 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and Open-data Driven Scalable Solar Power Profiling
May 04, 2026Solar photovoltaic (PV) deployment is expanding rapidly, yet detailed, up-to-date information on the spatial distribution and capacity of rooftop PV remains limited. This paper presents an open, scalable framework for detecting solar panels from open data and generating city-level solar power profiles. We leverage foundation vision AI models to detect solar panel geometries from open-source satellite imagery. This avoids manual data labeling and case-specific model training while maintaining robustness across heterogeneous imagery. Detected solar panels are converted into georeferenced polygons, yielding spatially explicit and incrementally extensible inventories. By integrating open weather data, we translate panel footprints into regional solar power profiles. The framework reduces dependency on proprietary imagery, manual labeling, and closed-source models, and offers a transparent and scalable approach for solar planning and analysis. We released the data and an API resulted from this work. For any user-specified building location, our API retrieves aerial imagery, detects rooftop solar panels, and returns georeferenced polygons. This empowers researchers and developers to scan user-defined areas to build solar panel maps and associated solar production profiles, thus facilitating advanced analysis like distributed solar production integration, local power flow optimization, energy tariff design, and infrastructure planning.
When Can We Trust LLM Graders? Calibrating Confidence for Automated Assessment
Mar 31, 2026Large Language Models (LLMs) show promise for automated grading, but their outputs can be unreliable. Rather than improving grading accuracy directly, we address a complementary problem: \textit{predicting when an LLM grader is likely to be correct}. This enables selective automation where high-confidence predictions are processed automatically while uncertain cases are flagged for human review. We compare three confidence estimation methods (self-reported confidence, self-consistency voting, and token probability) across seven LLMs of varying scale (4B to 120B parameters) on three educational datasets: RiceChem (long-answer chemistry), SciEntsBank, and Beetle (short-answer science). Our experiments reveal that self-reported confidence consistently achieves the best calibration across all conditions (avg ECE 0.166 vs 0.229 for self-consistency). Surprisingly, self-consistency remains 38\% worse despite requiring 5$\times$ the inference cost. Larger models exhibit substantially better calibration though gains vary by dataset and method (e.g., a 28\% ECE reduction for self-reported), with GPT-OSS-120B achieving the best calibration (avg ECE 0.100) and strong discrimination (avg AUC 0.668). We also observe that confidence is strongly top-skewed across methods, creating a ``confidence floor'' that practitioners must account for when setting thresholds. These findings suggest that simply asking LLMs to report their confidence provides a practical approach for identifying reliable grading predictions. Code is available \href{https://github.com/sonkar-lab/llm_grading_calibration}{here}.
Uncertainty-Guided Coarse-to-Fine Tumor Segmentation with Anatomy-Aware Post-Processing
Apr 16, 2025Reliable tumor segmentation in thoracic computed tomography (CT) remains challenging due to boundary ambiguity, class imbalance, and anatomical variability. We propose an uncertainty-guided, coarse-to-fine segmentation framework that combines full-volume tumor localization with refined region-of-interest (ROI) segmentation, enhanced by anatomically aware post-processing. The first-stage model generates a coarse prediction, followed by anatomically informed filtering based on lung overlap, proximity to lung surfaces, and component size. The resulting ROIs are segmented by a second-stage model trained with uncertainty-aware loss functions to improve accuracy and boundary calibration in ambiguous regions. Experiments on private and public datasets demonstrate improvements in Dice and Hausdorff scores, with fewer false positives and enhanced spatial interpretability. These results highlight the value of combining uncertainty modeling and anatomical priors in cascaded segmentation pipelines for robust and clinically meaningful tumor delineation. On the Orlando dataset, our framework improved Swin UNETR Dice from 0.4690 to 0.6447. Reduction in spurious components was strongly correlated with segmentation gains, underscoring the value of anatomically informed post-processing.
