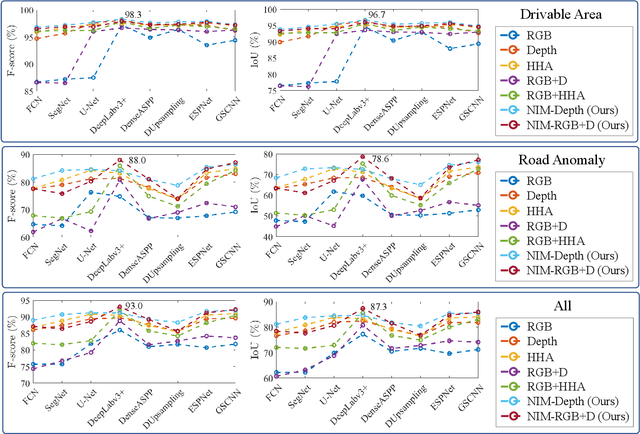
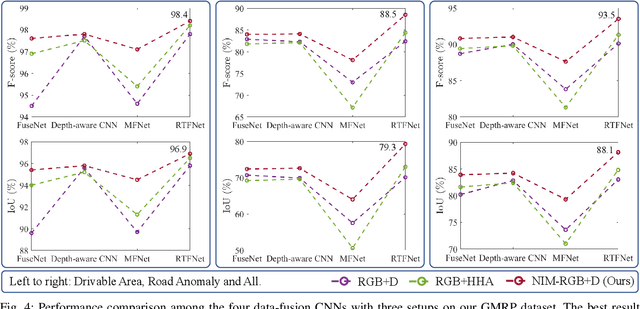
The joint detection of drivable areas and road anomalies is a crucial task for ground mobile robots. In recent years, many impressive semantic segmentation networks, which can be used for pixel-level drivable area and road anomaly detection, have been developed. However, the detection accuracy still needs improvement. Therefore, we develop a novel module named the Normal Inference Module (NIM), which can generate surface normal information from dense depth images with high accuracy and efficiency. Our NIM can be deployed in existing convolutional neural networks (CNNs) to refine the segmentation performance. To evaluate the effectiveness and robustness of our NIM, we embed it in twelve state-of-the-art CNNs. The experimental results illustrate that our NIM can greatly improve the performance of the CNNs for drivable area and road anomaly detection. Furthermore, our proposed NIM-RTFNet ranks 8th on the KITTI road benchmark and exhibits a real-time inference speed.
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation
Jul 26, 2021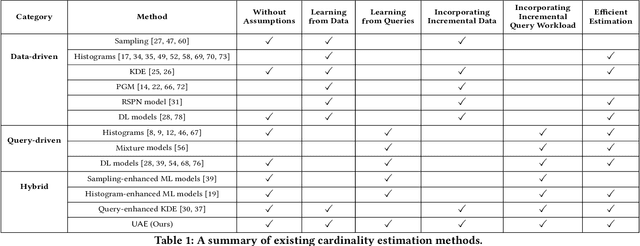
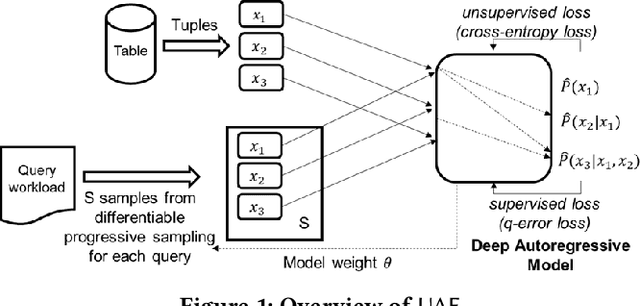
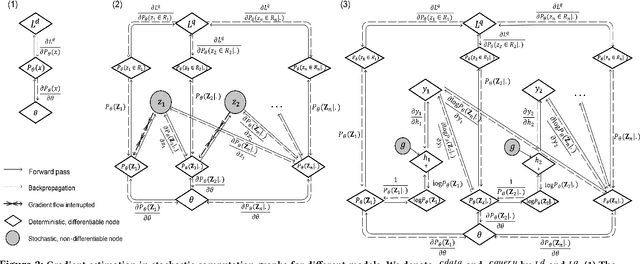
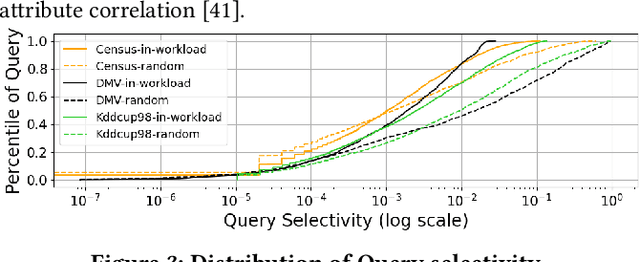
Cardinality estimation is a fundamental problem in database systems. To capture the rich joint data distributions of a relational table, most of the existing work either uses data as unsupervised information or uses query workload as supervised information. Very little work has been done to use both types of information, and cannot fully make use of both types of information to learn the joint data distribution. In this work, we aim to close the gap between data-driven and query-driven methods by proposing a new unified deep autoregressive model, UAE, that learns the joint data distribution from both the data and query workload. First, to enable using the supervised query information in the deep autoregressive model, we develop differentiable progressive sampling using the Gumbel-Softmax trick. Second, UAE is able to utilize both types of information to learn the joint data distribution in a single model. Comprehensive experimental results demonstrate that UAE achieves single-digit multiplicative error at tail, better accuracies over state-of-the-art methods, and is both space and time efficient.