Smart Home Energy Management: VAE-GAN synthetic dataset generator and Q-learning
May 14, 2023



Recent years have noticed an increasing interest among academia and industry towards analyzing the electrical consumption of residential buildings and employing smart home energy management systems (HEMS) to reduce household energy consumption and costs. HEMS has been developed to simulate the statistical and functional properties of actual smart grids. Access to publicly available datasets is a major challenge in this type of research. The potential of artificial HEMS applications will be further enhanced with the development of time series that represent different operating conditions of the synthetic systems. In this paper, we propose a novel variational auto-encoder-generative adversarial network (VAE-GAN) technique for generating time-series data on energy consumption in smart homes. We also explore how the generative model performs when combined with a Q-learning-based HEMS. We tested the online performance of Q-learning-based HEMS with real-world smart home data. To test the generated dataset, we measure the Kullback-Leibler (KL) divergence, maximum mean discrepancy (MMD), and the Wasserstein distance between the probability distributions of the real and synthetic data. Our experiments show that VAE-GAN-generated synthetic data closely matches the real data distribution. Finally, we show that the generated data allows for the training of a higher-performance Q-learning-based HEMS compared to datasets generated with baseline approaches.
Self-Supervised Learning for Organs At Risk and Tumor Segmentation with Uncertainty Quantification
May 04, 2023



In this study, our goal is to show the impact of self-supervised pre-training of transformers for organ at risk (OAR) and tumor segmentation as compared to costly fully-supervised learning. The proposed algorithm is called Monte Carlo Transformer based U-Net (MC-Swin-U). Unlike many other available models, our approach presents uncertainty quantification with Monte Carlo dropout strategy while generating its voxel-wise prediction. We test and validate the proposed model on both public and one private datasets and evaluate the gross tumor volume (GTV) as well as nearby risky organs' boundaries. We show that self-supervised pre-training approach improves the segmentation scores significantly while providing additional benefits for avoiding large-scale annotation costs.
Enhancing Organ at Risk Segmentation with Improved Deep Neural Networks
Feb 03, 2022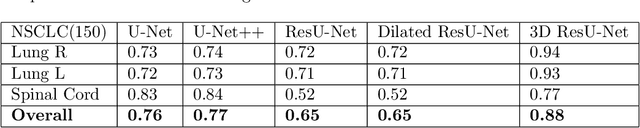
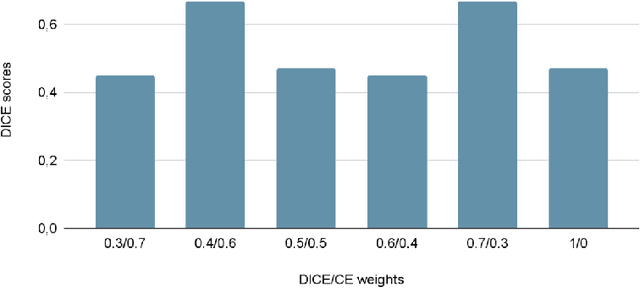
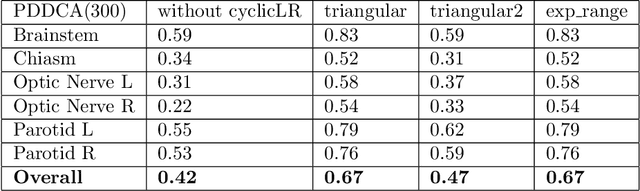
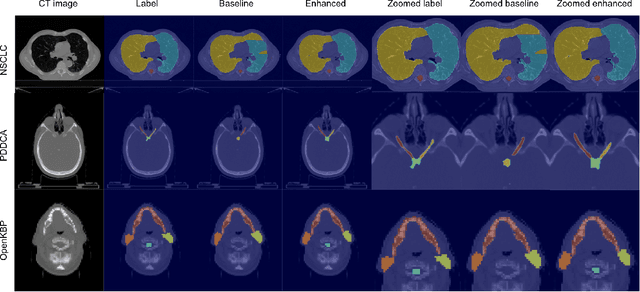
Organ at risk (OAR) segmentation is a crucial step for treatment planning and outcome determination in radiotherapy treatments of cancer patients. Several deep learning based segmentation algorithms have been developed in recent years, however, U-Net remains the de facto algorithm designed specifically for biomedical image segmentation and has spawned many variants with known weaknesses. In this study, our goal is to present simple architectural changes in U-Net to improve its accuracy and generalization properties. Unlike many other available studies evaluating their algorithms on single center data, we thoroughly evaluate several variations of U-Net as well as our proposed enhanced architecture on multiple data sets for an extensive and reliable study of the OAR segmentation problem. Our enhanced segmentation model includes (a)architectural changes in the loss function, (b)optimization framework, and (c)convolution type. Testing on three publicly available multi-object segmentation data sets, we achieved an average of 80% dice score compared to the baseline U-Net performance of 63%.
Variational Autoencoder Generative Adversarial Network for Synthetic Data Generation in Smart Home
Jan 19, 2022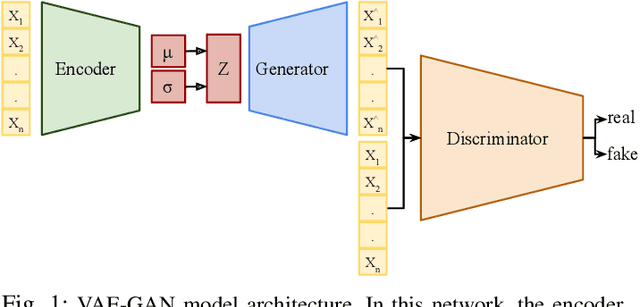
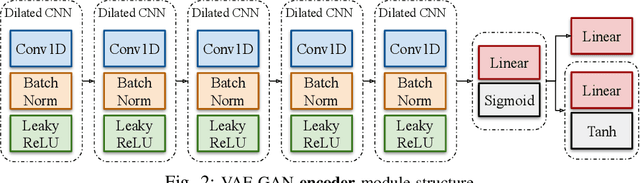
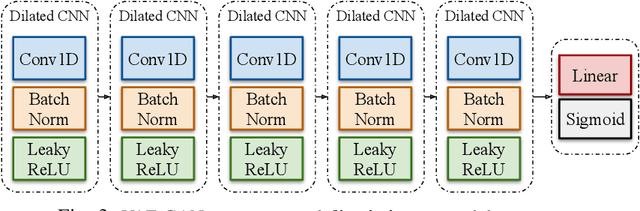
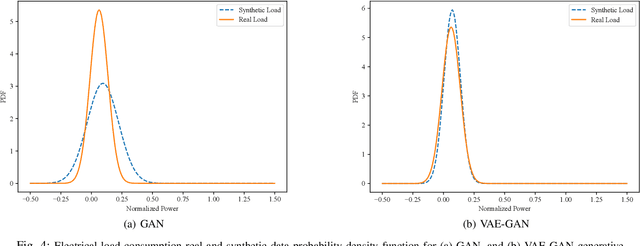
Data is the fuel of data science and machine learning techniques for smart grid applications, similar to many other fields. However, the availability of data can be an issue due to privacy concerns, data size, data quality, and so on. To this end, in this paper, we propose a Variational AutoEncoder Generative Adversarial Network (VAE-GAN) as a smart grid data generative model which is capable of learning various types of data distributions and generating plausible samples from the same distribution without performing any prior analysis on the data before the training phase.We compared the Kullback-Leibler (KL) divergence, maximum mean discrepancy (MMD), and Wasserstein distance between the synthetic data (electrical load and PV production) distribution generated by the proposed model, vanilla GAN network, and the real data distribution, to evaluate the performance of our model. Furthermore, we used five key statistical parameters to describe the smart grid data distribution and compared them between synthetic data generated by both models and real data. Experiments indicate that the proposed synthetic data generative model outperforms the vanilla GAN network. The distribution of VAE-GAN synthetic data is the most comparable to that of real data.
Predicting infections in the Covid-19 pandemic -- lessons learned
Dec 02, 2021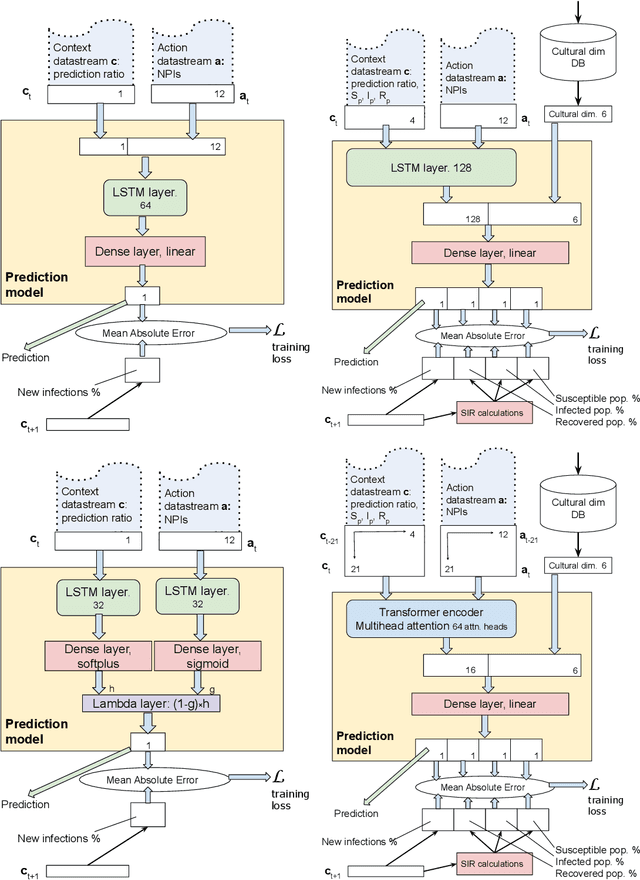
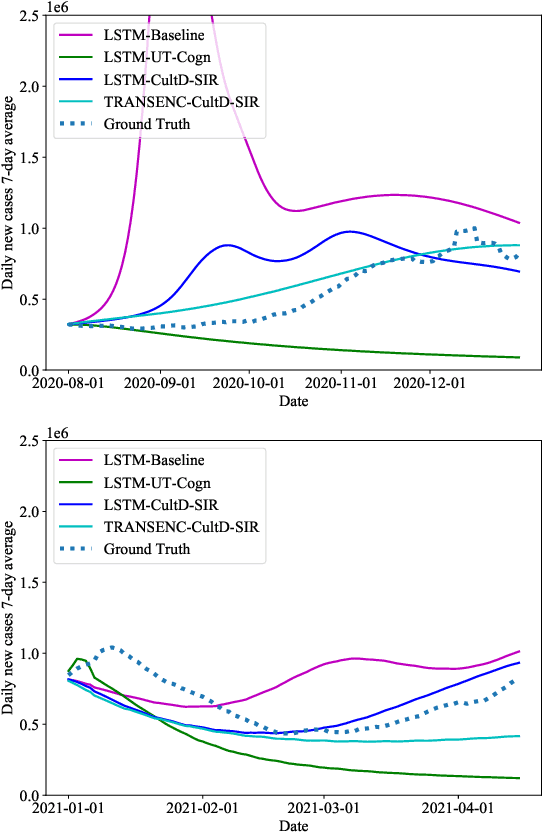

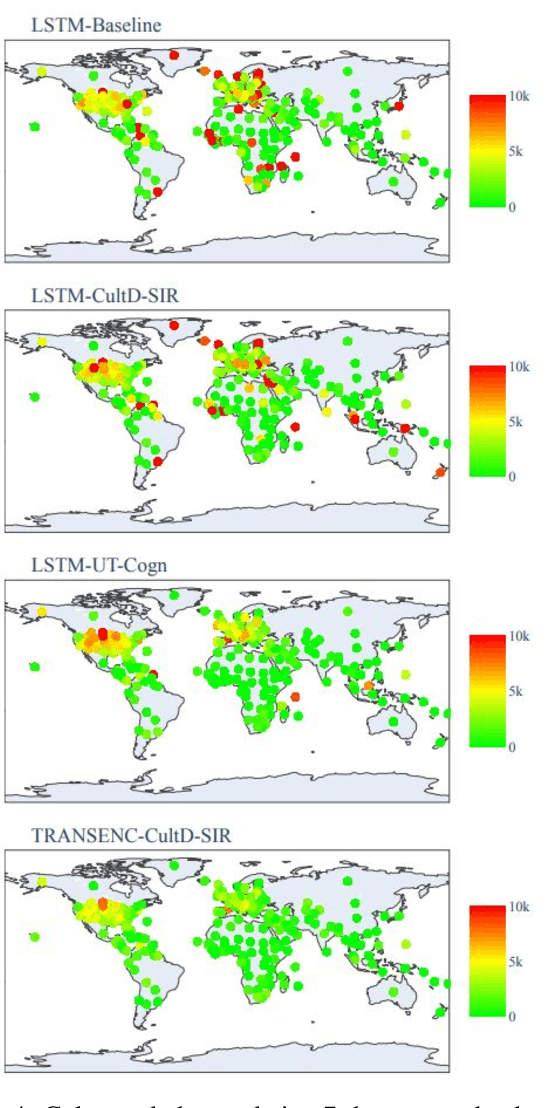
Throughout the Covid-19 pandemic, a significant amount of effort had been put into developing techniques that predict the number of infections under various assumptions about the public policy and non-pharmaceutical interventions. While both the available data and the sophistication of the AI models and available computing power exceed what was available in previous years, the overall success of prediction approaches was very limited. In this paper, we start from prediction algorithms proposed for XPrize Pandemic Response Challenge and consider several directions that might allow their improvement. Then, we investigate their performance over medium-term predictions extending over several months. We find that augmenting the algorithms with additional information about the culture of the modeled region, incorporating traditional compartmental models and up-to-date deep learning architectures can improve the performance for short term predictions, the accuracy of medium-term predictions is still very low and a significant amount of future research is needed to make such models a reliable component of a public policy toolbox.
Smart Home Energy Management: Sequence-to-Sequence Load Forecasting and Q-Learning
Sep 25, 2021
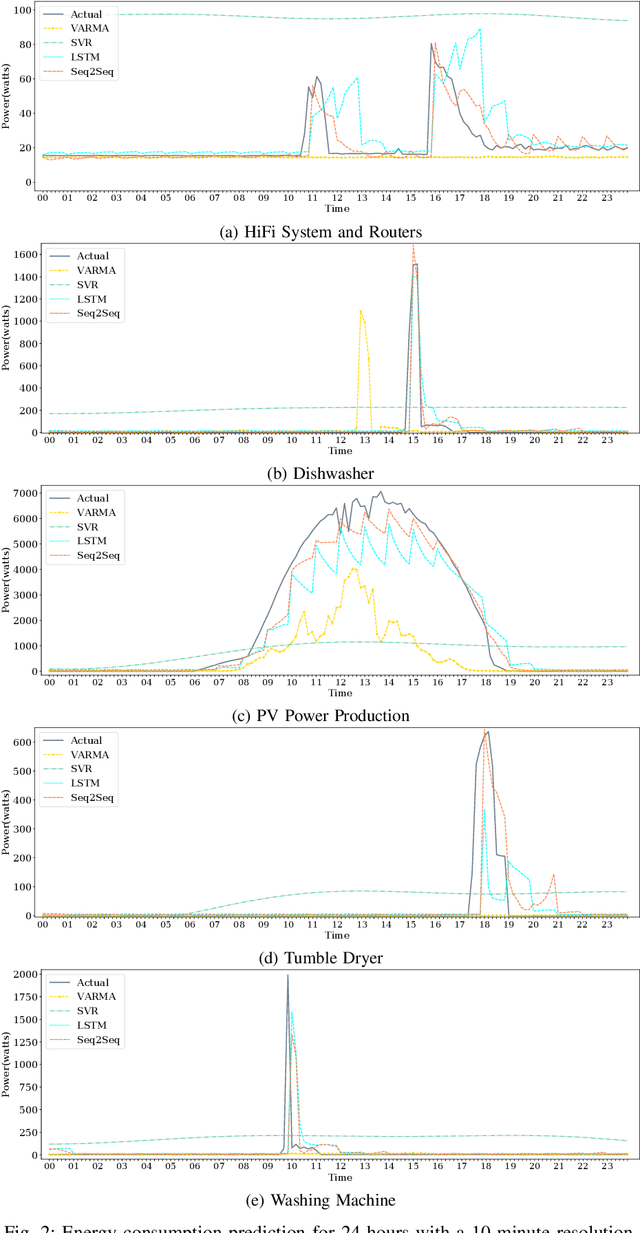
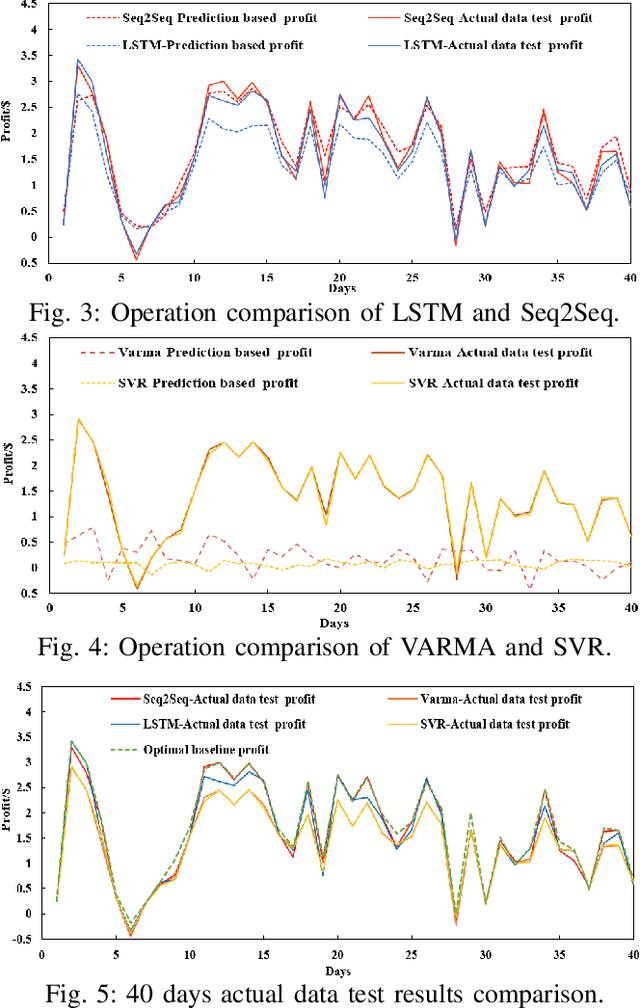
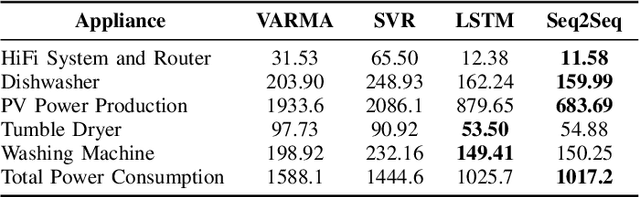
A smart home energy management system (HEMS) can contribute towards reducing the energy costs of customers; however, HEMS suffers from uncertainty in both energy generation and consumption patterns. In this paper, we propose a sequence to sequence (Seq2Seq) learning-based supply and load prediction along with reinforcement learning-based HEMS control. We investigate how the prediction method affects the HEMS operation. First, we use Seq2Seq learning to predict photovoltaic (PV) power and home devices' load. We then apply Q-learning for offline optimization of HEMS based on the prediction results. Finally, we test the online performance of the trained Q-learning scheme with actual PV and load data. The Seq2Seq learning is compared with VARMA, SVR, and LSTM in both prediction and operation levels. The simulation results show that Seq2Seq performs better with a lower prediction error and online operation performance.
Short-Term Load Forecasting for Smart HomeAppliances with Sequence to Sequence Learning
Jun 26, 2021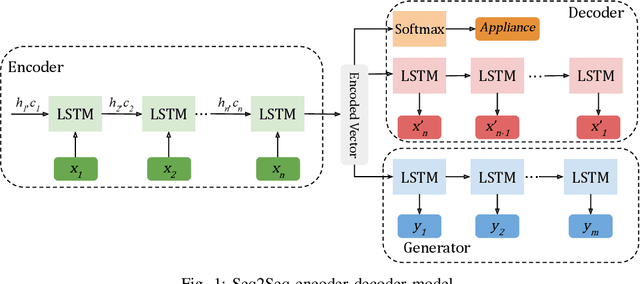
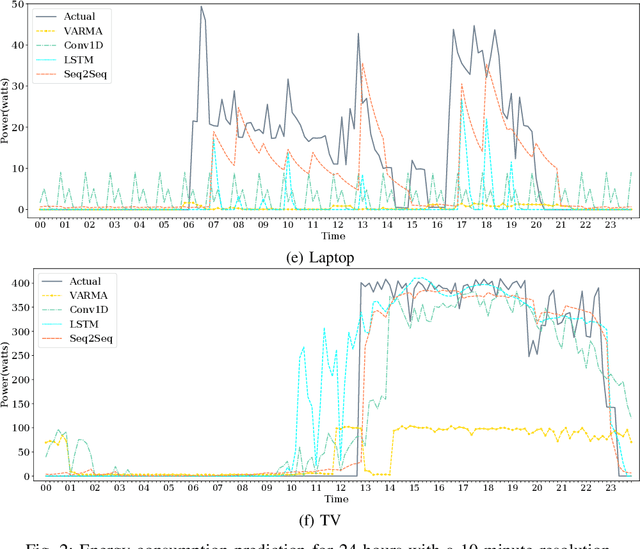
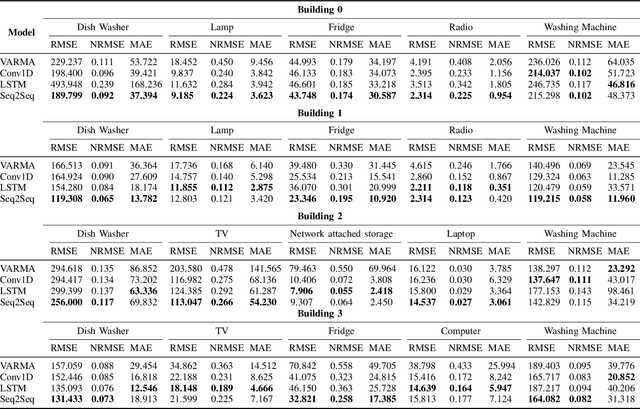
Appliance-level load forecasting plays a critical role in residential energy management, besides having significant importance for ancillary services performed by the utilities. In this paper, we propose to use an LSTM-based sequence-to-sequence (seq2seq) learning model that can capture the load profiles of appliances. We use a real dataset collected fromfour residential buildings and compare our proposed schemewith three other techniques, namely VARMA, Dilated One Dimensional Convolutional Neural Network, and an LSTM model.The results show that the proposed LSTM-based seq2seq model outperforms other techniques in terms of prediction error in most cases.